Muchas veces, para acelerar tareas específicas, se utilizan arquitecturas especializadas de computación en paralelo junto a procesadores tradicionales.La comunicación y sincronización entre diferentes subtareas son algunos de los mayores obstáculos para obtener un buen rendimiento del programa paralelo.[6] La computación en paralelo, por el contrario, utiliza simultáneamente múltiples elementos de procesamiento para resolver un problema.Con el fin del aumento de la frecuencia, estos transistores adicionales —que ya no se utilizan para el aumento de la frecuencia— se pueden utilizar para añadir hardware adicional que permita la computación paralela.La gestación de un niño toma nueve meses, no importa cuántas mujeres se le asigne».En este ejemplo, no existen dependencias entre las instrucciones, por lo que todos ellos se pueden ejecutar en paralelo.Las condiciones de Bernstein no permiten que la memoria se comparta entre los diferentes procesos.Por esto son necesarios algunos medios que impongan un ordenamiento entre los accesos tales como semáforos, barreras o algún otro método de sincronización.Por lo tanto, para garantizar la correcta ejecución del programa, el programa anterior se puede reescribir usando bloqueos: Un hilo bloqueará con éxito la variable V, mientras que el otro hilo no podrá continuar hasta que V se desbloquee.Bloquear múltiples variables utilizando cerraduras no atómicas introduce la posibilidad de que el programa alcance un bloqueo mutuo (deadlock).El modelo de consistencia define reglas para las operaciones en la memoria del ordenador y cómo se producen los resultados.Flynn clasifica los programas y computadoras atendiendo a si están operando con uno o varios conjuntos de instrucciones y si esas instrucciones se utilizan en una o varias series de datos.La clasificación instrucción-única-datos-múltiples (SIMD) es análoga a hacer la misma operación varias veces sobre un conjunto de datos grande.Estas instrucciones pueden reordenarse y combinarse en grupos que luego son ejecutadas en paralelo sin cambiar el resultado del programa.Dado que cada iteración depende del resultado de la anterior, no se pueden realizar en paralelo.Es probable que el medio utilizado para la comunicación entre los procesadores de grandes máquinas multiprocesador sea jerárquico.El microprocesador Cell de IBM, diseñado para su uso en la consola Sony PlayStation 3, es otro prominente procesador multinúcleo.Un multiprocesador simétrico (SMP) es un sistema computacional con múltiples procesadores idénticos que comparten memoria y se conectan a través de un bus.También se pueden utilizar para este propósito subconjuntos específicos de SystemC basados en C++.Los GPUs son co-procesadores que han sido fuertemente optimizados para procesamiento de gráficos por computadora.Un procesador vectorial es un CPU o un sistema computacional que puede ejecutar la misma instrucción en grandes conjuntos de datos.Las empresas CAPS entreprise y Pathscale están intentando convertir las directivas de HMPP (Hybrid Multicore Parallel Programming) en un estándar abierto denominado OpenHMPP.Existen pocos lenguajes de programación paralelos totalmente implícitos: SISAL, Parallel Haskell, y (para FPGAs) Mitrion C. Mientras un sistema computacional crece en complejidad, el tiempo medio entre fallos por lo general disminuye.Los subíndices son constantes enteras que sirven como nombre para la lista de comandos.Se convirtió en el primer equipo disponible en el mercado que utilizaba comandos aritméticos de punto flotante totalmente automáticos.[47] También en 1958, los investigadores de IBM John Cocke y Daniel Slotnick discutieron por primera vez el uso del paralelismo en cálculos numéricos.[50] En 1964, Slotnick había propuesto la construcción de un ordenador masivamente paralelo para el Laboratorio Nacional Lawrence Livermore.[48] Su diseño fue financiado por la Fuerza Aérea de los Estados Unidos, que fue el primer esfuerzo por lograr la computación en paralelo SIMD.Sin embargo, ILLIAC IV fue llamado «el más infame de los superordenadores», pues solo se había completado una cuarta parte del proyecto.8][43] Cuando estaba listo para ejecutar una aplicación real por primera vez en 1976, fue superado por supercomputadoras comerciales, como el Cray-1.
La supercomputadora
Cray-2
fue la más rápida del mundo desde 1985 hasta 1989.
Representación gráfica de la
ley de Amdahl
. La mejora en la velocidad de ejecución de un programa como resultado de la paralelización está limitada por la porción del programa que no se puede paralelizar. Por ejemplo, si el 10% del programa no puede paralelizarse, el máximo teórico de aceleración utilizando la computación en paralelo sería de 10x no importa cuántos procesadores se utilicen.
Supongamos que una tarea tiene dos partes independientes, A y B. B tarda aproximadamente 25% del tiempo total. Con esfuerzo adicional, un programador puede hacer esta parte cinco veces más rápida, pero esto reduce el tiempo de cálculo global por muy poco. Por otro lado, puede que sea necesario poco trabajo para hacer que la parte A sea doble de rápida. Esto haría el cálculo mucho más rápido que mediante la optimización de la parte B, a pesar de que B tiene una mayor aceleración (5x frente a 2×).
Leslie Lamport
definió por primera vez el concepto de consistencia secuencial. También es conocido por su trabajo en el desarrollo del software
LaTeX
.
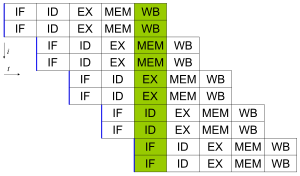
Un
pipeline
canónico de cinco etapas en una máquina RISC (IF = Pedido de Instrucción, ID = Decodificación de instrucción, EX = Ejecutar, MEM = Acceso a la memoria, WB = Escritura)
Un procesador superescalar con
pipeline
de cinco etapas, capaz de ejecutar dos instrucciones por ciclo. Puede tener dos instrucciones en cada etapa del
pipeline
, para un total de hasta 10 instrucciones (se muestra en verde) ejecutadas simultáneamente.
Una vista lógica de una arquitectura con acceso a memoria no uniforme (NUMA). Los procesadores en un directorio pueden acceder a la memoria de su directorio con una menor latencia de la que pueden acceder a la memoria del directorio de otro.
Un clúster Beowulf.
Un gabinete de Blue Gene/L, clasificado como el cuarto mejor superordenador del mundo de acuerdo a la clasificación TOP500 en 11/2008. Blue Gene/L es un procesador masivamente paralelo.