

Ácido desoxirribonucleico ( / d iː ˈ ɒ k s ɪ ˌ r aɪ b oʊ nj uː ˌ k l iː ɪ k , - ˌ k l eɪ -/ ;[1] El ADN) es unpolímerocompuesto por dosde polinucleótidosque se enrollan una alrededor de la otra para formar unadoble hélice. El polímero llevagenéticaspara el desarrollo, funcionamiento, crecimiento yreproducciónde todoslos organismosy muchosvirus. El ADN yel ácido ribonucleico(ARN) sonácidos nucleicos. Junto conlas proteínas,los lípidosy los carbohidratos complejos (polisacáridos), los ácidos nucleicos son uno de los cuatro tipos principales demacromoléculasvidaconocidas.
Las dos cadenas de ADN se conocen como polinucleótidos, ya que están compuestas de unidades monoméricas más simples llamadas nucleótidos . [2] [3] Cada nucleótido está compuesto por una de las cuatro nucleobases que contienen nitrógeno ( citosina [C], guanina [G], adenina [A] o timina [T]), un azúcar llamado desoxirribosa y un grupo fosfato . Los nucleótidos están unidos entre sí en una cadena mediante enlaces covalentes (conocidos como enlace fosfodiéster ) entre el azúcar de un nucleótido y el fosfato del siguiente, lo que da como resultado una cadena principal alternada de azúcar-fosfato . Las bases nitrogenadas de las dos cadenas de polinucleótidos separadas están unidas entre sí, de acuerdo con las reglas de apareamiento de bases (A con T y C con G), con enlaces de hidrógeno para formar ADN bicatenario. Las bases nitrogenadas complementarias se dividen en dos grupos, las pirimidinas de anillo simple y las purinas de anillo doble . En el ADN, las pirimidinas son timina y citosina; las purinas son adenina y guanina.
Ambas hebras de ADN bicatenario almacenan la misma información biológica . Esta información se replica cuando las dos hebras se separan. Una gran parte del ADN (más del 98% para los humanos) es no codificante , lo que significa que estas secciones no sirven como patrones para las secuencias de proteínas . Las dos hebras de ADN discurren en direcciones opuestas entre sí y, por tanto, son antiparalelas . Unido a cada azúcar hay uno de los cuatro tipos de nucleobases (o bases ). Es la secuencia de estas cuatro nucleobases a lo largo de la cadena principal la que codifica la información genética. Las hebras de ARN se crean utilizando hebras de ADN como plantilla en un proceso llamado transcripción , donde las bases de ADN se intercambian por sus bases correspondientes excepto en el caso de la timina (T), por la que el ARN sustituye al uracilo (U). [4] Según el código genético , estas hebras de ARN especifican la secuencia de aminoácidos dentro de las proteínas en un proceso llamado traducción .
Dentro de las células eucariotas, el ADN se organiza en estructuras largas llamadas cromosomas . Antes de la división celular típica , estos cromosomas se duplican en el proceso de replicación del ADN, proporcionando un conjunto completo de cromosomas para cada célula hija. Los organismos eucariotas ( animales , plantas , hongos y protistas ) almacenan la mayor parte de su ADN dentro del núcleo celular como ADN nuclear , y algo en las mitocondrias como ADN mitocondrial o en los cloroplastos como ADN de cloroplasto . [5] En contraste, los procariotas ( bacterias y arqueas ) almacenan su ADN solo en el citoplasma , en cromosomas circulares . Dentro de los cromosomas eucariotas, las proteínas de la cromatina , como las histonas , compactan y organizan el ADN. Estas estructuras compactadoras guían las interacciones entre el ADN y otras proteínas, ayudando a controlar qué partes del ADN se transcriben.

El ADN es un polímero largo hecho de unidades repetidas llamadas nucleótidos . [6] [7] La estructura del ADN es dinámica a lo largo de su longitud, siendo capaz de enrollarse en bucles apretados y otras formas. [8] En todas las especies está compuesto de dos cadenas helicoidales, unidas entre sí por enlaces de hidrógeno . Ambas cadenas están enrolladas alrededor del mismo eje y tienen el mismo paso de 34 ångströms (3,4 nm ). El par de cadenas tiene un radio de 10 Å (1,0 nm). [9] Según otro estudio, cuando se midió en una solución diferente, la cadena de ADN midió 22-26 Å (2,2-2,6 nm) de ancho, y una unidad de nucleótido midió 3,3 Å (0,33 nm) de largo. [10] La densidad de flotación de la mayoría del ADN es de 1,7 g/cm 3 . [11]
El ADN no suele existir como una sola hebra, sino como un par de hebras que se mantienen firmemente unidas. [9] [12] Estas dos hebras largas se enrollan una alrededor de la otra, en forma de doble hélice . El nucleótido contiene tanto un segmento de la estructura principal de la molécula (que mantiene unida la cadena) como una nucleobase (que interactúa con la otra hebra de ADN en la hélice). Una nucleobase unida a un azúcar se llama nucleósido , y una base unida a un azúcar y a uno o más grupos fosfato se llama nucleótido . Un biopolímero que comprende múltiples nucleótidos unidos (como en el ADN) se llama polinucleótido . [13]
La estructura principal de la cadena de ADN está formada por grupos de fosfato y azúcar alternados . [14] El azúcar del ADN es la 2-desoxirribosa , que es un azúcar pentosa (de cinco carbonos ). Los azúcares están unidos por grupos de fosfato que forman enlaces fosfodiéster entre el tercer y quinto átomo de carbono de los anillos de azúcar adyacentes. Estos se conocen como carbonos del extremo 3' (tres extremos primos) y del extremo 5' (cinco extremos primos), utilizándose el símbolo primo para distinguir estos átomos de carbono de los de la base con la que la desoxirribosa forma un enlace glucosídico . [12]
Por lo tanto, cualquier cadena de ADN normalmente tiene un extremo en el que hay un grupo fosfato unido al carbono 5' de una ribosa (el fosforilo 5') y otro extremo en el que hay un grupo hidroxilo libre unido al carbono 3' de una ribosa (el hidroxilo 3'). La orientación de los carbonos 3' y 5' a lo largo de la cadena principal de azúcar-fosfato confiere direccionalidad (a veces llamada polaridad) a cada cadena de ADN. En una doble hélice de ácido nucleico , la dirección de los nucleótidos en una cadena es opuesta a su dirección en la otra cadena: las cadenas son antiparalelas . Se dice que los extremos asimétricos de las cadenas de ADN tienen una direccionalidad de cinco extremos primarios (5') y tres extremos primarios (3'), con el extremo 5' que tiene un grupo fosfato terminal y el extremo 3' un grupo hidroxilo terminal. Una diferencia importante entre el ADN y el ARN es el azúcar, ya que la 2-desoxirribosa en el ADN es reemplazada por el azúcar pentosa relacionado, la ribosa, en el ARN. [12]

La doble hélice del ADN se estabiliza principalmente por dos fuerzas: enlaces de hidrógeno entre nucleótidos e interacciones de apilamiento de bases entre nucleobases aromáticas . [16] Las cuatro bases que se encuentran en el ADN son adenina ( A ), citosina ( C ), guanina ( G ) y timina ( T ). Estas cuatro bases están unidas al fosfato de azúcar para formar el nucleótido completo, como se muestra para el monofosfato de adenosina . La adenina se empareja con la timina y la guanina se empareja con la citosina, formando pares de bases AT y GC . [17] [18]
Las nucleobases se clasifican en dos tipos: las purinas , A y G , que son compuestos heterocíclicos fusionados de cinco y seis miembros , y las pirimidinas , los anillos de seis miembros C y T. [12] Una quinta nucleobase pirimidínica, el uracilo ( U ), suele ocupar el lugar de la timina en el ARN y se diferencia de esta por carecer de un grupo metilo en su anillo. Además del ARN y el ADN, se han creado muchos análogos artificiales de ácidos nucleicos para estudiar las propiedades de los ácidos nucleicos o para su uso en biotecnología. [19]
Las bases modificadas se encuentran en el ADN. La primera de ellas reconocida fue la 5-metilcitosina , que se encontró en el genoma de Mycobacterium tuberculosis en 1925. [20] La razón de la presencia de estas bases no canónicas en los virus bacterianos ( bacteriófagos ) es evitar las enzimas de restricción presentes en las bacterias. Este sistema enzimático actúa al menos en parte como un sistema inmunológico molecular que protege a las bacterias de la infección por virus. [21] Las modificaciones de las bases citosina y adenina, las bases del ADN más comunes y modificadas, desempeñan papeles vitales en el control epigenético de la expresión génica en plantas y animales. [22]
Se sabe que en el ADN existen varias bases no canónicas. [23] La mayoría de ellas son modificaciones de las bases canónicas más uracilo.

Las hebras helicoidales gemelas forman la estructura principal del ADN. Se puede encontrar otra doble hélice trazando los espacios, o surcos, entre las hebras. Estos huecos son adyacentes a los pares de bases y pueden proporcionar un sitio de unión . Como las hebras no están ubicadas simétricamente entre sí, los surcos tienen un tamaño desigual. El surco mayor tiene 22 ångströms (2,2 nm) de ancho, mientras que el surco menor tiene 12 Å (1,2 nm) de ancho. [24] Debido al mayor ancho del surco mayor, los bordes de las bases son más accesibles en el surco mayor que en el surco menor. Como resultado, las proteínas como los factores de transcripción que pueden unirse a secuencias específicas en el ADN bicatenario generalmente hacen contacto con los lados de las bases expuestas en el surco mayor. [25] Esta situación varía en conformaciones inusuales de ADN dentro de la célula (ver abajo) , pero los surcos mayores y menores siempre se nombran para reflejar las diferencias de ancho que se verían si el ADN se torciera nuevamente a la forma B ordinaria .
En una doble hélice de ADN, cada tipo de nucleobase en una cadena se enlaza con solo un tipo de nucleobase en la otra cadena. Esto se llama apareamiento de bases complementarias . Las purinas forman enlaces de hidrógeno con las pirimidinas, con la adenina uniéndose solo a la timina en dos enlaces de hidrógeno, y la citosina uniéndose solo a la guanina en tres enlaces de hidrógeno. Esta disposición de dos nucleótidos que se unen a través de la doble hélice (de anillo de seis carbonos a anillo de seis carbonos) se llama par de bases Watson-Crick. El ADN con alto contenido de GC es más estable que el ADN con bajo contenido de GC . Un par de bases Hoogsteen (unión de hidrógeno del anillo de 6 carbonos al anillo de 5 carbonos) es una variación rara del apareamiento de bases. [26] Como los enlaces de hidrógeno no son covalentes , se pueden romper y volver a unir con relativa facilidad. Las dos cadenas de ADN en una doble hélice se pueden separar como una cremallera, ya sea por una fuerza mecánica o alta temperatura . [27] Como resultado de esta complementariedad de pares de bases, toda la información de la secuencia bicatenaria de una hélice de ADN se duplica en cada hebra, lo que es vital para la replicación del ADN. Esta interacción reversible y específica entre pares de bases complementarios es fundamental para todas las funciones del ADN en los organismos. [7]
La mayoría de las moléculas de ADN son en realidad dos cadenas de polímeros unidas entre sí de forma helicoidal mediante enlaces no covalentes; esta estructura de doble cadena (dsADN) se mantiene en gran medida gracias a las interacciones de apilamiento de bases intracatenarias, que son más fuertes para las pilas G,C . Las dos cadenas pueden separarse (un proceso conocido como fusión) para formar dos moléculas de ADN monocatenario (ssADN). La fusión se produce a altas temperaturas, bajo nivel de sal y pH alto (el pH bajo también funde el ADN, pero como el ADN es inestable debido a la despurinización ácida, rara vez se utiliza un pH bajo).
La estabilidad de la forma dsADN depende no solo del contenido de GC (porcentaje de pares de bases G,C ), sino también de la secuencia (ya que el apilamiento es específico de la secuencia) y también de la longitud (las moléculas más largas son más estables). La estabilidad se puede medir de varias maneras; una forma común es la temperatura de fusión (también llamada valor Tm ), que es la temperatura a la que el 50% de las moléculas de doble cadena se convierten en moléculas de cadena sencilla; la temperatura de fusión depende de la fuerza iónica y la concentración de ADN. Como resultado, es tanto el porcentaje de pares de bases GC como la longitud total de una doble hélice de ADN lo que determina la fuerza de la asociación entre las dos cadenas de ADN. Las hélices de ADN largas con un alto contenido de GC tienen cadenas que interactúan más fuertemente, mientras que las hélices cortas con un alto contenido de AT tienen cadenas que interactúan más débilmente. [28] En biología, las partes de la doble hélice del ADN que necesitan separarse fácilmente, como la caja TATAAT Pribnow en algunos promotores , tienden a tener un alto contenido de AT , lo que hace que las hebras sean más fáciles de separar. [29]
En el laboratorio, la fuerza de esta interacción se puede medir hallando la temperatura de fusión Tm necesaria para romper la mitad de los enlaces de hidrógeno. Cuando todos los pares de bases de una doble hélice de ADN se funden, las cadenas se separan y existen en solución como dos moléculas completamente independientes. Estas moléculas de ADN monocatenario no tienen una única forma común, pero algunas conformaciones son más estables que otras. [30]

En los seres humanos, el genoma nuclear diploide femenino total por célula se extiende por 6,37 pares de gigabases (Gbp), tiene 208,23 cm de largo y pesa 6,51 picogramos (pg). [31] Los valores masculinos son 6,27 Gbp, 205,00 cm, 6,41 pg. [31] Cada polímero de ADN puede contener cientos de millones de nucleótidos, como en el cromosoma 1. El cromosoma 1 es el cromosoma humano más grande con aproximadamente 220 millones de pares de bases , y sería85 mm de largo si se endereza. [32]
En los eucariotas , además del ADN nuclear , también existe el ADN mitocondrial (ADNmt), que codifica ciertas proteínas utilizadas por las mitocondrias. El ADNmt suele ser relativamente pequeño en comparación con el ADN nuclear. Por ejemplo, el ADN mitocondrial humano forma moléculas circulares cerradas, cada una de las cuales contiene 16.569 [33] [34] pares de bases de ADN, [35] y cada una de estas moléculas contiene normalmente un conjunto completo de genes mitocondriales. Cada mitocondria humana contiene, en promedio, aproximadamente 5 moléculas de ADNmt. [35] Cada célula humana contiene aproximadamente 100 mitocondrias, lo que da un número total de moléculas de ADNmt por célula humana de aproximadamente 500. [35] Sin embargo, la cantidad de mitocondrias por célula también varía según el tipo de célula, y un óvulo puede contener 100.000 mitocondrias, que corresponden a hasta 1.500.000 copias del genoma mitocondrial (que constituye hasta el 90% del ADN de la célula). [36]
Una secuencia de ADN se denomina secuencia "sentido" si es la misma que la de una copia de ARN mensajero que se traduce en proteína. [37] La secuencia en la cadena opuesta se denomina secuencia "antisentido". Tanto las secuencias sentido como las antisentido pueden existir en diferentes partes de la misma cadena de ADN (es decir, ambas cadenas pueden contener secuencias sentido y antisentido). Tanto en procariotas como en eucariotas, se producen secuencias de ARN antisentido, pero las funciones de estos ARN no están del todo claras. [38] Una propuesta es que los ARN antisentido están involucrados en la regulación de la expresión génica a través del apareamiento de bases ARN-ARN. [39]
Unas pocas secuencias de ADN en procariotas y eucariotas, y más en plásmidos y virus , difuminan la distinción entre cadenas con sentido y antisentido al tener genes superpuestos . [40] En estos casos, algunas secuencias de ADN cumplen una doble función, codificando una proteína cuando se leen a lo largo de una cadena, y una segunda proteína cuando se leen en la dirección opuesta a lo largo de la otra cadena. En las bacterias , esta superposición puede estar involucrada en la regulación de la transcripción genética, [41] mientras que en los virus, los genes superpuestos aumentan la cantidad de información que se puede codificar dentro del pequeño genoma viral. [42]
El ADN se puede torcer como una cuerda en un proceso llamado superenrollamiento del ADN . Con el ADN en su estado "relajado", una hebra generalmente rodea el eje de la doble hélice una vez cada 10,4 pares de bases, pero si el ADN está torcido, las hebras se enrollan más apretadamente o más flojamente. [43] Si el ADN se tuerce en la dirección de la hélice, esto es superenrollamiento positivo, y las bases se mantienen más juntas. Si se tuercen en la dirección opuesta, esto es superenrollamiento negativo, y las bases se separan más fácilmente. En la naturaleza, la mayoría del ADN tiene un ligero superenrollamiento negativo que es introducido por enzimas llamadas topoisomerasas . [44] Estas enzimas también son necesarias para aliviar las tensiones de torsión introducidas en las hebras de ADN durante procesos como la transcripción y la replicación del ADN . [45]

El ADN existe en muchas conformaciones posibles que incluyen las formas A-ADN , B-ADN y Z-ADN , aunque solo el B-ADN y el Z-ADN se han observado directamente en organismos funcionales. [14] La conformación que adopta el ADN depende del nivel de hidratación, la secuencia de ADN, la cantidad y dirección del superenrollamiento, las modificaciones químicas de las bases, el tipo y la concentración de iones metálicos y la presencia de poliaminas en solución. [46]
Los primeros informes publicados de patrones de difracción de rayos X de A-ADN (y también de B-ADN) utilizaron análisis basados en funciones de Patterson que proporcionaron solo una cantidad limitada de información estructural para fibras orientadas de ADN. [47] [48] Wilkins et al. propusieron un análisis alternativo en 1953 para los patrones de dispersión por difracción de rayos X de B-ADN in vivo de fibras de ADN altamente hidratadas en términos de cuadrados de funciones de Bessel . [49] En la misma revista, James Watson y Francis Crick presentaron su análisis de modelado molecular de los patrones de difracción de rayos X de ADN para sugerir que la estructura era una doble hélice. [9]
Aunque la forma B-ADN es la más común en las condiciones que se dan en las células, [50] no es una conformación bien definida sino una familia de conformaciones de ADN relacionadas [51] que se dan en los altos niveles de hidratación presentes en las células. Sus correspondientes patrones de difracción y dispersión de rayos X son característicos de los paracristales moleculares con un grado significativo de desorden. [52] [53]
En comparación con el ADN-B, la forma del ADN-A es una espiral dextrógira más ancha , con un surco menor ancho y poco profundo y un surco mayor más estrecho y profundo. La forma A se produce en condiciones no fisiológicas en muestras de ADN parcialmente deshidratadas, mientras que en la célula puede producirse en apareamientos híbridos de cadenas de ADN y ARN, y en complejos enzima-ADN. [54] [55] Los segmentos de ADN en los que las bases han sido modificadas químicamente por metilación pueden sufrir un cambio mayor en la conformación y adoptar la forma Z. Aquí, las cadenas giran alrededor del eje helicoidal en una espiral levógira, lo opuesto a la forma B más común. [56] Estas estructuras inusuales pueden ser reconocidas por proteínas de unión específicas del ADN-Z y pueden estar involucradas en la regulación de la transcripción. [57]
Durante muchos años, los exobiólogos han propuesto la existencia de una biosfera de sombra , una biosfera microbiana postulada de la Tierra que utiliza procesos bioquímicos y moleculares radicalmente diferentes a los de la vida actualmente conocida. Una de las propuestas fue la existencia de formas de vida que utilizan arsénico en lugar de fósforo en el ADN . En 2010 se anunció un informe sobre la posibilidad en la bacteria GFAJ-1 , [58] [59] aunque la investigación fue cuestionada, [59] [60] y la evidencia sugiere que la bacteria previene activamente la incorporación de arsénico en la cadena principal del ADN y otras biomoléculas. [61]

En los extremos de los cromosomas lineales hay regiones especializadas de ADN llamadas telómeros . La función principal de estas regiones es permitir que la célula replique los extremos de los cromosomas utilizando la enzima telomerasa , ya que las enzimas que normalmente replican el ADN no pueden copiar los extremos 3′ de los cromosomas. [63] Estas tapas cromosómicas especializadas también ayudan a proteger los extremos del ADN y evitan que los sistemas de reparación del ADN en la célula los traten como un daño que debe corregirse. [64] En las células humanas , los telómeros suelen ser longitudes de ADN monocatenario que contienen varios miles de repeticiones de una secuencia TTAGGG simple. [65]
Estas secuencias ricas en guanina pueden estabilizar los extremos de los cromosomas al formar estructuras de conjuntos apilados de unidades de cuatro bases, en lugar de los pares de bases habituales que se encuentran en otras moléculas de ADN. Aquí, cuatro bases de guanina, conocidas como tétrada de guanina , forman una placa plana. Estas unidades planas de cuatro bases luego se apilan una sobre otra para formar una estructura G-quadruplex estable . [66] Estas estructuras se estabilizan mediante enlaces de hidrógeno entre los bordes de las bases y la quelación de un ion metálico en el centro de cada unidad de cuatro bases. [67] También se pueden formar otras estructuras, con el conjunto central de cuatro bases provenientes de una sola hebra doblada alrededor de las bases, o de varias hebras paralelas diferentes, cada una contribuyendo con una base a la estructura central.
Además de estas estructuras apiladas, los telómeros también forman grandes estructuras en forma de bucle llamadas bucles teloméricos o bucles T. Aquí, el ADN monocatenario se enrolla en un largo círculo estabilizado por proteínas que se unen a los telómeros. [68] En el extremo del bucle T, el ADN monocatenario del telómero se mantiene en una región de ADN bicatenario por la hebra del telómero, lo que altera el ADN de doble hélice y el apareamiento de bases con una de las dos hebras. Esta estructura de triple hebra se llama bucle de desplazamiento o bucle D. [66]
En el ADN, el deshilachado se produce cuando existen regiones no complementarias al final de una doble cadena de ADN que, por lo demás, sería complementaria. Sin embargo, el ADN ramificado puede producirse si se introduce una tercera cadena de ADN que contenga regiones adyacentes capaces de hibridar con las regiones deshilachadas de la doble cadena preexistente. Aunque el ejemplo más simple de ADN ramificado implica solo tres cadenas de ADN, también son posibles complejos que implican cadenas adicionales y múltiples ramificaciones. [69] El ADN ramificado se puede utilizar en nanotecnología para construir formas geométricas; consulte la sección sobre usos en tecnología a continuación.
Se han sintetizado varias nucleobases artificiales y se han incorporado con éxito en el análogo de ADN de ocho bases llamado ADN Hachimoji . Bautizadas como S, B, P y Z, estas bases artificiales son capaces de unirse entre sí de una manera predecible (S–B y P–Z), mantener la estructura de doble hélice del ADN y transcribirse en ARN. Su existencia podría verse como una indicación de que no hay nada especial en las cuatro nucleobases naturales que evolucionaron en la Tierra. [70] [71] Por otro lado, el ADN está estrechamente relacionado con el ARN , que no solo actúa como una transcripción del ADN, sino que también realiza como máquinas moleculares muchas tareas en las células. Para este propósito, tiene que plegarse en una estructura. Se ha demostrado que para permitir la creación de todas las estructuras posibles se requieren al menos cuatro bases para el ARN correspondiente , [72] aunque también es posible un número mayor, pero esto iría en contra del principio natural del mínimo esfuerzo .
Los grupos fosfato del ADN le confieren propiedades ácidas similares a las del ácido fosfórico y puede considerarse un ácido fuerte . Se ionizará por completo a un pH celular normal, liberando protones que dejan cargas negativas en los grupos fosfato. Estas cargas negativas protegen al ADN de la descomposición por hidrólisis al repeler a los nucleófilos que podrían hidrolizarlo. [73]
.jpg/1280px-Estrazione_DNA_(cropped).jpg)
El ADN puro extraído de las células forma grumos blancos y fibrosos. [74]
La expresión de los genes está influenciada por la forma en que el ADN está empaquetado en los cromosomas, en una estructura llamada cromatina . Las modificaciones de bases pueden estar involucradas en el empaquetamiento, con regiones que tienen baja o nula expresión génica que generalmente contienen altos niveles de metilación de bases de citosina . El empaquetamiento del ADN y su influencia en la expresión génica también puede ocurrir por modificaciones covalentes del núcleo de la proteína histona alrededor del cual se envuelve el ADN en la estructura de la cromatina o bien por remodelación llevada a cabo por complejos de remodelación de la cromatina (ver Remodelación de la cromatina ). Existe, además, una comunicación cruzada entre la metilación del ADN y la modificación de las histonas, por lo que pueden afectar de manera coordinada a la cromatina y la expresión génica. [75]
Por ejemplo, la metilación de la citosina produce 5-metilcitosina , que es importante para la inactivación del cromosoma X. [76] El nivel promedio de metilación varía entre organismos: el gusano Caenorhabditis elegans carece de metilación de citosina, mientras que los vertebrados tienen niveles más altos, con hasta un 1% de su ADN que contiene 5-metilcitosina. [77] A pesar de la importancia de la 5-metilcitosina, puede desaminarse para dejar una base de timina, por lo que las citosinas metiladas son particularmente propensas a las mutaciones . [78] Otras modificaciones de bases incluyen la metilación de adenina en bacterias, la presencia de 5-hidroximetilcitosina en el cerebro , [79] y la glicosilación de uracilo para producir la "base J" en los cinetoplastos . [80] [81]

El ADN puede resultar dañado por muchos tipos de mutágenos , que modifican la secuencia del ADN . Los mutágenos incluyen agentes oxidantes , agentes alquilantes y también radiación electromagnética de alta energía como la luz ultravioleta y los rayos X. El tipo de daño al ADN producido depende del tipo de mutágeno. Por ejemplo, la luz ultravioleta puede dañar el ADN produciendo dímeros de timina , que son enlaces cruzados entre bases de pirimidina. [83] Por otro lado, oxidantes como los radicales libres o el peróxido de hidrógeno producen múltiples formas de daño, incluidas modificaciones de bases, en particular de guanosina, y roturas de doble cadena. [84] Una célula humana típica contiene alrededor de 150.000 bases que han sufrido daño oxidativo. [85] De estas lesiones oxidativas, las más peligrosas son las roturas de doble cadena, ya que son difíciles de reparar y pueden producir mutaciones puntuales , inserciones , deleciones de la secuencia de ADN y translocaciones cromosómicas . [86] Estas mutaciones pueden provocar cáncer . Debido a los límites inherentes de los mecanismos de reparación del ADN, si los humanos vivieran lo suficiente, todos acabarían desarrollando cáncer. [87] [88] Los daños en el ADN que se producen de forma natural , debido a los procesos celulares normales que producen especies reactivas de oxígeno, las actividades hidrolíticas del agua celular, etc., también ocurren con frecuencia. Aunque la mayoría de estos daños se reparan, en cualquier célula puede quedar algo de daño en el ADN a pesar de la acción de los procesos de reparación. Estos daños restantes en el ADN se acumulan con la edad en los tejidos postmitóticos de los mamíferos. Esta acumulación parece ser una causa subyacente importante del envejecimiento. [89] [90] [91]
Muchos mutágenos encajan en el espacio entre dos pares de bases adyacentes, esto se llama intercalación . La mayoría de los intercaladores son moléculas aromáticas y planares; los ejemplos incluyen bromuro de etidio , acridinas , daunomicina y doxorrubicina . Para que un intercalador encaje entre pares de bases, las bases deben separarse, distorsionando las cadenas de ADN al desenrollar la doble hélice. Esto inhibe tanto la transcripción como la replicación del ADN, causando toxicidad y mutaciones. [92] Como resultado, los intercaladores de ADN pueden ser carcinógenos y, en el caso de la talidomida, un teratógeno . [93] Otros, como el epóxido de benzo[ a ]pirenodiol y la aflatoxina, forman aductos de ADN que inducen errores en la replicación. [94] Sin embargo, debido a su capacidad para inhibir la transcripción y replicación del ADN, también se utilizan otras toxinas similares en quimioterapia para inhibir las células cancerosas de crecimiento rápido . [95]

El ADN generalmente se presenta como cromosomas lineales en eucariotas y cromosomas circulares en procariotas . El conjunto de cromosomas en una célula constituye su genoma ; el genoma humano tiene aproximadamente 3 mil millones de pares de bases de ADN organizados en 46 cromosomas. [96] La información transportada por el ADN se mantiene en la secuencia de piezas de ADN llamadas genes . La transmisión de información genética en los genes se logra mediante el apareamiento de bases complementarias. Por ejemplo, en la transcripción, cuando una célula usa la información en un gen, la secuencia de ADN se copia en una secuencia de ARN complementaria a través de la atracción entre el ADN y los nucleótidos de ARN correctos. Por lo general, esta copia de ARN se usa luego para hacer una secuencia de proteína coincidente en un proceso llamado traducción , que depende de la misma interacción entre los nucleótidos de ARN. De manera alternativa, una célula puede copiar su información genética en un proceso llamado replicación de ADN . Los detalles de estas funciones se tratan en otros artículos; aquí el enfoque está en las interacciones entre el ADN y otras moléculas que median la función del genoma.
El ADN genómico se empaqueta de forma compacta y ordenada en el proceso llamado condensación del ADN , para adaptarse a los pequeños volúmenes disponibles de la célula. En los eucariotas, el ADN se encuentra en el núcleo celular , con pequeñas cantidades en las mitocondrias y los cloroplastos . En los procariotas, el ADN se mantiene dentro de un cuerpo de forma irregular en el citoplasma llamado nucleoide . [97] La información genética de un genoma se mantiene dentro de los genes, y el conjunto completo de esta información en un organismo se llama genotipo . Un gen es una unidad de herencia y es una región de ADN que influye en una característica particular de un organismo. Los genes contienen un marco de lectura abierto que se puede transcribir y secuencias reguladoras como promotores y potenciadores , que controlan la transcripción del marco de lectura abierto.
En muchas especies , sólo una pequeña fracción de la secuencia total del genoma codifica proteínas. Por ejemplo, sólo alrededor del 1,5% del genoma humano consiste en exones codificadores de proteínas, y más del 50% del ADN humano consiste en secuencias repetitivas no codificantes . [98] Las razones de la presencia de tanto ADN no codificante en los genomas eucariotas y las extraordinarias diferencias en el tamaño del genoma , o valor C , entre especies, representan un rompecabezas de larga data conocido como el " enigma del valor C ". [99] Sin embargo, algunas secuencias de ADN que no codifican proteínas aún pueden codificar moléculas de ARN no codificantes funcionales , que están involucradas en la regulación de la expresión génica . [100]

Algunas secuencias de ADN no codificante desempeñan funciones estructurales en los cromosomas. Los telómeros y centrómeros suelen contener pocos genes, pero son importantes para la función y la estabilidad de los cromosomas. [64] [102] Una forma abundante de ADN no codificante en los seres humanos son los pseudogenes , que son copias de genes que han sido desactivados por mutación. [103] Estas secuencias suelen ser simplemente fósiles moleculares , aunque ocasionalmente pueden servir como material genético en bruto para la creación de nuevos genes a través del proceso de duplicación y divergencia genética . [104]
Un gen es una secuencia de ADN que contiene información genética y puede influir en el fenotipo de un organismo. Dentro de un gen, la secuencia de bases a lo largo de una cadena de ADN define una secuencia de ARN mensajero , que a su vez define una o más secuencias de proteínas. La relación entre las secuencias de nucleótidos de los genes y las secuencias de aminoácidos de las proteínas está determinada por las reglas de traducción , conocidas colectivamente como el código genético . El código genético consta de "palabras" de tres letras llamadas codones formadas a partir de una secuencia de tres nucleótidos (por ejemplo, ACT, CAG, TTT).
En la transcripción, los codones de un gen se copian en ARN mensajero por la ARN polimerasa . Esta copia de ARN luego es decodificada por un ribosoma que lee la secuencia de ARN mediante el apareamiento de bases del ARN mensajero con el ARN de transferencia , que transporta aminoácidos. Dado que hay 4 bases en combinaciones de 3 letras, hay 64 codones posibles (4 combinaciones de 3 ). Estos codifican los veinte aminoácidos estándar , lo que da a la mayoría de los aminoácidos más de un codón posible. También hay tres codones de "parada" o "sin sentido" que significan el final de la región codificante; estos son los codones TAG, TAA y TGA (UAG, UAA y UGA en el ARNm).

La división celular es esencial para que un organismo crezca, pero, cuando una célula se divide, debe replicar el ADN en su genoma para que las dos células hijas tengan la misma información genética que su progenitora. La estructura bicatenaria del ADN proporciona un mecanismo simple para la replicación del ADN . Aquí, las dos hebras se separan y luego la secuencia de ADN complementaria de cada hebra es recreada por una enzima llamada ADN polimerasa . Esta enzima crea la hebra complementaria al encontrar la base correcta a través del apareamiento de bases complementarias y unirla a la hebra original. Como las ADN polimerasas solo pueden extender una hebra de ADN en una dirección de 5' a 3', se utilizan diferentes mecanismos para copiar las hebras antiparalelas de la doble hélice. [105] De esta manera, la base en la hebra antigua dicta qué base aparece en la nueva hebra, y la célula termina con una copia perfecta de su ADN.
El ADN extracelular desnudo (eDNA), la mayor parte del cual se libera por la muerte celular, es casi omnipresente en el medio ambiente. Su concentración en el suelo puede ser tan alta como 2 μg/L, y su concentración en ambientes acuáticos naturales puede ser tan alta como 88 μg/L. [106] Se han propuesto varias funciones posibles para el eDNA: puede estar involucrado en la transferencia horizontal de genes ; [107] puede proporcionar nutrientes; [108] y puede actuar como un amortiguador para reclutar o titular iones o antibióticos. [109] El ADN extracelular actúa como un componente funcional de la matriz extracelular en las biopelículas de varias especies bacterianas. Puede actuar como un factor de reconocimiento para regular la adhesión y dispersión de tipos de células específicos en la biopelícula; [110] puede contribuir a la formación de la biopelícula; [111] y puede contribuir a la fuerza física de la biopelícula y la resistencia al estrés biológico. [112]
El ADN fetal libre de células se encuentra en la sangre de la madre y se puede secuenciar para determinar una gran cantidad de información sobre el feto en desarrollo. [113]
Bajo el nombre de ADN ambiental, el eDNA se ha utilizado cada vez más en las ciencias naturales como herramienta de estudio para la ecología , el seguimiento de los movimientos y la presencia de especies en el agua, el aire o la tierra, y la evaluación de la biodiversidad de un área. [114] [115]
Las trampas extracelulares de neutrófilos (NET) son redes de fibras extracelulares, compuestas principalmente de ADN, que permiten a los neutrófilos , un tipo de glóbulo blanco, matar patógenos extracelulares mientras minimizan el daño a las células huésped.
Todas las funciones del ADN dependen de interacciones con proteínas. Estas interacciones pueden ser inespecíficas o la proteína puede unirse específicamente a una única secuencia de ADN. Las enzimas también pueden unirse al ADN y, entre ellas, las polimerasas que copian la secuencia de bases del ADN en la transcripción y replicación del ADN son particularmente importantes.

Las proteínas estructurales que se unen al ADN son ejemplos bien conocidos de interacciones no específicas entre ADN y proteína. Dentro de los cromosomas, el ADN se mantiene en complejos con proteínas estructurales. Estas proteínas organizan el ADN en una estructura compacta llamada cromatina . En los eucariotas, esta estructura implica la unión del ADN a un complejo de pequeñas proteínas básicas llamadas histonas , mientras que en los procariotas intervienen múltiples tipos de proteínas. [116] [117] Las histonas forman un complejo en forma de disco llamado nucleosoma , que contiene dos vueltas completas de ADN bicatenario envuelto alrededor de su superficie. Estas interacciones no específicas se forman a través de residuos básicos en las histonas, que forman enlaces iónicos con la cadena principal de azúcar-fosfato ácida del ADN y, por tanto, son en gran medida independientes de la secuencia de bases. [118] Las modificaciones químicas de estos residuos de aminoácidos básicos incluyen la metilación , la fosforilación y la acetilación . [119] Estos cambios químicos alteran la fuerza de la interacción entre el ADN y las histonas, haciendo que el ADN sea más o menos accesible a los factores de transcripción y cambiando la tasa de transcripción. [120] Otras proteínas de unión al ADN no específicas en la cromatina incluyen las proteínas del grupo de alta movilidad, que se unen al ADN doblado o distorsionado. [121] Estas proteínas son importantes para doblar conjuntos de nucleosomas y organizarlos en las estructuras más grandes que forman los cromosomas. [122]
Un grupo distinto de proteínas de unión al ADN son las proteínas de unión al ADN que se unen específicamente al ADN monocatenario. En los seres humanos, la proteína de replicación A es el miembro mejor comprendido de esta familia y se utiliza en procesos en los que se separa la doble hélice, incluida la replicación, la recombinación y la reparación del ADN. [123] Estas proteínas de unión parecen estabilizar el ADN monocatenario y protegerlo de la formación de bucles de tallo o de la degradación por nucleasas .

Por el contrario, otras proteínas han evolucionado para unirse a secuencias de ADN particulares. Las más estudiadas de ellas son los diversos factores de transcripción , que son proteínas que regulan la transcripción. Cada factor de transcripción se une a un conjunto particular de secuencias de ADN y activa o inhibe la transcripción de genes que tienen estas secuencias cerca de sus promotores. Los factores de transcripción hacen esto de dos maneras. En primer lugar, pueden unirse a la ARN polimerasa responsable de la transcripción, ya sea directamente o a través de otras proteínas mediadoras; esto ubica la polimerasa en el promotor y le permite comenzar la transcripción. [125] Alternativamente, los factores de transcripción pueden unirse a enzimas que modifican las histonas en el promotor. Esto cambia la accesibilidad de la plantilla de ADN a la polimerasa. [126]
Como estos objetivos de ADN pueden estar presentes en todo el genoma de un organismo, los cambios en la actividad de un tipo de factor de transcripción pueden afectar a miles de genes. [127] En consecuencia, estas proteínas suelen ser los objetivos de los procesos de transducción de señales que controlan las respuestas a los cambios ambientales o la diferenciación y el desarrollo celular . La especificidad de las interacciones de estos factores de transcripción con el ADN proviene de que las proteínas hacen múltiples contactos con los bordes de las bases del ADN, lo que les permite "leer" la secuencia del ADN. La mayoría de estas interacciones de bases se realizan en el surco mayor, donde las bases son más accesibles. [25]
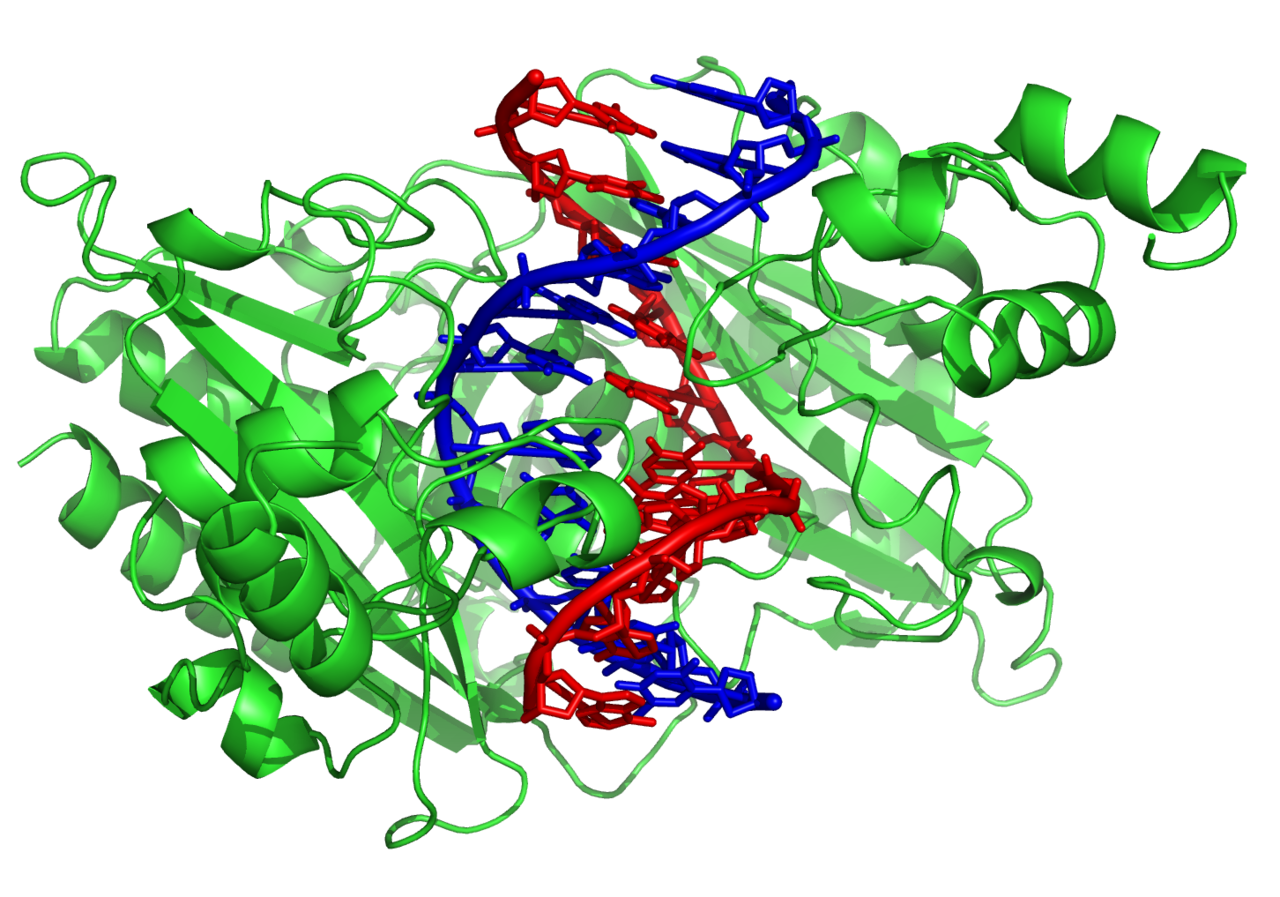
Las nucleasas son enzimas que cortan las cadenas de ADN al catalizar la hidrólisis de los enlaces fosfodiéster . Las nucleasas que hidrolizan los nucleótidos de los extremos de las cadenas de ADN se denominan exonucleasas , mientras que las endonucleasas cortan dentro de las cadenas. Las nucleasas más utilizadas en biología molecular son las endonucleasas de restricción , que cortan el ADN en secuencias específicas. Por ejemplo, la enzima EcoRV que se muestra a la izquierda reconoce la secuencia de 6 bases 5′-GATATC-3′ y realiza un corte en la línea horizontal. En la naturaleza, estas enzimas protegen a las bacterias contra la infección por fagos al digerir el ADN del fago cuando ingresa a la célula bacteriana, actuando como parte del sistema de modificación de restricción . [129] En tecnología, estas nucleasas específicas de secuencia se utilizan en la clonación molecular y la huella genética del ADN .
Las enzimas llamadas ligasas de ADN pueden volver a unir las cadenas de ADN cortadas o rotas. [130] Las ligasas son particularmente importantes en la replicación de la cadena rezagada de ADN, ya que unen los segmentos cortos de ADN producidos en la horquilla de replicación para formar una copia completa de la plantilla de ADN. También se utilizan en la reparación del ADN y la recombinación genética . [130]
Las topoisomerasas son enzimas con actividad tanto de nucleasa como de ligasa. Estas proteínas modifican la cantidad de superenrollamiento del ADN. Algunas de estas enzimas funcionan cortando la hélice del ADN y permitiendo que una sección rote, reduciendo así su nivel de superenrollamiento; la enzima luego sella la rotura del ADN. [44] Otros tipos de estas enzimas son capaces de cortar una hélice del ADN y luego pasar una segunda hebra de ADN a través de esta rotura, antes de volver a unir la hélice. [131] Las topoisomerasas son necesarias para muchos procesos que involucran al ADN, como la replicación y la transcripción del ADN. [45]
Las helicasas son proteínas que son un tipo de motor molecular . Utilizan la energía química de los trifosfatos de nucleósidos , predominantemente trifosfato de adenosina (ATP), para romper los enlaces de hidrógeno entre las bases y desenrollar la doble hélice del ADN en cadenas simples. [132] Estas enzimas son esenciales para la mayoría de los procesos en los que las enzimas necesitan acceder a las bases del ADN.
Las polimerasas son enzimas que sintetizan cadenas de polinucleótidos a partir de trifosfatos de nucleósidos . La secuencia de sus productos se crea en función de las cadenas de polinucleótidos existentes, que se denominan plantillas . Estas enzimas funcionan añadiendo repetidamente un nucleótido al grupo hidroxilo 3' al final de la cadena de polinucleótidos en crecimiento. Como consecuencia, todas las polimerasas funcionan en una dirección de 5' a 3'. [133] En el sitio activo de estas enzimas, el trifosfato de nucleósido entrante se aparea con la plantilla: esto permite a las polimerasas sintetizar con precisión la cadena complementaria de su plantilla. Las polimerasas se clasifican según el tipo de plantilla que utilizan.
En la replicación del ADN, las ADN polimerasas dependientes del ADN hacen copias de las cadenas de polinucleótidos del ADN. Para preservar la información biológica, es esencial que la secuencia de bases en cada copia sea precisamente complementaria a la secuencia de bases en la cadena molde. Muchas ADN polimerasas tienen una actividad de corrección de errores . Aquí, la polimerasa reconoce los errores ocasionales en la reacción de síntesis por la falta de apareamiento de bases entre los nucleótidos desapareados. Si se detecta un desapareamiento, se activa una actividad de exonucleasa 3' a 5' y se elimina la base incorrecta. [134] En la mayoría de los organismos, las ADN polimerasas funcionan en un gran complejo llamado replisoma que contiene múltiples subunidades accesorias, como la abrazadera de ADN o las helicasas . [135]
Las polimerasas de ADN dependientes de ARN son una clase especializada de polimerasas que copian la secuencia de una cadena de ARN en ADN. Incluyen la transcriptasa inversa , que es una enzima viral involucrada en la infección de células por retrovirus , y la telomerasa , que es necesaria para la replicación de los telómeros. [63] [136] Por ejemplo, la transcriptasa inversa del VIH es una enzima para la replicación del virus del SIDA. [136] La telomerasa es una polimerasa inusual porque contiene su propia plantilla de ARN como parte de su estructura. Sintetiza telómeros en los extremos de los cromosomas. Los telómeros previenen la fusión de los extremos de los cromosomas vecinos y protegen los extremos de los cromosomas de daños. [64]
La transcripción la lleva a cabo una ARN polimerasa dependiente del ADN que copia la secuencia de una cadena de ADN en ARN. Para comenzar a transcribir un gen, la ARN polimerasa se une a una secuencia de ADN llamada promotor y separa las cadenas de ADN. Luego copia la secuencia del gen en una transcripción de ARN mensajero hasta que llega a una región de ADN llamada terminador , donde se detiene y se separa del ADN. Al igual que con las ADN polimerasas dependientes del ADN humano, la ARN polimerasa II , la enzima que transcribe la mayoría de los genes en el genoma humano, opera como parte de un gran complejo proteico con múltiples subunidades reguladoras y accesorias. [137]

Una hélice de ADN normalmente no interactúa con otros segmentos de ADN, y en las células humanas, los diferentes cromosomas incluso ocupan áreas separadas en el núcleo llamadas " territorios cromosómicos ". [139] Esta separación física de diferentes cromosomas es importante para la capacidad del ADN de funcionar como un depósito estable de información, ya que una de las pocas veces que los cromosomas interactúan es en el cruce cromosómico que ocurre durante la reproducción sexual , cuando ocurre la recombinación genética . El cruce cromosómico es cuando dos hélices de ADN se rompen, intercambian una sección y luego se vuelven a unir.
La recombinación permite que los cromosomas intercambien información genética y produzcan nuevas combinaciones de genes, lo que aumenta la eficiencia de la selección natural y puede ser importante en la rápida evolución de nuevas proteínas. [140] La recombinación genética también puede estar involucrada en la reparación del ADN, particularmente en la respuesta de la célula a las roturas de doble cadena. [141]
La forma más común de entrecruzamiento cromosómico es la recombinación homóloga , donde los dos cromosomas involucrados comparten secuencias muy similares. La recombinación no homóloga puede ser dañina para las células, ya que puede producir translocaciones cromosómicas y anomalías genéticas. La reacción de recombinación es catalizada por enzimas conocidas como recombinasas , como RAD51 . [142] El primer paso en la recombinación es una ruptura de doble cadena causada por una endonucleasa o daño al ADN. [143] Una serie de pasos catalizados en parte por la recombinasa conduce luego a la unión de las dos hélices por al menos una unión de Holliday , en la que un segmento de una sola cadena en cada hélice se une a la cadena complementaria en la otra hélice. La unión de Holliday es una estructura de unión tetraédrica que se puede mover a lo largo del par de cromosomas, intercambiando una cadena por otra. La reacción de recombinación se detiene entonces por la escisión de la unión y la religación del ADN liberado. [144] Sólo las hebras de polaridad similar intercambian ADN durante la recombinación. Hay dos tipos de escisión: escisión este-oeste y escisión norte-sur. La escisión norte-sur corta ambas hebras de ADN, mientras que la escisión este-oeste deja una hebra de ADN intacta. La formación de una unión de Holliday durante la recombinación hace posible la diversidad genética, el intercambio de genes en los cromosomas y la expresión de genomas virales de tipo salvaje.
El ADN contiene la información genética que permite que todas las formas de vida funcionen, crezcan y se reproduzcan. Sin embargo, no está claro durante cuánto tiempo en los 4 mil millones de años de historia de la vida el ADN ha realizado esta función, ya que se ha propuesto que las primeras formas de vida pueden haber utilizado ARN como material genético. [145] [146] El ARN puede haber actuado como la parte central del metabolismo celular temprano , ya que puede transmitir información genética y llevar a cabo la catálisis como parte de las ribozimas . [147] Este antiguo mundo de ARN donde el ácido nucleico se habría utilizado tanto para la catálisis como para la genética puede haber influido en la evolución del código genético actual basado en cuatro bases de nucleótidos. Esto ocurriría, ya que el número de bases diferentes en un organismo de este tipo es una compensación entre un pequeño número de bases que aumenta la precisión de la replicación y un gran número de bases que aumenta la eficiencia catalítica de las ribozimas. [148] Sin embargo, no hay evidencia directa de sistemas genéticos antiguos, ya que la recuperación de ADN de la mayoría de los fósiles es imposible porque el ADN sobrevive en el medio ambiente durante menos de un millón de años y se degrada lentamente en fragmentos cortos en solución. [149] Se han hecho afirmaciones de ADN más antiguo, más notablemente un informe del aislamiento de una bacteria viable de un cristal de sal de 250 millones de años, [150] pero estas afirmaciones son controvertidas. [151] [152]
Los bloques de construcción del ADN ( adenina , guanina y moléculas orgánicas relacionadas ) pueden haberse formado extraterrestremente en el espacio exterior . [153] [154] [155] Los compuestos orgánicos complejos de ADN y ARN de la vida , incluidos el uracilo , la citosina y la timina , también se han formado en el laboratorio en condiciones que imitan las que se encuentran en el espacio exterior , utilizando sustancias químicas de partida, como la pirimidina , que se encuentra en meteoritos . La pirimidina, como los hidrocarburos aromáticos policíclicos (HAP), la sustancia química más rica en carbono que se encuentra en el universo , puede haberse formado en gigantes rojas o en nubes de polvo y gas cósmicos interestelares . [156]
Se ha recuperado ADN antiguo de organismos antiguos en una escala de tiempo en la que se puede observar directamente la evolución del genoma, incluso de organismos extintos de hasta millones de años de antigüedad, como el mamut lanudo . [157] [158]
Se han desarrollado métodos para purificar el ADN de los organismos, como la extracción con fenol-cloroformo , y para manipularlo en el laboratorio, como las digestaciones de restricción y la reacción en cadena de la polimerasa . La biología y la bioquímica modernas hacen un uso intensivo de estas técnicas en la tecnología del ADN recombinante. El ADN recombinante es una secuencia de ADN hecha por el hombre que se ha ensamblado a partir de otras secuencias de ADN. Se pueden transformar en organismos en forma de plásmidos o en el formato apropiado, utilizando un vector viral . [159] Los organismos modificados genéticamente producidos se pueden utilizar para producir productos como proteínas recombinantes , utilizadas en investigación médica , [160] o se pueden cultivar en agricultura . [161] [162]
Los científicos forenses pueden utilizar el ADN en la sangre , el semen , la piel , la saliva o el cabello encontrados en la escena de un crimen para identificar un ADN coincidente de un individuo, como un perpetrador. [163] Este proceso se denomina formalmente perfil de ADN , también llamado huella de ADN . En el perfil de ADN, las longitudes de secciones variables de ADN repetitivo, como repeticiones cortas en tándem y minisatélites , se comparan entre personas. Este método suele ser una técnica extremadamente confiable para identificar un ADN coincidente. [164] Sin embargo, la identificación puede ser complicada si la escena está contaminada con ADN de varias personas. [165] El perfil de ADN fue desarrollado en 1984 por el genetista británico Sir Alec Jeffreys , [166] y utilizado por primera vez en la ciencia forense para condenar a Colin Pitchfork en el caso de los asesinatos de Enderby de 1988. [167]
El desarrollo de la ciencia forense y la capacidad de obtener ahora coincidencias genéticas en muestras minúsculas de sangre, piel, saliva o cabello han llevado a reexaminar muchos casos. Ahora se pueden descubrir pruebas que eran científicamente imposibles en el momento del examen original. Combinado con la eliminación de la ley de doble enjuiciamiento en algunos lugares, esto puede permitir que se reabran casos en los que los juicios anteriores no han logrado producir pruebas suficientes para convencer a un jurado. A las personas acusadas de delitos graves se les puede exigir que proporcionen una muestra de ADN para fines de comparación. La defensa más obvia para las coincidencias de ADN obtenidas forensemente es alegar que se ha producido una contaminación cruzada de las pruebas. Esto ha dado lugar a procedimientos de manejo estrictos y meticulosos en los nuevos casos de delitos graves.
Los perfiles de ADN también se utilizan con éxito para identificar de forma positiva a víctimas de incidentes con víctimas en masa, [168] cadáveres o partes del cuerpo en accidentes graves y víctimas individuales en fosas de guerra masivas, mediante la comparación con miembros de la familia.
El perfil de ADN también se utiliza en las pruebas de paternidad de ADN para determinar si alguien es el padre o abuelo biológico de un niño; la probabilidad de paternidad suele ser del 99,99 % cuando el supuesto padre está biológicamente relacionado con el niño. Los métodos normales de secuenciación de ADN se realizan después del nacimiento, pero existen nuevos métodos para probar la paternidad mientras la madre todavía está embarazada. [169]
Las desoxirribozimas , también llamadas ADNzimas o ADN catalítico, se descubrieron por primera vez en 1994. [170] En su mayoría son secuencias de ADN monocatenarias aisladas de un gran grupo de secuencias de ADN aleatorias a través de un enfoque combinatorio llamado selección in vitro o evolución sistemática de ligandos por enriquecimiento exponencial (SELEX). Las ADNzimas catalizan una variedad de reacciones químicas, incluida la escisión de ARN-ADN, la ligación de ARN-ADN, la fosforilación-desfosforilación de aminoácidos, la formación de enlaces carbono-carbono, etc. Las ADNzimas pueden mejorar la tasa catalítica de las reacciones químicas hasta 100.000.000.000 de veces sobre la reacción no catalizada. [171] La clase de ADNzimas más ampliamente estudiada son los tipos de escisión de ARN que se han utilizado para detectar diferentes iones metálicos y diseñar agentes terapéuticos. Se han descrito varias ADNzimas específicas de metales, entre ellas la ADNzima GR-5 (específica del plomo), [170] las ADNzimas CA1-3 (específicas del cobre), [172] la ADNzima 39E (específica del uranilo) y la ADNzima NaA43 (específica del sodio). [173] La ADNzima NaA43, que se describe como más de 10 000 veces selectiva para el sodio sobre otros iones metálicos, se utilizó para crear un sensor de sodio en tiempo real en células.
La bioinformática implica el desarrollo de técnicas para almacenar, extraer datos , buscar y manipular datos biológicos, incluidos los datos de secuencias de ácidos nucleicos de ADN. Estos han llevado a avances ampliamente aplicados en la ciencia informática , especialmente algoritmos de búsqueda de cadenas , aprendizaje automático y teoría de bases de datos . [174] Los algoritmos de búsqueda o coincidencia de cadenas, que encuentran una ocurrencia de una secuencia de letras dentro de una secuencia más grande de letras, se desarrollaron para buscar secuencias específicas de nucleótidos. [175] La secuencia de ADN se puede alinear con otras secuencias de ADN para identificar secuencias homólogas y localizar las mutaciones específicas que las hacen distintas. Estas técnicas, especialmente la alineación de secuencias múltiples , se utilizan para estudiar las relaciones filogenéticas y la función de las proteínas. [176] Los conjuntos de datos que representan secuencias de ADN de genomas enteros, como los producidos por el Proyecto Genoma Humano , son difíciles de usar sin las anotaciones que identifican las ubicaciones de los genes y los elementos reguladores en cada cromosoma. Las regiones de la secuencia de ADN que tienen patrones característicos asociados con genes codificantes de proteínas o ARN se pueden identificar mediante algoritmos de búsqueda de genes , que permiten a los investigadores predecir la presencia de productos genéticos particulares y sus posibles funciones en un organismo incluso antes de que hayan sido aislados experimentalmente. [177] También se pueden comparar genomas completos, lo que puede arrojar luz sobre la historia evolutiva de un organismo particular y permitir el examen de eventos evolutivos complejos.

La nanotecnología del ADN utiliza las propiedades únicas de reconocimiento molecular del ADN y otros ácidos nucleicos para crear complejos de ADN ramificados autoensamblables con propiedades útiles. [179] Por lo tanto, el ADN se utiliza como material estructural en lugar de como portador de información biológica. Esto ha llevado a la creación de redes periódicas bidimensionales (tanto basadas en mosaicos como utilizando el método de origami de ADN ) y estructuras tridimensionales en forma de poliedros . [180] También se han demostrado dispositivos nanomecánicos y autoensamblaje algorítmico , [181] y estas estructuras de ADN se han utilizado para modelar la disposición de otras moléculas como nanopartículas de oro y proteínas estreptavidina . [182] El ADN y otros ácidos nucleicos son la base de los aptámeros , ligandos oligonucleótidos sintéticos para moléculas diana específicas utilizadas en una variedad de aplicaciones biotecnológicas y biomédicas. [183]
Debido a que el ADN recoge mutaciones a lo largo del tiempo, que luego se heredan, contiene información histórica y, al comparar secuencias de ADN, los genetistas pueden inferir la historia evolutiva de los organismos, su filogenia . [184] Este campo de la filogenética es una herramienta poderosa en la biología evolutiva . Si se comparan las secuencias de ADN dentro de una especie, los genetistas de poblaciones pueden aprender la historia de poblaciones particulares. Esto se puede utilizar en estudios que van desde la genética ecológica hasta la antropología .
El ADN como dispositivo de almacenamiento de información tiene un potencial enorme, ya que tiene una densidad de almacenamiento mucho mayor en comparación con los dispositivos electrónicos. Sin embargo, los altos costos, los tiempos de lectura y escritura lentos ( latencia de memoria ) y la confiabilidad insuficiente han impedido su uso práctico. [185] [186]

El ADN fue aislado por primera vez por el médico suizo Friedrich Miescher , quien, en 1869, descubrió una sustancia microscópica en el pus de vendajes quirúrgicos desechados. Como residía en los núcleos de las células, la llamó "nucleína". [187] [188] En 1878, Albrecht Kossel aisló el componente no proteico de la "nucleína", el ácido nucleico, y más tarde aisló sus cinco nucleobases primarias . [189] [190]
En 1909, Phoebus Levene identificó la unidad de nucleótidos de base, azúcar y fosfato del ARN (entonces llamado "ácido nucleico de levadura"). [191] [192] [193] En 1929, Levene identificó el azúcar desoxirribosa en el "ácido nucleico del timo" (ADN). [194] Levene sugirió que el ADN consistía en una cadena de cuatro unidades de nucleótidos unidas entre sí a través de los grupos fosfato ("hipótesis del tetranucleótido"). Levene pensó que la cadena era corta y las bases se repetían en un orden fijo. En 1927, Nikolai Koltsov propuso que los rasgos hereditarios se heredarían a través de una "molécula hereditaria gigante" compuesta de "dos cadenas espejo que se replicarían de manera semiconservativa utilizando cada cadena como plantilla". [195] [196] En 1928, Frederick Griffith en su experimento descubrió que los rasgos de la forma "lisa" de Pneumococcus podían transferirse a la forma "rugosa" de la misma bacteria mezclando bacterias "lisas" muertas con la forma "rugosa" viva. [197] [198] Este sistema proporcionó la primera sugerencia clara de que el ADN transporta información genética.
En 1933, mientras estudiaba los huevos de erizo de mar virgen , Jean Brachet sugirió que el ADN se encuentra en el núcleo celular y que el ARN está presente exclusivamente en el citoplasma . En ese momento, se pensaba que el "ácido nucleico de levadura" (ARN) se encontraba solo en plantas, mientras que el "ácido nucleico del timo" (ADN) solo en animales. Se pensaba que este último era un tetrámero, con la función de amortiguar el pH celular. [199] [200]
En 1937, William Astbury produjo los primeros patrones de difracción de rayos X que demostraron que el ADN tenía una estructura regular. [201]
En 1943, Oswald Avery , junto con sus colaboradores Colin MacLeod y Maclyn McCarty , identificaron al ADN como el principio transformante , apoyando la sugerencia de Griffith ( experimento de Avery-MacLeod-McCarty ). [202] Erwin Chargaff desarrolló y publicó observaciones ahora conocidas como reglas de Chargaff , que establecen que en el ADN de cualquier especie de cualquier organismo, la cantidad de guanina debe ser igual a la citosina y la cantidad de adenina debe ser igual a la timina . [203] [204]

A finales de 1951, Francis Crick comenzó a trabajar con James Watson en el Laboratorio Cavendish de la Universidad de Cambridge . El papel del ADN en la herencia se confirmó en 1952 cuando Alfred Hershey y Martha Chase, en el experimento Hershey-Chase, demostraron que el ADN es el material genético del fago enterobacteriano T2 . [205]
En mayo de 1952, Raymond Gosling , un estudiante de posgrado que trabajaba bajo la supervisión de Rosalind Franklin , tomó una imagen de difracción de rayos X , etiquetada como " Foto 51 ", [206] en altos niveles de hidratación del ADN. Esta foto fue entregada a Watson y Crick por Maurice Wilkins y fue fundamental para obtener la estructura correcta del ADN. Franklin le dijo a Crick y Watson que las cadenas principales tenían que estar en el exterior. Antes de eso, Linus Pauling, y Watson y Crick, tenían modelos erróneos con las cadenas en el interior y las bases apuntando hacia afuera. La identificación de Franklin del grupo espacial para los cristales de ADN reveló a Crick que las dos cadenas de ADN eran antiparalelas . [207] En febrero de 1953, Linus Pauling y Robert Corey propusieron un modelo para los ácidos nucleicos que contenía tres cadenas entrelazadas, con los fosfatos cerca del eje y las bases en el exterior. [208] Watson y Crick completaron su modelo, que ahora se acepta como el primer modelo correcto de la doble hélice del ADN . El 28 de febrero de 1953, Crick interrumpió la hora del almuerzo en el pub The Eagle en Cambridge, Inglaterra, para anunciar que él y Watson habían "descubierto el secreto de la vida". [209]
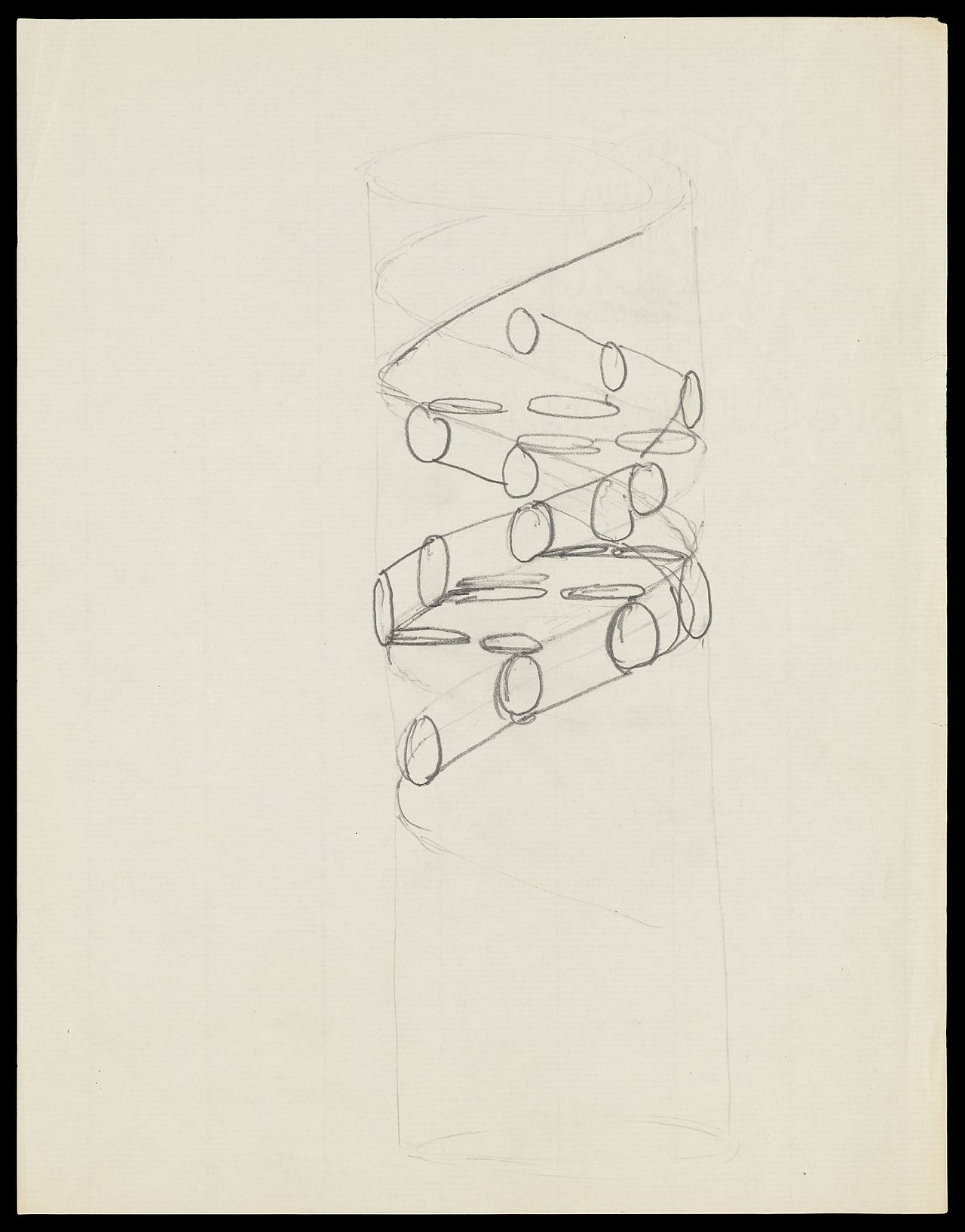
El número del 25 de abril de 1953 de la revista Nature publicó una serie de cinco artículos que presentaban la estructura de doble hélice del ADN de Watson y Crick y evidencia que la respaldaba. [210] La estructura se informó en una carta titulada " ESTRUCTURA MOLECULAR DE LOS ÁCIDOS NUCLEICOS Una estructura para el ácido nucleico desoxirribonucleico " , en la que decían: "No se nos ha escapado que el apareamiento específico que hemos postulado sugiere inmediatamente un posible mecanismo de copia para el material genético". [9] Esta carta fue seguida por una carta de Franklin y Gosling, que fue la primera publicación de sus propios datos de difracción de rayos X y de su método de análisis original. [48] [211] Luego siguió una carta de Wilkins y dos de sus colegas, que contenía un análisis de patrones de rayos X de ADN-B in vivo , y que respaldaba la presencia in vivo de la estructura de Watson y Crick. [49]
En abril de 2023, los científicos, basándose en nuevas evidencias, concluyeron que Rosalind Franklin fue una colaboradora y un "actor igualitario" en el proceso de descubrimiento del ADN, y no lo contrario, como pudo haberse presentado posteriormente después del momento del descubrimiento. [212] [213] [214]
En 1962, tras la muerte de Franklin, Watson, Crick y Wilkins recibieron conjuntamente el Premio Nobel de Fisiología o Medicina . [215] Los premios Nobel se otorgan únicamente a los destinatarios vivos. Sigue existiendo un debate sobre a quién se le debe atribuir el descubrimiento. [216]
En una influyente presentación en 1957, Crick expuso el dogma central de la biología molecular , que predijo la relación entre el ADN, el ARN y las proteínas, y articuló la "hipótesis del adaptador". [217] La confirmación final del mecanismo de replicación que estaba implícito en la estructura de doble hélice siguió en 1958 a través del experimento de Meselson-Stahl . [218] El trabajo posterior de Crick y sus colaboradores mostró que el código genético se basaba en tripletes de bases no superpuestos, llamados codones , lo que permitió a Har Gobind Khorana , Robert W. Holley y Marshall Warren Nirenberg descifrar el código genético. [219] Estos hallazgos representan el nacimiento de la biología molecular . [220]
En 1986, el análisis de ADN se utilizó por primera vez con fines de investigación criminal cuando la policía del Reino Unido solicitó a Alec Jeffreys, de la Universidad de Leicester, que verificara o refutara la "confesión" de un sospechoso de violación y asesinato. En este caso en particular, el sospechoso había confesado dos violaciones y asesinatos, pero luego se había retractado de su confesión. Las pruebas de ADN realizadas en los laboratorios de la universidad pronto desmintieron la veracidad de la "confesión" original del sospechoso, y el sospechoso fue exonerado de los cargos de asesinato y violación. [221]
Si viviéramos lo suficiente, tarde o temprano todos tendríamos cáncer.
fondo irreducible del cáncer independientemente de las circunstancias: las mutaciones nunca se pueden evitar por completo, porque son una consecuencia ineludible de las limitaciones fundamentales en la precisión de la replicación del ADN, como se analiza en el Capítulo 5. Si un ser humano pudiera vivir lo suficiente, es inevitable que al menos una de sus células eventualmente acumulara un conjunto de mutaciones suficientes para que se desarrollara el cáncer.
[pag. 456]
Ich habe mich daher später mit meinen Versuchen an die ganzen Kerne gehalten, die Trennung der Körper, die ich einstweilen ohne weiteres Präjudiz als lösliches und unlösliches Nuclein bezeichnen will, einem günstigeren Material überlassend.
(Por lo tanto, en mis experimentos me limité posteriormente al núcleo entero, dejando a un material más favorable la separación de las sustancias, que por el momento, sin mayor prejuicio, designaré como material nuclear soluble e insoluble ("Nucleína"). )
En la pág. 264, Kossel observó proféticamente: Der Erforschung der quantum Verhältnisse der vier stickstoffreichen Basen, der Abhängigkeit ihrer Menge von den psychologischen Zuständen der Zelle, verspricht wichtige Aufschlüsse über die elementaren psychologisch-chemischen Vorgänge. (El estudio de las relaciones cuantitativas de las cuatro bases nitrogenadas —[y] de la dependencia de su cantidad de los estados fisiológicos de la célula—promete importantes conocimientos sobre los procesos fisiológico-químicos fundamentales.)
De la página 313: "Creo que el tamaño de los cromosomas en las glándulas salivales [de Drosophila] está determinado por la multiplicación de
genonemas
. Con este término designo el hilo axial del cromosoma, en el que los genetistas ubican la combinación lineal de genes; … En el cromosoma normal normalmente hay un solo genoma; antes de la división celular, este genoma se ha dividido en dos hebras".
{kind=link}
{kind=link}