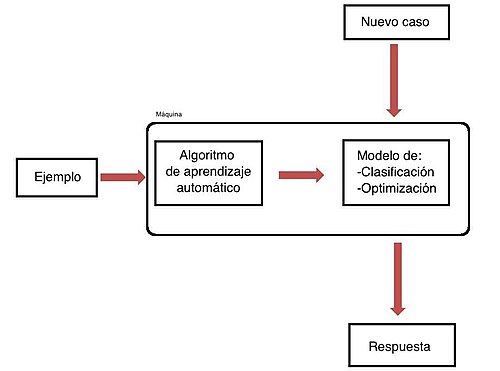
[2] "En el aprendizaje de máquinas un computador observa datos, construye un modelo basado en esos datos y utiliza ese modelo a la vez como una hipótesis acerca del mundo y una pieza de software que puede resolver problemas".Sin embargo, las computadoras son utilizadas por todo el mundo con fines tecnológicos muy buenos.Los segundos, como su nombre lo indican, representan un gradiente en el que se puede diferenciar entre cada instancia.Los algoritmos genéticos son procesos de búsqueda heurística que simulan la selección natural.Usan métodos tales como la mutación y el cruzamiento para generar nuevas clases que puedan ofrecer una buena solución a un problema dado.Dados ciertos síntomas, la red puede usarse para calcular las probabilidades de que ciertas enfermedades estén presentes en un organismo.Hay algoritmos eficientes que infieren y aprenden usando este tipo de representación.Un ejemplo podría ser un software que reconoce si una imagen dada es o no la imagen de un rostro: para el aprendizaje del programa tendríamos que proporcionarle diferentes imágenes, especificando en el proceso si se trata o no de rostros.La información obtenida por un algoritmo de aprendizaje no supervisado debe ser posteriormente interpretada por una persona para darle utilidad.Ya en los primeros días de la IA como disciplina académica, algunos investigadores se interesaron en hacer que las máquinas aprendiesen.Trataron de resolver el problema con diversos métodos simbólicos, así como lo que ellos llamaron 'redes neurales' que eran en general perceptrones y otros modelos básicamente basados en modelos lineares generalizados como se conocen en las estadísticas.[11] R es muy usado ante todo en el campo académico, mientras que Python es más popular en la empresa privada.De hecho, cuando la formación se realiza con datos clasificados por el ser humano el aprendizaje automático tiende a crear los mismos sesgos que hay en la sociedad.Es una herramienta muy poderosa que tan solo hemos comenzado a entender, y esa es una gran responsabilidad" [12]