Red neuronal residual
Se comporta como una Highway Network (Autopista de la información)[2] cuyas puertas se abren mediante pesos de sesgo fuertemente positivo.
Esto permite que los modelos de aprendizaje profundo con decenas o cientos de capas se entrenen fácilmente y se aproximen a una mayor precisión al profundizar.
Las conexiones de salto de identidad, a menudo denominadas "conexiones residuales", también se utilizan en las redes LSTM (memoria a corto-largo plazo) de 1997,[3] los modelos de transformador (por ejemplo, BERT, modelos GPT como ChatGPT), el sistema AlphaGo Zero, el sistema AlphaStar y el sistema AlphaFold.
Las redes residuales fueron desarrolladas por Kaiming He, Xiangyu Zhang, Shaoqing Ren y Jian Sun, que ganaron el concurso ImageNet 2015.
[4][5] El modelo AlexNet desarrollado en 2012 para ImageNet era una red neuronal convolucional de 8 capas.
[6] Pero apilar más capas provocó una rápida reducción de la precisión del entrenamiento,[7] lo que se conoce como el problema de la "degradación".
[1] Si las capas adicionales pueden establecerse como mapeos de identidad, la red más profunda representaría la misma función que la homóloga menos profunda.
-ésimo (es decir, suponiendo que no hay función de activación entre bloques), tenemos:[9]
de acuerdo con la propagación hacia adelante anterior, tenemos:[9] Aquí
Esta formulación sugiere que el cálculo del gradiente de una capa menos profunda
La primera capa de este bloque es una convolución 1x1 para reducir la dimensión, por ejemplo, a 1/4 de la dimensión de entrada; la segunda capa realiza una convolución 3x3; la última capa es otra convolución 1x1 para restaurar la dimensión.
Este diseño reduce el número de mapeos no identitarios entre bloques residuales.
Este diseño se utilizó para entrenar modelos con 200 a más de 1000 capas.
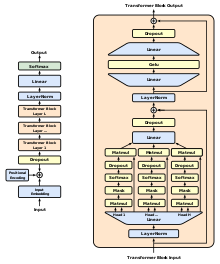
Esto se denomina a menudo "prenormalización" en la literatura de los modelos transformador.
Un bloque transformador tiene una profundidad de 4 capas (proyecciones lineales).
Los modelos transformador muy profundos no pueden entrenarse con éxito sin conexiones residuales.
En dos libros publicados en 1994[13] y 1996,[14] se presentaron las conexiones "skip-layer" (salto de capa) en los modelos MLP feed-forward: "La definición general [de MLP] permite más de una capa oculta, y también permite conexiones skip-layer desde la entrada a la salida" (p261 en,[13] p144 en[14]), "... lo que permite a las unidades no lineales perturbar una forma funcional lineal" (p262 en[13]).
Sepp Hochreiter analizó el problema del gradiente evanescente en 1991 y le atribuyó la razón por la que el aprendizaje profundo no funcionaba bien.
.Durante la retropropagación a través del tiempo, esto se convierte en la fórmula residual antes mencionada
Esto permite entrenar redes neuronales recurrentes muy profundas con un intervalo de tiempo t muy largo.
Se dice que es "la primera red feedforward muy profunda con cientos de capas".
[18] Es como una LSTM con puertas de olvido desplegadas en el tiempo,[16] mientras que las redes residuales posteriores no tienen puertas de olvido equivalentes y son como la LSTM original desplegada.
El artículo original Highway Network[2] no sólo introdujo el principio básico de las redes feedforward muy profundas, sino que también incluyó resultados experimentales con redes de 20, 50 y 100 capas, y mencionó experimentos en curso con hasta 900 capas.
Argumentaba que el mapeo de identidad sin modulación es crucial y mencionaba que la modulación en la conexión de salto puede llevar a señales de fuga en la propagación hacia delante y hacia atrás (Sección 3 en[9]).
Del mismo modo, una Highway Net cuyas puertas se abren mediante pesos de sesgo fuertemente positivos se comporta como una ResNet.
Las DenseNets de 2016[19] se diseñaron como redes neuronales profundas que intentan conectar cada capa con todas las demás.
También conocido como "DropPath", se trata de un método de regularización eficaz para entrenar modelos grandes y profundos, como el Vision Transformer (ViT).
En el artículo original sobre las redes residuales no se afirmaba que estuvieran inspiradas en sistemas biológicos.
Pero investigaciones posteriores han relacionado las redes residuales con algoritmos biológicamente plausibles.
Este estudio descubrió "atajos multicapa" a los que se asemejan las conexiones de salto de las redes neuronales artificiales, incluidas las ResNets.