En teoría de probabilidad y estadística , una distribución de probabilidad es la función matemática que da las probabilidades de ocurrencia de posibles resultados para un experimento . [1] [2] Es una descripción matemática de un fenómeno aleatorio en términos de su espacio muestral y las probabilidades de eventos ( subconjuntos del espacio muestral). [3]
Por ejemplo, si se utiliza X para indicar el resultado de un lanzamiento de moneda ("el experimento"), entonces la distribución de probabilidad de X tomaría el valor 0,5 (1 en 2 o 1/2) para X = cara y 0,5 para X = cruz (suponiendo que la moneda es justa ). Más comúnmente, las distribuciones de probabilidad se utilizan para comparar la ocurrencia relativa de muchos valores aleatorios diferentes.
Las distribuciones de probabilidad se pueden definir de distintas maneras y para variables discretas o continuas. Las distribuciones con propiedades especiales o para aplicaciones especialmente importantes reciben nombres específicos.
Una distribución de probabilidad es una descripción matemática de las probabilidades de eventos, subconjuntos del espacio muestral . El espacio muestral, a menudo representado en notación por, es el conjunto de todos los resultados posibles de un fenómeno aleatorio que se observa. El espacio muestral puede ser cualquier conjunto: un conjunto de números reales , un conjunto de etiquetas descriptivas, un conjunto de vectores , un conjunto de valores no numéricos arbitrarios, etc. Por ejemplo, el espacio muestral de un lanzamiento de moneda podría ser Ω = { "cara", "cruz" } .
Para definir distribuciones de probabilidad para el caso específico de variables aleatorias (para que el espacio muestral pueda verse como un conjunto numérico), es común distinguir entre variables aleatorias discretas y absolutamente continuas . En el caso discreto, es suficiente especificar una función de masa de probabilidad que asigne una probabilidad a cada resultado posible (por ejemplo, al lanzar un dado justo , cada uno de los seis dígitos “1” a “6” , correspondientes al número de puntos del dado, tiene la probabilidad La probabilidad de un evento se define entonces como la suma de las probabilidades de todos los resultados que satisfacen el evento; por ejemplo, la probabilidad del evento "el dado sale con un valor par" es
Por el contrario, cuando una variable aleatoria toma valores de un continuo, por convención, a cualquier resultado individual se le asigna una probabilidad de cero. Para tales variables aleatorias continuas , solo los eventos que incluyen una cantidad infinita de resultados, como los intervalos, tienen una probabilidad mayor que cero.
Por ejemplo, si se mide el peso de un trozo de jamón en el supermercado y se supone que la báscula puede proporcionar una cantidad arbitraria de dígitos de precisión, la probabilidad de que pese exactamente 500 g debe ser cero, ya que, independientemente de lo alto que sea el nivel de precisión elegido, no se puede suponer que no haya dígitos decimales distintos de cero en los dígitos omitidos restantes que el nivel de precisión ignora.
Sin embargo, para el mismo caso de uso, es posible cumplir con requisitos de control de calidad como que un paquete de "500 g" de jamón debe pesar entre 490 g y 510 g con al menos un 98% de probabilidad. Esto es posible porque esta medición no requiere tanta precisión del equipo subyacente.

Las distribuciones de probabilidad absolutamente continuas se pueden describir de varias maneras. La función de densidad de probabilidad describe la probabilidad infinitesimal de cualquier valor dado, y la probabilidad de que el resultado se encuentre en un intervalo dado se puede calcular integrando la función de densidad de probabilidad sobre ese intervalo. [4] Una descripción alternativa de la distribución es mediante la función de distribución acumulativa , que describe la probabilidad de que la variable aleatoria no sea mayor que un valor dado (es decir, para algún ). La función de distribución acumulativa es el área bajo la función de densidad de probabilidad de a como se muestra en la figura 1. [5]
Una distribución de probabilidad se puede describir de varias formas, como por ejemplo mediante una función de masa de probabilidad o una función de distribución acumulativa. Una de las descripciones más generales, que se aplica a variables absolutamente continuas y discretas, es mediante una función de probabilidad cuyo espacio de entrada es una σ-álgebra y da como salida la probabilidad de un número real , en particular, un número en .
La función de probabilidad puede tomar como argumento subconjuntos del propio espacio muestral, como en el ejemplo del lanzamiento de una moneda, donde la función se definió de forma que P (cara) = 0,5 y P (cruz) = 0,5 . Sin embargo, debido al uso generalizado de variables aleatorias , que transforman el espacio muestral en un conjunto de números (p. ej., , ), es más común estudiar distribuciones de probabilidad cuyo argumento son subconjuntos de estos tipos particulares de conjuntos (conjuntos de números), [6] y todas las distribuciones de probabilidad analizadas en este artículo son de este tipo. Es común denotar como la probabilidad de que un determinado valor de la variable pertenezca a un determinado evento . [7] [8]
La función de probabilidad anterior solo caracteriza una distribución de probabilidad si satisface todos los axiomas de Kolmogorov , es decir:
El concepto de función de probabilidad se hace más riguroso al definirlo como el elemento de un espacio de probabilidad , donde es el conjunto de resultados posibles, es el conjunto de todos los subconjuntos cuya probabilidad puede medirse, y es la función de probabilidad, o medida de probabilidad , que asigna una probabilidad a cada uno de estos subconjuntos medibles . [9]
Las distribuciones de probabilidad suelen pertenecer a una de dos clases. Una distribución de probabilidad discreta es aplicable a los escenarios en los que el conjunto de resultados posibles es discreto (por ejemplo, un lanzamiento de moneda, una tirada de dados) y las probabilidades están codificadas por una lista discreta de las probabilidades de los resultados; en este caso, la distribución de probabilidad discreta se conoce como función de masa de probabilidad . Por otro lado, las distribuciones de probabilidad absolutamente continuas son aplicables a escenarios en los que el conjunto de resultados posibles puede tomar valores en un rango continuo (por ejemplo, números reales), como la temperatura en un día determinado. En el caso absolutamente continuo, las probabilidades se describen mediante una función de densidad de probabilidad , y la distribución de probabilidad es, por definición, la integral de la función de densidad de probabilidad. [7] [4] [8] La distribución normal es una distribución de probabilidad absolutamente continua que se encuentra comúnmente. Los experimentos más complejos, como los que involucran procesos estocásticos definidos en tiempo continuo , pueden exigir el uso de medidas de probabilidad más generales .
Una distribución de probabilidad cuyo espacio muestral es unidimensional (por ejemplo, números reales, lista de etiquetas, etiquetas ordenadas o binaria) se denomina univariante , mientras que una distribución cuyo espacio muestral es un espacio vectorial de dimensión 2 o más se denomina multivariante . Una distribución univariante da las probabilidades de que una única variable aleatoria adopte varios valores diferentes; una distribución multivariante (una distribución de probabilidad conjunta ) da las probabilidades de que un vector aleatorio (una lista de dos o más variables aleatorias) adopte varias combinaciones de valores. Las distribuciones de probabilidad univariante importantes y de uso común incluyen la distribución binomial , la distribución hipergeométrica y la distribución normal . Una distribución multivariante de uso común es la distribución normal multivariante .
Además de la función de probabilidad, la función de distribución acumulativa, la función de masa de probabilidad y la función de densidad de probabilidad, la función generadora de momentos y la función característica también sirven para identificar una distribución de probabilidad, ya que determinan de forma única una función de distribución acumulativa subyacente. [10]

A continuación se enumeran algunos conceptos y términos clave, ampliamente utilizados en la literatura sobre el tema de las distribuciones de probabilidad. [1]
En el caso especial de una variable aleatoria de valor real, la distribución de probabilidad se puede representar de manera equivalente mediante una función de distribución acumulativa en lugar de una medida de probabilidad. La función de distribución acumulativa de una variable aleatoria con respecto a una distribución de probabilidad se define como
La función de distribución acumulativa de cualquier variable aleatoria de valor real tiene las propiedades:
Por el contrario, cualquier función que satisfaga las primeras cuatro propiedades anteriores es la función de distribución acumulativa de alguna distribución de probabilidad en los números reales. [13]
Cualquier distribución de probabilidad puede descomponerse como la mezcla de una distribución discreta , una absolutamente continua y una continua singular , [14] y por lo tanto cualquier función de distribución acumulativa admite una descomposición como la suma convexa de las tres funciones de distribución acumulativa correspondientes.
.svg/1280px-Dice_Distribution_(bar).svg.png)



Una distribución de probabilidad discreta es la distribución de probabilidad de una variable aleatoria que puede tomar solo un número contable de valores [15] ( casi con seguridad ) [16] lo que significa que la probabilidad de cualquier evento puede expresarse como una suma (finita o infinita contable ): donde es un conjunto contable con . Por lo tanto, las variables aleatorias discretas (es decir, variables aleatorias cuya distribución de probabilidad es discreta) son exactamente aquellas con una función de masa de probabilidad . En el caso en que el rango de valores sea infinito contable, estos valores tienen que disminuir a cero lo suficientemente rápido para que las probabilidades sumen 1. Por ejemplo, si para , la suma de probabilidades sería .
Las distribuciones de probabilidad discretas más conocidas que se utilizan en el modelado estadístico incluyen la distribución de Poisson , la distribución de Bernoulli , la distribución binomial , la distribución geométrica , la distribución binomial negativa y la distribución categórica . [3] Cuando se extrae una muestra (un conjunto de observaciones) de una población más grande, los puntos de muestra tienen una distribución empírica que es discreta y que proporciona información sobre la distribución de la población. Además, la distribución uniforme discreta se utiliza comúnmente en programas informáticos que realizan selecciones aleatorias de probabilidad igual entre una serie de opciones.
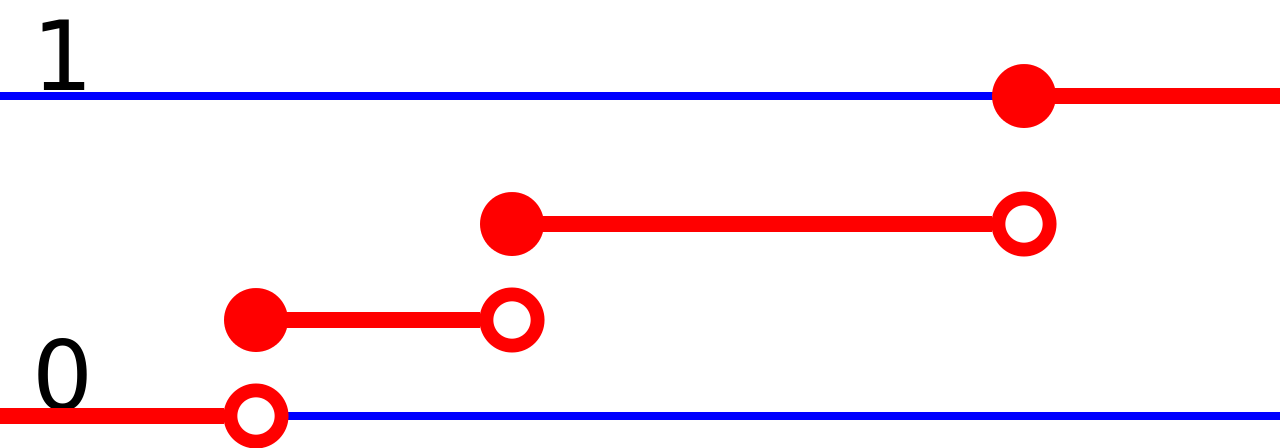
Una variable aleatoria discreta de valor real puede definirse de manera equivalente como una variable aleatoria cuya función de distribución acumulativa aumenta solo por discontinuidades de saltos , es decir, su función de distribución acumulativa aumenta solo donde "salta" a un valor más alto y es constante en intervalos sin saltos. Los puntos donde ocurren los saltos son precisamente los valores que puede tomar la variable aleatoria. Por lo tanto, la función de distribución acumulativa tiene la forma
Los puntos donde salta la función de distribución continua siempre forman un conjunto contable; éste puede ser cualquier conjunto contable y por lo tanto puede incluso ser denso en los números reales.
Una distribución de probabilidad discreta se representa a menudo con medidas de Dirac , las distribuciones de probabilidad de variables aleatorias deterministas . Para cualquier resultado , sea la medida de Dirac concentrada en . Dada una distribución de probabilidad discreta, existe un conjunto numerable con y una función de masa de probabilidad . Si es cualquier evento, entonces o en resumen,
De manera similar, las distribuciones discretas se pueden representar con la función delta de Dirac como una función de densidad de probabilidad generalizada , donde lo que significa para cualquier evento [17]
Para una variable aleatoria discreta , sean los valores que puede tomar con probabilidad distinta de cero. Denote
Estos son conjuntos disjuntos , y para tales conjuntos
De ello se deduce que la probabilidad de que tome cualquier valor excepto es cero, y por lo tanto se puede escribir como
excepto en un conjunto de probabilidad cero, donde es la función indicadora de . Esto puede servir como una definición alternativa de variables aleatorias discretas.
Un caso especial es la distribución discreta de una variable aleatoria que puede tomar solo un valor fijo; en otras palabras, es una distribución determinista . Expresada formalmente, la variable aleatoria tiene una distribución de un punto si tiene un resultado posible tal que [18] Todos los demás resultados posibles tienen entonces una probabilidad de 0. Su función de distribución acumulativa salta inmediatamente de 0 a 1.
Una distribución de probabilidad absolutamente continua es una distribución de probabilidad sobre los números reales con un número incontable de valores posibles, como un intervalo entero en la recta real, y donde la probabilidad de cualquier evento puede expresarse como una integral. [19] Más precisamente, una variable aleatoria real tiene una distribución de probabilidad absolutamente continua si hay una función tal que para cada intervalo la probabilidad de pertenecer a está dada por la integral de sobre : [20] [21] Esta es la definición de una función de densidad de probabilidad , de modo que las distribuciones de probabilidad absolutamente continuas son exactamente aquellas con una función de densidad de probabilidad. En particular, la probabilidad de que tome cualquier valor único (es decir, ) es cero, porque una integral con límites superior e inferior coincidentes siempre es igual a cero. Si el intervalo se reemplaza por cualquier conjunto medible , la igualdad correspondiente aún se mantiene:
Una variable aleatoria absolutamente continua es una variable aleatoria cuya distribución de probabilidad es absolutamente continua.
Hay muchos ejemplos de distribuciones de probabilidad absolutamente continuas: normal , uniforme , chi-cuadrado y otras .
Las distribuciones de probabilidad absolutamente continuas, como se definieron anteriormente, son precisamente aquellas que tienen una función de distribución acumulativa absolutamente continua . En este caso, la función de distribución acumulativa tiene la forma donde es una densidad de la variable aleatoria con respecto a la distribución .
Nota sobre la terminología: Las distribuciones absolutamente continuas deben distinguirse de las distribuciones continuas , que son aquellas que tienen una función de distribución acumulativa continua. Toda distribución absolutamente continua es una distribución continua pero la inversa no es cierta, existen distribuciones singulares , que no son ni absolutamente continuas ni discretas ni una mezcla de ellas, y no tienen densidad. Un ejemplo lo da la distribución de Cantor . Sin embargo, algunos autores utilizan el término "distribución continua" para denotar todas las distribuciones cuya función de distribución acumulativa es absolutamente continua , es decir, se refieren a las distribuciones absolutamente continuas como distribuciones continuas. [7]
Para una definición más general de las funciones de densidad y las medidas absolutamente continuas equivalentes, consulte medida absolutamente continua .
En la formalización de la teoría de la medida de la teoría de la probabilidad , una variable aleatoria se define como una función medible de un espacio de probabilidad a un espacio medible . Dado que las probabilidades de eventos de la forma satisfacen los axiomas de probabilidad de Kolmogorov , la distribución de probabilidad de es la medida de imagen de , que es una medida de probabilidad al satisfacer . [22] [23] [24]

Las distribuciones absolutamente continuas y discretas con soporte en o son extremadamente útiles para modelar una miríada de fenómenos, [7] [5] ya que la mayoría de las distribuciones prácticas se apoyan en subconjuntos relativamente simples, como hipercubos o bolas . Sin embargo, este no es siempre el caso, y existen fenómenos con soportes que en realidad son curvas complicadas dentro de algún espacio o similares. En estos casos, la distribución de probabilidad se apoya en la imagen de dicha curva, y es probable que se determine empíricamente, en lugar de encontrar una fórmula cerrada para ella. [25]
Un ejemplo se muestra en la figura de la derecha, que muestra la evolución de un sistema de ecuaciones diferenciales (comúnmente conocidas como ecuaciones de Rabinovich-Fabrikant ) que se pueden utilizar para modelar el comportamiento de las ondas de Langmuir en el plasma . [26] Cuando se estudia este fenómeno, los estados observados del subconjunto son los indicados en rojo. Por lo tanto, uno podría preguntarse cuál es la probabilidad de observar un estado en una determinada posición del subconjunto rojo; si existe tal probabilidad, se denomina medida de probabilidad del sistema. [27] [25]
Este tipo de soporte complicado aparece con bastante frecuencia en sistemas dinámicos . No es sencillo establecer que el sistema tiene una medida de probabilidad, y el problema principal es el siguiente. Sean instantes en el tiempo y un subconjunto del soporte; si la medida de probabilidad existe para el sistema, se esperaría que la frecuencia de los estados observables dentro del conjunto fuera igual en el intervalo y , lo que podría no suceder; por ejemplo, podría oscilar de manera similar a un seno, , cuyo límite cuando no converge. Formalmente, la medida existe solo si el límite de la frecuencia relativa converge cuando el sistema se observa en el futuro infinito. [28] La rama de los sistemas dinámicos que estudia la existencia de una medida de probabilidad es la teoría ergódica .
Obsérvese que incluso en estos casos, la distribución de probabilidad, si existe, todavía podría denominarse "absolutamente continua" o "discreta" dependiendo de si el soporte es incontable o contable, respectivamente.
La mayoría de los algoritmos se basan en un generador de números pseudoaleatorios que produce números que se distribuyen uniformemente en el intervalo semiabierto [0, 1) . Estas variables aleatorias se transforman luego mediante algún algoritmo para crear una nueva variable aleatoria que tenga la distribución de probabilidad requerida. Con esta fuente de pseudoaleatoriedad uniforme, se pueden generar realizaciones de cualquier variable aleatoria. [29]
Por ejemplo, supongamos que tiene una distribución uniforme entre 0 y 1. Para construir una variable aleatoria de Bernoulli para algún , definimos de modo que
Esta variable aleatoria X tiene una distribución de Bernoulli con parámetro . [29] Esta es una transformación de una variable aleatoria discreta.
Para una función de distribución de una variable aleatoria absolutamente continua, se debe construir una variable aleatoria absolutamente continua. , una función inversa de , se relaciona con la variable uniforme :
Por ejemplo, supongamos que se debe construir una variable aleatoria que tiene una distribución exponencial .
Entonces , si y tiene una distribución, entonces la variable aleatoria está definida por . Esta tiene una distribución exponencial de . [29]
Un problema frecuente en las simulaciones estadísticas (el método de Monte Carlo ) es la generación de números pseudoaleatorios que se distribuyen de una manera determinada.
El concepto de distribución de probabilidad y las variables aleatorias que describen subyacen a la disciplina matemática de la teoría de la probabilidad y a la ciencia de la estadística. Existe dispersión o variabilidad en casi cualquier valor que pueda medirse en una población (por ejemplo, la altura de las personas, la durabilidad de un metal, el crecimiento de las ventas, el flujo de tráfico, etc.); casi todas las mediciones se realizan con algún error intrínseco; en física, muchos procesos se describen de forma probabilística, desde las propiedades cinéticas de los gases hasta la descripción mecánico-cuántica de las partículas fundamentales . Por estas y muchas otras razones, los números simples a menudo son inadecuados para describir una cantidad, mientras que las distribuciones de probabilidad suelen ser más apropiadas.
A continuación se incluye una lista de algunas de las distribuciones de probabilidad más comunes, agrupadas por el tipo de proceso con el que están relacionadas. Para obtener una lista más completa, consulte la lista de distribuciones de probabilidad , que se agrupa por la naturaleza del resultado que se considera (discreto, absolutamente continuo, multivariado, etc.).
Todas las distribuciones univariadas que se muestran a continuación tienen un único pico, es decir, se supone que los valores se agrupan en torno a un único punto. En la práctica, las cantidades realmente observadas pueden agruparse en torno a múltiples valores. Dichas cantidades se pueden modelar utilizando una distribución mixta .
El ajuste de distribución de probabilidad o simplemente ajuste de distribución es el ajuste de una distribución de probabilidad a una serie de datos relativos a la medición repetida de un fenómeno variable. El objetivo del ajuste de distribución es predecir la probabilidad o pronosticar la frecuencia de ocurrencia de la magnitud del fenómeno en un intervalo determinado.
Existen muchas distribuciones de probabilidad (véase la lista de distribuciones de probabilidad ) de las cuales algunas pueden ajustarse mejor que otras a la frecuencia observada de los datos, dependiendo de las características del fenómeno y de la distribución. Se supone que la distribución que se ajusta mejor a la frecuencia permite realizar buenas predicciones.
Por lo tanto, al ajustar la distribución es necesario seleccionar una distribución que se adapte bien a los datos.{{cite book}}: CS1 maint: numeric names: authors list (link){{cite book}}: CS1 maint: multiple names: authors list (link){{cite book}}: CS1 maint: location missing publisher (link){{cite book}}: CS1 maint: location missing publisher (link)









![{\displaystyle [0,1]\subseteq \mathbb {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/042e529c93e86b5d03b1e1cd6ddcc50e89761c03)
























































![{\displaystyle f:\mathbb {R} \to [0,\infty ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f8544ec4fd60d201e49cacb3afd640e760798489)
![{\displaystyle I=[a,b]\subconjunto \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/1cad8a9865c17ed0c40a9e3f5eb3fe4a18df765e)




![{\estilo de visualización [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c4b788fc5c637e26ee98b45f89a5c08c85f7935)










![{\displaystyle \gamma :[a,b]\rightarrow \mathbb {R} ^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58e103c376cd9ea50b5c12c8f5398ded4d2a3577)



![{\estilo de visualización [t_{1},t_{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e35e13fa8221f864808f15cafa3d1467b5d78ce)
![{\estilo de visualización [t_{2},t_{3}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/82eae695d40fda9d1b713787d35efa48d9a95478)









![{\displaystyle {\begin{aligned}F(x)=u&\Leftrightarrow 1-e^{-\lambda x}=u\\[2pt]&\Leftrightarrow e^{-\lambda x}=1-u\\[2pt]&\Leftrightarrow -\lambda x=\ln(1-u)\\[2pt]&\Leftrightarrow x={\frac {-1}{\lambda }}\ln(1-u)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fb889e8427ec79417200e4c016790ef0d20c446)




