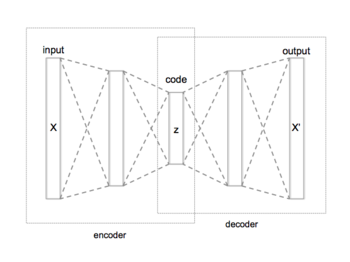
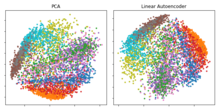Autocodificador
El autocodificador aprende una representación eficiente (codificación) para un conjunto de datos, normalmente para reducir la dimensionalidad.
[3] Algunos ejemplos son los autocodificadores regularizados (Sparse, Denoising y Contractive), que son eficaces en el aprendizaje de representaciones para tareas de clasificación posteriores,[4] y los autocodificadores variacionales, con aplicaciones como modelos generativos.
La búsqueda del autocodificador óptimo puede llevarse a cabo mediante cualquier técnica matemática de optimización, pero normalmente es realizado mediante el descenso de gradiente.
Este proceso de búsqueda se denomina "entrenamiento del autocodificador".
[1][10] En el límite de un autocodificador incompleto ideal, cada código posible
Este autocodificador ideal puede utilizarse para generar mensajes indistinguibles de los reales, alimentando su decodificador con código arbitrario
tiene una dimensión mayor (sobrecompleta) o igual al espacio de mensajes
, o las unidades ocultas tienen suficiente capacidad, un autocodificador puede aprender la función de identidad y volverse inútil.
Sin embargo, los resultados experimentales han demostrado que los autocodificadores sobrecompletos pueden aprender características útiles.
Una forma estándar de hacerlo es añadir modificaciones al autocodificador básico, que se detallarán a continuación.
[3] El autocodificador fue propuesto por primera vez por Kramer como una generalización no lineal del análisis de componentes principales (ACP) .
[18] Existen varias técnicas para evitar que los autocodificadores aprendan la función de identidad y para mejorar su capacidad de captar información importante y aprender representaciones más ricas.
Los autocodificadores dispersos pueden incluir más (en lugar de menos) unidades ocultas que entradas, pero sólo se permite que un pequeño número de unidades ocultas estén activas al mismo tiempo.
Una consiste simplemente en fijar en cero todas las activaciones del código latente excepto las k más altas.
El autocodificador concreto está diseñado para la selección de características discretas.
[25] Un autocodificador concreto fuerza al espacio latente a consistir sólo en un número de características especificado por el usuario.
A pesar de las similitudes arquitectónicas con los autocodificadores básicos, los VAE son arquitecturas con objetivos diferentes y con una formulación matemática completamente distinta.
Su método consiste en tratar cada conjunto vecino de dos capas como una máquina de Boltzmann restringida para que el pre-entrenamiento se aproxime a una buena solución y, a continuación, utilizar la retropropagación para afinar los resultados.
[10] Los investigadores han debatido si el entrenamiento conjunto (es decir, el entrenamiento de toda la arquitectura junto con un único objetivo de reconstrucción global para optimizar) sería mejor para los autocodificadores profundos.
[26] Un estudio de 2015 mostró que el entrenamiento conjunto aprende mejores modelos de datos junto con características más representativas para la clasificación en comparación con el método por capas.
[29] Si se utilizan activaciones lineales, o una sola capa oculta sigmoidea, entonces la solución óptima de un autocodificador está fuertemente relacionada con el análisis de componentes principales (ACP).
componentes principales, y la salida del autocodificador es una proyección ortogonal sobre este subespacio.
Los pesos del autocodificador no son iguales a los componentes principales y, por lo general, no son ortogonales, pero los componentes principales pueden recuperarse a partir de ellos mediante la descomposición en valores singulares.
[32] Sin embargo, el potencial de los autocodificadores reside en su no linealidad, que permite al modelo aprender generalizaciones más potentes en comparación con PCA, y reconstruir la entrada con una pérdida de información significativamente menor.
Salakhutdinov y Hinton propusieron en 2007 la aplicación de los autocodificadores al hash semántico.
Esta tabla permitiría recuperar la información devolviendo todas las entradas con el mismo código binario que la consulta, o entradas ligeramente menos similares cambiando algunos bits de la codificación de la consulta.
La arquitectura codificador-decodificador, utilizada a menudo en el procesamiento del lenguaje natural y las redes neuronales, puede aplicarse científicamente en el campo de la SEO (Search Engine Optimization) de diversas maneras: En esencia, la arquitectura codificador-decodificador o los autocodificadores pueden aprovecharse en SEO para optimizar el contenido de las páginas web, mejorar su indexación y aumentar su atractivo tanto para los motores de búsqueda como para los usuarios.
Cuando se enfrenta a anomalías, el modelo debe empeorar su rendimiento de reconstrucción.
[42][43][44] Los autocodificadores se han utilizado en contextos más exigentes, como la imagen médica, donde se han empleado para la eliminación de ruido de imágenes[45] y la superresolución.
[53][54] A diferencia de los autocodificadores tradicionales, la salida no coincide con la entrada, sino que está en otro idioma.