Reglas por las cuales la información codificada dentro del material genético se traduce en proteínas
Serie de codones que forman parte de una molécula de ARN mensajero (ARNm). Cada codón consta de tres nucleótidos , que normalmente corresponden a un solo aminoácido . Los nucleótidos se abrevian con las letras A, U, G y C. Este es el ARNm, que utiliza U ( uracilo ). El ADN utiliza T ( timina ) en su lugar. Esta molécula de ARNm dará instrucciones a un ribosoma para que sintetice una proteína de acuerdo con este código.
Los codones especifican qué aminoácido se añadirá a continuación durante la biosíntesis de proteínas . Con algunas excepciones, [1] un codón de tres nucleótidos en una secuencia de ácido nucleico especifica un solo aminoácido. La gran mayoría de los genes están codificados con un único esquema (véase la tabla de codones del ARN ). Ese esquema se suele denominar código genético canónico o estándar, o simplemente código genético, aunque existen códigos variantes (como en las mitocondrias ).
Historia
El código genético
Los esfuerzos para comprender cómo se codifican las proteínas comenzaron después de que se descubriera la estructura del ADN en 1953. Los descubridores clave, el biofísico inglés Francis Crick y el biólogo estadounidense James Watson , trabajando juntos en el Laboratorio Cavendish de la Universidad de Cambridge, plantearon la hipótesis de que la información fluye desde el ADN y que existe un vínculo entre el ADN y las proteínas. [2] El físico soviético-estadounidense George Gamow fue el primero en dar un esquema viable para la síntesis de proteínas a partir del ADN. [3] Postuló que se deben emplear conjuntos de tres bases (tripletes) para codificar los 20 aminoácidos estándar utilizados por las células vivas para construir proteínas, lo que permitiría un máximo de 4 3 = 64 aminoácidos. [4] Llamó a esta interacción ADN-proteína (el código genético original) "código diamante". [5]
En 1954, Gamow creó una organización científica informal, el RNA Tie Club , como lo sugirió Watson, para científicos de diferentes tendencias que estuvieran interesados en cómo se sintetizaban las proteínas a partir de los genes. Sin embargo, el club solo podía tener 20 miembros permanentes para representar a cada uno de los 20 aminoácidos y cuatro miembros honorarios adicionales para representar a los cuatro nucleótidos del ADN. [6]
La primera contribución científica del club, registrada posteriormente como "uno de los artículos inéditos más importantes de la historia de la ciencia" [7] y "el artículo inédito más famoso en los anales de la biología molecular", [8] fue realizada por Crick. Crick presentó un artículo escrito a máquina titulado "Sobre plantillas degeneradas y la hipótesis del adaptador: una nota para el RNA Tie Club" [9] a los miembros del club en enero de 1955, que "cambió totalmente la forma en que pensábamos sobre la síntesis de proteínas", como recordó Watson. [10] La hipótesis establece que el código de tripletes no se transmitió a los aminoácidos como pensaba Gamow, sino que lo transportó una molécula diferente, un adaptador, que interactúa con los aminoácidos. [8] El adaptador fue identificado posteriormente como ARNt. [11]
Marshall Nirenberg y J. Heinrich Matthaei fueron los primeros en revelar la naturaleza de un codón en 1961. [12] Utilizaron un sistema libre de células para traducir una secuencia de ARN de poliuracilo (es decir, UUUUU...) y descubrieron que el polipéptido que habían sintetizado consistía únicamente en el aminoácido fenilalanina . [13] De este modo dedujeron que el codón UUU especificaba el aminoácido fenilalanina.
A esto le siguieron experimentos en el laboratorio de Severo Ochoa que demostraron que la secuencia de ARN poliadenina (AAAAA...) codificaba para el polipéptido polilisina [ 14 ] y que la secuencia de ARN policitosina ( CCCCC...) codificaba para el polipéptido poliprolina [15] . Por lo tanto, el codón AAA especificaba el aminoácido lisina y el codón CCC especificaba el aminoácido prolina . Utilizando varios copolímeros se determinaron la mayoría de los codones restantes.
Trabajos posteriores de Har Gobind Khorana identificaron el resto del código genético. Poco después, Robert W. Holley determinó la estructura del ARN de transferencia (ARNt), la molécula adaptadora que facilita el proceso de traducción del ARN en proteína. Este trabajo se basó en los estudios anteriores de Ochoa, que le valieron el Premio Nobel de Fisiología o Medicina en 1959 por su trabajo sobre la enzimología de la síntesis del ARN. [16]
Ampliando este trabajo, Nirenberg y Philip Leder revelaron la naturaleza triplete del código y descifraron sus codones. En estos experimentos, varias combinaciones de ARNm se pasaron a través de un filtro que contenía ribosomas , los componentes de las células que traducen el ARN en proteína. Los tripletes únicos promovieron la unión de ARNt específicos al ribosoma. Leder y Nirenberg pudieron determinar las secuencias de 54 de los 64 codones en sus experimentos. [17] Khorana, Holley y Nirenberg recibieron el Premio Nobel (1968) por su trabajo. [18]
Los tres codones de terminación recibieron su nombre de los descubridores Richard Epstein y Charles Steinberg. El nombre "ámbar" se debe a su amigo Harris Bernstein, cuyo apellido significa "ámbar" en alemán. [19] Los otros dos codones de terminación se denominaron "ocre" y "ópalo" para mantener el tema de los "nombres de los colores".
Códigos genéticos ampliados (biología sintética)
En un amplio público académico, el concepto de la evolución del código genético desde el código genético original y ambiguo hasta un código bien definido (“congelado”) con el repertorio de 20 (+2) aminoácidos canónicos es ampliamente aceptado. [20]
Sin embargo, existen diferentes opiniones, conceptos, enfoques e ideas sobre cuál es la mejor manera de cambiarlo experimentalmente. Incluso se proponen modelos que predicen “puntos de entrada” para la invasión de aminoácidos sintéticos al código genético. [21]
Desde 2001, se han añadido 40 aminoácidos no naturales a las proteínas mediante la creación de un codón único (recodificación) y un par ARN de transferencia:aminoacil-ARNt-sintetasa correspondiente para codificarlo con diversas propiedades fisicoquímicas y biológicas con el fin de utilizarlo como herramienta para explorar la estructura y función de las proteínas o para crear proteínas nuevas o mejoradas. [22] [23]
H. Murakami y M. Sisido ampliaron algunos codones para que tuvieran cuatro y cinco bases. Steven A. Benner construyó un codón funcional número 65 ( in vivo ). [24]
En 2015, N. Budisa , D. Söll y colaboradores informaron la sustitución completa de los 20.899 residuos de triptófano (codones UGG) con tienopirrol-alanina no natural en el código genético de la bacteria Escherichia coli . [25]
En 2016 se creó el primer organismo semisintético estable. Se trataba de una bacteria (unicelular) con dos bases sintéticas (llamadas X e Y). Las bases sobrevivieron a la división celular. [26] [27]
En 2017, investigadores de Corea del Sur informaron que habían diseñado un ratón con un código genético extendido que puede producir proteínas con aminoácidos no naturales. [28]
En mayo de 2019, los investigadores informaron sobre la creación de una nueva cepa "Syn61" de la bacteria Escherichia coli . Esta cepa tiene un genoma completamente sintético que se refactorizó (se expandieron todas las superposiciones), se recodificaron (se eliminaron por completo el uso de tres de los 64 codones) y se modificaron aún más para eliminar los ARNt y los factores de liberación ahora innecesarios. Es completamente viable y crece 1,6 veces más lento que su contraparte de tipo salvaje "MDS42". [29] [30]
Características
Marcos de lectura en la secuencia de ADN de una región del genoma mitocondrial humano que codifica para los genes MT-ATP8 y MT-ATP6 (en negro: posiciones 8.525 a 8.580 en la secuencia de acceso NC_012920 [31] ). Hay tres posibles marcos de lectura en la dirección 5' → 3' hacia adelante, comenzando en la primera (+1), segunda (+2) y tercera posición (+3). Para cada codón (corchetes), el aminoácido viene dado por el código mitocondrial de vertebrados , ya sea en el marco +1 para MT-ATP8 (en rojo) o en el marco +3 para MT-ATP6 (en azul). El gen MT-ATP8 termina con el codón de terminación TAG (punto rojo) en el marco +1. El gen MT-ATP6 comienza con el codón ATG (círculo azul para el aminoácido M) en el marco +3.
Marco de lectura
Un marco de lectura se define por el triplete inicial de nucleótidos a partir del cual comienza la traducción. Establece el marco para una serie de codones sucesivos que no se superponen, lo que se conoce como un " marco de lectura abierto " (ORF). Por ejemplo, la cadena 5'-AAATGAACG-3' (ver figura), si se lee desde la primera posición, contiene los codones AAA, TGA y ACG; si se lee desde la segunda posición, contiene los codones AAT y GAA; y si se lee desde la tercera posición, contiene los codones ATG y AAC. Cada secuencia puede, por lo tanto, leerse en su dirección 5' → 3' en tres marcos de lectura , cada uno de los cuales produce una secuencia de aminoácidos posiblemente distinta: en el ejemplo dado, Lys (K)-Trp (W)-Thr (T), Asn (N)-Glu (E) o Met (M)-Asn (N), respectivamente (al traducir con el código mitocondrial de vertebrados). Cuando el ADN es de doble cadena, se definen seis posibles marcos de lectura , tres en orientación directa en una cadena y tres en orientación inversa en la cadena opuesta. [32] : 330 Los marcos de codificación de proteínas se definen por un codón de inicio , generalmente el primer codón AUG (ATG) en la secuencia de ARN (ADN).
La traducción comienza con un codón de inicio de cadena o codón de inicio . El codón de inicio por sí solo no es suficiente para comenzar el proceso. También se requieren secuencias cercanas como la secuencia Shine-Dalgarno en E. coli y factores de iniciación para iniciar la traducción. El codón de inicio más común es AUG, que se lee como metionina o como formilmetionina (en bacterias, mitocondrias y plástidos). Los codones de inicio alternativos según el organismo incluyen "GUG" o "UUG"; estos codones normalmente representan valina y leucina , respectivamente, pero como codones de inicio se traducen como metionina o formilmetionina. [33]
Los tres codones de terminación tienen nombres: UAG es ámbar , UGA es ópalo (a veces también llamado umber ) y UAA es ocre . Los codones de terminación también se denominan codones de "terminación" o "sin sentido". Señalan la liberación del polipéptido naciente del ribosoma porque ningún ARNt cognado tiene anticodones complementarios a estas señales de terminación, lo que permite que un factor de liberación se una al ribosoma en su lugar. [34]
Durante el proceso de replicación del ADN , ocasionalmente ocurren errores en la polimerización de la segunda cadena. Estos errores, las mutaciones , pueden afectar el fenotipo de un organismo , especialmente si ocurren dentro de la secuencia codificante de proteínas de un gen. Las tasas de error son típicamente de 1 error cada 10–100 millones de bases, debido a la capacidad de "corrección" de las polimerasas del ADN . [36] [37]
Las mutaciones que alteran la secuencia del marco de lectura mediante inserciones o deleciones de un número no múltiplo de 3 bases de nucleótidos se conocen como mutaciones por desplazamiento del marco de lectura . Estas mutaciones suelen dar lugar a una traducción completamente diferente de la original y probablemente provoquen la lectura de un codón de terminación , lo que trunca la proteína. [41] Estas mutaciones pueden perjudicar la función de la proteína y, por lo tanto, son raras en las secuencias codificantes de proteínas in vivo . Una razón por la que la herencia de las mutaciones por desplazamiento del marco de lectura es rara es que, si la proteína que se está traduciendo es esencial para el crecimiento bajo las presiones selectivas a las que se enfrenta el organismo, la ausencia de una proteína funcional puede provocar la muerte antes de que el organismo se vuelva viable. [42] Las mutaciones por desplazamiento del marco de lectura pueden dar lugar a enfermedades genéticas graves, como la enfermedad de Tay-Sachs . [43]
Aunque la mayoría de las mutaciones que cambian las secuencias de proteínas son dañinas o neutrales, algunas mutaciones tienen beneficios. [44] Estas mutaciones pueden permitir que el organismo mutante resista estreses ambientales particulares mejor que los organismos de tipo salvaje , o se reproduzca más rápidamente. En estos casos, una mutación tenderá a volverse más común en una población a través de la selección natural . [45] Los virus que usan ARN como material genético tienen tasas de mutación rápidas, [46] lo que puede ser una ventaja, ya que estos virus evolucionan rápidamente y, por lo tanto, evaden las respuestas defensivas del sistema inmunológico . [47] En grandes poblaciones de organismos que se reproducen asexualmente, por ejemplo, E. coli , pueden ocurrir simultáneamente múltiples mutaciones beneficiosas. Este fenómeno se llama interferencia clonal y causa competencia entre las mutaciones. [48]
Degeneración
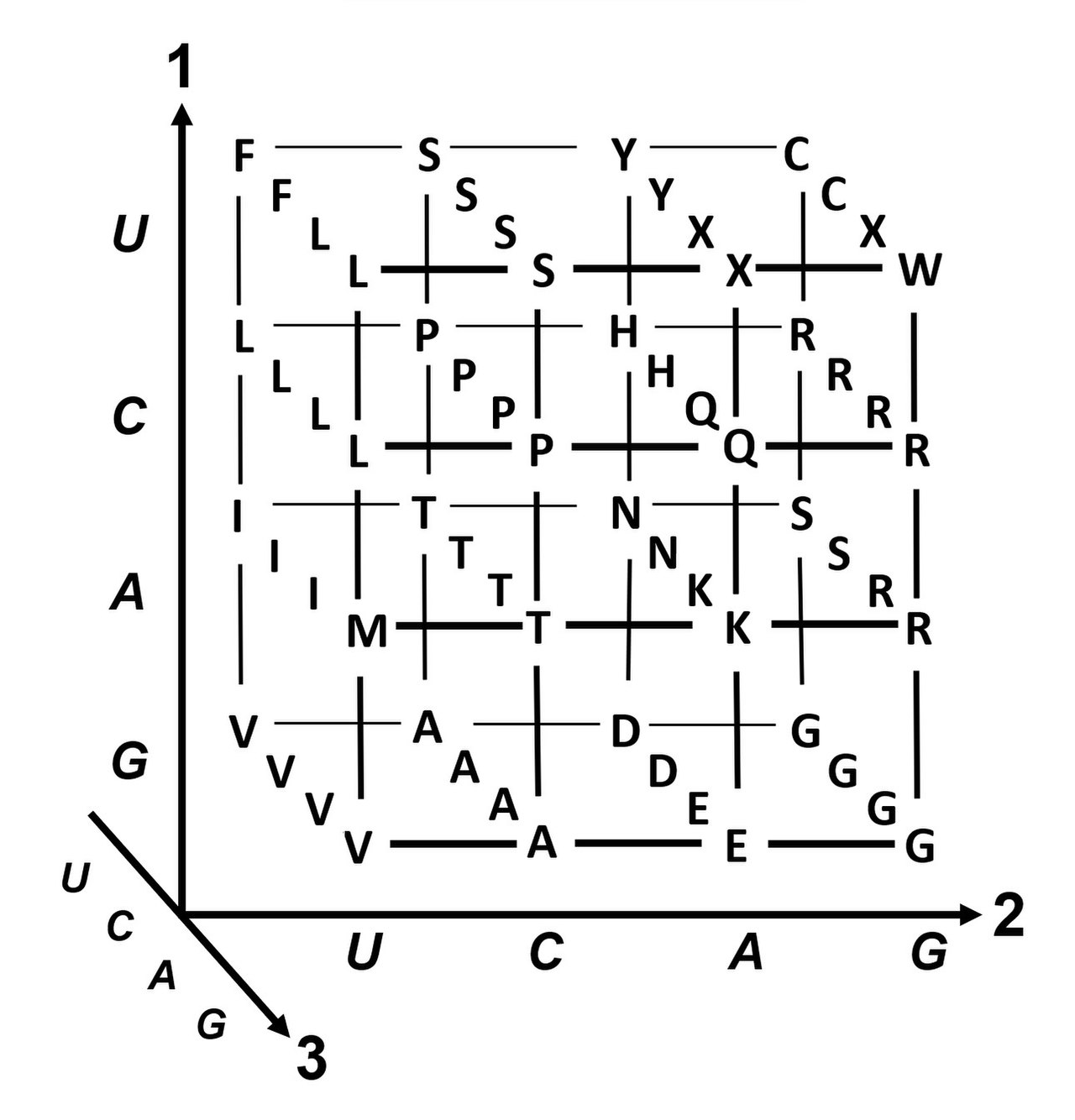
Agrupamiento de codones por volumen molar de residuos de aminoácidos e hidropaticidad . Hay disponible una versión más detallada .Los ejes 1, 2 y 3 son la primera, segunda y tercera posición del codón. Los 20 aminoácidos y los codones de terminación (X) se muestran en código de una sola letra .
La degeneración es la redundancia del código genético. Este término fue dado por Bernfield y Nirenberg. El código genético tiene redundancia pero no ambigüedad (ver las tablas de codones a continuación para la correlación completa). Por ejemplo, aunque los codones GAA y GAG especifican ácido glutámico (redundancia), ninguno especifica otro aminoácido (sin ambigüedad). Los codones que codifican un aminoácido pueden diferir en cualquiera de sus tres posiciones. Por ejemplo, el aminoácido leucina se especifica mediante los codones Y U R o CU N (UUA, UUG, CUU, CUC, CUA o CUG) (la diferencia en la primera o tercera posición se indica utilizando la notación IUPAC ), mientras que el aminoácido serina se especifica mediante los codones UC N o AG Y (UCA, UCG, UCC, UCU, AGU o AGC) (diferencia en la primera, segunda o tercera posición). [49] Una consecuencia práctica de la redundancia es que los errores en la tercera posición del codón triplete causan solo una mutación silenciosa o un error que no afectaría a la proteína porque la hidrofilia o hidrofobicidad se mantiene por sustitución equivalente de aminoácidos; por ejemplo, un codón de NUN (donde N = cualquier nucleótido) tiende a codificar aminoácidos hidrofóbicos. NCN produce residuos de aminoácidos que son pequeños en tamaño y moderados en hidropaticidad ; NAN codifica residuos hidrofílicos de tamaño promedio. El código genético está tan bien estructurado para la hidropaticidad que un análisis matemático ( descomposición en valores singulares ) de 12 variables (4 nucleótidos x 3 posiciones) produce una correlación notable (C = 0,95) para predecir la hidropaticidad del aminoácido codificado directamente a partir de la secuencia de nucleótidos del triplete, sin traducción. [50] [51] Nótese en la tabla, a continuación, que ocho aminoácidos no se ven afectados en absoluto por mutaciones en la tercera posición del codón, mientras que en la figura anterior, es probable que una mutación en la segunda posición cause un cambio radical en las propiedades fisicoquímicas del aminoácido codificado. Sin embargo, los cambios en la primera posición de los codones son más importantes que los cambios en la segunda posición a escala global. [52] La razón puede ser que la inversión de carga (de una carga positiva a una negativa o viceversa) solo puede ocurrir tras mutaciones en la primera posición de ciertos codones, pero no tras cambios en la segunda posición de ningún codón. Tal inversión de carga puede tener consecuencias dramáticas para la estructura o función de una proteína. Este aspecto puede haber sido subestimado en gran medida por estudios previos. [52]
Sesgo en el uso de codones
La frecuencia de los codones, también conocida como sesgo de uso de codones , puede variar de una especie a otra con implicaciones funcionales para el control de la traducción . El codón varía según el organismo; por ejemplo, el codón de prolina más común en E. coli es CCG, mientras que en los humanos este es el codón de prolina menos utilizado. [53]
Códigos genéticos alternativos
Aminoácidos no estándar
En algunas proteínas, los aminoácidos no estándar se sustituyen por codones de terminación estándar, dependiendo de las secuencias de señal asociadas en el ARN mensajero. Por ejemplo, UGA puede codificar selenocisteína y UAG puede codificar pirrolisina . La selenocisteína llegó a ser vista como el aminoácido número 21, y la pirrolisina como el número 22. [55] Tanto la selenocisteína como la pirrolisina pueden estar presentes en el mismo organismo. [55] Aunque el código genético normalmente está fijo en un organismo, el procariota aqueal Acetohalobium arabaticum puede expandir su código genético de 20 a 21 aminoácidos (al incluir pirrolisina) bajo diferentes condiciones de crecimiento. [56]
Variaciones
Logotipo del código genético del genoma mitocondrial de Globobulimina pseudospinescens elaborado por FACIL. El programa es capaz de inferir correctamente que se está utilizando el Código Mitocondrial de Protozoos . [57] El logotipo muestra los 64 codones de izquierda a derecha, las alternativas predichas en rojo (en relación con el código genético estándar). Línea roja: codones de terminación. La altura de cada aminoácido en la pila muestra la frecuencia con la que se alinea con el codón en los dominios proteicos homólogos. La altura de la pila indica el apoyo a la predicción.
En un principio, existía un argumento simple y ampliamente aceptado de que el código genético debería ser universal: a saber, que cualquier variación en el código genético sería letal para el organismo (aunque Crick había afirmado que los virus eran una excepción). Esto se conoce como el argumento del "accidente congelado" para la universalidad del código genético. Sin embargo, en su artículo seminal sobre los orígenes del código genético en 1968, Francis Crick todavía afirmaba que la universalidad del código genético en todos los organismos era una suposición no probada, y probablemente no era cierta en algunos casos. Predijo que "el código es universal (el mismo en todos los organismos) o casi". [58] La primera variación fue descubierta en 1979, por investigadores que estudiaban los genes mitocondriales humanos . [59] A partir de entonces se descubrieron muchas variantes leves, [60] incluidos varios códigos mitocondriales alternativos. [61] Estas variantes menores, por ejemplo, implican la traducción del codón UGA como triptófano en especies de Mycoplasma , y la traducción de CUG como una serina en lugar de leucina en levaduras del "clado CTG" (como Candida albicans ). [62] [63] [64] Debido a que los virus deben utilizar el mismo código genético que sus huéspedes, las modificaciones al código genético estándar podrían interferir con la síntesis o el funcionamiento de las proteínas virales. Sin embargo, virus como los totivirus se han adaptado a la modificación del código genético del huésped. [65] En bacterias y arqueas , GUG y UUG son codones de inicio comunes. En casos raros, ciertas proteínas pueden utilizar codones de inicio alternativos. [60]
Sorprendentemente, también existen variaciones en la interpretación del código genético en los genes humanos codificados en el núcleo: en 2016, los investigadores que estudiaban la traducción de la malato deshidrogenasa descubrieron que en aproximadamente el 4% de los ARNm que codifican esta enzima, el codón de terminación se usa de forma natural para codificar los aminoácidos triptófano y arginina. [66] Este tipo de recodificación es inducida por un contexto de codón de terminación de alta lectura [67] y se denomina lectura funcional traduccional . [68]
A pesar de estas diferencias, todos los códigos naturales conocidos son muy similares. El mecanismo de codificación es el mismo para todos los organismos: codones de tres bases, ARNt , ribosomas, lectura en una sola dirección y traducción de codones individuales en aminoácidos individuales. [69] Las variaciones más extremas ocurren en ciertos ciliados donde el significado de los codones de terminación depende de su posición dentro del ARNm. Cuando están cerca del extremo 3' actúan como terminadores mientras que en posiciones internas codifican aminoácidos como en Condylostoma magnum [70] o desencadenan el cambio de marco ribosómico como en Euplotes . [71]
Los orígenes y la variación del código genético, incluidos los mecanismos detrás de la capacidad de evolución del código genético, han sido ampliamente estudiados, [72] [73] y se han realizado algunos estudios para evolucionar experimentalmente el código genético de algunos organismos. [74] [75] [76] [77]
Inferencia
Los códigos genéticos variantes utilizados por un organismo se pueden inferir identificando genes altamente conservados codificados en ese genoma y comparando su uso de codones con los aminoácidos en proteínas homólogas de otros organismos. Por ejemplo, el programa FACIL infiere un código genético buscando qué aminoácidos en dominios proteicos homólogos se alinean con mayor frecuencia con cada codón. Las probabilidades de aminoácidos (o codones de terminación) resultantes para cada codón se muestran en un logotipo de código genético. [57]
A partir de enero de 2022, el estudio más completo de códigos genéticos lo han realizado Shulgina y Eddy, quienes examinaron 250.000 genomas procariotas utilizando su herramienta Codetta. Esta herramienta utiliza un enfoque similar a FACIL con una base de datos Pfam más grande . A pesar de que el NCBI ya proporciona 27 tablas de traducción, los autores pudieron encontrar 5 nuevas variaciones del código genético (corroboradas por mutaciones de ARNt) y corregir varias atribuciones erróneas. [78] Codetta se utilizó más tarde para analizar el cambio del código genético en ciliados . [79]
Origen
El código genético es una parte clave de la historia de la vida , según una versión de la cual las moléculas de ARN autorreplicantes precedieron a la vida tal como la conocemos. Esta es la hipótesis del mundo del ARN . Bajo esta hipótesis, cualquier modelo para el surgimiento del código genético está íntimamente relacionado con un modelo de la transferencia de las ribozimas (enzimas del ARN) a las proteínas como las principales enzimas en las células. En línea con la hipótesis del mundo del ARN, las moléculas de ARN de transferencia parecen haber evolucionado antes que las modernas aminoacil-ARNt sintetasas , por lo que estas últimas no pueden ser parte de la explicación de sus patrones. [80]
Un código genético hipotético evolucionado aleatoriamente motiva además un modelo bioquímico o evolutivo para su origen. Si los aminoácidos se asignaran aleatoriamente a codones tripletes, habría 1,5 × 10 84 códigos genéticos posibles. [81] : 163 Este número se encuentra calculando el número de formas en que 21 elementos (20 aminoácidos más una parada) se pueden colocar en 64 contenedores, donde cada elemento se usa al menos una vez. [82] Sin embargo, la distribución de asignaciones de codones en el código genético no es aleatoria. [83] En particular, el código genético agrupa ciertas asignaciones de aminoácidos.
Los aminoácidos que comparten la misma vía biosintética tienden a tener la misma primera base en sus codones. Esto podría ser una reliquia evolutiva de un código genético primitivo, más simple, con menos aminoácidos, que luego evolucionó para codificar un conjunto más grande de aminoácidos. [84] También podría reflejar propiedades estéricas y químicas que tuvieron otro efecto en el codón durante su evolución. Los aminoácidos con propiedades físicas similares también tienden a tener codones similares, [85] [86] lo que reduce los problemas causados por mutaciones puntuales y traducciones erróneas. [83]
Dado el esquema de codificación de tripletes genéticos no aleatorio, una hipótesis sostenible para el origen del código genético podría abordar múltiples aspectos de la tabla de codones, como la ausencia de codones para los aminoácidos D, los patrones de codones secundarios para algunos aminoácidos, el confinamiento de posiciones sinónimas a la tercera posición, el pequeño conjunto de solo 20 aminoácidos (en lugar de un número cercano a 64) y la relación de los patrones de codones de terminación con los patrones de codificación de aminoácidos. [87]
Tres hipótesis principales abordan el origen del código genético. Muchos modelos pertenecen a una de ellas o a un híbrido: [88]
Congelación aleatoria: el código genético se creó aleatoriamente. Por ejemplo, las primeras ribozimas similares al ARNt pueden haber tenido diferentes afinidades por los aminoácidos, con codones que surgían de otra parte de la ribozima que exhibía variabilidad aleatoria. Una vez que se codificaron suficientes péptidos , cualquier cambio aleatorio importante en el código genético habría sido letal; por lo tanto, quedó "congelado". [89]
Afinidad estereoquímica: el código genético es el resultado de una alta afinidad entre cada aminoácido y su codón o anticodón; la última opción implica que las moléculas de pre-ARNt se emparejaron con sus aminoácidos correspondientes por esta afinidad. Más tarde durante la evolución, esta coincidencia fue reemplazada gradualmente por la coincidencia mediante aminoacil-ARNt sintetasas. [87] [90] [91]
Optimalidad: el código genético continuó evolucionando después de su creación inicial, de modo que el código actual maximiza alguna función de aptitud , generalmente algún tipo de minimización de errores. [87] [88] [92]
Las hipótesis han abordado una variedad de escenarios: [93]
Los principios químicos rigen la interacción específica del ARN con los aminoácidos. Los experimentos con aptámeros demostraron que algunos aminoácidos tienen una afinidad química selectiva por sus codones. [94] Los experimentos demostraron que de los 8 aminoácidos analizados, 6 muestran alguna asociación de triplete de ARN con aminoácido. [81] [91]
Expansión biosintética. El código genético creció a partir de un código anterior más simple a través de un proceso de "expansión biosintética". La vida primordial "descubrió" nuevos aminoácidos (por ejemplo, como subproductos del metabolismo ) y luego incorporó algunos de ellos a la maquinaria de codificación genética. [95] Aunque se ha encontrado mucha evidencia circunstancial que sugiere que se usaron menos tipos de aminoácidos en el pasado, [96] las hipótesis precisas y detalladas sobre qué aminoácidos ingresaron al código y en qué orden son controvertidas. [97] [98] Sin embargo, varios estudios han sugerido que Gly, Ala, Asp, Val, Ser, Pro, Glu, Leu, Thr pueden pertenecer a un grupo de aminoácidos de adición temprana, mientras que Cys, Met, Tyr, Trp, His, Phe pueden pertenecer a un grupo de aminoácidos de adición posterior. [99] [100] [101] [102]
La selección natural ha llevado a asignaciones de codones del código genético que minimizan los efectos de las mutaciones . [103] Una hipótesis reciente [104] sugiere que el código de tripletes se derivó de códigos que usaban codones más largos que los tripletes (como los codones de cuatrillizos). Una decodificación más larga que los tripletes aumentaría la redundancia de codones y sería más resistente a errores. Esta característica podría permitir una decodificación precisa en ausencia de maquinaria de traducción compleja como el ribosoma , como antes de que las células comenzaran a producir ribosomas.
Canales de información: Los enfoques basados en la teoría de la información modelan el proceso de traducción del código genético a los aminoácidos correspondientes como un canal de información propenso a errores. [105] El ruido inherente (es decir, el error) en el canal plantea al organismo una pregunta fundamental: ¿cómo se puede construir un código genético que resista el ruido [106] y al mismo tiempo traduzca la información de manera precisa y eficiente? Estos modelos de "distorsión de la velocidad" [107] sugieren que el código genético se originó como resultado de la interacción de las tres fuerzas evolutivas en conflicto: las necesidades de diversos aminoácidos [108] , de tolerancia a los errores [103] y de un costo mínimo de recursos. El código emerge en una transición cuando el mapeo de codones a aminoácidos deja de ser aleatorio. La aparición del código está regida por la topología definida por los errores probables y está relacionada con el problema de coloración del mapa . [109]
Teoría de juegos: Los modelos basados en juegos de señalización combinan elementos de la teoría de juegos, la selección natural y los canales de información. Dichos modelos se han utilizado para sugerir que los primeros polipéptidos probablemente eran cortos y tenían una función no enzimática. Los modelos de teoría de juegos sugirieron que la organización de cadenas de ARN en células puede haber sido necesaria para evitar el uso "engañoso" del código genético, es decir, evitar que el equivalente antiguo de los virus abrumara el mundo del ARN. [110]
Codones de terminación: Los codones de terminación de la traducción también son un aspecto interesante del problema del origen del código genético. Como ejemplo para abordar la evolución de los codones de terminación, se ha sugerido que los codones de terminación son tales que es más probable que terminen la traducción de forma temprana en el caso de un error de cambio de marco de lectura . [111] En contraste, algunos modelos moleculares estereoquímicos explican el origen de los codones de terminación como "inasignables". [87]
^ Turanov AA, Lobanov AV, Fomenko DE, Morrison HG, Sogin ML, Klobutcher LA, Hatfield DL, Gladyshev VN (enero de 2009). "El código genético apoya la inserción dirigida de dos aminoácidos por un codón". Science . 323 (5911): 259–61. doi :10.1126/science.1164748. PMC 3088105 . PMID 19131629.
^ Watson, JD; Crick, FH (30 de mayo de 1953). "Implicaciones genéticas de la estructura del ácido desoxirribonucleico". Nature . 171 (4361): 964–967. Bibcode :1953Natur.171..964W. doi :10.1038/171964b0. ISSN 0028-0836. PMID 13063483. S2CID 4256010.
^ Stegmann, Ulrich E. (1 de septiembre de 2016). «Reconsideración de la «codificación genética»: un análisis del uso real». Revista británica de filosofía de la ciencia . 67 (3): 707–730. doi :10.1093/bjps/axv007. ISSN 0007-0882. PMC 4990703 . PMID 27924115.
^ Hayes, Brian (1998). "Ciencia informática: la invención del código genético". Científico estadounidense . 86 (1): 8–14. doi :10.1511/1998.17.3338. ISSN 0003-0996. JSTOR 27856930. S2CID 121907709.
^ Strauss, Bernard S (1 de marzo de 2019). "Martynas Yčas: El "Archivista" del RNA Tie Club". Genética . 211 (3): 789–795. doi :10.1534/genetics.118.301754. ISSN 1943-2631. PMC 6404253 . PMID 30846543.
^ "Francis Crick - Resultados de búsqueda de perfiles en la ciencia". profiles.nlm.nih.gov . Consultado el 21 de julio de 2022 .
^ ab Fry, Michael (2022). "La hipótesis del adaptador de Crick y el descubrimiento del ARN de transferencia: experimento que supera la predicción teórica". Filosofía, teoría y práctica en biología . 14 . doi : 10.3998/ptpbio.2628 . ISSN 2475-3025. S2CID 249112573.
^ Crick, Francis (1955). "Sobre las plantillas degeneradas y la hipótesis del adaptador: una nota para el RNA Tie Club". Biblioteca Nacional de Medicina . Consultado el 21 de julio de 2022 .
^ Watson, James D. (2007). Evitar a la gente aburrida: lecciones de una vida en la ciencia. Oxford University Press. pág. 112. ISBN978-0-19-280273-6.OCLC 47716375 .
^ Barciszewska, Mirosława Z.; Perrigue, Patrick M.; Barciszewski, Jan (2016). "ARNt: el estándar de oro en biología molecular". Molecular BioSystems . 12 (1): 12–17. doi :10.1039/c5mb00557d. PMID 26549858.
^ Yanofsky, Charles (9 de marzo de 2007). "Establecimiento de la naturaleza triple del código genético". Cell . 128 (5): 815–818. doi : 10.1016/j.cell.2007.02.029 . PMID 17350564. S2CID 14249277.
^ Nirenberg MW, Matthaei JH (octubre de 1961). "La dependencia de la síntesis de proteínas libres de células en E. coli de polirribonucleótidos sintéticos o de origen natural". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 47 (10): 1588–602. Bibcode :1961PNAS...47.1588N. doi : 10.1073/pnas.47.10.1588 . PMC 223178 . PMID 14479932.
^ Gardner RS, Wahba AJ, Basilio C, Miller RS, Lengyel P, Speyer JF (diciembre de 1962). "Polinucleótidos sintéticos y el código de aminoácidos. VII". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 48 (12): 2087–94. Bibcode :1962PNAS...48.2087G. doi : 10.1073/pnas.48.12.2087 . PMC 221128 . PMID 13946552.
^ Wahba AJ, Gardner RS, Basilio C, Miller RS, Speyer JF, Lengyel P (enero de 1963). "Polinucleótidos sintéticos y el código de aminoácidos. VIII". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 49 (1): 116–22. Bibcode :1963PNAS...49..116W. doi : 10.1073/pnas.49.1.116 . PMC 300638 . PMID 13998282.
^ "El Premio Nobel de Fisiología o Medicina 1959" (Nota de prensa). Real Academia Sueca de Ciencias. 1959. Consultado el 27 de febrero de 2010. El Premio Nobel de Fisiología o Medicina 1959 fue otorgado conjuntamente a Severo Ochoa y Arthur Kornberg "por su descubrimiento de los mecanismos en la síntesis biológica del ácido ribonucleico y el ácido desoxirribonucleico".
^ Nirenberg M, Leder P, Bernfield M, Brimacombe R, Trupin J, Rottman F, O'Neal C (mayo de 1965). "Palabras clave del ARN y síntesis de proteínas, VII. Sobre la naturaleza general del código del ARN". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 53 (5): 1161–8. Bibcode :1965PNAS...53.1161N. doi : 10.1073/pnas.53.5.1161 . PMC 301388 . PMID 5330357.
^ "El Premio Nobel de Fisiología o Medicina 1968" (Nota de prensa). Real Academia Sueca de Ciencias. 1968. Consultado el 27 de febrero de 2010. El Premio Nobel de Fisiología o Medicina 1968 fue otorgado conjuntamente a Robert W. Holley, Har Gobind Khorana y Marshall W. Nirenberg "por su interpretación del código genético y su función en la síntesis de proteínas".
^ Edgar B (octubre de 2004). "El genoma del bacteriófago T4: una excavación arqueológica". Genética . 168 (2): 575–82. doi :10.1093/genetics/168.2.575. PMC 1448817 . PMID 15514035.
^ Budisa, Nediljko (23 de diciembre de 2005). El libro en la Biblioteca en línea de Wiley . doi :10.1002/3527607188. ISBN9783527312436.
^ Kubyshkin, V.; Budisa, N. (2017). "Alienación sintética de organismos microbianos mediante ingeniería de código genético: ¿por qué y cómo?". Biotechnology Journal . 12 (8): 1600097. doi :10.1002/biot.201600097. PMID 28671771.
^ Xie J, Schultz PG (diciembre de 2005). "Adición de aminoácidos al repertorio genético". Current Opinion in Chemical Biology . 9 (6): 548–54. doi :10.1016/j.cbpa.2005.10.011. PMID 16260173.
^ Wang Q, Parrish AR, Wang L (marzo de 2009). "Expansión del código genético para estudios biológicos". Química y biología . 16 (3): 323–36. doi :10.1016/j.chembiol.2009.03.001. PMC 2696486 . PMID 19318213.
^ Simon M (7 de enero de 2005). Computación emergente: énfasis en la bioinformática. Springer Science & Business Media. pp. 105–106. ISBN978-0-387-22046-8.
^ Hoesl, MG; Oehm, S.; Durkin, P.; Darmon, E.; Peil, L.; Aerni, H.-R.; Rapsilber, J .; Rinehart, J.; Lixiviación, D.; Söll, D.; Budisa, N. (2015). "Evolución química de un proteoma bacteriano". Edición internacional Angewandte Chemie . 54 (34): 10030–10034. doi :10.1002/anie.201502868. PMC 4782924 . PMID 26136259. Identificador NIHMS: NIHMS711205
^ "Creado el primer organismo semisintético estable | KurzweilAI". www.kurzweilai.net . 3 de febrero de 2017 . Consultado el 9 de febrero de 2017 .
^ Zhang Y, Lamb BM, Feldman AW, Zhou AX, Lavergne T, Li L, Romesberg FE (febrero de 2017). "Un organismo semisintético diseñado para la expansión estable del alfabeto genético". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 114 (6): 1317–1322. Bibcode :2017PNAS..114.1317Z. doi : 10.1073/pnas.1616443114 . PMC 5307467 . PMID 28115716.
^ Han S, Yang A, Lee S, Lee HW, Park CB, Park HS (febrero de 2017). "Expansión del código genético de Mus musculus". Nature Communications . 8 : 14568. Bibcode :2017NatCo...814568H. doi :10.1038/ncomms14568. PMC 5321798 . PMID 28220771.
^ Zimmer, Carl (15 de mayo de 2019). "Los científicos crearon bacterias con un genoma sintético. ¿Es esto vida artificial? - En un hito para la biología sintética, las colonias de E. coli prosperan con ADN construido desde cero por humanos, no por la naturaleza" . The New York Times . Archivado desde el original el 2 de enero de 2022. Consultado el 16 de mayo de 2019 .
^ Fredens, Julius; et al. (15 de mayo de 2019). "Síntesis total de Escherichia coli con un genoma recodificado". Nature . 569 (7757): 514–518. Bibcode :2019Natur.569..514F. doi :10.1038/s41586-019-1192-5. PMC 7039709 . PMID 31092918. S2CID 205571025.
^ Mitocondria del Homo sapiens , genoma completo. «Revised Cambridge Reference Sequence (rCRS): accession NC_012920», National Center for Biotechnology Information . Consultado el 27 de diciembre de 2017.
^ ab King RC, Mulligan P, Stansfield W (10 de enero de 2013). Diccionario de genética. OUP USA. pág. 608. ISBN978-0-19-976644-4.
^ Touriol C, Bornes S, Bonnal S, Audigier S, Prats H, Prats AC, Vagner S (2003). "Generación de diversidad de isoformas de proteínas mediante iniciación alternativa de la traducción en codones no AUG". Biology of the Cell . 95 (3–4): 169–78. doi : 10.1016/S0248-4900(03)00033-9 . PMID 12867081.
^ Maloy S (29 de noviembre de 2003). "Cómo las mutaciones sin sentido obtuvieron sus nombres". Curso de Genética Microbiana . Universidad Estatal de San Diego . Consultado el 10 de marzo de 2010 .
^ Las referencias a la imagen se encuentran en la página de Wikimedia Commons en: Commons:File:Notable changes.svg#References.
^ Griffiths AJ, Miller JH, Suzuki DT, Lewontin RC, et al., eds. (2000). "Mutaciones espontáneas". Introducción al análisis genético (7.ª ed.). Nueva York: WH Freeman. ISBN978-0-7167-3520-5.
^ Freisinger E, Grollman AP, Miller H, Kisker C (abril de 2004). "La (in)tolerancia a las lesiones revela información sobre la fidelidad de la replicación del ADN". The EMBO Journal . 23 (7): 1494–505. doi :10.1038/sj.emboj.7600158. PMC 391067 . PMID 15057282.
^ Boillée, S; Vande Velde, C; Cleveland, DW (2006). "ELA: una enfermedad de las neuronas motoras y sus vecinas no neuronales". Neuron . 52 (1): 39–59. doi : 10.1016/j.neuron.2006.09.018 . PMID 17015226.
^ Chang JC, Kan YW (junio de 1979). «Talasemia beta 0, una mutación sin sentido en el hombre». Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 76 (6): 2886–9. Bibcode :1979PNAS...76.2886C. doi : 10.1073/pnas.76.6.2886 . PMC 383714 . PMID 88735.
^ Boillée S, Vande Velde C, Cleveland DW (octubre de 2006). "ELA: una enfermedad de las neuronas motoras y sus vecinas no neuronales". Neuron . 52 (1): 39–59. doi : 10.1016/j.neuron.2006.09.018 . PMID 17015226.
^ Isbrandt D, Hopwood JJ, von Figura K, Peters C (1996). "Dos nuevas mutaciones por cambio de marco de lectura que causan codones de terminación prematuros en un paciente con la forma grave del síndrome de Maroteaux-Lamy". Human Mutation . 7 (4): 361–3. doi : 10.1002/(SICI)1098-1004(1996)7:4<361::AID-HUMU12>3.0.CO;2-0 . PMID 8723688. S2CID 22693748.
^ Crow JF (1993). "¿Cuánto sabemos sobre las tasas de mutación humana espontánea?". Environmental and Molecular Mutagenesis . 21 (2): 122–9. Bibcode :1993EnvMM..21..122C. doi :10.1002/em.2850210205. PMID 8444142. S2CID 32918971.
^ Lewis R (2005). Genética humana: conceptos y aplicaciones (6.ª ed.). Boston, Mass.: McGraw Hill. pp. 227–228. ISBN978-0-07-111156-0.
^ Sawyer SA, Parsch J, Zhang Z, Hartl DL (abril de 2007). "Prevalencia de selección positiva entre reemplazos de aminoácidos casi neutros en Drosophila". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 104 (16): 6504–10. Bibcode :2007PNAS..104.6504S. doi : 10.1073/pnas.0701572104 . PMC 1871816 . PMID 17409186.
^ Bridges KR (2002). "Malaria and the Red Cell". Harvard . Archivado desde el original el 27 de noviembre de 2011.
^ Drake JW, Holland JJ (noviembre de 1999). "Tasas de mutación entre virus ARN". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 96 (24): 13910–3. Bibcode :1999PNAS...9613910D. doi : 10.1073/pnas.96.24.13910 . PMC 24164 . PMID 10570172.
^ Holland J, Spindler K, Horodyski F, Grabau E, Nichol S, VandePol S (marzo de 1982). "Evolución rápida de los genomas de ARN". Science . 215 (4540): 1577–85. Bibcode :1982Sci...215.1577H. doi :10.1126/science.7041255. PMID 7041255.
^ de Visser JA, Rozen DE (abril de 2006). "Interferencia clonal y selección periódica de nuevas mutaciones beneficiosas en Escherichia coli". Genética . 172 (4): 2093–100. doi :10.1534/genetics.105.052373. PMC 1456385 . PMID 16489229.
^ Watson, James D. (2008). Biología molecular del gen. Pearson/Benjamin Cummings. ISBN978-0-8053-9592-1. : 102–117 : 521–522
^ Michel-Beyerle, Maria Elisabeth (1990). Centros de reacción de las bacterias fotosintéticas: Feldafing-II-Meeting. Springer-Verlag. ISBN978-3-540-53420-4.
^ Füllen G, Youvan DC (1994). "Algoritmos genéticos y mutagénesis recursiva en conjunto en ingeniería de proteínas". Complexity International 1.
^ ab Fricke, Markus (2019). "Importancia global de las estructuras secundarias del ARN en las secuencias codificantes de proteínas". Bioinformática . 35 (4): 579–583. doi :10.1093/bioinformatics/bty678. PMC 7109657 . PMID 30101307. S2CID 51968530.
^ "Tabla de frecuencia de uso de codones (gráfico) - Genscript". www.genscript.com . Consultado el 4 de febrero de 2022 .
^ "Tabla de uso de codones". www.kazusa.or.jp .
^ ab Zhang Y, Baranov PV, Atkins JF, Gladyshev VN (mayo de 2005). "La pirrolisina y la selenocisteína utilizan estrategias de decodificación diferentes". The Journal of Biological Chemistry . 280 (21): 20740–51. doi : 10.1074/jbc.M501458200 . PMID 15788401.
^ Prat L, Heinemann IU, Aerni HR, Rinehart J, O'Donoghue P, Söll D (diciembre de 2012). "Expansión del código genético en bacterias dependiente de la fuente de carbono". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 109 (51): 21070–5. Bibcode :2012PNAS..10921070P. doi : 10.1073/pnas.1218613110 . PMC 3529041 . PMID 23185002.
^ ab Dutilh BE, Jurgelenaite R, Szklarczyk R, van Hijum SA, Harhangi HR, Schmid M, de Wild B, Françoijs KJ, Stunnenberg HG, Strous M, Jetten MS, Op den Camp HJ, Huynen MA (julio de 2011). "FACIL: Inferencia y logotipo de código genético rápidos y precisos". Bioinformática . 27 (14): 1929–33. doi :10.1093/bioinformatics/btr316. PMC 3129529 . PMID 21653513.
^ Francis Crick, 1968. "El origen del código genético". J. Mol. Biol.
^ Barrell BG, Bankier AT, Drouin J (1979). "Un código genético diferente en las mitocondrias humanas". Nature . 282 (5735): 189–194. Código Bibliográfico :1979Natur.282..189B. doi :10.1038/282189a0. PMID 226894. S2CID 4335828.([1])
^ ab Elzanowski A, Ostell J (7 de abril de 2008). "The Genetic Codes". Centro Nacional de Información Biotecnológica (NCBI) . Consultado el 10 de marzo de 2010 .
^ Jukes TH, Osawa S (diciembre de 1990). "El código genético en mitocondrias y cloroplastos". Experientia . 46 (11–12): 1117–26. doi :10.1007/BF01936921. PMID 2253709. S2CID 19264964.
^ Fitzpatrick DA, Logue ME, Stajich JE, Butler G (1 de enero de 2006). "Una filogenia fúngica basada en 42 genomas completos derivados de superárboles y análisis de genes combinados". BMC Evolutionary Biology . 6 : 99. doi : 10.1186/1471-2148-6-99 . PMC 1679813 . PMID 17121679.
^ Santos MA, Tuite MF (mayo de 1995). "El codón CUG se decodifica in vivo como serina y no como leucina en Candida albicans". Nucleic Acids Research . 23 (9): 1481–6. doi :10.1093/nar/23.9.1481. PMC 306886 . PMID 7784200.
^ Butler G, Rasmussen MD, Lin MF, et al. (junio de 2009). "Evolución de la patogenicidad y la reproducción sexual en ocho genomas de Candida". Nature . 459 (7247): 657–62. Bibcode :2009Natur.459..657B. doi :10.1038/nature08064. PMC 2834264 . PMID 19465905.
^ Taylor DJ, Ballinger MJ, Bowman SM, Bruenn JA (2013). "Coevolución virus-huésped bajo un código genético nuclear modificado". PeerJ . 1 : e50. doi : 10.7717/peerj.50 . PMC 3628385 . PMID 23638388.
^ Hofhuis J, Schueren F, Nötzel C, Lingner T, Gärtner J, Jahn O, Thoms S (2016). "La extensión funcional de la lectura continua de la malato deshidrogenasa revela una modificación del código genético". Open Biol . 6 (11): 160246. doi :10.1098/rsob.160246. PMC 5133446. PMID 27881739 .
^ Schueren F, Lingner T, George R, Hofhuis J, Gartner J, Thoms S (2014). "La lactato deshidrogenasa peroxisomal se genera mediante lectura transcripcional en mamíferos". eLife . 3 : e03640. doi : 10.7554/eLife.03640 . PMC 4359377 . PMID 25247702.
^ F. Schueren y S. Thoms (2016). "Lectura funcional traslacional: una perspectiva desde la biología de sistemas". PLOS Genetics . 12 (8): e1006196. doi : 10.1371/journal.pgen.1006196 . PMC 4973966 . PMID 27490485.
^ Kubyshkin V, Acevedo-Rocha CG, Budisa N (febrero de 2018). "Sobre eventos de codificación universal en la biogénesis de proteínas". Bio Systems . 164 : 16–25. Bibcode :2018BiSys.164...16K. doi : 10.1016/j.biosystems.2017.10.004 . PMID 29030023.
^ Heaphy SM, Mariotti M, Gladyshev VN, Atkins JF, Baranov PV (noviembre de 2016). "Nuevas variantes del código genético de los ciliados, incluida la reasignación de los tres codones de terminación a codones de sentido en Condylostoma magnum". Biología molecular y evolución . 33 (11): 2885–2889. doi :10.1093/molbev/msw166. PMC 5062323 . PMID 27501944.
^ Lobanov AV, Heaphy SM, Turanov AA, Gerashchenko MV, Pucciarelli S, Devaraj RR, et al. (enero de 2017). "Terminación dependiente de la posición y desplazamiento obligatorio generalizado del marco de lectura en la traducción de Euplotes". Nature Structural & Molecular Biology . 24 (1): 61–68. doi :10.1038/nsmb.3330. PMC 5295771 . PMID 27870834.
^ Koonin EV, Novozhilov AS (febrero de 2009). "Origen y evolución del código genético: el enigma universal". IUBMB Life . 61 (2): 91–111. doi :10.1002/iub.146. PMC 3293468 . PMID 19117371.
^ Sengupta S, Higgs PG (junio de 2015). "Vías de evolución del código genético en organismos antiguos y modernos". Journal of Molecular Evolution . 80 (5–6): 229–243. Bibcode :2015JMolE..80..229S. doi :10.1007/s00239-015-9686-8. PMID 26054480. S2CID 15542587.
^ Xie J, Schultz PG (agosto de 2006). "Un conjunto de herramientas químicas para las proteínas: un código genético ampliado". Nature Reviews Molecular Cell Biology . 7 (10): 775–782. doi :10.1038/nrm2005. PMID 16926858. S2CID 19385756.
^ Neumann H, Wang K, Davis L, Garcia-Alai M, Chin JW (marzo de 2010). "Codificación de múltiples aminoácidos no naturales mediante la evolución de un ribosoma decodificador de cuatrillizos". Nature . 18 (464): 441–444. doi :10.1038/nrm2005. PMID 16926858. S2CID 19385756.
^ Liu CC, Schultz PG (2010). "Añadir nuevas químicas al código genético". Revista anual de bioquímica . 79 : 413–444. doi :10.1146/annurev.biochem.052308.105824. PMID 20307192.
^ Chin JW (febrero de 2014). "Expansión y reprogramación del código genético de células y animales". Revista anual de bioquímica . 83 : 379–408. doi :10.1146/annurev-biochem-060713-035737. PMID 24555827.
^ Shulgina, Y; Eddy, SR (9 de noviembre de 2021). "Un análisis computacional de códigos genéticos alternativos en más de 250.000 genomas". eLife . 10 . doi : 10.7554/eLife.71402 . PMC 8629427 . PMID 34751130.
^ Chen, W; Geng, Y; Zhang, B; Yan, Y; Zhao, F; Miao, M (4 de abril de 2023). "Detenerse o no: perfil de todo el genoma de codones de detención reasignados en ciliados". Biología molecular y evolución . 40 (4). doi :10.1093/molbev/msad064. PMC 1008964 . PMID 36952281.
^ Ribas de Pouplana L, Turner RJ, Steer BA, Schimmel P (septiembre de 1998). "Orígenes del código genético: ¿ARNt más antiguos que sus sintetasas?". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 95 (19): 11295–300. Bibcode :1998PNAS...9511295D. doi : 10.1073/pnas.95.19.11295 . PMC 21636 . PMID 9736730.
^ ab Yarus, Michael (2010). La vida en un mundo de ARN: el ancestro interior. Harvard University Press. ISBN978-0-674-05075-4.
^ "¿Función de Mathematica para la cantidad de posibles disposiciones de elementos en contenedores? – Grupos de discusión técnica en línea—Comunidad Wolfram". community.wolfram.com . Consultado el 3 de febrero de 2017 .
^ ab Freeland SJ, Hurst LD (septiembre de 1998). "El código genético es uno en un millón". Journal of Molecular Evolution . 47 (3): 238–48. Bibcode :1998JMolE..47..238F. doi :10.1007/PL00006381. PMID 9732450. S2CID 20130470.
^ Taylor FJ, Coates D (1989). "El código dentro de los codones". Bio Systems . 22 (3): 177–87. Bibcode :1989BiSys..22..177T. doi :10.1016/0303-2647(89)90059-2. PMID 2650752.
^ Di Giulio M (octubre de 1989). "La extensión alcanzada por la minimización de las distancias de polaridad durante la evolución del código genético". Journal of Molecular Evolution . 29 (4): 288–93. Bibcode :1989JMolE..29..288D. doi :10.1007/BF02103616. PMID 2514270. S2CID 20803686.
^ Wong JT (febrero de 1980). "El papel de la minimización de las distancias químicas entre aminoácidos en la evolución del código genético". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 77 (2): 1083–6. Bibcode :1980PNAS...77.1083W. doi : 10.1073/pnas.77.2.1083 . PMC 348428 . PMID 6928661.
^ abcd Erives A (agosto de 2011). "Un modelo de enzimas de ARN proto-anticodón que requieren homoquiralidad de L-aminoácidos". Journal of Molecular Evolution . 73 (1–2): 10–22. Bibcode :2011JMolE..73...10E. doi :10.1007/s00239-011-9453-4. PMC 3223571 . PMID 21779963.
^ ab Freeland SJ, Knight RD, Landweber LF, Hurst LD (abril de 2000). "Fijación temprana de un código genético óptimo". Biología molecular y evolución . 17 (4): 511–18. doi : 10.1093/oxfordjournals.molbev.a026331 . PMID 10742043.
^ Crick FH (diciembre de 1968). "El origen del código genético". Journal of Molecular Evolution . 38 (3): 367–79. doi :10.1016/0022-2836(68)90392-6. PMID 4887876. S2CID 4144681.
^ Hopfield JJ (1978). "Origen del código genético: una hipótesis comprobable basada en la estructura, secuencia y corrección cinética del ARNt". PNAS . 75 (9): 4334–4338. Bibcode :1978PNAS...75.4334H. doi : 10.1073/pnas.75.9.4334 . PMC 336109 . PMID 279919.
^ ab Yarus M, Widmann JJ, Knight R (noviembre de 2009). "Unión de aminoácidos con ARN: una era estereoquímica para el código genético". Journal of Molecular Evolution . 69 (5): 406–29. Bibcode :2009JMolE..69..406Y. doi : 10.1007/s00239-009-9270-1 . PMID 19795157.
^ Brown, Sean M.; Voráček, Václav; Freeland, Stephen (5 de abril de 2023). "¿Cómo sería un alfabeto de aminoácidos extraterrestre y por qué?". Astrobiología . 23 (5): 536–549. Bibcode :2023AsBio..23..536B. doi :10.1089/ast.2022.0107. PMID 37022727. S2CID 257983174.
^ Knight RD, Freeland SJ, Landweber LF (junio de 1999). "Selección, historia y química: las tres caras del código genético". Tendencias en ciencias bioquímicas . 24 (6): 241–7. doi :10.1016/S0968-0004(99)01392-4. PMID 10366854.
^ Knight RD, Landweber LF (septiembre de 1998). "Rima o razón: interacciones ARN-arginina y el código genético". Química y biología . 5 (9): R215–20. doi : 10.1016/S1074-5521(98)90001-1 . PMID 9751648.
^ Sengupta S, Higgs PG (2015). "Vías de evolución del código genético en organismos antiguos y modernos". Journal of Molecular Evolution . 80 (5–6): 229–243. Bibcode :2015JMolE..80..229S. doi :10.1007/s00239-015-9686-8. PMID 26054480. S2CID 15542587.
^ Brooks DJ, Fresco JR, Lesk AM, Singh M (octubre de 2002). "Evolución de las frecuencias de aminoácidos en proteínas a lo largo del tiempo: orden inferido de introducción de aminoácidos en el código genético". Biología molecular y evolución . 19 (10): 1645–55. doi : 10.1093/oxfordjournals.molbev.a003988 . PMID 12270892.
^ Amirnovin R (mayo de 1997). "Un análisis de la teoría metabólica del origen del código genético". Journal of Molecular Evolution . 44 (5): 473–6. Bibcode :1997JMolE..44..473A. doi :10.1007/PL00006170. PMID 9115171. S2CID 23334860.
^ Ronneberg TA, Landweber LF, Freeland SJ (diciembre de 2000). "Prueba de una teoría biosintética del código genético: ¿hecho o artefacto?". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 97 (25): 13690–5. Bibcode :2000PNAS...9713690R. doi : 10.1073/pnas.250403097 . PMC 17637 . PMID 11087835.
^ Trifonov, Edward N. (septiembre de 2009). "El origen del código genético y de los primeros oligopéptidos". Investigación en microbiología . 160 (7): 481–486. doi :10.1016/j.resmic.2009.05.004. PMID 19524038.
^ Higgs, Paul G.; Pudritz, Ralph E. (junio de 2009). "Una base termodinámica para la síntesis de aminoácidos prebióticos y la naturaleza del primer código genético". Astrobiología . 9 (5): 483–490. arXiv : 0904.0402 . Bibcode :2009AsBio...9..483H. doi :10.1089/ast.2008.0280. ISSN 1531-1074. PMID 19566427. S2CID 9039622.
^ Chaliotis, Anargyros; Vlastaridis, Panayotis; Mossialos, Dimitris; Ibba, Michael; Becker, Hubert D.; Stathopoulos, Constantinos; Amoutzias, Grigorios D. (17 de febrero de 2017). "La compleja historia evolutiva de las aminoacil-ARNt sintetasas". Investigación de ácidos nucleicos . 45 (3): 1059–1068. doi :10.1093/nar/gkw1182. ISSN 0305-1048. PMC 5388404 . PMID 28180287.
^ Ntountoumi, Chrysa; Vlastaridis, Panayotis; Mossialos, Dimitris; Stathopoulos, Constantinos; Iliopoulos, Ioannis; Promponas, Vasilios; Oliver, Stephen G; Amoutzias, Grigoris D (4 de noviembre de 2019). "Las regiones de baja complejidad en las proteínas de los procariotas desempeñan papeles funcionales importantes y están altamente conservadas". Investigación de ácidos nucleicos . 47 (19): 9998–10009. doi :10.1093/nar/gkz730. ISSN 0305-1048. PMC 6821194 . PMID 31504783.
^ ab Freeland SJ, Wu T, Keulmann N (octubre de 2003). "El caso de un código genético estándar que minimiza los errores". Orígenes de la vida y evolución de la biosfera . 33 (4–5): 457–77. Bibcode :2003OLEB...33..457F. doi :10.1023/A:1025771327614. PMID 14604186. S2CID 18823745.
^ Baranov PV, Venin M, Provan G (2009). Gemmell NJ (ed.). "Reducción del tamaño del codón como origen del código genético de tripletes". PLOS ONE . 4 (5): e5708. Bibcode :2009PLoSO...4.5708B. doi : 10.1371/journal.pone.0005708 . PMC 2682656 . PMID 19479032.
^ Tlusty T (noviembre de 2007). "Un modelo para la aparición del código genético como una transición en un canal de información ruidoso". Journal of Theoretical Biology . 249 (2): 331–42. arXiv : 1007.4122 . Bibcode :2007JThBi.249..331T. doi :10.1016/j.jtbi.2007.07.029. PMID 17826800. S2CID 12206140.
^ Sonneborn TM (1965). Bryson V, Vogel H (eds.). Evolución de genes y proteínas . Nueva York: Academic Press. págs. 377–397.
^ Tlusty T (febrero de 2008). "Escenario de distorsión de velocidad para la aparición y evolución de códigos moleculares ruidosos". Physical Review Letters . 100 (4): 048101. arXiv : 1007.4149 . Bibcode :2008PhRvL.100d8101T. doi :10.1103/PhysRevLett.100.048101. PMID 18352335. S2CID 12246664.
^ Sella G, Ardell DH (septiembre de 2006). "La coevolución de los genes y los códigos genéticos: el accidente congelado de Crick revisitado". Journal of Molecular Evolution . 63 (3): 297–313. Bibcode :2006JMolE..63..297S. doi :10.1007/s00239-004-0176-7. PMID 16838217. S2CID 1260806.
^ Tlusty T (septiembre de 2010). "Un origen colorido para el código genético: teoría de la información, mecánica estadística y el surgimiento de códigos moleculares". Physics of Life Reviews . 7 (3): 362–76. arXiv : 1007.3906 . Bibcode :2010PhLRv...7..362T. doi :10.1016/j.plrev.2010.06.002. PMID 20558115. S2CID 1845965.
^ Jee J, Sundstrom A, Massey SE, Mishra B (noviembre de 2013). "¿Qué nos pueden decir los juegos de información asimétrica sobre el contexto del 'accidente congelado' de Crick?". Journal of the Royal Society, Interface . 10 (88): 20130614. doi :10.1098/rsif.2013.0614. PMC 3785830 . PMID 23985735.
^ Itzkovitz S, Alon U (2007). "El código genético es casi óptimo para permitir información adicional dentro de las secuencias codificantes de proteínas". Genome Research . 17 (4): 405–412. doi :10.1101/gr.5987307. PMC 1832087 . PMID 17293451.
Lectura adicional
Griffiths AJ, Miller JH, Suzuki DT, Lewontin RC, Gilbert WM (1999). Introducción al análisis genético (7.ª ed.). San Francisco: WH Freeman. ISBN 978-0-7167-3771-1.
Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Biología molecular de la célula (4.ª ed.). Nueva York: Garland Science. ISBN 978-0-8153-3218-3.
Lodish HF, Berk A, Zipursky SL, Matsudaira P, Baltimore D, Darnell JE (2000). Biología celular molecular (4.ª ed.). San Francisco: WH Freeman. ISBN 9780716737063.
Caskey CT, Leder P (abril de 2014). "El código del ARN: la piedra Rosetta de la naturaleza". Actas de la Academia Nacional de Ciencias de los Estados Unidos de América . 111 (16): 5758–9. Bibcode :2014PNAS..111.5758C. doi : 10.1073/pnas.1404819111 . PMC 4000803 . PMID 24756939.
Enlaces externos
Wikimedia Commons tiene medios relacionados con Código genético .
Los códigos genéticos: Tablas de códigos genéticos
Base de datos de uso de codones: tablas de frecuencia de codones para muchos organismos





{kind=link}