Modelo computacional utilizado en aprendizaje automático, basado en funciones jerárquicas conectadas
Una red neuronal artificial es un grupo de nodos interconectados, inspirado en una simplificación de las neuronas del cerebro . Aquí, cada nodo circular representa una neurona artificial y una flecha representa una conexión desde la salida de una neurona artificial hasta la entrada de otra.
Una ANN consta de unidades o nodos conectados llamados neuronas artificiales , que modelan vagamente las neuronas del cerebro. Estas están conectadas por bordes , que modelan las sinapsis del cerebro. Cada neurona artificial recibe señales de las neuronas conectadas, luego las procesa y envía una señal a otras neuronas conectadas. La "señal" es un número real , y la salida de cada neurona se calcula mediante una función no lineal de la suma de sus entradas, llamada función de activación . La fuerza de la señal en cada conexión está determinada por un peso , que se ajusta durante el proceso de aprendizaje.
Por lo general, las neuronas se agrupan en capas. Las diferentes capas pueden realizar diferentes transformaciones en sus entradas. Las señales viajan desde la primera capa (la capa de entrada ) hasta la última capa (la capa de salida ), posiblemente pasando por múltiples capas intermedias ( capas ocultas ). Una red se denomina típicamente red neuronal profunda si tiene al menos dos capas ocultas. [3]
Las redes neuronales artificiales se utilizan para diversas tareas, como el modelado predictivo , el control adaptativo y la resolución de problemas en el ámbito de la inteligencia artificial . Pueden aprender de la experiencia y extraer conclusiones de un conjunto de información complejo y aparentemente no relacionado.
Capacitación
Las redes neuronales se entrenan típicamente a través de la minimización de riesgos empíricos . Este método se basa en la idea de optimizar los parámetros de la red para minimizar la diferencia, o riesgo empírico, entre el resultado previsto y los valores objetivo reales en un conjunto de datos determinado. [4] Los métodos basados en gradientes, como la retropropagación, se utilizan generalmente para estimar los parámetros de la red. [4] Durante la fase de entrenamiento, las ANN aprenden de los datos de entrenamiento etiquetados actualizando iterativamente sus parámetros para minimizar una función de pérdida definida . [5] Este método permite que la red se generalice a datos no vistos.
Historia
Trabajos tempranos
Históricamente, las computadoras digitales evolucionaron a partir del modelo de von Neumann y funcionan mediante la ejecución de instrucciones explícitas con acceso a la memoria por parte de varios procesadores. Las redes neuronales, por otro lado, se originaron a partir de los esfuerzos por modelar el procesamiento de información en sistemas biológicos a través del marco del conexionismo . A diferencia del modelo de von Neumann, la computación conexionista no separa la memoria del procesamiento.
Warren McCulloch y Walter Pitts [7] (1943) consideraron un modelo computacional sin aprendizaje para redes neuronales. [8] Este modelo allanó el camino para que la investigación se dividiera en dos enfoques. Un enfoque se centró en los procesos biológicos, mientras que el otro se centró en la aplicación de redes neuronales a la inteligencia artificial .
A finales de la década de 1940, DO Hebb [9] propuso una hipótesis de aprendizaje basada en el mecanismo de plasticidad neuronal que se conoció como aprendizaje hebbiano . Se utilizó en muchas de las primeras redes neuronales, como el perceptrón de Rosenblatt y la red de Hopfield.
La invención del perceptrón despertó el interés del público por la investigación en redes neuronales artificiales, lo que provocó que el gobierno de Estados Unidos aumentara drásticamente la financiación de la investigación en aprendizaje profundo . Esto dio lugar a la «Edad de Oro de la IA», impulsada por las afirmaciones optimistas de los científicos informáticos sobre la capacidad de los perceptrones para emular la inteligencia humana. [15]
Red neuronal de invierno
En los años 1970 y 1980 se realizaron pocas investigaciones sobre las ANN, lo que supuso un "invierno de las redes neuronales". Un acontecimiento clave fue el perceptrón de Minsky y Papert (1969). [16] A esto le siguió un " invierno de la IA " general, [17] con una reducción de la investigación sobre la IA en general. El resto de la financiación gubernamental se destinó principalmente a la inteligencia artificial simbólica en los Estados Unidos y otros países occidentales. [18] [19]
La retropropagación es una aplicación eficiente de la regla de la cadena derivada por Gottfried Wilhelm Leibniz en 1673 [27] a redes de nodos diferenciables. La terminología "errores de retropropagación" fue introducida en 1962 por Rosenblatt, [28] pero no sabía cómo implementarla, aunque Henry J. Kelley tuvo un precursor continuo de la retropropagación en 1960 en el contexto de la teoría de control . [29] La forma moderna de retropropagación se desarrolló varias veces a principios de la década de 1970. La primera instancia publicada fue la tesis de maestría de Seppo Linnainmaa (1970). [30] [31] Paul Werbos la desarrolló de forma independiente en 1971, [32] pero tuvo dificultades para publicarla hasta 1982. [33] En 1986, David E. Rumelhart et al. popularizaron la retropropagación. [34]
La red neuronal con retardo temporal (TDNN) de Alex Waibel (1987) combinó convoluciones, reparto de peso y retropropagación. [39] [40] Algunas de las primeras demostraciones de CNN incluyeron el reconocimiento del alfabeto, [41] [42] y LeNet (1989) que reconoció códigos postales escritos a mano en el correo. [43] LeNet -5 (1998), una CNN de 7 niveles de Yann LeCun et al., [44] que clasifica dígitos, fue aplicada por varios bancos para reconocer números escritos a mano en cheques digitalizados en imágenes de 32x32 píxeles.
A partir de 1988, [45] [46] el uso de redes neuronales transformó el campo de la predicción de la estructura de proteínas , en particular cuando las primeras redes en cascada se entrenaron en perfiles (matrices) producidos por múltiples alineaciones de secuencias . [47]
Redes recurrentes
Un origen de las RNN fue la mecánica estadística . Shun'ichi Amari propuso en 1972 modificar los pesos de un modelo de Ising mediante la regla de aprendizaje de Hebb como un modelo de memoria asociativa, agregando el componente de aprendizaje. [48] Esto se popularizó como la red de Hopfield (1982). [49] Otro origen de las RNN fue la neurociencia. La palabra "recurrente" se utiliza para describir estructuras similares a bucles en anatomía. En 1901, Cajal observó "semicírculos recurrentes" en la corteza cerebelosa . [50] Hebb consideró el "circuito reverberante" como una explicación de la memoria a corto plazo. [51] El artículo de McCulloch y Pitts (1943) consideró redes neuronales que contienen ciclos y señaló que la actividad actual de dichas redes puede verse afectada por la actividad indefinidamente lejana en el pasado. [52]
Dos de los primeros trabajos influyentes fueron la red Jordan (1986) y la red Elman (1990), que aplicaron la RNN para estudiar la psicología cognitiva . En 1993, un sistema compresor de historia neuronal resolvió una tarea de "aprendizaje muy profundo" que requería más de 1000 capas sucesivas en una RNN desplegada en el tiempo. [53]
En 1991, la tesis de diploma de Sepp Hochreiter [54] identificó y analizó el problema del gradiente evanescente [54] [55] y propuso conexiones residuales recurrentes para resolverlo. Él y Schmidhuber introdujeron la memoria de corto plazo larga (LSTM), que estableció récords de precisión en múltiples dominios de aplicación. [56] [57] Esta todavía no era la versión moderna de LSTM, que requería la puerta de olvido, que se introdujo en 1999. [58] Se convirtió en la opción predeterminada para la arquitectura RNN.
Entre 2009 y 2012, las ANN comenzaron a ganar premios en concursos de reconocimiento de imágenes, acercándose al desempeño a nivel humano en varias tareas, inicialmente en reconocimiento de patrones y reconocimiento de escritura a mano . [63] [64] En 2011, una CNN llamada DanNet [65] [66] por Dan Ciresan, Ueli Meier, Jonathan Masci, Luca Maria Gambardella y Jürgen Schmidhuber logró por primera vez un desempeño sobrehumano en un concurso de reconocimiento de patrones visuales, superando a los métodos tradicionales por un factor de 3. [67] Luego ganó más concursos. [68] [69] También mostraron cómo la agrupación máxima de CNN en la GPU mejoró el rendimiento significativamente. [70]
En 2012, Ng y Dean crearon una red que aprendió a reconocer conceptos de nivel superior, como gatos, solo al observar imágenes sin etiquetas. [74] El preentrenamiento no supervisado y el mayor poder computacional de las GPU y la computación distribuida permitieron el uso de redes más grandes, particularmente en problemas de reconocimiento visual y de imágenes, lo que se conoció como "aprendizaje profundo". [5]
La red generativa antagónica (GAN) ( Ian Goodfellow et al., 2014) [76] se convirtió en el estado del arte en modelado generativo durante el período 2014-2018. La excelente calidad de imagen se logra con StyleGAN de Nvidia (2018) [77] basada en la GAN progresiva de Tero Karras et al. [78] Aquí, el generador de GAN crece de pequeña a gran escala de manera piramidal. La generación de imágenes por GAN alcanzó un éxito popular y provocó discusiones sobre deepfakes . [79] Los modelos de difusión (2015) [80] eclipsaron a las GAN en el modelado generativo desde entonces, con sistemas como DALL·E 2 (2022) y Stable Diffusion (2022).
En 2014, el estado del arte era entrenar “redes neuronales muy profundas” con 20 a 30 capas. [81] Apilar demasiadas capas condujo a una reducción pronunciada en la precisión del entrenamiento , [82] conocido como el problema de “degradación”. [83] En 2015, se desarrollaron dos técnicas simultáneamente para entrenar redes muy profundas: red de autopistas [84] y red neuronal residual (ResNet). [85] El equipo de investigación de ResNet intentó entrenar redes más profundas probando empíricamente varios trucos para entrenar redes más profundas hasta que descubrieron la arquitectura de red residual profunda. [86]
En 2017, Ashish Vaswani et al. presentaron la arquitectura Transformer moderna en su artículo "Attention Is All You Need". [87]
Combina esto con un operador softmax y una matriz de proyección. [38]
Los Transformers se han convertido cada vez más en el modelo de elección para el procesamiento del lenguaje natural . [88] Muchos modelos de lenguaje grandes modernos como ChatGPT , GPT-4 y BERT utilizan esta arquitectura.
Modelos
Neurona y axón mielinizado, con flujo de señales desde las entradas en las dendritas hasta las salidas en las terminales del axón.
Las ANN comenzaron como un intento de explotar la arquitectura del cerebro humano para realizar tareas con las que los algoritmos convencionales tenían poco éxito. Pronto se reorientaron hacia la mejora de los resultados empíricos, abandonando los intentos de permanecer fieles a sus precursores biológicos. Las ANN tienen la capacidad de aprender y modelar no linealidades y relaciones complejas. Esto se logra mediante la conexión de neuronas en varios patrones, lo que permite que la salida de algunas neuronas se convierta en la entrada de otras. La red forma un gráfico dirigido y ponderado . [89]
Una red neuronal artificial consta de neuronas simuladas. Cada neurona está conectada a otros nodos a través de enlaces , como una conexión biológica axón-sinapsis-dendrita. Todos los nodos conectados por enlaces toman algunos datos y los utilizan para realizar operaciones y tareas específicas con los datos. Cada enlace tiene un peso, que determina la fuerza de la influencia de un nodo sobre otro, [90] lo que permite que los pesos elijan la señal entre neuronas.
Neuronas artificiales
Las ANN están compuestas por neuronas artificiales que conceptualmente se derivan de neuronas biológicas . Cada neurona artificial tiene entradas y produce una única salida que puede enviarse a múltiples otras neuronas. [91] Las entradas pueden ser los valores característicos de una muestra de datos externos, como imágenes o documentos, o pueden ser las salidas de otras neuronas. Las salidas de las neuronas de salida finales de la red neuronal realizan la tarea, como reconocer un objeto en una imagen.
Para encontrar la salida de la neurona tomamos la suma ponderada de todas las entradas, ponderada por los pesos de las conexiones de las entradas a la neurona. A esta suma le añadimos un término de sesgo . [92] Esta suma ponderada a veces se denomina activación . Esta suma ponderada se pasa luego a través de una función de activación (normalmente no lineal) para producir la salida. Las entradas iniciales son datos externos, como imágenes y documentos. Las salidas finales realizan la tarea, como reconocer un objeto en una imagen. [93]
Organización
Las neuronas se organizan típicamente en múltiples capas, especialmente en el aprendizaje profundo . Las neuronas de una capa se conectan solo a las neuronas de las capas inmediatamente anteriores e inmediatamente posteriores. La capa que recibe datos externos es la capa de entrada . La capa que produce el resultado final es la capa de salida . Entre ellas hay cero o más capas ocultas . También se utilizan redes de una sola capa y sin capas. Entre dos capas, son posibles múltiples patrones de conexión. Pueden estar "completamente conectados", con cada neurona en una capa conectándose a cada neurona en la siguiente capa. Pueden ser agrupadas , donde un grupo de neuronas en una capa se conecta a una sola neurona en la siguiente capa, reduciendo así el número de neuronas en esa capa. [94] Las neuronas con solo tales conexiones forman un gráfico acíclico dirigido y se conocen como redes de propagación hacia adelante . [95] Alternativamente, las redes que permiten conexiones entre neuronas en la misma capa o en capas anteriores se conocen como redes recurrentes . [96]
Hiperparámetro
Un hiperparámetro es un parámetro constante cuyo valor se establece antes de que comience el proceso de aprendizaje. Los valores de los parámetros se derivan mediante el aprendizaje. Algunos ejemplos de hiperparámetros son la tasa de aprendizaje , la cantidad de capas ocultas y el tamaño del lote. [ cita requerida ] Los valores de algunos hiperparámetros pueden depender de los de otros hiperparámetros. Por ejemplo, el tamaño de algunas capas puede depender de la cantidad total de capas.
Aprendiendo
El aprendizaje es la adaptación de la red para manejar mejor una tarea considerando observaciones de muestra. El aprendizaje implica ajustar los pesos (y los umbrales opcionales) de la red para mejorar la precisión del resultado. Esto se hace minimizando los errores observados. El aprendizaje es completo cuando examinar observaciones adicionales no reduce de manera útil la tasa de error. Incluso después del aprendizaje, la tasa de error normalmente no llega a 0. Si después del aprendizaje, la tasa de error es demasiado alta, la red normalmente debe rediseñarse. En la práctica, esto se hace definiendo una función de costo que se evalúa periódicamente durante el aprendizaje. Mientras su salida continúe disminuyendo, el aprendizaje continúa. El costo se define con frecuencia como una estadística cuyo valor solo se puede aproximar. Las salidas son en realidad números, por lo que cuando el error es bajo, la diferencia entre la salida (casi con certeza un gato) y la respuesta correcta (cat) es pequeña. El aprendizaje intenta reducir el total de las diferencias entre las observaciones. La mayoría de los modelos de aprendizaje pueden verse como una aplicación directa de la teoría de optimización y la estimación estadística . [89] [97]
Tasa de aprendizaje
La tasa de aprendizaje define el tamaño de los pasos correctivos que el modelo toma para ajustar los errores en cada observación. [98] Una alta tasa de aprendizaje acorta el tiempo de entrenamiento, pero con una precisión final menor, mientras que una tasa de aprendizaje menor toma más tiempo, pero con el potencial de una mayor precisión. Las optimizaciones como Quickprop están dirigidas principalmente a acelerar la minimización de errores, mientras que otras mejoras intentan principalmente aumentar la confiabilidad. Para evitar la oscilación dentro de la red, como los pesos de conexión alternados, y para mejorar la tasa de convergencia, los refinamientos utilizan una tasa de aprendizaje adaptativa que aumenta o disminuye según sea apropiado. [99] El concepto de momento permite ponderar el equilibrio entre el gradiente y el cambio anterior de modo que el ajuste del peso dependa en algún grado del cambio anterior. Un momento cercano a 0 enfatiza el gradiente, mientras que un valor cercano a 1 enfatiza el último cambio.
Función de costo
Si bien es posible definir una función de costo ad hoc , con frecuencia la elección está determinada por las propiedades deseables de la función (como la convexidad ) o porque surge del modelo (por ejemplo, en un modelo probabilístico, la probabilidad posterior del modelo se puede utilizar como un costo inverso).
Retropropagación
La retropropagación es un método utilizado para ajustar los pesos de conexión para compensar cada error encontrado durante el aprendizaje. La cantidad de error se divide efectivamente entre las conexiones. Técnicamente, la retropropagación calcula el gradiente (la derivada) de la función de costo asociada con un estado dado con respecto a los pesos. Las actualizaciones de peso se pueden realizar mediante descenso de gradiente estocástico u otros métodos, como máquinas de aprendizaje extremo , [100] redes "sin prop", [101] entrenamiento sin retroceso, [102] redes "sin peso", [103] [104] y redes neuronales no conexionistas . [ cita requerida ]
El aprendizaje supervisado utiliza un conjunto de entradas pareadas y salidas deseadas. La tarea de aprendizaje es producir la salida deseada para cada entrada. En este caso, la función de costo está relacionada con la eliminación de deducciones incorrectas. [108] Un costo comúnmente utilizado es el error cuadrático medio , que intenta minimizar el error cuadrático medio entre la salida de la red y la salida deseada. Las tareas adecuadas para el aprendizaje supervisado son el reconocimiento de patrones (también conocido como clasificación) y la regresión (también conocida como aproximación de funciones). El aprendizaje supervisado también es aplicable a datos secuenciales (por ejemplo, para reconocimiento de escritura a mano, habla y gestos ). Esto puede considerarse como aprendizaje con un "maestro", en forma de una función que proporciona retroalimentación continua sobre la calidad de las soluciones obtenidas hasta el momento.
Aprendizaje no supervisado
En el aprendizaje no supervisado , los datos de entrada se proporcionan junto con la función de costo, alguna función de los datos y la salida de la red. La función de costo depende de la tarea (el dominio del modelo) y de cualquier suposición a priori (las propiedades implícitas del modelo, sus parámetros y las variables observadas). Como ejemplo trivial, considere el modelo donde es una constante y el costo . Minimizar este costo produce un valor de que es igual a la media de los datos. La función de costo puede ser mucho más complicada. Su forma depende de la aplicación: por ejemplo, en la compresión podría estar relacionada con la información mutua entre y , mientras que en el modelado estadístico, podría estar relacionada con la probabilidad posterior del modelo dados los datos (nótese que en ambos ejemplos, esas cantidades se maximizarían en lugar de minimizarse). Las tareas que caen dentro del paradigma del aprendizaje no supervisado son, en general, problemas de estimación ; las aplicaciones incluyen la agrupación en clústeres , la estimación de distribuciones estadísticas , la compresión y el filtrado .
Aprendizaje por refuerzo
En aplicaciones como los videojuegos, un actor realiza una serie de acciones, recibiendo una respuesta generalmente impredecible del entorno después de cada una. El objetivo es ganar el juego, es decir, generar las respuestas más positivas (de menor coste). En el aprendizaje por refuerzo , el objetivo es ponderar la red (idear una política) para realizar acciones que minimicen el coste a largo plazo (acumulativo esperado). En cada punto del tiempo, el agente realiza una acción y el entorno genera una observación y un coste instantáneo , de acuerdo con algunas reglas (normalmente desconocidas). Las reglas y el coste a largo plazo normalmente solo se pueden estimar. En cualquier coyuntura, el agente decide si explorar nuevas acciones para descubrir sus costes o explotar el aprendizaje previo para proceder más rápidamente.
Formalmente, el entorno se modela como un proceso de decisión de Markov (MDP) con estados y acciones . Como no se conocen las transiciones de estado, se utilizan en su lugar distribuciones de probabilidad: la distribución de costo instantáneo , la distribución de observación y la distribución de transición , mientras que una política se define como la distribución condicional sobre acciones dadas las observaciones. En conjunto, las dos definen una cadena de Markov (CM). El objetivo es descubrir la CM de menor costo.
Las ANN sirven como componente de aprendizaje en tales aplicaciones. [109] [110] La programación dinámica acoplada con ANN (dando programación neurodinámica ) [111] se ha aplicado a problemas tales como los relacionados con el enrutamiento de vehículos , [112] videojuegos, gestión de recursos naturales [113] [114] y medicina [115] debido a la capacidad de las ANN de mitigar pérdidas de precisión incluso cuando se reduce la densidad de la cuadrícula de discretización para aproximar numéricamente la solución de problemas de control. Las tareas que caen dentro del paradigma del aprendizaje de refuerzo son problemas de control, juegos y otras tareas de toma de decisiones secuenciales.
Autoaprendizaje
El autoaprendizaje en redes neuronales se introdujo en 1982 junto con una red neuronal capaz de autoaprender llamada matriz adaptativa de barras cruzadas (CAA). [116] Es un sistema con una sola entrada, la situación s, y una sola salida, la acción (o comportamiento) a. No tiene ni entrada de consejo externo ni entrada de refuerzo externo del entorno. El CAA calcula, en forma de barras cruzadas, tanto las decisiones sobre acciones como las emociones (sentimientos) sobre las situaciones encontradas. El sistema está impulsado por la interacción entre la cognición y la emoción. [117] Dada la matriz de memoria, W =||w(a,s)||, el algoritmo de autoaprendizaje de barras cruzadas en cada iteración realiza el siguiente cálculo:
En la situación s realizar la acción a; Recibir situaciones de consecuencia; Calcular la emoción de estar en la situación de consecuencia v(s'); Actualizar la memoria de la barra transversal w'(a,s) = w(a,s) + v(s').
El valor retropropagado (reforzamiento secundario) es la emoción hacia la situación de consecuencia. El CAA existe en dos entornos, uno es el entorno conductual donde se comporta, y el otro es el entorno genético, de donde inicialmente y sólo una vez recibe emociones iniciales acerca de las situaciones que se van a encontrar en el entorno conductual. Habiendo recibido el vector genómico (vector de especie) del entorno genético, el CAA aprenderá una conducta de búsqueda de objetivos, en el entorno conductual que contiene situaciones tanto deseables como indeseables. [118]
Neuroevolución
La neuroevolución puede crear topologías y ponderaciones de redes neuronales mediante el uso de cálculos evolutivos . Es competitiva con los sofisticados enfoques de descenso de gradientes. [119] [120] Una ventaja de la neuroevolución es que puede ser menos propensa a quedar atrapada en "callejones sin salida". [121]
Red neuronal estocástica
Las redes neuronales estocásticas que se originan a partir de los modelos de Sherrington-Kirkpatrick son un tipo de red neuronal artificial construida mediante la introducción de variaciones aleatorias en la red, ya sea dándoles funciones de transferencia estocásticas a las neuronas artificiales de la red o dándoles pesos estocásticos. Esto las convierte en herramientas útiles para problemas de optimización , ya que las fluctuaciones aleatorias ayudan a la red a escapar de los mínimos locales . [122] Las redes neuronales estocásticas entrenadas utilizando un enfoque bayesiano se conocen como redes neuronales bayesianas . [123]
Existen dos modos de aprendizaje: estocástico y por lotes. En el aprendizaje estocástico, cada entrada crea un ajuste de peso. En el aprendizaje por lotes, los pesos se ajustan en función de un lote de entradas, acumulando errores a lo largo del lote. El aprendizaje estocástico introduce "ruido" en el proceso, utilizando el gradiente local calculado a partir de un punto de datos; esto reduce la posibilidad de que la red se quede atascada en mínimos locales. Sin embargo, el aprendizaje por lotes generalmente produce un descenso más rápido y más estable a un mínimo local, ya que cada actualización se realiza en la dirección del error promedio del lote. Un compromiso común es utilizar "minilotes", lotes pequeños con muestras en cada lote seleccionadas estocásticamente de todo el conjunto de datos.
Tipos
Las ANN han evolucionado hasta convertirse en una amplia familia de técnicas que han hecho avanzar el estado del arte en múltiples dominios. Los tipos más simples tienen uno o más componentes estáticos, que incluyen número de unidades, número de capas, pesos de unidad y topología . Los tipos dinámicos permiten que uno o más de estos evolucionen mediante el aprendizaje. Este último es mucho más complicado, pero puede acortar los períodos de aprendizaje y producir mejores resultados. Algunos tipos permiten/requieren que el aprendizaje sea "supervisado" por el operador, mientras que otros funcionan de forma independiente. Algunos tipos funcionan puramente en hardware, mientras que otros son puramente software y se ejecutan en computadoras de propósito general.
Algunos de los principales avances incluyen:
Redes neuronales convolucionales que han demostrado ser particularmente exitosas en el procesamiento de datos visuales y otros datos bidimensionales; [130] [131] donde la memoria a corto plazo evita el problema del gradiente de desaparición [132] y puede manejar señales que tienen una mezcla de componentes de baja y alta frecuencia que ayudan al reconocimiento de voz de vocabulario amplio, [133] [134] síntesis de texto a voz, [135] [136] [137] y cabezas parlantes fotorrealistas; [138]
Redes competitivas como las redes generativas adversarias en las que múltiples redes (de estructura variable) compiten entre sí en tareas como ganar un juego [139] o engañar al oponente sobre la autenticidad de una entrada. [140]
Diseño de red
El uso de redes neuronales artificiales requiere una comprensión de sus características.
Elección del modelo: Depende de la representación de los datos y de la aplicación. Los parámetros del modelo incluyen el número, el tipo y la conectividad de las capas de red, así como el tamaño de cada una de ellas y el tipo de conexión (completa, agrupación, etc.). Los modelos demasiado complejos aprenden lentamente.
Algoritmo de aprendizaje : existen numerosas compensaciones entre los algoritmos de aprendizaje. Casi cualquier algoritmo funcionará bien con los hiperparámetros correctos [141] para el entrenamiento en un conjunto de datos en particular. Sin embargo, la selección y el ajuste de un algoritmo para el entrenamiento en datos no vistos requiere una experimentación significativa.
Robustez : si el modelo, la función de costo y el algoritmo de aprendizaje se seleccionan adecuadamente, la ANN resultante puede volverse robusta.
La búsqueda de arquitectura neuronal (NAS) utiliza el aprendizaje automático para automatizar el diseño de ANN. Varios enfoques de NAS han diseñado redes que se comparan bien con los sistemas diseñados a mano. El algoritmo de búsqueda básico es proponer un modelo candidato, evaluarlo contra un conjunto de datos y usar los resultados como retroalimentación para enseñarle a la red NAS. [142] Los sistemas disponibles incluyen AutoML y AutoKeras. [143] La biblioteca scikit-learn proporciona funciones para ayudar con la construcción de una red profunda desde cero. Luego podemos implementar una red profunda con TensorFlow o Keras .
Los hiperparámetros también deben definirse como parte del diseño (no se aprenden) y rigen cuestiones como cuántas neuronas hay en cada capa, tasa de aprendizaje, paso, zancada, profundidad, campo receptivo y relleno (para CNN), etc. [144]
El fragmento de código de Python proporciona una descripción general de la función de entrenamiento, que utiliza el conjunto de datos de entrenamiento, la cantidad de unidades de capa oculta, la tasa de aprendizaje y la cantidad de iteraciones como parámetros:
def tren ( X , y , n_oculto , tasa_de_aprendizaje , n_iter ):m , n_entrada = X . forma# 1. inicialización aleatoria de pesos y sesgosw1 = np . random . randn ( n_entrada , n_oculto )b1 = np . ceros (( 1 , n_oculto ))w2 = np . aleatorio . randn ( n_oculto , 1 )b2 = np . ceros (( 1 , 1 ))# 2. En cada iteración, alimente todas las capas con los últimos pesos y sesgos.para i en el rango ( n_iter + 1 ):z2 = np . punto ( X , w1 ) + b1a2 = sigmoide ( z2 )z3 = np . punto ( a2 , w2 ) + b2a3 = z3dz3 = a3 - ydw2 = np . punto ( a2 . T , dz3 )db2 = np . suma ( dz3 , eje = 0 , keepdims = True )dz2 = np . punto ( dz3 , w2 . T ) * derivada_sigmoidea ( z2 )dw1 = np . punto ( X . T , dz2 )db1 = np . suma ( dz2 , eje = 0 )# 3. Actualizar pesos y sesgos con gradientesw1 -= tasa de aprendizaje * dw1 / mw2 -= tasa de aprendizaje * dw2 / mb1 -= tasa de aprendizaje * db1 / mb2 -= tasa_de_aprendizaje * db2 / msi i % 1000 == 0 :imprimir ( " Época" , i , " pérdida:" , np.media ( np.cuadrado ( dz3 ) ) )modelo = { "w1" : w1 , "b1" : b1 , "w2" : w2 , "b2" : b2 }modelo de retorno
Debido a su capacidad para reproducir y modelar procesos no lineales, las redes neuronales artificiales han encontrado aplicaciones en muchas disciplinas, entre ellas:
Las ANN se han utilizado para diagnosticar varios tipos de cáncer [161] [162] y para distinguir líneas celulares de cáncer altamente invasivas de líneas menos invasivas utilizando solo información sobre la forma de la célula. [163] [164]
Las ANN se han utilizado para acelerar el análisis de confiabilidad de infraestructuras sujetas a desastres naturales [165] [166] y para predecir asentamientos de cimientos. [167] También puede ser útil para mitigar inundaciones mediante el uso de ANN para modelar lluvia-escorrentía. [168] Las ANN también se han utilizado para construir modelos de caja negra en geociencia : hidrología , [169] [170] modelado oceánico e ingeniería costera , [171] [172] y geomorfología . [173] Las ANN se han empleado en ciberseguridad , con el objetivo de discriminar entre actividades legítimas y maliciosas. Por ejemplo, el aprendizaje automático se ha utilizado para clasificar malware de Android, [174] para identificar dominios que pertenecen a actores de amenazas y para detectar URL que representan un riesgo de seguridad. [175] Se están realizando investigaciones sobre sistemas ANN diseñados para pruebas de penetración, para detectar botnets, [176] fraudes con tarjetas de crédito [177] e intrusiones en la red.
Las ANN se han propuesto como una herramienta para resolver ecuaciones diferenciales parciales en física [178] [179] [180] y simular las propiedades de sistemas cuánticos abiertos de muchos cuerpos . [181] [182] [183] [184] En la investigación del cerebro, las ANN han estudiado el comportamiento a corto plazo de neuronas individuales , [185] la dinámica de los circuitos neuronales surge de las interacciones entre neuronas individuales y cómo el comportamiento puede surgir de módulos neuronales abstractos que representan subsistemas completos. Los estudios consideraron la plasticidad a largo y corto plazo de los sistemas neuronales y su relación con el aprendizaje y la memoria desde la neurona individual hasta el nivel del sistema.
Es posible crear un perfil de los intereses de un usuario a partir de imágenes, utilizando redes neuronales artificiales entrenadas para el reconocimiento de objetos. [186]
Más allá de sus aplicaciones tradicionales, las redes neuronales artificiales se utilizan cada vez más en la investigación interdisciplinaria, como la ciencia de los materiales. Por ejemplo, las redes neuronales de grafos (GNN) han demostrado su capacidad para escalar el aprendizaje profundo para el descubrimiento de nuevos materiales estables al predecir de manera eficiente la energía total de los cristales. Esta aplicación subraya la adaptabilidad y el potencial de las ANN para abordar problemas complejos más allá de los ámbitos del modelado predictivo y la inteligencia artificial, abriendo nuevos caminos para el descubrimiento científico y la innovación. [187]
La propiedad de "capacidad" de un modelo corresponde a su capacidad para modelar cualquier función dada. Está relacionada con la cantidad de información que se puede almacenar en la red y con la noción de complejidad. La comunidad conoce dos nociones de capacidad: la capacidad de información y la dimensión VC. La capacidad de información de un perceptrón se analiza en profundidad en el libro de Sir David MacKay [191] , que resume el trabajo de Thomas Cover. [192] La capacidad de una red de neuronas estándar (no convolucional) se puede derivar de cuatro reglas [193] que se derivan de entender una neurona como un elemento eléctrico. La capacidad de información captura las funciones modelables por la red dados los datos de entrada. La segunda noción es la dimensión VC . La dimensión VC utiliza los principios de la teoría de la medida y encuentra la capacidad máxima en las mejores circunstancias posibles. Esto es, dados los datos de entrada en una forma específica. Como se señala en [191] , la dimensión VC para entradas arbitrarias es la mitad de la capacidad de información de un perceptrón. La dimensión VC para puntos arbitrarios a veces se denomina capacidad de memoria. [194]
Convergencia
Es posible que los modelos no converjan de manera consistente en una única solución, en primer lugar porque pueden existir mínimos locales, dependiendo de la función de costo y del modelo. En segundo lugar, el método de optimización utilizado podría no garantizar la convergencia cuando comienza lejos de cualquier mínimo local. En tercer lugar, para datos o parámetros suficientemente grandes, algunos métodos se vuelven imprácticos.
Otra cuestión que vale la pena mencionar es que el entrenamiento puede cruzar algún punto de silla , lo que puede llevar la convergencia a la dirección equivocada.
El comportamiento de convergencia de ciertos tipos de arquitecturas de ANN se entiende mejor que otros. Cuando el ancho de la red se acerca al infinito, la ANN está bien descrita por su expansión de Taylor de primer orden a lo largo del entrenamiento, y por lo tanto hereda el comportamiento de convergencia de los modelos afines . [195] [196] Otro ejemplo es cuando los parámetros son pequeños, se observa que las ANN a menudo ajustan funciones objetivo de frecuencias bajas a altas. Este comportamiento se conoce como el sesgo espectral, o principio de frecuencia, de las redes neuronales. [197] [198] [199] [200] Este fenómeno es opuesto al comportamiento de algunos esquemas numéricos iterativos bien estudiados como el método de Jacobi . Se ha observado que las redes neuronales más profundas están más sesgadas hacia funciones de baja frecuencia. [201]
Generalización y estadística
Las aplicaciones cuyo objetivo es crear un sistema que se generalice bien a ejemplos no vistos se enfrentan a la posibilidad de un sobreentrenamiento. Esto surge en sistemas complejos o sobreespecificados cuando la capacidad de la red excede significativamente los parámetros libres necesarios. Hay dos enfoques que abordan el sobreentrenamiento. El primero es utilizar la validación cruzada y técnicas similares para verificar la presencia de sobreentrenamiento y seleccionar hiperparámetros para minimizar el error de generalización.
La segunda es utilizar alguna forma de regularización . Este concepto surge en un marco probabilístico (bayesiano), donde la regularización se puede realizar seleccionando una probabilidad previa mayor sobre modelos más simples; pero también en la teoría del aprendizaje estadístico, donde el objetivo es minimizar más de dos cantidades: el "riesgo empírico" y el "riesgo estructural", que corresponde aproximadamente al error sobre el conjunto de entrenamiento y el error previsto en datos no vistos debido al sobreajuste.
Análisis de confianza de una red neuronal
Las redes neuronales supervisadas que utilizan una función de costo de error cuadrático medio (MSE) pueden utilizar métodos estadísticos formales para determinar la confianza del modelo entrenado. El MSE en un conjunto de validación se puede utilizar como una estimación de la varianza. Este valor se puede utilizar para calcular el intervalo de confianza de la salida de la red, suponiendo una distribución normal . Un análisis de confianza realizado de esta manera es estadísticamente válido siempre que la distribución de probabilidad de salida permanezca igual y la red no se modifique.
Al asignar una función de activación softmax , una generalización de la función logística , en la capa de salida de la red neuronal (o un componente softmax en una red basada en componentes) para las variables objetivo categóricas, las salidas se pueden interpretar como probabilidades posteriores. Esto es útil en la clasificación, ya que proporciona una medida de certeza sobre las clasificaciones.
La función de activación softmax es:
Crítica
Capacitación
Una crítica común a las redes neuronales, particularmente en robótica, es que requieren demasiadas muestras de entrenamiento para operar en el mundo real. [202]
Cualquier máquina de aprendizaje necesita suficientes ejemplos representativos para capturar la estructura subyacente que le permite generalizar a nuevos casos. Las posibles soluciones incluyen mezclar aleatoriamente los ejemplos de entrenamiento, mediante el uso de un algoritmo de optimización numérica que no da pasos demasiado grandes al cambiar las conexiones de red después de un ejemplo, agrupar los ejemplos en los llamados minilotes y/o introducir un algoritmo de mínimos cuadrados recursivo para CMAC . [128]
Dean Pomerleau usa una red neuronal para entrenar un vehículo robótico para que conduzca en múltiples tipos de carreteras (de un solo carril, de varios carriles, de tierra, etc.), y una gran parte de su investigación está dedicada a extrapolar múltiples escenarios de entrenamiento a partir de una única experiencia de entrenamiento y preservar la diversidad de entrenamientos anteriores para que el sistema no se sobreentrene (si, por ejemplo, se le presenta una serie de giros a la derecha, no debería aprender a girar siempre a la derecha). [203]
Teoría
Una afirmación central [ cita requerida ] de las ANN es que incorporan principios generales nuevos y poderosos para procesar información. Estos principios están mal definidos. A menudo se afirma [ ¿por quién? ] que emergen de la red misma. Esto permite que la asociación estadística simple (la función básica de las redes neuronales artificiales) se describa como aprendizaje o reconocimiento. En 1997, Alexander Dewdney , un ex columnista de Scientific American , comentó que, como resultado, las redes neuronales artificiales tienen una "calidad de algo por nada, que imparte un aura peculiar de pereza y una clara falta de curiosidad sobre cuán buenos son estos sistemas informáticos. No interviene ninguna mano (o mente) humana; las soluciones se encuentran como por arte de magia; y nadie, al parecer, ha aprendido nada". [204] Una respuesta a Dewdney es que las redes neuronales se han utilizado con éxito para manejar muchas tareas complejas y diversas, que van desde volar aviones de forma autónoma [205] hasta detectar fraudes con tarjetas de crédito o dominar el juego de Go .
El escritor de tecnología Roger Bridgman comentó:
Las redes neuronales, por ejemplo, están en el banquillo no sólo porque han sido promocionadas hasta el cielo (¿qué no?), sino también porque se podría crear una red exitosa sin entender cómo funciona: el conjunto de números que captura su comportamiento sería con toda probabilidad "una tabla opaca, ilegible... sin valor como recurso científico".
A pesar de su enfática declaración de que la ciencia no es tecnología, Dewdney parece aquí poner en la picota las redes neuronales como mala ciencia, cuando la mayoría de quienes las idean sólo intentan ser buenos ingenieros. Una tabla ilegible que una máquina útil pudiera leer seguiría siendo digna de tener. [206]
Si bien es cierto que analizar lo aprendido por una red neuronal artificial es difícil, es mucho más fácil hacerlo que analizar lo aprendido por una red neuronal biológica. Además, el énfasis reciente en la explicabilidad de la IA ha contribuido al desarrollo de métodos, en particular los basados en mecanismos de atención , para visualizar y explicar las redes neuronales aprendidas. Además, los investigadores involucrados en la exploración de algoritmos de aprendizaje para redes neuronales están descubriendo gradualmente principios genéricos que permiten que una máquina de aprendizaje tenga éxito. Por ejemplo, Bengio y LeCun (2007) escribieron un artículo sobre el aprendizaje local frente al no local, así como sobre la arquitectura superficial frente a la profunda. [207]
Los cerebros biológicos utilizan circuitos superficiales y profundos, como lo indica la anatomía cerebral [208], que muestra una amplia variedad de invariancia. Weng [209] sostuvo que el cerebro se autoconecta en gran medida de acuerdo con las estadísticas de señales y, por lo tanto, una cascada serial no puede captar todas las dependencias estadísticas principales.
Hardware
Las redes neuronales grandes y eficaces requieren considerables recursos informáticos. [210] Si bien el cerebro tiene hardware adaptado a la tarea de procesar señales a través de un gráfico de neuronas, simular incluso una neurona simplificada en la arquitectura de von Neumann puede consumir enormes cantidades de memoria y almacenamiento. Además, el diseñador a menudo necesita transmitir señales a través de muchas de estas conexiones y sus neuronas asociadas, lo que requiere una enorme potencia de CPU y tiempo.
Algunos sostienen que el resurgimiento de las redes neuronales en el siglo XXI se debe en gran medida a los avances en hardware: de 1991 a 2015, la potencia informática, especialmente la proporcionada por las GPGPU (en las GPU ), ha aumentado alrededor de un millón de veces, lo que hace que el algoritmo de retropropagación estándar sea factible para entrenar redes que son varias capas más profundas que antes. [211] El uso de aceleradores como FPGAs y GPU puede reducir los tiempos de entrenamiento de meses a días. [210] [212]
La ingeniería neuromórfica o red neuronal física aborda la dificultad del hardware directamente, mediante la construcción de chips que no son de von Neumann para implementar directamente redes neuronales en circuitos. Otro tipo de chip optimizado para el procesamiento de redes neuronales se denomina unidad de procesamiento tensorial o TPU. [213]
Contraejemplos prácticos
Analizar lo que ha aprendido una ANN es mucho más fácil que analizar lo que ha aprendido una red neuronal biológica. Además, los investigadores que se dedican a explorar algoritmos de aprendizaje para redes neuronales están descubriendo gradualmente principios generales que permiten que una máquina de aprendizaje tenga éxito. Por ejemplo, aprendizaje local vs. no local y arquitectura superficial vs. profunda. [214]
Enfoques híbridos
Los defensores de los modelos híbridos (que combinan redes neuronales y enfoques simbólicos) dicen que esa mezcla puede captar mejor los mecanismos de la mente humana. [215] [216]
Sesgo del conjunto de datos
Las redes neuronales dependen de la calidad de los datos con los que se entrenan, por lo que los datos de baja calidad con representatividad desequilibrada pueden llevar al modelo a aprender y perpetuar sesgos sociales. [217] [218] Estos sesgos heredados se vuelven especialmente críticos cuando las ANN se integran en escenarios del mundo real donde los datos de entrenamiento pueden estar desequilibrados debido a la escasez de datos para una raza, género u otro atributo específico. [217] Este desequilibrio puede resultar en que el modelo tenga una representación y comprensión inadecuadas de los grupos subrepresentados, lo que lleva a resultados discriminatorios que exasperan las desigualdades sociales, especialmente en aplicaciones como el reconocimiento facial , los procesos de contratación y la aplicación de la ley . [218] [219] Por ejemplo, en 2018, Amazon tuvo que descartar una herramienta de reclutamiento porque el modelo favorecía a los hombres sobre las mujeres para trabajos en ingeniería de software debido al mayor número de trabajadores masculinos en el campo. [219] El programa penalizaría cualquier currículum con la palabra "mujer" o el nombre de cualquier universidad de mujeres. Sin embargo, el uso de datos sintéticos puede ayudar a reducir el sesgo del conjunto de datos y aumentar la representación en los conjuntos de datos. [220]
Galería
Red neuronal artificial de una sola capa con retroalimentación positiva. Las flechas que se originan en se omiten para mayor claridad. Hay p entradas en esta red y q salidas. En este sistema, el valor de la q-ésima salida, , se calcula como
Una red neuronal artificial de dos capas con retroalimentación positiva
Una red neuronal artificial
Un gráfico de dependencia de ANN
Red neuronal artificial de una sola capa con 4 entradas, 6 nodos ocultos y 2 salidas. En función de la posición y la dirección, genera valores de control basados en las ruedas.
Red neuronal artificial de dos capas con 8 entradas, 2x8 nodos ocultos y 2 salidas. En función de la posición, la dirección y otros valores del entorno, genera valores de control basados en el propulsor.
Estructura de canalización paralela de la red neuronal CMAC. Este algoritmo de aprendizaje puede converger en un solo paso.
Avances recientes y direcciones futuras
Las redes neuronales artificiales (RNA) han experimentado avances significativos, en particular en su capacidad para modelar sistemas complejos, manejar grandes conjuntos de datos y adaptarse a diversos tipos de aplicaciones. Su evolución en las últimas décadas ha estado marcada por una amplia gama de aplicaciones en campos como el procesamiento de imágenes, el reconocimiento de voz, el procesamiento del lenguaje natural, las finanzas y la medicina.
Procesamiento de imágenes
En el ámbito del procesamiento de imágenes, las ANN se emplean en tareas como la clasificación de imágenes, el reconocimiento de objetos y la segmentación de imágenes. Por ejemplo, las redes neuronales convolucionales profundas (CNN) han sido importantes en el reconocimiento de dígitos escritos a mano, logrando un rendimiento de vanguardia. [221] Esto demuestra la capacidad de las ANN para procesar e interpretar eficazmente información visual compleja, lo que conduce a avances en campos que van desde la vigilancia automatizada hasta la imagenología médica. [221]
Reconocimiento de voz
Al modelar las señales de voz, las ANN se utilizan para tareas como la identificación del hablante y la conversión de voz a texto. Las arquitecturas de redes neuronales profundas han introducido mejoras significativas en el reconocimiento continuo de voz de vocabulario amplio, superando a las técnicas tradicionales. [221] [222] Estos avances han permitido el desarrollo de sistemas activados por voz más precisos y eficientes, mejorando las interfaces de usuario en productos tecnológicos.
Procesamiento del lenguaje natural
En el procesamiento del lenguaje natural, las ANN se utilizan para tareas como la clasificación de texto, el análisis de sentimientos y la traducción automática. Han permitido el desarrollo de modelos que pueden traducir con precisión entre idiomas, comprender el contexto y el sentimiento en datos textuales y categorizar el texto en función del contenido. [221] [222] Esto tiene implicaciones para el servicio de atención al cliente automatizado, la moderación de contenido y las tecnologías de comprensión del lenguaje.
Sistemas de control
En el campo de los sistemas de control, las redes neuronales artificiales se utilizan para modelar sistemas dinámicos para tareas como la identificación de sistemas, el diseño de control y la optimización. Por ejemplo, las redes neuronales de propagación hacia adelante profundas son importantes en las aplicaciones de identificación y control de sistemas.
En materia de inversiones, las ANN pueden procesar grandes cantidades de datos financieros, reconocer patrones complejos y pronosticar tendencias del mercado de valores, ayudando a los inversores y gestores de riesgos a tomar decisiones informadas. [221]
En la calificación crediticia, las ANN ofrecen evaluaciones personalizadas de la solvencia crediticia basadas en datos, mejorando la precisión de las predicciones de incumplimiento y automatizando el proceso de préstamo. [222]
Las ANN requieren datos de alta calidad y un ajuste cuidadoso, y su naturaleza de "caja negra" puede plantear desafíos en la interpretación. Sin embargo, los avances en curso sugieren que las ANN siguen desempeñando un papel en las finanzas, ofreciendo información valiosa y mejorando las estrategias de gestión de riesgos .
Medicamento
Las ANN pueden procesar y analizar grandes conjuntos de datos médicos. Mejoran la precisión diagnóstica, especialmente al interpretar imágenes médicas complejas para la detección temprana de enfermedades y al predecir los resultados del paciente para la planificación personalizada del tratamiento. [222] En el descubrimiento de fármacos, las ANN aceleran la identificación de posibles candidatos a fármacos y predicen su eficacia y seguridad, lo que reduce significativamente el tiempo y los costos de desarrollo. [221] Además, su aplicación en la medicina personalizada y el análisis de datos de atención médica permite terapias a medida y una gestión eficiente de la atención al paciente. [222] La investigación en curso tiene como objetivo abordar los desafíos restantes, como la privacidad de los datos y la interpretabilidad de los modelos, así como ampliar el alcance de las aplicaciones de las ANN en medicina.
Creación de contenido
Las ANN como las redes generativas antagónicas ( GAN ) y los transformadores se utilizan para la creación de contenido en numerosas industrias. [223] Esto se debe a que los modelos de aprendizaje profundo pueden aprender el estilo de un artista o músico a partir de enormes conjuntos de datos y generar obras de arte y composiciones musicales completamente nuevas. Por ejemplo, DALL-E es una red neuronal profunda entrenada en 650 millones de pares de imágenes y textos en Internet que puede crear obras de arte basadas en el texto ingresado por el usuario. [224] En el campo de la música, los transformadores se utilizan para crear música original para comerciales y documentales a través de empresas como AIVA y Jukedeck . [225] En la industria del marketing, los modelos generativos se utilizan para crear anuncios personalizados para los consumidores. [223] Además, las principales compañías cinematográficas se están asociando con empresas de tecnología para analizar el éxito financiero de una película, como la asociación entre Warner Bros y la empresa de tecnología Cinelytic establecida en 2020. [226] Además, las redes neuronales han encontrado usos en la creación de videojuegos, donde los personajes no jugadores (NPC) pueden tomar decisiones basadas en todos los personajes que están actualmente en el juego. [227]
Este archivo de audio se creó a partir de una revisión de este artículo con fecha del 27 de noviembre de 2011 y no refleja ediciones posteriores. (2011-11-27)
Una breve introducción a las redes neuronales (D. Kriesel) - Manuscrito ilustrado y bilingüe sobre redes neuronales artificiales; Temas hasta el momento: Perceptrones, retropropagación, funciones de base radial, redes neuronales recurrentes, mapas autoorganizados, redes de Hopfield.
Revisión de redes neuronales en ciencia de materiales Archivado el 7 de junio de 2015 en Wayback Machine
Tutorial de Redes Neuronales Artificiales en tres idiomas (Univ. Politécnica de Madrid)
Otra introducción a ANN
La próxima generación de redes neuronales Archivado el 24 de enero de 2011 en Wayback Machine - Google Tech Talks
Rendimiento de las redes neuronales
Redes neuronales e información Archivado el 9 de julio de 2009 en Wayback Machine.
Sanderson G (5 de octubre de 2017). «Pero, ¿qué es una red neuronal?». 3Blue1Brown . Archivado desde el original el 7 de noviembre de 2021 – vía YouTube .
Notas
Referencias
^ Hardesty L (14 de abril de 2017). «Explicación: redes neuronales». Oficina de noticias del MIT. Archivado desde el original el 18 de marzo de 2024. Consultado el 2 de junio de 2022 .
^ Yang Z, Yang Z (2014). Física biomédica integral. Instituto Karolinska, Estocolmo, Suecia: Elsevier. p. 1. ISBN978-0-444-53633-4Archivado del original el 28 de julio de 2022 . Consultado el 28 de julio de 2022 .
^ Bishop CM (17 de agosto de 2006). Reconocimiento de patrones y aprendizaje automático . Nueva York: Springer. ISBN978-0-387-31073-2.
^ ab Vapnik VN, Vapnik VN (1998). La naturaleza de la teoría del aprendizaje estadístico (2.ª edición corregida). Nueva York, Berlín, Heidelberg: Springer. ISBN978-0-387-94559-0.
^ ab Ian Goodfellow y Yoshua Bengio y Aaron Courville (2016). Deep Learning. MIT Press. Archivado desde el original el 16 de abril de 2016 . Consultado el 1 de junio de 2016 .
^ Ferrie, C., Kaiser, S. (2019). Redes neuronales para bebés . Libros de consulta. ISBN978-1-4926-7120-6.
^ McCulloch W, Walter Pitts (1943). "Un cálculo lógico de ideas inmanentes en la actividad nerviosa". Boletín de biofísica matemática . 5 (4): 115–133. doi :10.1007/BF02478259.
^ Kleene S (1956). "Representación de eventos en redes nerviosas y autómatas finitos". Anales de estudios matemáticos . N.º 34. Princeton University Press. págs. 3–41 . Consultado el 17 de junio de 2017 .
^ Hebb D (1949). La organización del comportamiento. Nueva York: Wiley. ISBN978-1-135-63190-1.
^ Haykin (2008) Redes neuronales y máquinas de aprendizaje, 3.ª edición
^ Rosenblatt F (1958). "El perceptrón: un modelo probabilístico para el almacenamiento y la organización de la información en el cerebro". Psychological Review . 65 (6): 386–408. CiteSeerX 10.1.1.588.3775 . doi :10.1037/h0042519. PMID 13602029. S2CID 12781225.
^ Werbos P (1975). Más allá de la regresión: nuevas herramientas para la predicción y el análisis en las ciencias del comportamiento.
^ Rosenblatt F (1957). "El perceptrón: un autómata que percibe y reconoce". Informe 85-460-1 . Laboratorio Aeronáutico de Cornell.
^ Olazaran M (1996). "Un estudio sociológico de la historia oficial de la controversia de los perceptrones". Estudios sociales de la ciencia . 26 (3): 611–659. doi :10.1177/030631296026003005. JSTOR 285702. S2CID 16786738.
^ Russel, Stuart, Norvig, Peter (2010). Inteligencia artificial: un enfoque moderno (PDF) (3.ª ed.). Estados Unidos de América: Pearson Education. pp. 16–28. ISBN978-0-13-604259-4.
^ Minsky M, Papert S (1969). Perceptrones: una introducción a la geometría computacional. MIT Press. ISBN978-0-262-63022-1.
^ Crevier D (1993). AI: La tumultuosa búsqueda de la inteligencia artificial . Nueva York, NY: BasicBooks. ISBN0-465-02997-3.
^ Giacaglia, GP (2 de noviembre de 2022). Hacer que las cosas piensen. Holloway. ISBN978-1-952120-41-1Archivado desde el original el 9 de diciembre de 2023 . Consultado el 29 de diciembre de 2023 .
^ Russell SJ, Norvig P (2021). Inteligencia artificial: un enfoque moderno . Serie Pearson sobre inteligencia artificial. Ming-wei Chang, Jacob Devlin, Anca Dragan, David Forsyth, Ian Goodfellow, Jitendra Malik, Vikash Mansinghka, Judea Pearl, Michael J. Wooldridge (4.ª ed.). Hoboken, Nueva Jersey: Pearson. ISBN978-0-13-461099-3.
^ Ivakhnenko AG, Lapa VG (1967). Cibernética y técnicas de previsión. American Elsevier Publishing Co. ISBN978-0-444-00020-0.
^ Ivakhnenko A (marzo de 1970). "Autoorganización heurística en problemas de ingeniería cibernética". Automatica . 6 (2): 207–219. doi :10.1016/0005-1098(70)90092-0.
^ Robbins H , Monro S (1951). "Un método de aproximación estocástica". Anales de estadística matemática . 22 (3): 400. doi : 10.1214/aoms/1177729586 .
^ Amari S (1967). "Una teoría del clasificador de patrones adaptativo". Transacciones IEEE . EC (16): 279–307.
^ Kohonen T (1982). "Formación autoorganizada de mapas de características topológicamente correctos". Cibernética biológica . 43 (1): 59–69. doi :10.1007/bf00337288. S2CID 206775459.
^ Von der Malsburg C (1973). "Autoorganización de células sensibles a la orientación en la corteza estriada". Kybernetik . 14 (2): 85–100. doi :10.1007/bf00288907. PMID 4786750. S2CID 3351573.
^ Leibniz GW (1920). Los primeros manuscritos matemáticos de Leibniz: traducidos de los textos latinos publicados por Carl Immanuel Gerhardt con notas críticas e históricas (Leibniz publicó la regla de la cadena en unas memorias de 1676). Open Court Publishing Company. ISBN9780598818461.
^ Rosenblatt F (1962). Principios de neurodinámica . Spartan, Nueva York.
^ Kelley HJ (1960). "Teoría de gradientes de trayectorias de vuelo óptimas". ARS Journal . 30 (10): 947–954. doi :10.2514/8.5282.
^ Linnainmaa S (1970). La representación del error de redondeo acumulativo de un algoritmo como una expansión de Taylor de los errores de redondeo locales (Masters) (en finlandés). Universidad de Helsinki. págs. 6-7.
^ Linnainmaa S (1976). "Expansión de Taylor del error de redondeo acumulado". BIT Numerical Mathematics . 16 (2): 146–160. doi :10.1007/bf01931367. S2CID 122357351.
^ Anderson JA, Rosenfeld E, eds. (2000). Talking Nets: Una historia oral de las redes neuronales. The MIT Press. doi :10.7551/mitpress/6626.003.0016. ISBN978-0-262-26715-1.
^ Werbos P (1982). "Aplicaciones de los avances en el análisis de sensibilidad no lineal" (PDF) . Modelado y optimización de sistemas . Springer. pp. 762–770. Archivado (PDF) desde el original el 14 de abril de 2016. Consultado el 2 de julio de 2017 .
^ Rumelhart DE, Hinton GE, Williams RJ (octubre de 1986). "Aprendizaje de representaciones mediante retropropagación de errores". Nature . 323 (6088): 533–536. Bibcode :1986Natur.323..533R. doi :10.1038/323533a0. ISSN 1476-4687.
^ Fukushima K (1980). "Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position" (PDF) . Cibernética biológica . 36 (4): 193–202. doi :10.1007/BF00344251. PMID 7370364. S2CID 206775608. Archivado (PDF) desde el original el 3 de junio de 2014 . Consultado el 16 de noviembre de 2013 .
^ Fukushima K, Miyake S (1 de enero de 1982). "Neocognitron: Un nuevo algoritmo para el reconocimiento de patrones tolerante a deformaciones y cambios de posición". Reconocimiento de patrones . 15 (6): 455–469. doi :10.1016/0031-3203(82)90024-3. ISSN 0031-3203.
^ Fukushima K (1969). "Extracción de características visuales mediante una red multicapa de elementos de umbral analógicos". IEEE Transactions on Systems Science and Cybernetics . 5 (4): 322–333. doi :10.1109/TSSC.1969.300225.
^ por Schmidhuber J (2022). "Historia anotada de la IA moderna y el aprendizaje profundo". arXiv : 2212.11279 [cs.NE].
^ Waibel A (diciembre de 1987). Reconocimiento de fonemas mediante redes neuronales con retardo temporal . Reunión del Instituto de Ingenieros Eléctricos, de Información y de Comunicaciones (IEICE). Tokio, Japón.
^ Alexander Waibel et al., Reconocimiento de fonemas mediante redes neuronales con retardo temporal Archivado el 25 de febrero de 2021 en Wayback Machine IEEE Transactions on Acoustics, Speech, and Signal Processing, Volumen 37, N.º 3, págs. 328. – 339, marzo de 1989.
^ Zhang W (1988). «Red neuronal de reconocimiento de patrones invariante al cambio y su arquitectura óptica». Actas de la Conferencia Anual de la Sociedad Japonesa de Física Aplicada . Archivado desde el original el 23 de junio de 2020. Consultado el 12 de abril de 2023 .
^ Zhang W (1990). "Modelo de procesamiento distribuido paralelo con interconexiones locales invariantes en el espacio y su arquitectura óptica". Applied Optics . 29 (32): 4790–7. Bibcode :1990ApOpt..29.4790Z. doi :10.1364/AO.29.004790. PMID 20577468. Archivado desde el original el 6 de febrero de 2017 . Consultado el 12 de abril de 2023 .
^ LeCun et al. , "Retropropagación aplicada al reconocimiento de códigos postales escritos a mano", Neural Computation , 1, págs. 541–551, 1989.
^ LeCun Y, Léon Bottou, Yoshua Bengio, Patrick Haffner (1998). "Gradient-based learning applied to document awareness" (PDF) . Actas del IEEE . 86 (11): 2278–2324. CiteSeerX 10.1.1.32.9552 . doi :10.1109/5.726791. S2CID 14542261. Archivado (PDF) desde el original el 15 de diciembre de 2017 . Consultado el 7 de octubre de 2016 .
^ Qian, Ning y Terrence J. Sejnowski. "Predicción de la estructura secundaria de proteínas globulares utilizando modelos de redes neuronales". Journal of molecular biology 202, n.º 4 (1988): 865-884.
^ Bohr, Henrik, Jakob Bohr, Søren Brunak, Rodney MJ Cotterill, Benny Lautrup, Leif Nørskov, Ole H. Olsen y Steffen B. Petersen. "Estructura secundaria de proteínas y homología por redes neuronales. Las hélices α en rodopsina". Cartas FEBS 241, (1988): 223-228
^ Rost, Burkhard y Chris Sander. "Predicción de la estructura secundaria de proteínas con una precisión superior al 70%". Journal of molecular biology 232, n.º 2 (1993): 584-599.
^ Amari SI (noviembre de 1972). "Aprendizaje de patrones y secuencias de patrones mediante redes autoorganizadas de elementos umbral". IEEE Transactions on Computers . C-21 (11): 1197–1206. doi :10.1109/TC.1972.223477. ISSN 0018-9340.
^ Hopfield JJ (1982). "Redes neuronales y sistemas físicos con capacidades computacionales colectivas emergentes". Actas de la Academia Nacional de Ciencias . 79 (8): 2554–2558. Bibcode :1982PNAS...79.2554H. doi : 10.1073/pnas.79.8.2554 . PMC 346238 . PMID 6953413.
^ Espinosa-Sanchez JM, Gomez-Marin A, de Castro F (5 de julio de 2023). "La importancia de la neurociencia de Cajal y Lorente de Nó para el nacimiento de la cibernética". The Neuroscientist . doi :10.1177/10738584231179932. hdl : 10261/348372 . ISSN 1073-8584. PMID 37403768.
^ "circuito reverberante". Referencia de Oxford . Consultado el 27 de julio de 2024 .
^ McCulloch WS, Pitts W (diciembre de 1943). "Un cálculo lógico de las ideas inmanentes en la actividad nerviosa". Boletín de biofísica matemática . 5 (4): 115–133. doi :10.1007/BF02478259. ISSN 0007-4985.
^ Schmidhuber J (1993). Tesis de habilitación: Modelado y optimización de sistemas (PDF) .[ enlace muerto permanente ] La página 150 y siguientes demuestra la asignación de crédito a lo largo del equivalente de 1200 capas en una RNN desplegada.
^ ab S. Hochreiter., "Untersuchungen zu dynamischen neuronalen Netzen Archivado el 6 de marzo de 2015 en Wayback Machine ", Tesis de diploma. Instituto f. Informática, Universidad Técnica. Munich. Asesor: J. Schmidhuber , 1991.
^ Hochreiter S, et al. (15 de enero de 2001). "Flujo de gradiente en redes recurrentes: la dificultad de aprender dependencias a largo plazo". En Kolen JF, Kremer SC (eds.). Una guía de campo para redes recurrentes dinámicas . John Wiley & Sons. ISBN978-0-7803-5369-5Archivado desde el original el 19 de mayo de 2024 . Consultado el 26 de junio de 2017 .
^ Hochreiter S , Schmidhuber J (1 de noviembre de 1997). "Memoria a corto y largo plazo". Computación neuronal . 9 (8): 1735–1780. doi :10.1162/neco.1997.9.8.1735. PMID 9377276. S2CID 1915014.
^ Gers F, Schmidhuber J, Cummins F (1999). "Aprender a olvidar: predicción continua con LSTM". Novena Conferencia Internacional sobre Redes Neuronales Artificiales: ICANN '99 . Vol. 1999. págs. 850–855. doi :10.1049/cp:19991218. ISBN.0-85296-721-7.
^ Ackley DH, Hinton GE, Sejnowski TJ (1 de enero de 1985). "Un algoritmo de aprendizaje para máquinas de Boltzmann". Cognitive Science . 9 (1): 147–169. doi :10.1016/S0364-0213(85)80012-4 (inactivo el 7 de agosto de 2024). ISSN 0364-0213.{{cite journal}}: CS1 maint: DOI inactive as of August 2024 (link)
^ Peter D , Hinton GE , Neal RM , Zemel RS (1995). "La máquina de Helmholtz". Computación neuronal . 7 (5): 889–904. doi :10.1162/neco.1995.7.5.889. hdl : 21.11116/0000-0002-D6D3-E . PMID : 7584891. S2CID : 1890561.
^ Hinton GE , Dayan P , Frey BJ , Neal R (26 de mayo de 1995). "El algoritmo de vigilia-sueño para redes neuronales no supervisadas". Science . 268 (5214): 1158–1161. Bibcode :1995Sci...268.1158H. doi :10.1126/science.7761831. PMID 7761831. S2CID 871473.
^ Entrevista de Kurzweil AI de 2012 Archivada el 31 de agosto de 2018 en Wayback Machine con Juergen Schmidhuber sobre las ocho competiciones ganadas por su equipo de Deep Learning entre 2009 y 2012
^ "Cómo el aprendizaje profundo bioinspirado sigue ganando competencias | KurzweilAI". www.kurzweilai.net . Archivado desde el original el 31 de agosto de 2018 . Consultado el 16 de junio de 2017 .
^ Cireşan DC, Meier U, Gambardella LM, Schmidhuber J (21 de septiembre de 2010). "Redes neuronales profundas, grandes y simples para el reconocimiento de dígitos escritos a mano". Computación neuronal . 22 (12): 3207–3220. arXiv : 1003.0358 . doi :10.1162/neco_a_00052. ISSN 0899-7667. PMID 20858131. S2CID 1918673.
^ Ciresan DC, Meier U, Masci J, Gambardella L, Schmidhuber J (2011). "Redes neuronales convolucionales flexibles y de alto rendimiento para la clasificación de imágenes" (PDF) . Conferencia conjunta internacional sobre inteligencia artificial . doi :10.5591/978-1-57735-516-8/ijcai11-210. Archivado (PDF) desde el original el 29 de septiembre de 2014 . Consultado el 13 de junio de 2017 .
^ Schmidhuber J (2015). "Aprendizaje profundo en redes neuronales: una descripción general". Redes neuronales . 61 : 85–117. arXiv : 1404.7828 . doi :10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
^ Ciresan D, Giusti A, Gambardella LM, Schmidhuber J (2012). Pereira F, Burges CJ, Bottou L, Weinberger KQ (eds.). Advances in Neural Information Processing Systems 25 (PDF) . Curran Associates, Inc. pp. 2843–2851. Archivado (PDF) del original el 9 de agosto de 2017 . Consultado el 13 de junio de 2017 .
^ Ciresan D, Giusti A, Gambardella L, Schmidhuber J (2013). "Detección de mitosis en imágenes de histología de cáncer de mama con redes neuronales profundas". Computación de imágenes médicas e intervención asistida por computadora – MICCAI 2013. Apuntes de clase en informática. Vol. 7908. págs. 411–418. doi :10.1007/978-3-642-40763-5_51. ISBN978-3-642-38708-1. Número de identificación personal 24579167.
^ Ciresan D, Meier U, Schmidhuber J (2012). "Redes neuronales profundas multicolumnas para la clasificación de imágenes". Conferencia IEEE de 2012 sobre visión artificial y reconocimiento de patrones . págs. 3642–3649. arXiv : 1202.2745 . doi :10.1109/cvpr.2012.6248110. ISBN.978-1-4673-1228-8.S2CID2161592 .
^ Krizhevsky A, Sutskever I, Hinton G (2012). «Clasificación ImageNet con redes neuronales convolucionales profundas» (PDF) . NIPS 2012: Neural Information Processing Systems, Lake Tahoe, Nevada . Archivado (PDF) del original el 10 de enero de 2017. Consultado el 24 de mayo de 2017 .
^ Simonyan K, Andrew Z (2014). "Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala". arXiv : 1409.1556 [cs.CV].
^ Szegedy C (2015). "Profundizando con las convoluciones" (PDF) . Cvpr2015 .
^ Ng A, Dean J (2012). "Construcción de características de alto nivel mediante aprendizaje no supervisado a gran escala". arXiv : 1112.6209 [cs.LG].
^ ab Billings SA (2013). Identificación de sistemas no lineales: métodos NARMAX en los dominios de tiempo, frecuencia y espacio-temporal . Wiley. ISBN978-1-119-94359-4.
^ Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. (2014). Generative Adversarial Networks (PDF) . Actas de la Conferencia Internacional sobre Sistemas de Procesamiento de Información Neural (NIPS 2014). págs. 2672–2680. Archivado (PDF) del original el 22 de noviembre de 2019 . Consultado el 20 de agosto de 2019 .
^ "GAN 2.0: el generador de rostros hiperrealistas de NVIDIA". SyncedReview.com . 14 de diciembre de 2018 . Consultado el 3 de octubre de 2019 .
^ Karras T, Aila T, Laine S, Lehtinen J (26 de febrero de 2018). "Crecimiento progresivo de GAN para mejorar la calidad, la estabilidad y la variación". arXiv : 1710.10196 [cs.NE].
^ "Prepárense, no se asusten: medios sintéticos y deepfakes". witness.org. Archivado desde el original el 2 de diciembre de 2020. Consultado el 25 de noviembre de 2020 .
^ Sohl-Dickstein J, Weiss E, Maheswaranathan N, Ganguli S (1 de junio de 2015). "Aprendizaje profundo no supervisado mediante termodinámica de no equilibrio" (PDF) . Actas de la 32.ª Conferencia internacional sobre aprendizaje automático . 37. PMLR: 2256–2265.
^ Simonyan K, Zisserman A (10 de abril de 2015), Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala , arXiv : 1409.1556
^ He K, Zhang X, Ren S, Sun J (2016). "Profundizando en los rectificadores: superando el rendimiento a nivel humano en la clasificación de ImageNet". arXiv : 1502.01852 [cs.CV].
^ He K, Zhang X, Ren S, Sun J (10 de diciembre de 2015). Aprendizaje residual profundo para reconocimiento de imágenes . arXiv : 1512.03385 .
^ Srivastava RK, Greff K, Schmidhuber J (2 de mayo de 2015). "Redes de carreteras". arXiv : 1505.00387 [cs.LG].
^ He K, Zhang X, Ren S, Sun J (2016). Aprendizaje residual profundo para reconocimiento de imágenes. Conferencia IEEE 2016 sobre visión artificial y reconocimiento de patrones (CVPR) . Las Vegas, NV, EE. UU.: IEEE. págs. 770–778. arXiv : 1512.03385 . doi :10.1109/CVPR.2016.90. ISBN .978-1-4673-8851-1.
^ Linn A (10 de diciembre de 2015). «Investigadores de Microsoft ganan el desafío de visión artificial de ImageNet». The AI Blog . Consultado el 29 de junio de 2024 .
^ Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. (12 de junio de 2017). "Todo lo que necesita es atención". arXiv : 1706.03762 [cs.CL].
^ Wolf T, Debut L, Sanh V, Chaumond J, Delangue C, Moi A, et al. (2020). "Transformers: State-of-the-Art Natural Language Processing". Actas de la Conferencia de 2020 sobre métodos empíricos en el procesamiento del lenguaje natural: demostraciones de sistemas . págs. 38–45. doi :10.18653/v1/2020.emnlp-demos.6. S2CID 208117506.
^ ab Zell A (2003). "capítulo 5.2". Simulación neuronaler Netze [ Simulación de redes neuronales ] (en alemán) (1ª ed.). Addison-Wesley. ISBN978-3-89319-554-1.OCLC 249017987 .
^ Abbod MF (2007). "Aplicación de la inteligencia artificial al tratamiento del cáncer urológico". The Journal of Urology . 178 (4): 1150–1156. doi :10.1016/j.juro.2007.05.122. PMID 17698099.
^ Dawson CW (1998). "Un enfoque de red neuronal artificial para el modelado de lluvia-escorrentía". Revista de Ciencias Hidrológicas . 43 (1): 47–66. Código Bibliográfico :1998HydSJ..43...47D. doi : 10.1080/02626669809492102 .
^ "The Machine Learning Dictionary" (El diccionario de aprendizaje automático). www.cse.unsw.edu.au. Archivado desde el original el 26 de agosto de 2018. Consultado el 4 de noviembre de 2009 .
^ Ciresan D, Ueli Meier, Jonathan Masci, Luca M. Gambardella, Jurgen Schmidhuber (2011). "Redes neuronales convolucionales flexibles y de alto rendimiento para la clasificación de imágenes" (PDF) . Actas de la vigésimo segunda conferencia conjunta internacional sobre inteligencia artificial, volumen dos . 2 : 1237–1242. Archivado (PDF) desde el original el 5 de abril de 2022. Consultado el 7 de julio de 2022 .
^ Zell A (1994). Simulación Neuronaler Netze [ Simulación de redes neuronales ] (en alemán) (1ª ed.). Addison-Wesley. pag. 73.ISBN3-89319-554-8.
^ Miljanovic M (febrero-marzo de 2012). «Análisis comparativo de redes neuronales de respuesta al impulso finito y recurrente en la predicción de series temporales» (PDF) . Indian Journal of Computer and Engineering . 3 (1). Archivado (PDF) desde el original el 19 de mayo de 2024. Consultado el 21 de agosto de 2019 .
^ Kelleher JD, Mac Namee B, D'Arcy A (2020). "7-8". Fundamentos del aprendizaje automático para el análisis predictivo de datos: algoritmos, ejemplos prácticos y estudios de casos (2.ª ed.). Cambridge, MA: The MIT Press. ISBN978-0-262-36110-1.OCLC 1162184998 .
^ Wei J (26 de abril de 2019). "Olvídate de la tasa de aprendizaje, la pérdida por decaimiento". arXiv : 1905.00094 [cs.LG].
^ Li Y, Fu Y, Li H, Zhang SW (1 de junio de 2009). "El algoritmo de entrenamiento mejorado de la red neuronal de retropropagación con tasa de aprendizaje autoadaptativa". Conferencia internacional de 2009 sobre inteligencia computacional y computación natural . Vol. 1. págs. 73–76. doi :10.1109/CINC.2009.111. ISBN978-0-7695-3645-3.S2CID10557754 .
^ Huang GB, Zhu QY, Siew CK (2006). "Máquina de aprendizaje extremo: teoría y aplicaciones". Neurocomputing . 70 (1): 489–501. CiteSeerX 10.1.1.217.3692 . doi :10.1016/j.neucom.2005.12.126. S2CID 116858.
^ Widrow B, et al. (2013). "El algoritmo sin prop: un nuevo algoritmo de aprendizaje para redes neuronales multicapa". Redes neuronales . 37 : 182–188. doi :10.1016/j.neunet.2012.09.020. PMID 23140797.
^ Ollivier Y, Charpiat G (2015). "Entrenamiento de redes recurrentes sin retroceso". arXiv : 1507.07680 [cs.NE].
^ Hinton GE (2010). "Una guía práctica para el entrenamiento de máquinas de Boltzmann restringidas". Tech. Rep. UTML TR 2010-003 . Archivado desde el original el 9 de mayo de 2021. Consultado el 27 de junio de 2017 .
^ Bernard E (2021). Introducción al aprendizaje automático. Champaign: Wolfram Media. pág. 9. ISBN978-1-57955-048-6Archivado desde el original el 19 de mayo de 2024 . Consultado el 22 de marzo de 2023 .
^ Bernard E (2021). Introducción al aprendizaje automático. Champaign: Wolfram Media. pág. 12. ISBN978-1-57955-048-6Archivado desde el original el 19 de mayo de 2024 . Consultado el 22 de marzo de 2023 .
^ Bernard E (2021). Introducción al aprendizaje automático. Wolfram Media Inc. pág. 9. ISBN978-1-57955-048-6Archivado desde el original el 19 de mayo de 2024 . Consultado el 28 de julio de 2022 .
^ Ojha VK, Abraham A, Snášel V (1 de abril de 2017). "Diseño metaheurístico de redes neuronales de propagación hacia adelante: una revisión de dos décadas de investigación". Aplicaciones de ingeniería de la inteligencia artificial . 60 : 97–116. arXiv : 1705.05584 . Bibcode :2017arXiv170505584O. doi :10.1016/j.engappai.2017.01.013. S2CID 27910748.
^ Dominic, S., Das, R., Whitley, D., Anderson, C. (julio de 1991). "Aprendizaje de refuerzo genético para redes neuronales" . IJCNN-91-Seattle International Joint Conference on Neural Networks . IJCNN-91-Seattle International Joint Conference on Neural Networks. Seattle, Washington, EE. UU.: IEEE. págs. 71–76. doi :10.1109/IJCNN.1991.155315. ISBN.0-7803-0164-1.
^ Hoskins J, Himmelblau, DM (1992). "Control de procesos mediante redes neuronales artificiales y aprendizaje por refuerzo". Computers & Chemical Engineering . 16 (4): 241–251. doi :10.1016/0098-1354(92)80045-B.
^ Bertsekas D, Tsitsiklis J (1996). Programación neurodinámica. Athena Scientific. pág. 512. ISBN978-1-886529-10-6Archivado desde el original el 29 de junio de 2017 . Consultado el 17 de junio de 2017 .
^ Secomandi N (2000). "Comparación de algoritmos de programación neurodinámica para el problema de enrutamiento de vehículos con demandas estocásticas". Computers & Operations Research . 27 (11–12): 1201–1225. CiteSeerX 10.1.1.392.4034 . doi :10.1016/S0305-0548(99)00146-X.
^ de Rigo, D., Rizzoli, AE, Soncini-Sessa, R., Weber, E., Zenesi, P. (2001). "Programación neurodinámica para la gestión eficiente de redes de embalses". Actas de MODSIM 2001, Congreso Internacional sobre Modelado y Simulación . MODSIM 2001, Congreso Internacional sobre Modelado y Simulación. Canberra, Australia: Sociedad de Modelado y Simulación de Australia y Nueva Zelanda. doi :10.5281/zenodo.7481. ISBN0-86740-525-2Archivado desde el original el 7 de agosto de 2013 . Consultado el 29 de julio de 2013 .
^ Damas, M., Salmerón, M., Díaz, A., Ortega, J., Prieto, A., Olivares, G. (2000). "Algoritmos genéticos y programación neurodinámica: aplicación a redes de abastecimiento de agua". Actas del Congreso de Computación Evolutiva de 2000. Congreso de Computación Evolutiva de 2000. Vol. 1. La Jolla, California, EE. UU.: IEEE. págs. 7–14. doi :10.1109/CEC.2000.870269. ISBN .0-7803-6375-2.
^ Deng G, Ferris, MC (2008). "Programación neurodinámica para la planificación de radioterapia fraccionada". Optimización en medicina . Springer Optimization and Its Applications. Vol. 12. págs. 47–70. CiteSeerX 10.1.1.137.8288 . doi :10.1007/978-0-387-73299-2_3. ISBN.978-0-387-73298-5.
^ Bozinovski, S. (1982). "Un sistema de autoaprendizaje mediante refuerzo secundario". En R. Trappl (ed.) Investigación en cibernética y sistemas: Actas de la sexta reunión europea sobre investigación en cibernética y sistemas. Holanda Septentrional. págs. 397–402. ISBN 978-0-444-86488-8 .
^ Bozinovski, S. (2014) "Mecanismos de modelado de la interacción cognición-emoción en redes neuronales artificiales, desde 1981 Archivado el 23 de marzo de 2019 en Wayback Machine ." Procedia Computer Science p. 255-263
^ Bozinovski S, Bozinovska L (2001). "Agentes de autoaprendizaje: una teoría conexionista de la emoción basada en el juicio de valor de barras cruzadas". Cibernética y sistemas . 32 (6): 637–667. doi :10.1080/01969720118145. S2CID 8944741.
^ Salimans T, Ho J, Chen X, Sidor S, Sutskever I (7 de septiembre de 2017). "Estrategias evolutivas como una alternativa escalable al aprendizaje por refuerzo". arXiv : 1703.03864 [stat.ML].
^ Such FP, Madhavan V, Conti E, Lehman J, Stanley KO, Clune J (20 de abril de 2018). "Neuroevolución profunda: los algoritmos genéticos son una alternativa competitiva para entrenar redes neuronales profundas para el aprendizaje por refuerzo". arXiv : 1712.06567 [cs.NE].
^ "La inteligencia artificial puede 'evolucionar' para resolver problemas". Ciencia | AAAS . 10 de enero de 2018. Archivado desde el original el 9 de diciembre de 2021 . Consultado el 7 de febrero de 2018 .
^ Turchetti C (2004), Modelos estocásticos de redes neuronales , Fronteras en inteligencia artificial y aplicaciones: sistemas de ingeniería inteligente basados en el conocimiento, vol. 102, IOS Press, ISBN978-1-58603-388-0
^ Jospin LV, Laga H, Boussaid F, Buntine W, Bennamoun M (2022). "Redes neuronales bayesianas prácticas: un tutorial para usuarios de aprendizaje profundo". Revista IEEE Computational Intelligence . Vol. 17, núm. 2. págs. 29–48. arXiv : 2007.06823 . doi :10.1109/mci.2022.3155327. ISSN 1556-603X. S2CID 220514248.
^ de Rigo, D., Castelletti, A., Rizzoli, AE, Soncini-Sessa, R., Weber, E. (enero de 2005). "Una técnica de mejora selectiva para la fijación de la programación neurodinámica en la gestión de redes de recursos hídricos". En Pavel Zítek (ed.). Actas del 16.º Congreso Mundial de la IFAC – IFAC-PapersOnLine . 16.º Congreso Mundial de la IFAC. Vol. 16. Praga, República Checa: IFAC. págs. 7–12. doi :10.3182/20050703-6-CZ-1902.02172. hdl : 11311/255236 . ISBN978-3-902661-75-3Archivado desde el original el 26 de abril de 2012 . Consultado el 30 de diciembre de 2011 .
^ Ferreira C (2006). "Designing Neural Networks Using Gene Expression Programming". En A. Abraham, B. de Baets, M. Köppen, B. Nickolay (eds.). Tecnologías de computación blanda aplicadas: el desafío de la complejidad (PDF) . Springer-Verlag. págs. 517–536. Archivado (PDF) desde el original el 19 de diciembre de 2013 . Consultado el 8 de octubre de 2012 .
^ Da, Y., Xiurun, G. (julio de 2005). "Una ANN basada en PSO mejorada con técnica de recocido simulado". En T. Villmann (ed.). Nuevos aspectos en neurocomputación: 11.º simposio europeo sobre redes neuronales artificiales . Vol. 63. Elsevier. págs. 527–533. doi :10.1016/j.neucom.2004.07.002. Archivado desde el original el 25 de abril de 2012. Consultado el 30 de diciembre de 2011 .
^ Wu, J., Chen, E. (mayo de 2009). "Un nuevo conjunto de regresión no paramétrica para la predicción de precipitaciones mediante la técnica de optimización de enjambre de partículas acoplada con una red neuronal artificial". En Wang, H., Shen, Y., Huang, T., Zeng, Z. (eds.). 6.º Simposio internacional sobre redes neuronales, ISNN 2009. Lecture Notes in Computer Science. Vol. 5553. Springer. págs. 49–58. doi :10.1007/978-3-642-01513-7_6. ISBN.978-3-642-01215-0Archivado desde el original el 31 de diciembre de 2014 . Consultado el 1 de enero de 2012 .
^ ab Ting Qin, Zonghai Chen, Haitao Zhang, Sifu Li, Wei Xiang, Ming Li (2004). "Un algoritmo de aprendizaje de CMAC basado en RLS" (PDF) . Neural Processing Letters . 19 (1): 49–61. doi :10.1023/B:NEPL.0000016847.18175.60. S2CID 6233899. Archivado (PDF) del original el 14 de abril de 2021 . Consultado el 30 de enero de 2019 .
^ Ting Qin, Haitao Zhang, Zonghai Chen, Wei Xiang (2005). "Continuous CMAC-QRLS and its systolic array" (PDF) . Neural Processing Letters . 22 (1): 1–16. doi :10.1007/s11063-004-2694-0. S2CID 16095286. Archivado (PDF) del original el 18 de noviembre de 2018 . Consultado el 30 de enero de 2019 .
^ LeCun Y, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W, et al. (1989). "Retropropagación aplicada al reconocimiento de códigos postales escritos a mano". Neural Computation . 1 (4): 541–551. doi :10.1162/neco.1989.1.4.541. S2CID 41312633.
^ Yann LeCun (2016). Diapositivas sobre aprendizaje profundo en línea Archivado el 23 de abril de 2016 en Wayback Machine.
^ Hochreiter S , Schmidhuber J (1 de noviembre de 1997). "Memoria a corto y largo plazo". Computación neuronal . 9 (8): 1735–1780. doi :10.1162/neco.1997.9.8.1735. ISSN 0899-7667. PMID 9377276. S2CID 1915014.
^ Sak H, Senior A, Beaufays F (2014). "Arquitecturas de redes neuronales recurrentes de memoria a corto y largo plazo para modelado acústico a gran escala" (PDF) . Archivado desde el original (PDF) el 24 de abril de 2018.
^ Li X, Wu X (15 de octubre de 2014). "Construcción de redes neuronales recurrentes profundas basadas en memoria de corto y largo plazo para el reconocimiento de voz de vocabulario amplio". arXiv : 1410.4281 [cs.CL].
^ Fan Y, Qian Y, Xie F, Soong FK (2014). "Síntesis de TTS con redes neuronales recurrentes basadas en LSTM bidireccional". Actas de la Conferencia Anual de la Asociación Internacional de Comunicación del Habla, Interspeech : 1964–1968 . Consultado el 13 de junio de 2017 .
^ Zen H, Sak H (2015). "Red neuronal recurrente de memoria a corto y largo plazo unidireccional con capa de salida recurrente para síntesis de voz de baja latencia" (PDF) . Google.com . ICASSP. págs. 4470–4474. Archivado (PDF) del original el 9 de mayo de 2021 . Consultado el 27 de junio de 2017 .
^ Fan B, Wang L, Soong FK, Xie L (2015). "Cabeza parlante fotorrealista con LSTM bidireccional profundo" (PDF) . Actas de ICASSP . Archivado (PDF) del original el 1 de noviembre de 2017. Consultado el 27 de junio de 2017 .
^ Silver D , Hubert T, Schrittwieser J, Antonoglou I, Lai M, Guez A, et al. (5 de diciembre de 2017). "Dominar el ajedrez y el shogi mediante el juego autónomo con un algoritmo de aprendizaje por refuerzo general". arXiv : 1712.01815 [cs.AI].
^ Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. (2014). Generative Adversarial Networks (PDF) . Actas de la Conferencia Internacional sobre Sistemas de Procesamiento de Información Neural (NIPS 2014). págs. 2672–2680. Archivado (PDF) del original el 22 de noviembre de 2019 . Consultado el 20 de agosto de 2019 .
^ Probst P, Boulesteix AL, Bischl B (26 de febrero de 2018). "Capacidad de ajuste: importancia de los hiperparámetros de los algoritmos de aprendizaje automático". J. Mach. Learn. Res . 20 : 53:1–53:32. S2CID 88515435.
^ Zoph B, Le QV (4 de noviembre de 2016). "Búsqueda de arquitectura neuronal con aprendizaje por refuerzo". arXiv : 1611.01578 [cs.LG].
^ Haifeng Jin, Qingquan Song, Xia Hu (2019). «Auto-keras: Un sistema de búsqueda de arquitectura neuronal eficiente». Actas de la 25.ª Conferencia internacional ACM SIGKDD sobre descubrimiento de conocimiento y minería de datos . ACM. arXiv : 1806.10282 . Archivado desde el original el 21 de agosto de 2019. Consultado el 21 de agosto de 2019 en autokeras.com.
^ Claesen M, De Moor B (2015). "Búsqueda de hiperparámetros en aprendizaje automático". arXiv : 1502.02127 [cs.LG].Código Bibliográfico :2015arXiv150202127C
^ Esch R (1990). "Aproximación funcional". Manual de matemáticas aplicadas (Springer US ed.). Boston, MA: Springer US. págs. 928–987. doi :10.1007/978-1-4684-1423-3_17. ISBN978-1-4684-1423-3.
^ Sarstedt M, Moo E (2019). "Análisis de regresión". Una guía concisa para la investigación de mercados . Springer Texts in Business and Economics. Springer Berlin Heidelberg. págs. 209–256. doi :10.1007/978-3-662-56707-4_7. ISBN978-3-662-56706-7. S2CID 240396965. Archivado desde el original el 20 de marzo de 2023 . Consultado el 20 de marzo de 2023 .
^ Tian J, Tan Y, Sun C, Zeng J, Jin Y (diciembre de 2016). "Una aproximación de aptitud basada en similitud autoadaptativa para la optimización evolutiva". Serie de simposios IEEE de 2016 sobre inteligencia computacional (SSCI) . págs. 1–8. doi :10.1109/SSCI.2016.7850209. ISBN.978-1-5090-4240-1. S2CID 14948018. Archivado desde el original el 19 de mayo de 2024 . Consultado el 22 de marzo de 2023 .
^ Alaloul WS, Qureshi AH (2019). "Procesamiento de datos mediante redes neuronales artificiales". Asimilación dinámica de datos: cómo superar las incertidumbres . doi :10.5772/intechopen.91935. ISBN978-1-83968-083-0. S2CID 219735060. Archivado desde el original el 20 de marzo de 2023 . Consultado el 20 de marzo de 2023 .
^ Pal M, Roy R, Basu J, Bepari MS (2013). "Separación ciega de fuentes: una revisión y análisis". Conferencia internacional de 2013 COCOSDA oriental celebrada conjuntamente con la Conferencia de 2013 sobre investigación y evaluación de lenguas habladas asiáticas (O-COCOSDA/CASLRE) . IEEE. págs. 1–5. doi :10.1109/ICSDA.2013.6709849. ISBN.978-1-4799-2378-6. S2CID 37566823. Archivado desde el original el 20 de marzo de 2023 . Consultado el 20 de marzo de 2023 .
^ Zissis D (octubre de 2015). «Una arquitectura basada en la nube capaz de percibir y predecir el comportamiento de múltiples buques». Applied Soft Computing . 35 : 652–661. doi :10.1016/j.asoc.2015.07.002. Archivado desde el original el 26 de julio de 2020 . Consultado el 18 de julio de 2019 .
^ Sengupta N, Sahidullah, Md, Saha, Goutam (agosto de 2016). "Clasificación de sonidos pulmonares utilizando características estadísticas basadas en cepstrales". Computers in Biology and Medicine . 75 (1): 118–129. doi :10.1016/j.compbiomed.2016.05.013. PMID 27286184.
^ Choy, Christopher B., et al. "3d-r2n2: Un enfoque unificado para la reconstrucción de objetos 3D de vista única y múltiple Archivado el 26 de julio de 2020 en Wayback Machine ." Conferencia europea sobre visión artificial. Springer, Cham, 2016.
^ Turek, Fred D. (marzo de 2007). "Introducción a la visión artificial mediante redes neuronales". Diseño de sistemas de visión . 12 (3). Archivado desde el original el 16 de mayo de 2013 . Consultado el 5 de marzo de 2013 .
^ Maitra DS, Bhattacharya U, Parui SK (agosto de 2015). "Enfoque común basado en CNN para el reconocimiento de caracteres manuscritos de múltiples escrituras". 2015 13.ª Conferencia Internacional sobre Análisis y Reconocimiento de Documentos (ICDAR) . pp. 1021–1025. doi :10.1109/ICDAR.2015.7333916. ISBN978-1-4799-1805-8. S2CID 25739012. Archivado desde el original el 16 de octubre de 2023 . Consultado el 18 de marzo de 2021 .
^ Gessler J (agosto de 2021). «Sensor para análisis de alimentos aplicando espectroscopia de impedancia y redes neuronales artificiales». RiuNet UPV (1): 8–12. Archivado desde el original el 21 de octubre de 2021 . Consultado el 21 de octubre de 2021 .
^ French J (2016). "El CAPM del viajero en el tiempo". Revista de analistas de inversiones . 46 (2): 81–96. doi :10.1080/10293523.2016.1255469. S2CID 157962452.
^ Roman M. Balabin, Ekaterina I. Lomakina (2009). "Enfoque de red neuronal para datos de química cuántica: predicción precisa de energías de la teoría funcional de la densidad". J. Chem. Phys. 131 (7): 074104. Bibcode :2009JChPh.131g4104B. doi :10.1063/1.3206326. PMID 19708729.
^ Silver D, et al. (2016). "Mastering the game of Go with deep neural networks and tree search" (PDF) . Nature . 529 (7587): 484–489. Bibcode :2016Natur.529..484S. doi :10.1038/nature16961. PMID 26819042. S2CID 515925. Archivado (PDF) del original el 23 de noviembre de 2018 . Consultado el 31 de enero de 2019 .
^ Pasick A (27 de marzo de 2023). «Glosario de inteligencia artificial: redes neuronales y otros términos explicados». The New York Times . ISSN 0362-4331. Archivado desde el original el 1 de septiembre de 2023. Consultado el 22 de abril de 2023 .
^ Schechner S (15 de junio de 2017). «Facebook potencia la inteligencia artificial para bloquear la propaganda terrorista». The Wall Street Journal . ISSN 0099-9660. Archivado desde el original el 19 de mayo de 2024. Consultado el 16 de junio de 2017 .
^ Ganesan N (2010). "Aplicación de redes neuronales en el diagnóstico de enfermedades oncológicas mediante datos demográficos". Revista internacional de aplicaciones informáticas . 1 (26): 81–97. Bibcode :2010IJCA....1z..81G. doi : 10.5120/476-783 .
^ Bottaci L (1997). "Redes neuronales artificiales aplicadas a la predicción de resultados para pacientes con cáncer colorrectal en instituciones separadas" (PDF) . Lancet . 350 (9076). The Lancet: 469–72. doi :10.1016/S0140-6736(96)11196-X. PMID 9274582. S2CID 18182063. Archivado desde el original (PDF) el 23 de noviembre de 2018 . Consultado el 2 de mayo de 2012 .
^ Alizadeh E, Lyons SM, Castle JM, Prasad A (2016). "Medición de cambios sistemáticos en la forma de células cancerosas invasivas mediante momentos de Zernike". Integrative Biology . 8 (11): 1183–1193. doi :10.1039/C6IB00100A. PMID 27735002. Archivado desde el original el 19 de mayo de 2024 . Consultado el 28 de marzo de 2017 .
^ Lyons S (2016). "Los cambios en la forma celular se correlacionan con el potencial metastásico en ratones". Biology Open . 5 (3): 289–299. doi :10.1242/bio.013409. PMC 4810736 . PMID 26873952.
^ Nabian MA, Meidani H (28 de agosto de 2017). "Aprendizaje profundo para el análisis acelerado de confiabilidad de redes de infraestructura". Ingeniería civil y de infraestructura asistida por computadora . 33 (6): 443–458. arXiv : 1708.08551 . Código Bibliográfico :2017arXiv170808551N. doi :10.1111/mice.12359. S2CID 36661983.
^ Nabian MA, Meidani H (2018). "Aceleración de la evaluación estocástica de la conectividad de la red de transporte posterior al terremoto mediante sustitutos basados en aprendizaje automático". 97.ª reunión anual de la Junta de Investigación del Transporte . Archivado desde el original el 9 de marzo de 2018. Consultado el 14 de marzo de 2018 .
^ Díaz E, Brotons V, Tomás R (septiembre de 2018). "Uso de redes neuronales artificiales para predecir asentamientos elásticos tridimensionales de cimentaciones en suelos con lecho rocoso inclinado". Suelos y cimentaciones . 58 (6): 1414–1422. Bibcode :2018SoFou..58.1414D. doi : 10.1016/j.sandf.2018.08.001 . hdl : 10045/81208 . ISSN 0038-0806.
^ Tayebiyan A, Mohammad TA, Ghazali AH, Mashohor S. "Red neuronal artificial para modelar la lluvia y la escorrentía". Revista Pertanika de ciencia y tecnología . 24 (2): 319–330. Archivado desde el original el 17 de mayo de 2023. Consultado el 17 de mayo de 2023 .
^ Govindaraju RS (1 de abril de 2000). "Redes neuronales artificiales en hidrología. I: Conceptos preliminares". Journal of Hydrologic Engineering . 5 (2): 115–123. doi :10.1061/(ASCE)1084-0699(2000)5:2(115).
^ Govindaraju RS (1 de abril de 2000). "Redes neuronales artificiales en hidrología. II: Aplicaciones hidrológicas". Journal of Hydrologic Engineering . 5 (2): 124–137. doi :10.1061/(ASCE)1084-0699(2000)5:2(124).
^ Peres DJ, Iuppa C, Cavallaro L, Cancelliere A, Foti E (1 de octubre de 2015). "Extensión significativa del registro de altura de ola mediante redes neuronales y reanálisis de datos de viento". Ocean Modelling . 94 : 128–140. Bibcode :2015OcMod..94..128P. doi :10.1016/j.ocemod.2015.08.002.
^ Dwarakish GS, Rakshith S, Natesan U (2013). "Revisión de aplicaciones de redes neuronales en ingeniería costera". Sistemas de inteligencia artificial y aprendizaje automático . 5 (7): 324–331. Archivado desde el original el 15 de agosto de 2017. Consultado el 5 de julio de 2017 .
^ Ermini L, Catani F, Casagli N (1 de marzo de 2005). "Redes neuronales artificiales aplicadas a la evaluación de la susceptibilidad a deslizamientos de tierra". Geomorfología . Peligro geomorfológico e impacto humano en entornos montañosos. 66 (1): 327–343. Bibcode :2005Geomo..66..327E. doi :10.1016/j.geomorph.2004.09.025.
^ Nix R, Zhang J (mayo de 2017). "Clasificación de aplicaciones y malware de Android mediante redes neuronales profundas". Conferencia conjunta internacional sobre redes neuronales (IJCNN) de 2017. págs. 1871–1878. doi :10.1109/IJCNN.2017.7966078. ISBN978-1-5090-6182-2.S2CID8838479 .
^ "Detección de URL maliciosas". Grupo de sistemas y redes de la UCSD . Archivado desde el original el 14 de julio de 2019. Consultado el 15 de febrero de 2019 .
^ Homayoun S, Ahmadzadeh M, Hashemi S, Dehghantanha A, Khayami R (2018), Dehghantanha A, Conti M, Dargahi T (eds.), "BoTShark: un enfoque de aprendizaje profundo para la detección del tráfico de botnets", Cyber Threat Intelligence , Advances in Information Security, vol. 70, Springer International Publishing, págs. 137-153, doi :10.1007/978-3-319-73951-9_7, ISBN978-3-319-73951-9
^ Ghosh, Reilly (enero de 1994). "Detección de fraudes con tarjetas de crédito mediante una red neuronal". Actas de la vigésimo séptima conferencia internacional de Hawái sobre ciencias de sistemas HICSS-94 . Vol. 3. págs. 621–630. doi :10.1109/HICSS.1994.323314. ISBN978-0-8186-5090-1. Número de identificación del sujeto 13260377.
^ Ananthaswamy A (19 de abril de 2021). "Las últimas redes neuronales resuelven las ecuaciones más difíciles del mundo más rápido que nunca". Revista Quanta . Archivado desde el original el 19 de mayo de 2024. Consultado el 12 de mayo de 2021 .
^ "La IA ha resuelto un problema matemático clave para comprender nuestro mundo". MIT Technology Review . Archivado desde el original el 19 de mayo de 2024. Consultado el 19 de noviembre de 2020 .
^ "Caltech abre el código fuente de una IA para resolver ecuaciones diferenciales parciales". InfoQ . Archivado desde el original el 25 de enero de 2021 . Consultado el 20 de enero de 2021 .
^ Nagy A (28 de junio de 2019). "Método de Monte Carlo cuántico variacional con un ansatz de red neuronal para sistemas cuánticos abiertos". Physical Review Letters . 122 (25): 250501. arXiv : 1902.09483 . Bibcode :2019PhRvL.122y0501N. doi :10.1103/PhysRevLett.122.250501. PMID 31347886. S2CID 119074378.
^ Yoshioka N, Hamazaki R (28 de junio de 2019). "Construcción de estados estacionarios neuronales para sistemas cuánticos abiertos de muchos cuerpos". Physical Review B . 99 (21): 214306. arXiv : 1902.07006 . Código Bibliográfico :2019PhRvB..99u4306Y. doi :10.1103/PhysRevB.99.214306. S2CID 119470636.
^ Hartmann MJ, Carleo G (28 de junio de 2019). "Enfoque de redes neuronales para la dinámica cuántica disipativa de muchos cuerpos". Physical Review Letters . 122 (25): 250502. arXiv : 1902.05131 . Bibcode :2019PhRvL.122y0502H. doi :10.1103/PhysRevLett.122.250502. PMID 31347862. S2CID 119357494.
^ Vicentini F, Biella A, Regnault N, Ciuti C (28 de junio de 2019). "Análisis de redes neuronales variacionales para estados estacionarios en sistemas cuánticos abiertos". Physical Review Letters . 122 (25): 250503. arXiv : 1902.10104 . Bibcode :2019PhRvL.122y0503V. doi :10.1103/PhysRevLett.122.250503. PMID 31347877. S2CID 119504484.
^ Forrest MD (abril de 2015). "Simulación de la acción del alcohol sobre un modelo detallado de neuronas de Purkinje y un modelo sustituto más simple que se ejecuta >400 veces más rápido". BMC Neuroscience . 16 (27): 27. doi : 10.1186/s12868-015-0162-6 . PMC 4417229 . PMID 25928094.
^ Wieczorek S, Filipiak D, Filipowska A (2018). "Semantic Image-Based Profiling of Users' Interests with Neural Networks" (Elaboración de perfiles semánticos basados en imágenes de los intereses de los usuarios con redes neuronales). Estudios sobre la Web Semántica . 36 (Temas emergentes en tecnologías semánticas). doi :10.3233/978-1-61499-894-5-179. Archivado desde el original el 19 de mayo de 2024. Consultado el 20 de enero de 2024 .
^ Merchant A, Batzner S, Schoenholz SS, Aykol M, Cheon G, Cubuk ED (diciembre de 2023). "Escalamiento del aprendizaje profundo para el descubrimiento de materiales". Nature . 624 (7990): 80–85. Bibcode :2023Natur.624...80M. doi :10.1038/s41586-023-06735-9. ISSN 1476-4687. PMC 10700131 . PMID 38030720.
^ Siegelmann H, Sontag E (1991). "Turing computability with neural nets" (PDF) . Appl. Math. Lett . 4 (6): 77–80. doi :10.1016/0893-9659(91)90080-F. Archivado (PDF) desde el original el 19 de mayo de 2024 . Consultado el 10 de enero de 2017 .
^ Bains S (3 de noviembre de 1998). «La computadora analógica supera al modelo de Turing». EE Times . Archivado desde el original el 11 de mayo de 2023. Consultado el 11 de mayo de 2023 .
^ Balcázar J (julio de 1997). "Poder computacional de redes neuronales: una caracterización de la complejidad de Kolmogorov". IEEE Transactions on Information Theory . 43 (4): 1175–1183. CiteSeerX 10.1.1.411.7782 . doi :10.1109/18.605580.
^ ab MacKay DJ (2003). Teoría de la información, inferencia y algoritmos de aprendizaje (PDF) . Cambridge University Press . ISBN978-0-521-64298-9. Archivado (PDF) del original el 19 de octubre de 2016 . Consultado el 11 de junio de 2016 .
^ Cover T (1965). "Propiedades geométricas y estadísticas de sistemas de desigualdades lineales con aplicaciones en el reconocimiento de patrones" (PDF) . IEEE Transactions on Electronic Computers . EC-14 (3). IEEE : 326–334. doi :10.1109/PGEC.1965.264137. Archivado (PDF) del original el 5 de marzo de 2016. Consultado el 10 de marzo de 2020 .
^ Gerald F (2019). "Reproducibilidad y diseño experimental para el aprendizaje automático en datos de audio y multimedia". Actas de la 27.ª Conferencia Internacional de la ACM sobre Multimedia . ACM . págs. 2709–2710. doi :10.1145/3343031.3350545. ISBN.978-1-4503-6889-6. Número de identificación del sujeto 204837170.
^ "¡Deja de trastear, empieza a medir! Diseño experimental predecible de experimentos de redes neuronales". El medidor de Tensorflow . Archivado desde el original el 18 de abril de 2022. Consultado el 10 de marzo de 2020 .
^ Lee J, Xiao L, Schoenholz SS, Bahri Y, Novak R, Sohl-Dickstein J, et al. (2020). "Las redes neuronales amplias de cualquier profundidad evolucionan como modelos lineales bajo descenso de gradiente". Journal of Statistical Mechanics: Theory and Experiment . 2020 (12): 124002. arXiv : 1902.06720 . Código Bibliográfico :2020JSMTE2020l4002L. doi :10.1088/1742-5468/abc62b. S2CID 62841516.
^ Arthur Jacot, Franck Gabriel, Clement Hongler (2018). Neural Tangent Kernel: Convergence and Generalization in Neural Networks (PDF) . 32.ª Conferencia sobre sistemas de procesamiento de información neuronal (NeurIPS 2018), Montreal, Canadá. Archivado (PDF) del original el 22 de junio de 2022. Consultado el 4 de junio de 2022 .
^ Xu ZJ, Zhang Y, Xiao Y (2019). "Comportamiento de entrenamiento de redes neuronales profundas en el dominio de la frecuencia". En Gedeon T, Wong K, Lee M (eds.). Procesamiento de información neuronal . Notas de clase en informática. Vol. 11953. Springer, Cham. págs. 264–274. arXiv : 1807.01251 . doi :10.1007/978-3-030-36708-4_22. ISBN.978-3-030-36707-7.S2CID 49562099 .
^ Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, et al. (2019). "Sobre el sesgo espectral de las redes neuronales" (PDF) . Actas de la 36.ª Conferencia Internacional sobre Aprendizaje Automático . 97 : 5301–5310. arXiv : 1806.08734 . Archivado (PDF) del original el 22 de octubre de 2022. Consultado el 4 de junio de 2022 .
^ Zhi-Qin John Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, Zheng Ma (2020). "Principio de frecuencia: el análisis de Fourier arroja luz sobre las redes neuronales profundas". Comunicaciones en física computacional . 28 (5): 1746–1767. arXiv : 1901.06523 . Código Bibliográfico :2020CCoPh..28.1746X. doi :10.4208/cicp.OA-2020-0085. S2CID 58981616.
^ Tao Luo, Zheng Ma, Zhi-Qin John Xu, Yaoyu Zhang (2019). "Teoría del principio de frecuencia para redes neuronales profundas generales". arXiv : 1906.09235 [cs.LG].
^ Xu ZJ, Zhou H (18 de mayo de 2021). «Principio de frecuencia profunda para comprender por qué el aprendizaje más profundo es más rápido». Actas de la Conferencia AAAI sobre Inteligencia Artificial . 35 (12): 10541–10550. arXiv : 2007.14313 . doi :10.1609/aaai.v35i12.17261. ISSN 2374-3468. S2CID 220831156. Archivado desde el original el 5 de octubre de 2021. Consultado el 5 de octubre de 2021 .
^ Parisi GI, Kemker R, Part JL, Kanan C, Wermter S (1 de mayo de 2019). "Aprendizaje continuo a lo largo de la vida con redes neuronales: una revisión". Redes neuronales . 113 : 54–71. arXiv : 1802.07569 . doi : 10.1016/j.neunet.2019.01.012 . ISSN 0893-6080. PMID 30780045.
^ Dean Pomerleau, "Entrenamiento basado en el conocimiento de redes neuronales artificiales para la conducción autónoma de robots"
^ Dewdney AK (1 de abril de 1997). Sí, no tenemos neutrones: un recorrido revelador por los vericuetos de la mala ciencia. Wiley. pág. 82. ISBN978-0-471-10806-1.
^ NASA – Dryden Flight Research Center – Sala de prensa: Comunicados de prensa: EL PROYECTO DE RED NEURONAL DE LA NASA ALCANZA UN HITO Archivado el 2 de abril de 2010 en Wayback Machine . Nasa.gov. Consultado el 20 de noviembre de 2013.
^ "La defensa de las redes neuronales por parte de Roger Bridgman". Archivado desde el original el 19 de marzo de 2012. Consultado el 12 de julio de 2010 .
^ "Escalamiento de algoritmos de aprendizaje hacia {IA} - LISA - Publicaciones - Aigaion 2.0". www.iro.umontreal.ca .
^ DJ Felleman y DC Van Essen, "Procesamiento jerárquico distribuido en la corteza cerebral de los primates", Cerebral Cortex , 1, págs. 1–47, 1991.
^ J. Weng, "Inteligencia natural y artificial: Introducción a la mente-cerebro computacional Archivado el 19 de mayo de 2024 en Wayback Machine ", BMI Press, ISBN 978-0-9858757-2-5 , 2012.
^ ab Edwards C (25 de junio de 2015). "Dolores crecientes para el aprendizaje profundo". Comunicaciones de la ACM . 58 (7): 14–16. doi :10.1145/2771283. S2CID 11026540.
^ Schmidhuber J (2015). "Aprendizaje profundo en redes neuronales: una descripción general". Redes neuronales . 61 : 85–117. arXiv : 1404.7828 . doi :10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
^ "La amarga lección". www.incompleteideas.net . Consultado el 7 de agosto de 2024 .
^ Cade Metz (18 de mayo de 2016). «Google construyó sus propios chips para impulsar sus robots de inteligencia artificial». Wired . Archivado desde el original el 13 de enero de 2018. Consultado el 5 de marzo de 2017 .
^ "Escalando algoritmos de aprendizaje hacia la IA" (PDF) . Archivado (PDF) del original el 12 de agosto de 2022 . Consultado el 6 de julio de 2022 .
^ Tahmasebi, Hezarkhani (2012). "Un algoritmo híbrido de redes neuronales, lógica difusa y genética para la estimación de la ley". Computers & Geosciences . 42 : 18–27. Bibcode :2012CG.....42...18T. doi :10.1016/j.cageo.2012.02.004. PMC 4268588 . PMID 25540468.
^ Sun y Bookman, 1990
^ ab Norori N, Hu Q, Aellen FM, Faraci FD, Tzovara A (octubre de 2021). "Abordar el sesgo en los macrodatos y la IA para la atención sanitaria: un llamado a la ciencia abierta". Patrones . 2 (10): 100347. doi : 10.1016/j.patter.2021.100347 . PMC 8515002 . PMID 34693373.
^ ab Carina W (27 de octubre de 2022). "Failing at Face Value: The Effect of Biased Facial Recognition Technology on Racial Discrimination in Criminal Justice" (Fallar en el valor aparente: el efecto de la tecnología de reconocimiento facial sesgada en la discriminación racial en la justicia penal). Investigación científica y social . 4 (10): 29–40. doi : 10.26689/ssr.v4i10.4402 . ISSN 2661-4332.
^ ab Chang X (13 de septiembre de 2023). «Sesgo de género en la contratación: un análisis del impacto del algoritmo de contratación de Amazon». Avances en economía, gestión y ciencias políticas . 23 (1): 134–140. doi : 10.54254/2754-1169/23/20230367 . ISSN 2754-1169. Archivado desde el original el 9 de diciembre de 2023. Consultado el 9 de diciembre de 2023 .
^ Kortylewski A, Egger B, Schneider A, Gerig T, Morel-Forster A, Vetter T (junio de 2019). "Análisis y reducción del daño del sesgo de los conjuntos de datos en el reconocimiento de rostros con datos sintéticos". Talleres de la Conferencia IEEE/CVF de 2019 sobre visión artificial y reconocimiento de patrones (CVPRW) (PDF) . IEEE. págs. 2261–2268. doi :10.1109/cvprw.2019.00279. ISBN.978-1-7281-2506-0. S2CID 198183828. Archivado (PDF) del original el 19 de mayo de 2024 . Consultado el 30 de diciembre de 2023 .
^ abcdef Huang Y (2009). "Avances en redes neuronales artificiales: desarrollo metodológico y aplicación". Algorithms . 2 (3): 973–1007. doi : 10.3390/algor2030973 . ISSN 1999-4893.
^ abcde Kariri E, Louati H, Louati A, Masmoudi F (2023). "Explorando los avances y las futuras direcciones de investigación de las redes neuronales artificiales: un enfoque de minería de texto". Applied Sciences . 13 (5): 3186. doi : 10.3390/app13053186 . ISSN 2076-3417.
^ ab Fui-Hoon Nah F, Zheng R, Cai J, Siau K, Chen L (3 de julio de 2023). "IA generativa y ChatGPT: aplicaciones, desafíos y colaboración entre IA y humanos". Revista de investigación de casos y aplicaciones de tecnología de la información . 25 (3): 277–304. doi : 10.1080/15228053.2023.2233814 . ISSN 1522-8053.
^ "Los fallos de DALL-E 2 son lo más interesante del asunto - IEEE Spectrum". IEEE . Archivado desde el original el 15 de julio de 2022 . Consultado el 9 de diciembre de 2023 .
^ Briot JP (enero de 2021). «De las redes neuronales artificiales al aprendizaje profundo para la generación de música: historia, conceptos y tendencias». Computación neuronal y aplicaciones . 33 (1): 39–65. doi : 10.1007/s00521-020-05399-0 . ISSN 0941-0643.
^ Chow PS (6 de julio de 2020). «Fantasma en la máquina (de Hollywood): aplicaciones emergentes de la inteligencia artificial en la industria cinematográfica». NECSUS_European Journal of Media Studies . doi :10.25969/MEDIAREP/14307. ISSN 2213-0217.
^ Yu X, He S, Gao Y, Yang J, Sha L, Zhang Y, et al. (junio de 2010). "Ajuste dinámico de la dificultad de la IA del juego para el videojuego Dead-End". Tercera Conferencia Internacional sobre Ciencias de la Información y Ciencias de la Interacción . IEEE. págs. 583–587. doi :10.1109/icicis.2010.5534761. ISBN .978-1-4244-7384-7.ID S2C 17555595.
Bibliografía
Bhadeshia HKDH (1999). "Redes neuronales en la ciencia de los materiales" (PDF) . ISIJ International . 39 (10): 966–979. doi :10.2355/isijinternational.39.966.
Bishop CM (1995). Redes neuronales para el reconocimiento de patrones . Clarendon Press. ISBN 978-0-19-853849-3.OCLC 33101074 .
Borgelt C (2003). Neuro-Fuzzy-Systeme: von den Grundlagen künstlicher Neuronaler Netze zur Kopplung mit Fuzzy-Systemen . Vereg. ISBN 978-3-528-25265-6.OCLC 76538146 .
Dewdney AK (1997). Sí, no tenemos neutrones: un recorrido revelador por los vericuetos de la mala ciencia . Nueva York: Wiley. ISBN 978-0-471-10806-1.OCLC 35558945 .
Duda RO, Hart PE, Stork DG (2001). Clasificación de patrones (2.ª edición). Wiley. ISBN 978-0-471-05669-0.OCLC 41347061 .
Egmont-Petersen M, de Ridder D, Handels H (2002). "Procesamiento de imágenes con redes neuronales: una revisión". Reconocimiento de patrones . 35 (10): 2279–2301. CiteSeerX 10.1.1.21.5444 . doi :10.1016/S0031-3203(01)00178-9.
Fahlman S, Lebiere C (1991). "The Cascade-Correlation Learning Architecture" (PDF) . Archivado desde el original (PDF) el 3 de mayo de 2013. Consultado el 28 de agosto de 2006 .
Gurney K (1997). Introducción a las redes neuronales . UCL Press. ISBN 978-1-85728-673-1.OCLC 37875698 .
Haykin SS (1999). Redes neuronales: una base integral . Prentice Hall. ISBN 978-0-13-273350-2.OCLC 38908586 .
Hertz J, Palmer RG, Krogh AS (1991). Introducción a la teoría de la computación neuronal . Addison-Wesley. ISBN 978-0-201-51560-2.OCLC 21522159 .
Teoría de la información, inferencia y algoritmos de aprendizaje . Cambridge University Press. 25 de septiembre de 2003. Bibcode :2003itil.book.....M. ISBN 978-0-521-64298-9.OCLC 52377690 .
Kruse R, Borgelt C, Klawonn F, Moewes C, Steinbrecher M, Held P (2013). Inteligencia computacional: una introducción metodológica . Saltador. ISBN 978-1-4471-5012-1. OCLC 837524179.
Lawrence J (1994). Introducción a las redes neuronales: diseño, teoría y aplicaciones . California Scientific Software. ISBN 978-1-883157-00-5.OCLC 32179420 .
Masters T (1994). Procesamiento de señales e imágenes con redes neuronales: un libro de consulta de C++ . J. Wiley. ISBN 978-0-471-04963-0.OCLC 29877717 .
Ripley BD (2007). Reconocimiento de patrones y redes neuronales. Cambridge University Press. ISBN 978-0-521-71770-0.
Siegelmann H, Sontag ED (1994). "Computación analógica mediante redes neuronales". Ciencias de la Computación Teórica . 131 (2): 331–360. doi : 10.1016/0304-3975(94)90178-3 . S2CID 2456483.
Smith M (1993). Redes neuronales para modelado estadístico . Van Nostrand Reinhold. ISBN 978-0-442-01310-3.OCLC 27145760 .
Wasserman PD (1993). Métodos avanzados en computación neuronal . Van Nostrand Reinhold. ISBN 978-0-442-00461-3.OCLC 27429729 .
Wilson H (2018). Inteligencia artificial . Editorial Grey House. ISBN 978-1-68217-867-6.





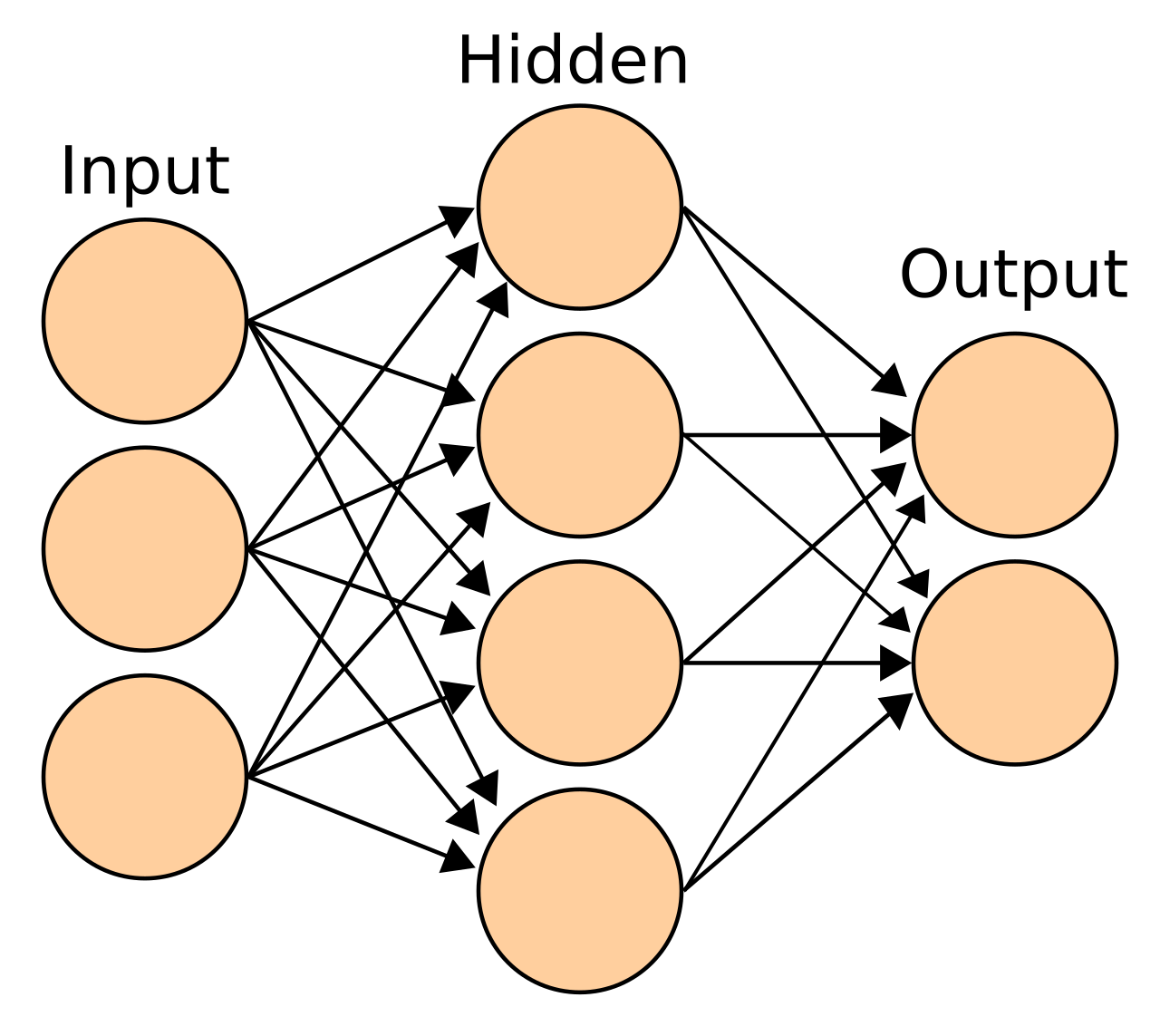
.svg/1280px-Ann_dependency_(graph).svg.png)





![{\displaystyle \textstyle C=E[(xf(x))^{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2929ecb1606fdfeaddc55477d9671e11c034e21c)










