
El perfil de ADN (también llamado huella dactilar de ADN y huella genética ) es el proceso de determinar las características del ácido desoxirribonucleico ( ADN ) de un individuo . El análisis de ADN destinado a identificar una especie, en lugar de un individuo, se denomina código de barras de ADN .
La elaboración de perfiles de ADN es una técnica forense en investigaciones criminales , que compara los perfiles de los sospechosos de delitos con la evidencia de ADN para evaluar la probabilidad de su participación en el delito. [1] [2] También se utiliza en pruebas de paternidad , [3] para establecer la elegibilidad de inmigración, [4] y en investigaciones genealógicas y médicas. Los perfiles de ADN también se han utilizado en el estudio de poblaciones de animales y plantas en los campos de la zoología, la botánica y la agricultura. [5]

A partir de la década de 1980, los avances científicos permitieron el uso del ADN como material para la identificación de un individuo. La primera patente que cubre el uso directo de la variación del ADN con fines forenses (US5593832A [6] [7] ) fue presentada por Jeffrey Glassberg en 1983, basándose en el trabajo que había realizado mientras estaba en la Universidad Rockefeller en los Estados Unidos en 1981.
El genetista británico Sir Alec Jeffreys desarrolló de forma independiente un proceso para la elaboración de perfiles de ADN en 1985 mientras trabajaba en el Departamento de Genética de la Universidad de Leicester . Jeffreys descubrió que un examinador de ADN podía establecer patrones en ADN desconocido. Estos patrones formaban parte de rasgos heredados que podrían utilizarse para avanzar en el campo del análisis de relaciones. Estos descubrimientos conducen al primer uso de perfiles de ADN en un caso penal. [8] [9] [10] [11]
El proceso, desarrollado por Jeffreys junto con Peter Gill y Dave Werrett del Servicio de Ciencias Forenses (FSS), se utilizó por primera vez de forma forense para resolver el asesinato de dos adolescentes que habían sido violadas y asesinadas en Narborough, Leicestershire en 1983 y 1986. En la investigación del asesinato, dirigida por el detective David Baker, el ADN contenido en muestras de sangre obtenidas voluntariamente de alrededor de 5.000 hombres locales que ayudaron voluntariamente a la policía de Leicestershire con la investigación, resultó en la exoneración de Richard Buckland, un sospechoso inicial que había confesado uno. de los crímenes y la posterior condena de Colin Pitchfork el 2 de enero de 1988. Pitchfork, un empleado de una panadería local, había obligado a su compañero de trabajo Ian Kelly a sustituirlo cuando le proporcionara una muestra de sangre; luego, Kelly usó un pasaporte falsificado para hacerse pasar por Pitchfork. . Otro compañero de trabajo denunció el engaño a la policía. Pitchfork fue arrestado y su sangre fue enviada al laboratorio de Jeffreys para su procesamiento y desarrollo de perfiles. El perfil de Pitchfork coincidía con el del ADN dejado por el asesino, lo que confirmó la presencia de Pitchfork en ambas escenas del crimen; se declaró culpable de ambos asesinatos. [12] Después de algunos años, una empresa química llamada Imperial Chemical Industries (ICI) presentó al mundo el primer kit disponible comercialmente. A pesar de ser un campo relativamente reciente, tuvo una influencia global significativa tanto en el sistema de justicia penal como en la sociedad. [13]

Aunque el 99,9% de las secuencias de ADN humano son iguales en todas las personas, una cantidad suficiente de ADN es diferente como para que sea posible distinguir un individuo de otro, a menos que sean gemelos monocigóticos (idénticos) . [14] La elaboración de perfiles de ADN utiliza secuencias repetitivas que son altamente variables, [14] llamadas repeticiones en tándem de número variable (VNTR), en particular repeticiones cortas en tándem (STR), también conocidas como microsatélites y minisatélites . Los loci VNTR son similares entre individuos estrechamente relacionados, pero son tan variables que es poco probable que individuos no relacionados tengan los mismos VNTR.
Antes de los VNTR y los STR, personas como Jeffreys utilizaban un proceso llamado polimorfismo de longitud de fragmentos de restricción (RFLP). Este proceso utilizaba regularmente grandes porciones de ADN para analizar las diferencias entre dos muestras de ADN. RFLP fue una de las primeras tecnologías utilizadas en la elaboración de perfiles y análisis de ADN. Sin embargo, a medida que la tecnología evolucionó, surgieron nuevas tecnologías, como STR, que reemplazaron a tecnologías más antiguas como RFLP. [15]
La admisibilidad de la evidencia de ADN en los tribunales fue cuestionada en los Estados Unidos en las décadas de 1980 y 1990, pero desde entonces se ha vuelto más universalmente aceptada debido a la mejora de las técnicas. [dieciséis]
Cuando se obtiene una muestra como sangre o saliva , el ADN es sólo una pequeña parte de lo que está presente en la muestra. Antes de poder analizar el ADN, es necesario extraerlo de las células y purificarlo. Hay muchas maneras de lograr esto, pero todos los métodos siguen el mismo procedimiento básico. Es necesario romper las membranas celulares y nucleares para permitir que el ADN quede libre en solución. Una vez que el ADN está libre, se puede separar de todos los demás componentes celulares. Una vez que el ADN se ha separado en la solución, los restos celulares restantes se pueden retirar de la solución y desechar, dejando solo el ADN. Los métodos más comunes de extracción de ADN incluyen la extracción orgánica (también llamada extracción con fenol cloroformo ), [17] extracción Chelex y extracción en fase sólida . La extracción diferencial es una versión modificada de la extracción en la que el ADN de dos tipos diferentes de células se puede separar entre sí antes de purificarlo de la solución. Cada método de extracción funciona bien en el laboratorio, pero los analistas suelen seleccionar su método preferido en función de factores como el costo, el tiempo involucrado, la cantidad de ADN obtenido y la calidad del ADN obtenido. [18]

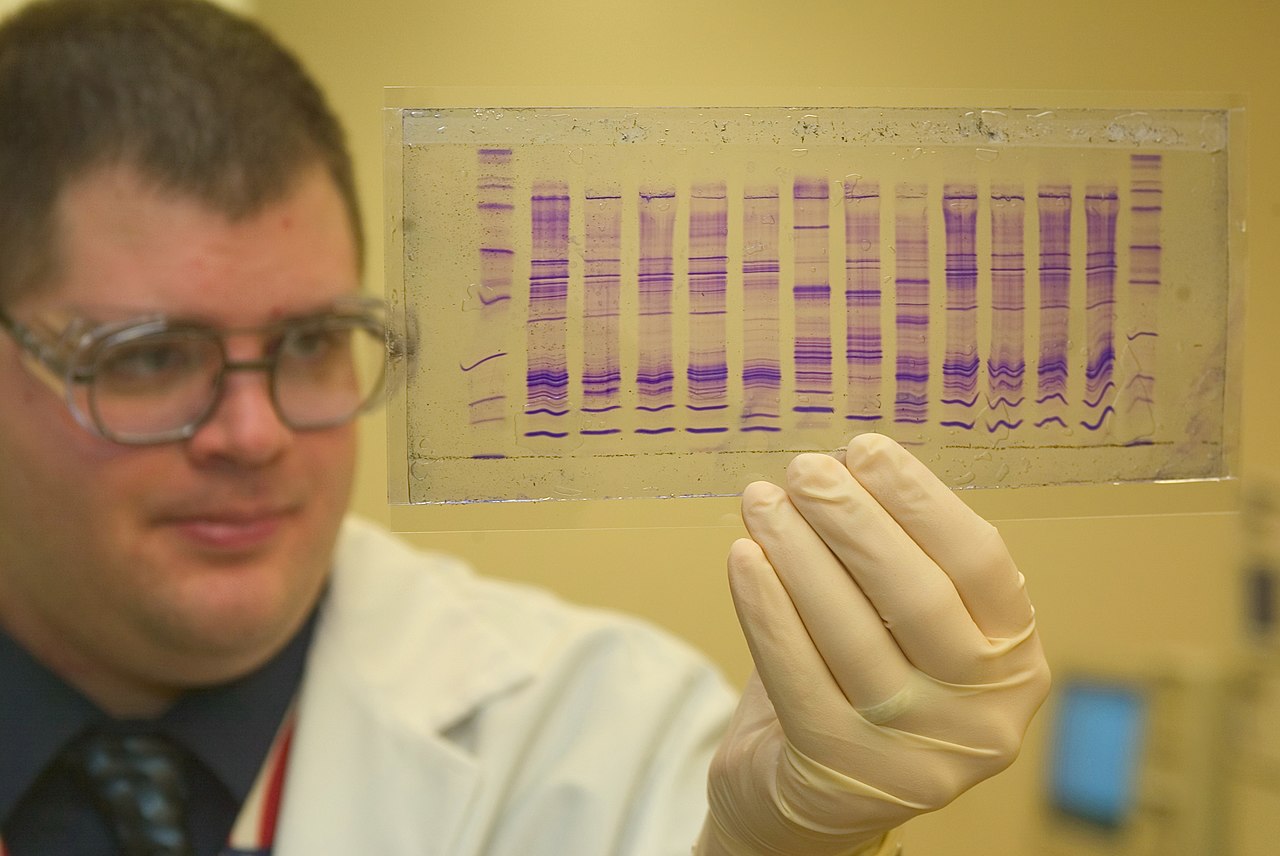
RFLP significa polimorfismo de longitud de fragmentos de restricción y, en términos de análisis de ADN, describe un método de prueba de ADN que utiliza enzimas de restricción para "cortar" el ADN en secuencias cortas y específicas en toda la muestra. Para iniciar el procesamiento en el laboratorio, la muestra debe pasar primero por un protocolo de extracción, que puede variar según el tipo de muestra o los SOP (procedimientos operativos estándar) del laboratorio. Una vez que el ADN se ha "extraído" de las células dentro de la muestra y se ha separado de los materiales celulares extraños y de cualquier nucleasa que pueda degradar el ADN, la muestra se puede introducir en las enzimas de restricción deseadas para cortarla en fragmentos discernibles. Después de la digestión enzimática, se realiza una transferencia Southern. Southern Blots es un método de separación basado en el tamaño que se realiza en un gel con sondas radiactivas o quimioluminiscentes. RFLP podría realizarse con sondas de un solo locus o de múltiples locus (sondas que apuntan a una ubicación del ADN o a múltiples ubicaciones del ADN). La incorporación de sondas multilocus permitió un mayor poder de discriminación para el análisis; sin embargo, completar este proceso podría llevar de varios días a una semana para una muestra debido a la cantidad extrema de tiempo requerido en cada paso requerido para la visualización de las sondas.
La técnica fue desarrollada en 1983 por Kary Mullis; la PCR es ahora una técnica común e importante utilizada en laboratorios de investigación médica y biológica para una variedad de aplicaciones. [19]
La PCR, o reacción en cadena de la polimerasa, es una técnica de biología molecular ampliamente utilizada para amplificar una secuencia de ADN específica.

La amplificación se logra mediante una serie de tres pasos:
1- Desnaturalización : En este paso, el ADN se calienta a 95 °C para disociar los enlaces de hidrógeno entre los pares de bases complementarias del ADN bicatenario.
2-Recocido : Durante esta etapa la reacción se enfría a 50-65 °C . Esto permite que los cebadores se unan a una ubicación específica del ADN molde monocatenario mediante enlaces de hidrógeno.
3-Extensión : en este paso se usa comúnmente una ADN polimerasa termoestable que es la polimerasa Taq. Esto se hace a una temperatura de 72 °C . La ADN polimerasa agrega nucleótidos en la dirección 5'-3' y sintetiza la cadena complementaria de la plantilla de ADN.
_analysis.png/1280px-Short_Tandem_Repeat_(STR)_analysis.png)
El sistema de perfiles de ADN que se utiliza hoy en día se basa en la reacción en cadena de la polimerasa (PCR) y utiliza secuencias simples. [9]
De un país a otro se utilizan diferentes sistemas de elaboración de perfiles de ADN basados en STR. En América del Norte, los sistemas que amplifican los loci centrales CODIS 20 [21] son casi universales, mientras que en el Reino Unido se utiliza el sistema de loci ADN-17 y Australia utiliza 18 marcadores centrales. [22]
El verdadero poder del análisis STR está en su poder estadístico de discriminación. Debido a que los 20 loci que se utilizan actualmente para la discriminación en CODIS se clasifican de forma independiente (tener un cierto número de repeticiones en un locus no cambia la probabilidad de tener cualquier número de repeticiones en cualquier otro locus), se puede aplicar la regla del producto para probabilidades . Esto significa que, si alguien tiene el tipo de ADN ABC, donde los tres loci eran independientes, entonces la probabilidad de que ese individuo tenga ese tipo de ADN es la probabilidad de tener el tipo A multiplicada por la probabilidad de tener el tipo B multiplicada por la probabilidad de tener el tipo B. C. Esto ha dado como resultado la capacidad de generar probabilidades de coincidencia de 1 entre quintillones (1x10 18 ) o más. [ se necesita más explicación ] Sin embargo, las búsquedas en la base de datos de ADN mostraron coincidencias de perfiles de ADN falsos mucho más frecuentes de lo esperado. [23]
Debido a la herencia paterna, los haplotipos Y proporcionan información sobre la ascendencia genética de la población masculina. Para investigar la historia de esta población y proporcionar estimaciones de las frecuencias de haplotipos en casos penales, en 2000 se creó la "base de datos de referencia de haplotipos Y (YHRD)" como recurso en línea. Actualmente comprende más de 300.000 haplotipos mínimos (8 locus) de poblaciones de todo el mundo. [24]
El ADNmt se puede obtener de materiales como tallos de cabello y huesos/dientes viejos. [25] Mecanismo de control basado en el punto de interacción con los datos. Esto se puede determinar mediante la colocación de herramientas en la muestra. [26]
Cuando la gente piensa en análisis de ADN, a menudo piensa en programas de televisión como NCIS o CSI , que retratan muestras de ADN que llegan a un laboratorio y se analizan instantáneamente, seguido de la obtención de una fotografía del sospechoso en cuestión de minutos. Sin embargo, la realidad es bastante diferente y muchas veces no se recogen muestras de ADN perfectas en la escena del crimen. Las víctimas de homicidio frecuentemente quedan expuestas a duras condiciones antes de ser encontradas, y los objetos que se utilizan para cometer delitos a menudo han sido manipulados por más de una persona. Los dos problemas más frecuentes que encuentran los científicos forenses al analizar muestras de ADN son las muestras degradadas y las mezclas de ADN. [27]
Antes de que existieran los métodos de PCR modernos, era casi imposible analizar muestras de ADN degradadas. Métodos como el polimorfismo de longitud de fragmentos de restricción (RFLP), que fue la primera técnica utilizada para el análisis de ADN en la ciencia forense, requerían ADN de alto peso molecular en la muestra para obtener datos confiables. Sin embargo, en las muestras degradadas falta ADN de alto peso molecular, ya que el ADN está demasiado fragmentado para realizar RFLP con precisión. Sólo cuando se inventaron las técnicas de reacción en cadena de la polimerasa se pudieron realizar análisis de muestras de ADN degradadas. En particular, la PCR múltiple ha permitido aislar y amplificar los pequeños fragmentos de ADN que aún quedan en las muestras degradadas. Cuando se comparan los métodos de PCR multiplex con los métodos más antiguos como RFLP, se puede observar una gran diferencia. En teoría, la PCR múltiple puede amplificar menos de 1 ng de ADN, pero RFLP debía tener al menos 100 ng de ADN para poder realizar un análisis. [28]
El ADN con plantilla baja puede ocurrir cuando hay menos de 0,1 ng ( [29] ) de ADN en una muestra. Esto puede conducir a efectos más estocásticos (eventos aleatorios), como la caída o la entrada alélica, que pueden alterar la interpretación de un perfil de ADN. Estos efectos estocásticos pueden conducir a la amplificación desigual de los 2 alelos que provienen de un individuo heterocigoto. Es especialmente importante tener en cuenta el ADN con plantilla baja cuando se trata de una mezcla de muestras de ADN. Esto se debe a que es más probable que uno (o más) de los contribuyentes de la mezcla tengan una cantidad de ADN inferior a la óptima para que la reacción de PCR funcione correctamente. [30] Por lo tanto, se desarrollan umbrales estocásticos para la interpretación del perfil de ADN. El umbral estocástico es la altura máxima mínima (valor RFU), que se observa en un electroferograma donde se produce la caída. Si el valor de altura máxima está por encima de este umbral, entonces es razonable suponer que no se ha producido una pérdida alélica. Por ejemplo, si solo se ve un pico para un locus particular en el electroferograma pero la altura de su pico está por encima del umbral estocástico, entonces podemos suponer razonablemente que este individuo es homocigoto y no le falta su alelo asociado heterocigoto que de otro modo habría abandonado. debido a que tiene ADN de plantilla baja. La pérdida alélica puede ocurrir cuando hay ADN con baja plantilla porque, para empezar, hay tan poco ADN que en este locus el contribuyente a la muestra (o mezcla) de ADN es un heterocigoto verdadero, pero el otro alelo no está amplificado, por lo que sería perdido. La caída alélica [31] también puede ocurrir cuando hay ADN con plantilla baja porque a veces el pico entrecortado puede amplificarse. La tartamudez es un artefacto de la PCR. Durante la reacción de PCR, la ADN polimerasa entrará y agregará nucleótidos del cebador, pero todo este proceso es muy dinámico, lo que significa que la ADN polimerasa se une constantemente, se desprende y luego se vuelve a unir. Por lo tanto, a veces la ADN polimerasa se reincorporará en la repetición corta en tándem que tiene delante, lo que dará lugar a una repetición corta en tándem que es 1 repetición menos que la plantilla. Durante la PCR, si la ADN polimerasa se une a un locus en tartamudeo y comienza a amplificarlo para hacer muchas copias, entonces este producto de tartamudez aparecerá aleatoriamente en el electroferograma, lo que provocará una caída alélica.
En los casos en que las muestras de ADN se degradan, como si hay incendios intensos o lo único que queda son fragmentos de huesos, las pruebas STR estándar en esas muestras pueden ser inadecuadas. Cuando las pruebas STR estándar se realizan en muestras altamente degradadas, los loci STR más grandes a menudo desaparecen y sólo se obtienen perfiles de ADN parciales. Los perfiles de ADN parciales pueden ser una herramienta poderosa, pero la probabilidad de una coincidencia aleatoria es mayor que si se obtuviera un perfil completo. Un método que se ha desarrollado para analizar muestras de ADN degradadas es utilizar la tecnología miniSTR. En el nuevo enfoque, los cebadores están especialmente diseñados para unirse más cerca de la región STR. [32]
En las pruebas STR normales, los cebadores se unen a secuencias más largas que contienen la región STR dentro del segmento. Sin embargo, el análisis MiniSTR se centra únicamente en la ubicación del STR, lo que da como resultado un producto de ADN mucho más pequeño. [32]
Al colocar los cebadores más cerca de las regiones STR reales, existe una mayor probabilidad de que se produzca una amplificación exitosa de esta región. Ahora se puede realizar una amplificación exitosa de esas regiones STR y se pueden obtener perfiles de ADN más completos. El éxito de que los productos de PCR más pequeños produzcan una mayor tasa de éxito con muestras altamente degradadas se informó por primera vez en 1995, cuando se utilizó la tecnología miniSTR para identificar a las víctimas del incendio de Waco. [33]
Las mezclas son otro problema común al que se enfrentan los científicos forenses cuando analizan muestras de ADN desconocidas o cuestionables. Una mezcla se define como una muestra de ADN que contiene dos o más contribuyentes individuales. [28] Esto puede ocurrir a menudo cuando se toma una muestra de ADN de un artículo que es manipulado por más de una persona o cuando una muestra contiene tanto el ADN de la víctima como el del agresor. La presencia de más de un individuo en una muestra de ADN puede dificultar la detección de perfiles individuales, y la interpretación de mezclas debe ser realizada únicamente por personas altamente capacitadas. Las mezclas que contienen dos o tres individuos pueden interpretarse con dificultad. Las mezclas que contienen cuatro o más individuos son demasiado complicadas para obtener perfiles individuales. Un escenario común en el que se suele obtener una mezcla es en el caso de agresión sexual. Se puede recolectar una muestra que contenga material de la víctima, sus parejas sexuales consensuales y los perpetradores. [34]
Las mezclas generalmente se pueden clasificar en tres categorías: Tipo A, Tipo B y Tipo C. [35] Las mezclas de tipo A tienen alelos con alturas de pico similares en todas partes, por lo que los contribuyentes no se pueden distinguir entre sí. Las mezclas de tipo B se pueden desconvolucionar comparando las proporciones pico-altura para determinar qué alelos se donaron juntos. Las mezclas de tipo C no se pueden interpretar de forma segura con la tecnología actual porque las muestras se vieron afectadas por la degradación del ADN o porque tenían una cantidad demasiado pequeña de ADN presente.
Al observar un electroferograma, es posible determinar la cantidad de contribuyentes en mezclas menos complejas en función de la cantidad de picos ubicados en cada locus. En comparación con un perfil de fuente única, que solo tendrá uno o dos picos en cada locus, una mezcla es cuando hay tres o más picos en dos o más loci. [36] Si hay tres picos en un solo locus, entonces es posible tener un único contribuyente que sea pruebalélico en ese locus. [37] Las mezclas de dos personas tendrán entre dos y cuatro picos en cada locus, y las mezclas de tres personas tendrán entre tres y seis picos en cada locus. Las mezclas se vuelven cada vez más difíciles de desconvolucionar a medida que aumenta el número de contribuyentes.
A medida que avanzan los métodos de detección en los perfiles de ADN, los científicos forenses ven cada vez más muestras de ADN que contienen mezclas, ya que ahora incluso el contribuyente más pequeño puede detectarse mediante pruebas modernas. La facilidad que tienen los científicos forenses para interpenetrar mezclas de ADN depende en gran medida de la proporción de ADN presente de cada individuo, las combinaciones de genotipos y la cantidad total de ADN amplificado. [38] La proporción de ADN es a menudo el aspecto más importante a considerar para determinar si una mezcla puede interpretarse. Por ejemplo, si una muestra de ADN tuviera dos contribuyentes, sería fácil interpretar perfiles individuales si la proporción de ADN aportado por una persona fuera mucho mayor que la de la segunda. Cuando una muestra tiene tres o más contribuyentes, resulta extremadamente difícil determinar perfiles individuales. Afortunadamente, los avances en el genotipado probabilístico pueden hacer posible ese tipo de determinación en el futuro. El genotipado probabilístico utiliza un complejo software para ejecutar miles de cálculos matemáticos para producir probabilidades estadísticas de genotipos individuales encontrados en una mezcla. [39]
Perfiles de ADN en plantas:
El perfil de ADN de la planta (huellas dactilares) es un método para identificar cultivares que utiliza técnicas de marcadores moleculares. Este método está ganando atención debido a los derechos de propiedad intelectual relacionados con el comercio (TRIP) y el Convenio sobre la Diversidad Biológica (CDB). [40]
Ventajas del perfilado de ADN vegetal:
La identificación, autenticación, distinción específica, detección de adulteración e identificación de fitoconstituyentes son posibles con la huella digital de ADN en plantas medicinales. [41]
Los marcadores basados en ADN son fundamentales para estas aplicaciones y determinan el futuro de los estudios científicos en farmacognosia. [41]
También ayuda a determinar los rasgos (como el tamaño de la semilla y el color de las hojas) que probablemente mejoren o no la descendencia. [42]
Una de las primeras aplicaciones de una base de datos de ADN fue la compilación de una concordancia de ADN mitocondrial, [43] preparada por Kevin WP Miller y John L. Dawson en la Universidad de Cambridge de 1996 a 1999 [44] a partir de datos recopilados como parte de la tesis doctoral de Miller. . En la actualidad existen varias bases de datos de ADN en todo el mundo. Algunas son privadas, pero la mayoría de las bases de datos más grandes están controladas por el gobierno. Estados Unidos mantiene la base de datos de ADN más grande , con el Sistema de Índice Combinado de ADN (CODIS) con más de 13 millones de registros en mayo de 2018. [45] El Reino Unido mantiene la Base de Datos Nacional de ADN (NDNAD), que es de tamaño similar, a pesar de la menor población del Reino Unido. El tamaño de esta base de datos y su tasa de crecimiento preocupan a los grupos de libertades civiles en el Reino Unido, donde la policía tiene amplios poderes para tomar muestras y retenerlas incluso en caso de absolución. [46] La coalición Conservador-Liberal Demócrata abordó parcialmente estas preocupaciones con la parte 1 de la Ley de Protección de las Libertades de 2012 , según la cual las muestras de ADN deben eliminarse si los sospechosos son absueltos o no acusados, excepto en relación con ciertos delitos (en su mayoría graves o sexuales). ofensas. El discurso público sobre la introducción de técnicas forenses avanzadas (como la genealogía genética utilizando bases de datos genealógicas públicas y enfoques de fenotipado de ADN) ha sido limitado, inconexo, desenfocado y plantea cuestiones de privacidad y consentimiento que pueden justificar el establecimiento de protecciones legales adicionales. [47]
La Ley Patriota de los Estados Unidos proporciona un medio para que el gobierno de los Estados Unidos obtenga muestras de ADN de presuntos terroristas. La información de ADN de los delitos se recopila y deposita en la base de datos CODIS , mantenida por el FBI . CODIS permite a los funcionarios encargados de hacer cumplir la ley analizar muestras de ADN de delitos para buscar coincidencias dentro de la base de datos, proporcionando un medio para encontrar perfiles biológicos específicos asociados con la evidencia de ADN recopilada. [48]
Cuando se realiza una coincidencia a partir de un banco de datos de ADN nacional para vincular la escena del crimen con un delincuente que ha proporcionado una muestra de ADN a una base de datos, ese vínculo a menudo se denomina resultado en frío . Un golpe frío es valioso para remitir a la agencia policial a un sospechoso específico, pero tiene menos valor probatorio que una coincidencia de ADN realizada fuera del banco de datos de ADN. [49]
Los agentes del FBI no pueden almacenar legalmente ADN de una persona que no haya sido condenada por un delito. El ADN recolectado de un sospechoso que no sea condenado posteriormente debe eliminarse y no ingresarse en la base de datos. En 1998, un hombre residente en el Reino Unido fue arrestado acusado de robo. Le tomaron y analizaron su ADN y luego fue puesto en libertad. Nueve meses después, el ADN de este hombre fue ingresado accidental e ilegalmente en la base de datos de ADN. El ADN nuevo se compara automáticamente con el ADN encontrado en casos sin resolver y, en este caso, se descubrió que este hombre coincidía con el ADN encontrado en un caso de violación y agresión un año antes. Luego, el gobierno lo procesó por estos crímenes. Durante el juicio se solicitó que la coincidencia de ADN fuera eliminada de las pruebas porque había sido ingresada ilegalmente en la base de datos. La solicitud fue realizada. [50] El ADN del perpetrador, recopilado de víctimas de violación, puede almacenarse durante años hasta que se encuentre una coincidencia. En 2014, para abordar este problema, el Congreso amplió un proyecto de ley que ayuda a los estados a lidiar con "una acumulación" de pruebas. [51]
Bases de datos de perfiles de ADN en Plantas:
PIDS:
PIDS (Sistema internacional de huellas dactilares de ADN de plantas) es un servidor web de código abierto y un sistema internacional de huellas dactilares de ADN de plantas basado en software gratuito.
Gestiona una gran cantidad de datos de huellas dactilares de ADN de microsatélites, realiza estudios genéticos y automatiza la recopilación, el almacenamiento y el mantenimiento, al tiempo que reduce el error humano y aumenta la eficiencia.
El sistema puede adaptarse a las necesidades específicas del laboratorio, lo que lo convierte en una herramienta valiosa para los fitomejoradores, la ciencia forense y el reconocimiento de huellas dactilares humanas.
Realiza un seguimiento de los experimentos, estandariza los datos y promueve la comunicación entre bases de datos.
También ayuda con la regulación de la calidad de las variedades, la preservación de los derechos de las variedades y el uso de marcadores moleculares en el mejoramiento al proporcionar estadísticas de ubicación, fusión, comparación y función de análisis genético. [52]
Cuando se utiliza RFLP , el riesgo teórico de una coincidencia coincidente es de 1 entre 100 mil millones (100.000.000.000), aunque el riesgo práctico es en realidad de 1 entre 1.000 porque los gemelos monocigóticos constituyen el 0,2% de la población humana. [53] Además, la tasa de error de laboratorio es casi con certeza mayor que esa y los procedimientos de laboratorio reales a menudo no reflejan la teoría bajo la cual se calcularon las probabilidades de coincidencia. Por ejemplo, las probabilidades de coincidencia se pueden calcular basándose en las probabilidades de que los marcadores en dos muestras tengan bandas exactamente en la misma ubicación, pero un trabajador de laboratorio puede concluir que patrones de bandas similares pero no exactamente idénticos resultan de muestras genéticas idénticas con alguna imperfección en la Gel de agarosa. Sin embargo, en ese caso, el trabajador del laboratorio aumenta el riesgo de coincidencia al ampliar los criterios para declarar una coincidencia. Los estudios realizados en la década de 2000 citaron tasas de error relativamente altas, lo que puede ser motivo de preocupación. [54] En los primeros días de la toma de huellas genéticas, los datos de población necesarios para calcular con precisión la probabilidad de coincidencia a veces no estaban disponibles. Entre 1992 y 1996, se establecieron polémicamente límites bajos y arbitrarios a las probabilidades de coincidencia utilizadas en el análisis RFLP, en lugar de los más altos calculados teóricamente. [55]
Es posible utilizar perfiles de ADN como evidencia de una relación genética, aunque dicha evidencia varía en intensidad, de débil a positiva. Las pruebas que no muestran ninguna relación son absolutamente seguras. Además, mientras que casi todos los individuos tienen un conjunto único y distinto de genes, los individuos ultra raros, conocidos como " quimeras ", tienen al menos dos conjuntos diferentes de genes. Ha habido dos casos de perfiles de ADN que sugirieron falsamente que una madre no tenía relación con sus hijos. [56]
El análisis funcional de genes y sus secuencias codificantes ( marcos de lectura abiertos [ORF]) generalmente requiere que se exprese cada ORF, se purifique la proteína codificada, se produzcan anticuerpos, se examinen los fenotipos, se determine la localización intracelular y se busquen interacciones con otras proteínas. [57] En un estudio realizado por la empresa de ciencias biológicas Nucleix y publicado en la revista Forensic Science International , los científicos descubrieron que se puede construir una muestra de ADN sintetizada in vitro que coincida con cualquier perfil genético deseado utilizando técnicas estándar de biología molecular sin obtener ningún tejido real. de esa persona.
La búsqueda de ADN familiar (a veces denominada "ADN familiar" o "búsqueda en la base de datos de ADN familiar") es la práctica de crear nuevas pistas de investigación en los casos en que las pruebas de ADN encontradas en la escena de un delito (perfil forense) se parecen mucho a las de una investigación existente. Perfil de ADN (perfil de delincuente) en una base de datos de ADN estatal pero no hay una coincidencia exacta. [58] [59] Después de que se hayan agotado todas las demás pistas, los investigadores pueden utilizar un software especialmente desarrollado para comparar el perfil forense con todos los perfiles tomados de la base de datos de ADN de un estado para generar una lista de los delincuentes que ya están en la base de datos y que tienen más probabilidades de ser un pariente muy cercano del individuo cuyo ADN está en el perfil forense. [60]
La búsqueda en bases de datos de ADN familiar se utilizó por primera vez en una investigación que condujo a la condena de Jeffrey Gafoor por el asesinato de Lynette White en el Reino Unido el 4 de julio de 2003. Las pruebas de ADN coincidieron con las del sobrino de Gafoor, que a los 14 años no había nacido en en el momento del asesinato en 1988. Se utilizó de nuevo en 2004 [61] para encontrar a un hombre que arrojó un ladrillo desde un puente de la autopista y golpeó a un camionero, matándolo. El ADN encontrado en el ladrillo coincidía con el encontrado en la escena del robo de un automóvil ese mismo día, pero no había buenas coincidencias en la base de datos nacional de ADN. Una búsqueda más amplia encontró una coincidencia parcial con un individuo; Al ser interrogado, este hombre reveló que tenía un hermano, Craig Harman, que vivía muy cerca de la escena del crimen original. Harman presentó voluntariamente una muestra de ADN y confesó cuando coincidía con la muestra del ladrillo. [62] A partir de 2011, la búsqueda en bases de datos de ADN familiar no se realiza a nivel nacional en los Estados Unidos, donde los estados determinan cómo y cuándo realizar búsquedas familiares. La primera búsqueda de ADN familiar con una condena posterior en los Estados Unidos se llevó a cabo en Denver , Colorado, en 2008, utilizando un software desarrollado bajo el liderazgo del fiscal de distrito de Denver, Mitch Morrissey , y el director del laboratorio criminalístico del Departamento de Policía de Denver, Gregg LaBerge. [63] California fue el primer estado en implementar una política de búsqueda familiar bajo el entonces Fiscal General Jerry Brown , quien más tarde se convirtió en Gobernador. [64] En su papel como consultor del Grupo de Trabajo de Búsqueda Familiar del Departamento de Justicia de California , se considera ampliamente que el ex fiscal del condado de Alameda, Rock Harmon, fue el catalizador en la adopción de la tecnología de búsqueda familiar en California. La técnica se utilizó para atrapar al asesino en serie de Los Ángeles conocido como " Grim Sleeper " en 2010. [65] No fue un testigo o informante quien alertó a las autoridades sobre la identidad del asesino en serie "Grim Sleeper", que había eludió a la policía durante más de dos décadas, pero el ADN del propio hijo del sospechoso. El hijo del sospechoso había sido arrestado y condenado por un delito grave de posesión de armas y se le había realizado una prueba de ADN el año anterior. Cuando su ADN se ingresó en la base de datos de delincuentes convictos, los detectives fueron alertados de una coincidencia parcial con la evidencia encontrada en las escenas del crimen de "Grim Sleeper". David Franklin Jr., también conocido como Grim Sleeper, fue acusado de diez cargos de asesinato y un cargo de intento de asesinato. [66] Más recientemente, el ADN familiar condujo al arresto de Elvis García, de 21 años, acusado de agresión sexual y encarcelamiento falso de una mujer en Santa Cruz en 2008. [67]En marzo de 2011, el gobernador de Virginia, Bob McDonnell, anunció que Virginia comenzaría a utilizar búsquedas de ADN familiar. [68]
En una conferencia de prensa en Virginia el 7 de marzo de 2011, sobre el violador de la costa este , el fiscal del condado de Prince William, Paul Ebert, y el detective de la policía del condado de Fairfax, John Kelly, dijeron que el caso se habría resuelto hace años si Virginia hubiera utilizado la búsqueda de ADN familiar. Aaron Thomas, el presunto violador de la costa este, fue arrestado en relación con la violación de 17 mujeres desde Virginia hasta Rhode Island, pero no se utilizó ADN familiar en el caso. [69]
Los críticos de las búsquedas en bases de datos de ADN familiar argumentan que la técnica es una invasión de los derechos de la Cuarta Enmienda de un individuo . [70] Los defensores de la privacidad están solicitando restricciones a las bases de datos de ADN, argumentando que la única manera justa de buscar posibles coincidencias de ADN con familiares de delincuentes o detenidos sería tener una base de datos de ADN para toda la población. [50] Algunos académicos han señalado que las preocupaciones sobre la privacidad que rodean la búsqueda familiar son similares en algunos aspectos a otras técnicas de búsqueda policial, [71] y la mayoría ha llegado a la conclusión de que la práctica es constitucional. [72] El Tribunal de Apelaciones del Noveno Circuito en el caso Estados Unidos v. Pool (anulado como discutible) sugirió que esta práctica es algo análoga a un testigo que mira una fotografía de una persona y afirma que se parece al perpetrador, lo que lleva a las fuerzas del orden. para mostrar a los testigos fotografías de individuos de apariencia similar, uno de los cuales es identificado como el perpetrador. [73]
Los críticos también afirman que la elaboración de perfiles raciales podría ocurrir debido a pruebas de ADN familiares. En Estados Unidos, las tasas de condenas de las minorías raciales son mucho más altas que las de la población en general. No está claro si esto se debe a la discriminación por parte de los agentes de policía y los tribunales, en contraposición a una simple tasa más alta de delitos entre las minorías. Las bases de datos basadas en arrestos, que se encuentran en la mayoría de los Estados Unidos, conducen a un nivel aún mayor de discriminación racial. Un arresto, a diferencia de una condena, depende mucho más de la discreción de la policía. [50]
Por ejemplo, los investigadores de la Oficina del Fiscal de Distrito de Denver identificaron con éxito a un sospechoso en un caso de robo de propiedad mediante una búsqueda de ADN familiar. En este ejemplo, la sangre del sospechoso que quedó en la escena del crimen se parecía mucho a la de un prisionero actual del Departamento Correccional de Colorado . [63]
Las coincidencias parciales de ADN son el resultado de búsquedas CODIS de rigurosidad moderada que producen una coincidencia potencial que comparte al menos un alelo en cada locus . [74] La comparación parcial no implica el uso de software de búsqueda familiar, como los utilizados en el Reino Unido y los Estados Unidos, ni análisis Y-STR adicionales y, por lo tanto, a menudo pasa por alto las relaciones entre hermanos. La comparación parcial se ha utilizado para identificar sospechosos en varios casos en ambos países [75] y también se ha utilizado como herramienta para exonerar a los acusados falsamente. Darryl Hunt fue condenado erróneamente en relación con la violación y el asesinato de una joven en 1984 en Carolina del Norte . [76]
Las fuerzas policiales pueden recolectar muestras de ADN sin el conocimiento del sospechoso y utilizarlas como prueba. La legalidad de la práctica ha sido cuestionada en Australia . [77]
En los Estados Unidos , donde ha sido aceptado, los tribunales a menudo dictaminan que no existe expectativa de privacidad y citan California v. Greenwood (1988), en el que la Corte Suprema sostuvo que la Cuarta Enmienda no prohíbe el registro e incautación sin orden judicial de Basura dejada para su recogida fuera del recinto de una vivienda . Los críticos de esta práctica subrayan que esta analogía ignora que "la mayoría de las personas no tienen idea de que corren el riesgo de entregar su identidad genética a la policía si, por ejemplo, no destruyen una taza de café usada. Además, incluso si se dan cuenta, hay No hay manera de evitar abandonar el propio ADN en público." [78]
La Corte Suprema de los Estados Unidos dictaminó en Maryland v. King (2013) que la toma de muestras de ADN de prisioneros arrestados por delitos graves es constitucional. [79] [80] [81]
En el Reino Unido , la Ley de Tejidos Humanos de 2004 prohíbe a los particulares recolectar de forma encubierta muestras biológicas (cabello, uñas, etc.) para análisis de ADN, pero exime de la prohibición las investigaciones médicas y penales. [82]
La evidencia de un experto que haya comparado muestras de ADN debe ir acompañada de evidencia sobre las fuentes de las muestras y los procedimientos para obtener los perfiles de ADN. [83] El juez debe asegurarse de que el jurado comprenda la importancia de las coincidencias y discrepancias de ADN en los perfiles. El juez también debe asegurarse de que el jurado no confunda la probabilidad de coincidencia (la probabilidad de que una persona elegida al azar tenga un perfil de ADN coincidente con la muestra de la escena) con la probabilidad de que una persona con ADN coincidente haya cometido el delito. En 1996 , R contra Doheny [84]
Los jurados deben sopesar las pruebas contradictorias y corroborativas, utilizando su propio sentido común y no utilizando fórmulas matemáticas, como el teorema de Bayes , para evitar "confusiones, malentendidos y errores de juicio". [85]
En R v Bates , [86] Moore-Bick LJ dijo:
No vemos ninguna razón por la que la evidencia de ADN de perfil parcial no deba ser admisible siempre que el jurado sea consciente de sus limitaciones inherentes y se le dé una explicación suficiente para permitirle evaluarla. Puede haber casos en los que la probabilidad de coincidencia en relación con todas las muestras analizadas sea tan grande que el juez considere que su valor probatorio es mínimo y decida excluir la prueba en el ejercicio de su discreción, pero esto no da lugar a ninguna cuestión nueva. por principio y puede dejarse a la decisión caso por caso. Sin embargo, el hecho de que en el caso de todas las pruebas de perfil parcial exista la posibilidad de que un alelo "faltante" pueda exculpar al acusado por completo no proporciona motivos suficientes para rechazar dichas pruebas. En muchos casos existe la posibilidad (al menos en teoría) de que existan pruebas que ayuden al acusado y tal vez incluso lo exculpen por completo, pero eso no proporciona motivos para excluir pruebas relevantes que están disponibles y que de otro modo son admisibles, aunque sí las hacen importantes. para garantizar que el jurado reciba suficiente información para permitirle evaluar esa evidencia adecuadamente. [87]
Existen leyes estatales sobre perfiles de ADN en los 50 estados de los Estados Unidos . [88] Puede encontrarse información detallada sobre las leyes de bases de datos en cada estado en el sitio web de la Conferencia Nacional de Legislaturas Estatales . [89]
En agosto de 2009, científicos de Israel plantearon serias dudas sobre el uso del ADN por parte de las fuerzas del orden como método definitivo de identificación. En un artículo publicado en la revista Forensic Science International: Genetics , los investigadores israelíes demostraron que es posible fabricar ADN en un laboratorio, falsificando así las pruebas de ADN. Los científicos fabricaron muestras de saliva y sangre que originalmente contenían ADN de una persona distinta del supuesto donante de sangre y saliva. [90]
Los investigadores también demostraron que, utilizando una base de datos de ADN, es posible tomar información de un perfil y fabricar ADN para que coincida con él, y que esto se puede hacer sin acceso al ADN real de la persona cuyo ADN se están duplicando. Los oligonucleótidos de ADN sintéticos necesarios para el procedimiento son habituales en los laboratorios moleculares. [90]
El New York Times citó al autor principal, Daniel Frumkin, diciendo: "Se puede diseñar la escena de un crimen... cualquier estudiante de biología podría realizar esto". [90] Frumkin perfeccionó una prueba que puede diferenciar muestras de ADN reales de las falsas. Su prueba detecta modificaciones epigenéticas , en particular la metilación del ADN . [91] El setenta por ciento del ADN en cualquier genoma humano está metilado, lo que significa que contienemodificaciones del grupo metilo dentro de un contexto de dinucleótido CpG . La metilación en la región promotora está asociada con el silenciamiento de genes. El ADN sintético carece de esta modificación epigenética , lo que permite a la prueba distinguir el ADN fabricado del ADN genuino. [90]
Se desconoce cuántos departamentos de policía, si es que hay alguno, utilizan actualmente la prueba. Ningún laboratorio policial ha anunciado públicamente que utilizará la nueva prueba para verificar los resultados del ADN. [92]
Investigadores de la Universidad de Tokio integraron un esquema de replicación de ADN artificial con un sistema de expresión genética reconstruido y microcompartimentalización utilizando únicamente materiales libres de células por primera vez. Se realizaron múltiples ciclos de dilución en serie en un sistema contenido en gotas de agua en aceite a microescala. [93]
Posibilidades de realizar un cambio de ADN a propósito
En general, el ADN genómico artificial de este estudio, que se copió a sí mismo utilizando proteínas autocodificadas y mejoró su secuencia por sí solo, es un buen punto de partida para crear células artificiales más complejas. Al agregar los genes necesarios para la transcripción y la traducción al ADN genómico artificial, en el futuro será posible crear células artificiales que puedan crecer por sí solas cuando se alimenten con pequeñas moléculas como aminoácidos y nucleótidos. Usar organismos vivos para fabricar cosas útiles, como medicamentos y alimentos, sería más estable y más fácil de controlar en estas células artificiales. [93]
El 7 de julio de 2008, la sociedad química estadounidense informó que químicos japoneses habían creado la primera molécula de ADN del mundo compuesta casi en su totalidad por componentes sintéticos.
Un factor de transcripción artificial basado en nanopartículas para la regulación genética:
Nano Script es un factor de transcripción artificial basado en nanopartículas que se supone replica la estructura y función de los TF. A las nanopartículas de oro, se unieron péptidos funcionales y pequeñas moléculas denominadas factores de transcripción sintéticos, que imitan los distintos dominios TF, para crear Nano Script. Mostramos que Nano Script se localiza en el núcleo y comienza la transcripción de un plásmido informador en una cantidad de más de 15 veces. Además, Nano Script puede transcribir con éxito genes específicos en ADN endógeno de forma no viral. [94]
Se fijaron cuidadosamente tres fluoróforos diferentes (rojo, verde y azul) en la superficie de la varilla de ADN para proporcionar información espacial y crear un código de barras a nanoescala. La microscopía de fluorescencia de epifluorescencia y reflexión interna total descifró de manera confiable la información espacial entre fluoróforos. Al mover los tres fluoróforos en la varilla de ADN, este código de barras a nanoescala creó 216 patrones de fluorescencia. [95]
Se han utilizado pruebas de ADN para establecer el derecho de sucesión de títulos británicos. [132]
Casos:
Las formas originales de prueba e interpretación forense del ADN utilizadas en los años 1980 y principios de los 1990 fueron objeto de muchas críticas durante las "Guerras del ADN", cuya historia ha sido hábilmente contada por otros (Kaye, 2010; Lynch et al., 2008; ver capítulo 1). Pero estas técnicas anteriores han sido reemplazadas en el análisis forense de ADN por la tipificación discreta de alelos STR basada en PCR. Los tribunales ahora aceptan universalmente como generalmente confiables tanto el proceso de PCR para la amplificación de ADN como el sistema basado en STR para identificar y comparar alelos (Kaye, 2010, pp. 190-191).
{{cite journal}}: CS1 maint: multiple names: authors list (link){{cite web}}: CS1 maint: bot: original URL status unknown (link){kind=link}