Incrustación de vecinos estocásticos distribuidos en t (t-SNE)
La incrustación de vecinos estocásticos distribuidos en t (t-SNE) es un método estadístico para visualizar datos de alta dimensión asignando a cada punto de datos una ubicación en un mapa bidimensional o tridimensional.Se basa en la incrustación de vecinos estocástica desarrollada originalmente por Geoffrey Hinton y Sam Roweis,[1] donde Laurens van der Maaten propuso la variante t-distribuida.Concretamente, modela cada objeto de alta dimensión mediante un punto bidimensional o tridimensional, de tal forma que los objetos similares se modelan mediante puntos cercanos y los objetos disímiles se modelan mediante puntos distantes con alta probabilidad.El algoritmo t-SNE consta de dos etapas principales.En primer lugar, t-SNE construye una distribución de probabilidad sobre pares de objetos de alta dimensión de tal forma que a los objetos similares se les asigna una probabilidad mayor, mientras que a los puntos disímiles se les asigna una probabilidad menor.En segundo lugar, t-SNE define una distribución de probabilidad similar sobre los puntos del mapa de baja dimensión y minimiza la divergencia de Kullback-Leibler (divergencia KL) entre las dos distribuciones con respecto a las ubicaciones de los puntos en el mapa.Aunque el algoritmo original utiliza la distancia euclidiana entre objetos como base de su métrica de similitud, ésta puede modificarse según convenga.La t-SNE se ha utilizado para la visualización en una amplia gama de aplicaciones, como la genómica, la investigación en seguridad informática,[3] el procesamiento del lenguaje natural, el análisis musical,[4] la investigación del cáncer,[5] la bioinformática,[6] la interpretación de dominios geológicos,[7][8][9] y el procesamiento de señales biomédicas.[10] Aunque los gráficos t-SNE a menudo parecen mostrar clusters, los clústers o conglomerados visuales pueden estar fuertemente influenciados por la parametrización elegida y, por lo tanto, es necesario un buen conocimiento de los parámetros para t-SNE.Se puede demostrar que estos "conglomerados" aparecen incluso en datos no agrupados,[11] por lo que pueden ser falsos hallazgos.Por tanto, puede ser necesaria una exploración interactiva para elegir los parámetros y validar los resultados.[12][13] Se ha demostrado que t-SNE a menudo es capaz de recuperar conglomerados bien separados y, con elecciones especiales de los parámetros, se aproxima a una forma simple de agrupación espectral.[14] Para un conjunto de datos con n elementos, t-SNE se ejecuta en tiempo O(n2) y requiere espacio O(n2).que son proporcionales a la similitud de los objetosObsérvese que el denominador anterior garantizacomo su vecino si los vecinos se eligieran en proporción a su densidad de probabilidad bajo una gaussiana centrada enEsto es motivado debido a quede las N muestras se estiman como 1/N, por lo que la probabilidad condicional puede escribirse comoTambién se debe tener en cuenta quese fija de forma que la entropía de la distribución condicional sea igual a una entropía predefinida mediante el método de bisección.se utilizan en las partes más densas del espacio de datos.Dado que el kernel gaussiano utiliza la distancia euclidianase vuelven demasiado similares (asintóticamente, convergerían a una constante).Para paliarlo, se ha propuesto ajustar las distancias con una transformada de potencia, basada en la dimensión intrínseca de cada punto.t-SNE pretende aprender un mapa dimensionalnormalmente elegido como 2 o 3) que refleje las similitudesEn este caso se utiliza una distribución t de Student de colas gruesas (con un grado de libertad, que es lo mismo que una distribución de Cauchy) para medir las similitudes entre puntos de baja dimensión, con el fin de permitir que los objetos disímiles se modelen muy separados en el mapa.en el mapa se determina minimizando la divergencia (no simétrica) de Kullback-Leibler de la distribuciónse realiza mediante el descenso de gradiente.El resultado de esta optimización es un mapa que refleja las similitudes entre las entradas de alta dimensión.
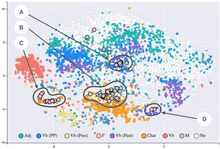
Visualización T-SNE de incrustaciones de palabras (
word embedding
)
generadas a partir de literatura del siglo XIX