ASCII ( / ˈ æ s k iː / ASS-kee),[3]: 6, acrónimo deCódigo estándar estadounidense para el intercambio de información, es unde codificación de caracterespara comunicaciones electrónicas. Los códigos ASCII representan texto en computadoras,equipos de telecomunicacionesy otros dispositivos. ASCII tiene sólo 128puntos de código, de los cuales sólo 95 son caracteres imprimibles, lo que limita gravemente su alcance. El conjunto de puntuación disponible tuvo un impacto significativo en la sintaxis de los lenguajes informáticos y el marcado de texto. ASCII influyó enormemente en el diseño de los juegos de caracteres utilizados por las computadoras modernas, incluidoUnicode, que tiene más de un millón de puntos de código, pero los primeros 128 de ellos son los mismos que ASCII.
La Autoridad de Números Asignados en Internet (IANA) prefiere el nombre US-ASCII para esta codificación de caracteres. [2]
ASCII es uno de los hitos del IEEE . [4]
ASCII se desarrolló en parte a partir del código telegráfico . Su primer uso comercial fue en el Teletype Model 33 y el Teletype Model 35 como código de teleimpresor de siete bits promovido por los servicios de datos de Bell. [ ¿cuando? ] El trabajo en el estándar ASCII comenzó en mayo de 1961, con la primera reunión del subcomité X3.2 de la Asociación Estadounidense de Estándares (ASA) (ahora Instituto Nacional Estadounidense de Estándares o ANSI). La primera edición de la norma se publicó en 1963, [5] [6] se sometió a una revisión importante durante 1967, [7] [8] y experimentó su actualización más reciente durante 1986. [9] En comparación con los códigos telegráficos anteriores, los códigos telegráficos propuestos Se ordenaron tanto el código Bell como el ASCII para una clasificación más conveniente (es decir, alfabetización) de las listas y se agregaron funciones para dispositivos distintos de los teleimpresores. [9]
El uso del formato ASCII para el intercambio de redes se describió en 1969. [10] Ese documento fue elevado formalmente a estándar de Internet en 2015. [11]
Originalmente basado en el alfabeto inglés (moderno) , ASCII codifica 128 caracteres específicos en enteros de siete bits, como se muestra en el cuadro ASCII de este artículo. [12] Noventa y cinco de los caracteres codificados son imprimibles: estos incluyen los dígitos del 0 al 9 , las letras minúsculas de la A a la Z , las letras mayúsculas de la A a la Z y los símbolos de puntuación . Además, la especificación ASCII original incluía 33 códigos de control no imprimibles que se originaron con los modelos Teletype ; la mayoría de ellos ahora están obsoletos, [13] aunque algunos todavía se usan comúnmente, como el retorno de carro , el avance de línea y los códigos de tabulación .
Por ejemplo, la i minúscula estaría representada en la codificación ASCII por el binario 1101001 = hexadecimal 69 ( i es la novena letra) = decimal 105.
A pesar de ser un estándar americano, ASCII no tiene un punto de código para el centavo (¢). Tampoco admite términos en inglés con signos diacríticos como currículum y jalapeño , ni nombres propios con signos diacríticos como Beyoncé .

El Código Estándar Estadounidense para el Intercambio de Información (ASCII) fue desarrollado bajo los auspicios de un comité de la Asociación Estadounidense de Estándares (ASA), llamado comité X3, por su subcomité X3.2 (más tarde X3L2), y más tarde por el X3 de ese subcomité. Grupo de trabajo 2.4 (ahora INCITS ). Posteriormente, la ASA se convirtió en el Instituto de Estándares de los Estados Unidos de América (USASI) [3] : 211 y finalmente se convirtió en el Instituto Nacional Estadounidense de Estándares (ANSI).
Con los demás caracteres especiales y códigos de control completados, ASCII se publicó como ASA X3.4-1963, [6] [14] dejando 28 posiciones de código sin ningún significado asignado, reservadas para futura estandarización, y un código de control sin asignar. [3] : 66, 245 Hubo cierto debate en ese momento sobre si debería haber más caracteres de control en lugar del alfabeto en minúsculas. [3] : 435 La indecisión no duró mucho: durante mayo de 1963, el Grupo de Trabajo del CCITT sobre el Nuevo Alfabeto Telegráfico propuso asignar caracteres en minúsculas a las barras [a] [15] 6 y 7, [16] y la Organización Internacional de Normalización TC 97 SC 2 votó durante octubre para incorporar el cambio en su proyecto de norma. [17] El grupo de trabajo X3.2.4 votó su aprobación para el cambio a ASCII en su reunión de mayo de 1963. [18] La ubicación de las letras minúsculas en barras [a] [15] 6 y 7 provocó que los caracteres difirieran en el patrón de bits de las mayúsculas en un solo bit, lo que simplificó la coincidencia de caracteres que no distingue entre mayúsculas y minúsculas y la construcción de teclados e impresoras.
El comité X3 realizó otros cambios, incluidos otros caracteres nuevos (los caracteres de llave y barra vertical ), [19] cambiar el nombre de algunos caracteres de control (SOM se convirtió en inicio del encabezado (SOH)) y mover o eliminar otros (se eliminó RU). [3] : 247–248 ASCII se actualizó posteriormente como USAS X3.4-1967, [7] [20] luego USAS X3.4-1968, [21] ANSI X3.4-1977 y, finalmente, ANSI X3.4 -1986. [9] [22]
En el estándar X3.15, el comité X3 también abordó cómo se debe transmitir ASCII ( el bit menos significativo primero) [3] : 249–253 [29] y grabarse en cinta perforada. Propusieron un estándar de 9 pistas para cinta magnética e intentaron trabajar con algunos formatos de tarjetas perforadas .
El subcomité X3.2 diseñó ASCII basándose en los sistemas de codificación de teleimpresores anteriores. Al igual que otras codificaciones de caracteres , ASCII especifica una correspondencia entre patrones de bits digitales y símbolos de caracteres (es decir, grafemas y caracteres de control ). Esto permite que los dispositivos digitales se comuniquen entre sí y procesen, almacenen y comuniquen información orientada a caracteres, como el lenguaje escrito. Antes de que se desarrollara ASCII, las codificaciones en uso incluían 26 caracteres alfabéticos , 10 dígitos numéricos y de 11 a 25 símbolos gráficos especiales. Para incluir todos estos y controlar caracteres compatibles con el estándar del Alfabeto Telegráfico Internacional No. 2 (ITA2) del Comité Consultatif International Téléphonique et Télégraphique (CCITT) de 1932, [30] [31] FIELDATA (1956 [ cita necesaria ] ), y principios EBCDIC (1963), se requerían más de 64 códigos para ASCII.
ITA2 se basó a su vez en el código Baudot , el código telegráfico de 5 bits que Émile Baudot inventó en 1870 y patentó en 1874. [31]
El comité debatió la posibilidad de una función de cambio (como en ITA2 ), que permitiría representar más de 64 códigos mediante un código de seis bits . En un código desplazado, algunos códigos de caracteres determinan las elecciones entre las opciones para los siguientes códigos de caracteres. Permite una codificación compacta, pero es menos confiable para la transmisión de datos , ya que un error en la transmisión del código de cambio generalmente hace que una gran parte de la transmisión sea ilegible. El comité de estándares decidió no realizar cambios, por lo que ASCII requirió al menos un código de siete bits. [3] : 215 §13.6, 236 §4
El comité consideró un código de ocho bits, ya que ocho bits ( octetos ) permitirían que dos patrones de cuatro bits codificaran eficientemente dos dígitos con decimales codificados en binario . Sin embargo, toda transmisión de datos requeriría enviar ocho bits cuando siete podrían ser suficientes. El comité votó a favor de utilizar un código de siete bits para minimizar los costos asociados con la transmisión de datos. Dado que la cinta perforada en ese momento podía grabar ocho bits en una posición, también permitía un bit de paridad para verificar errores si se deseaba. [3] : 217 §c, 236 §5 Las máquinas de ocho bits (con octetos como tipo de datos nativo) que no usaban verificación de paridad generalmente configuraban el octavo bit en 0. [32]
El código en sí estaba diseñado de modo que la mayoría de los códigos de control estuvieran juntos y todos los códigos gráficos estuvieran juntos, para facilitar la identificación. Los dos primeros sticks ASCII [a] [15] (32 posiciones) estaban reservados para los caracteres de control. [3] : 220, 236 8, 9) El carácter "espacio" tenía que ir antes de los gráficos para facilitar la clasificación , por lo que pasó a ser la posición 20 hexadecimal ; [3] : 237 §10 por la misma razón, muchos signos especiales comúnmente utilizados como separadores se colocaron antes de los dígitos. El comité decidió que era importante admitir alfabetos de 64 caracteres en mayúsculas y optó por utilizar un patrón ASCII para poder reducirlo fácilmente a un conjunto utilizable de códigos gráficos de 64 caracteres, [3] : 228, 237 §14 como se hizo en el Código DEC SIXBIT (1963). Por lo tanto, las letras minúsculas no se intercalaban con las mayúsculas . Para mantener opciones disponibles para letras minúsculas y otros gráficos, los códigos numéricos y especiales se dispusieron antes de las letras y la letra A se colocó en la posición 41 hexadecimal para coincidir con el borrador del estándar británico correspondiente. [3] : 238 §18 Los dígitos del 0 al 9 tienen el prefijo 011, pero los 4 bits restantes corresponden a sus respectivos valores en binario, lo que hace que la conversión con decimal codificado en binario sea sencilla (por ejemplo, 5 codificado en 011 0101 , donde 5 es 0101 en binario).
Muchos de los caracteres no alfanuméricos se colocaron para corresponder a su posición cambiada en las máquinas de escribir; una sutileza importante es que se basaban en máquinas de escribir mecánicas , no en máquinas de escribir eléctricas . [33] Las máquinas de escribir mecánicas siguieron el estándar de facto establecido por la Remington No. 2 (1878), la primera máquina de escribir con una tecla de mayúsculas, y los valores desplazados de 23456789-fueron "#$%_&'() : las primeras máquinas de escribir omitieron 0 y 1 , usando O (letra o mayúscula ) y l (letra L minúscula ), pero los pares 1!y 0)se volvieron estándar una vez que 0 y 1 se volvieron comunes. Así, en ASCII !"#$%se colocaron en el segundo stick, [a] [15] las posiciones 1–5, correspondientes a los dígitos 1–5 del stick adyacente. [a] [15] Sin embargo , los paréntesis no podían corresponder a 9 y 0 , porque el lugar correspondiente a 0 lo ocupaba el carácter de espacio. Esto se solucionó eliminando _(guión bajo) de 6 y cambiando los caracteres restantes, lo que correspondía a muchas máquinas de escribir europeas que colocaban los paréntesis con 8 y 9 . Esta discrepancia con las máquinas de escribir condujo a teclados de pares de bits , en particular el Teletype Model 33 , que utilizaba el diseño desplazado a la izquierda correspondiente a ASCII, a diferencia de las máquinas de escribir mecánicas tradicionales.
Las máquinas de escribir eléctricas, en particular la IBM Selectric (1961), utilizaban un diseño algo diferente que se ha convertido en el estándar de facto en las computadoras (siguiendo a la IBM PC (1981), especialmente el Modelo M (1984)) y, por lo tanto, los valores de los símbolos en los teclados modernos no cambian. no se corresponden tan estrechamente con la tabla ASCII como lo hacían los teclados anteriores. El /?par también data del No. 2, y los ,< .>pares se usaron en algunos teclados (otros, incluido el No. 2, no cambiaron ,(coma) o .(punto) para que pudieran usarse en mayúsculas sin cambiar). Sin embargo, ASCII dividió el ;:par (que data del No. 2) y reorganizó los símbolos matemáticos (convenciones variadas, comúnmente -* =+) a :* ;+ -=.
Algunos caracteres de máquina de escribir entonces comunes no se incluyeron, en particular ½ ¼ ¢, mientras que ^ ` ~ se incluyeron como signos diacríticos para uso internacional y < >para uso matemático, junto con los caracteres de línea simple \ |(además de los comunes /). El símbolo @ no se usó en Europa continental y el comité esperaba que fuera reemplazado por una A acentuada en la variación francesa, por lo que la @ se colocó en la posición 40 hexadecimal , justo antes de la letra A. [3] : 243
Los códigos de control que se consideraron esenciales para la transmisión de datos fueron el inicio del mensaje (SOM), el final de la dirección (EOA), el fin del mensaje (EOM), el fin de la transmisión (EOT), "¿quién es usted?" (WRU), "¿lo eres?" (RU), un control de dispositivo reservado (DC0), inactivo síncrono (SYNC) y reconocimiento (ACK). Estos se colocaron para maximizar la distancia de Hamming entre sus patrones de bits. [3] : 243–245
El orden del código ASCII también se denomina orden ASCIIbético . [34] La recopilación de datos a veces se realiza en este orden en lugar del orden alfabético "estándar" ( secuencia de clasificación ). Las principales desviaciones en el orden ASCII son:
Un orden intermedio convierte letras mayúsculas a minúsculas antes de comparar valores ASCII.
.svg/1280px-ASCII_Table_(suitable_for_printing).svg.png)
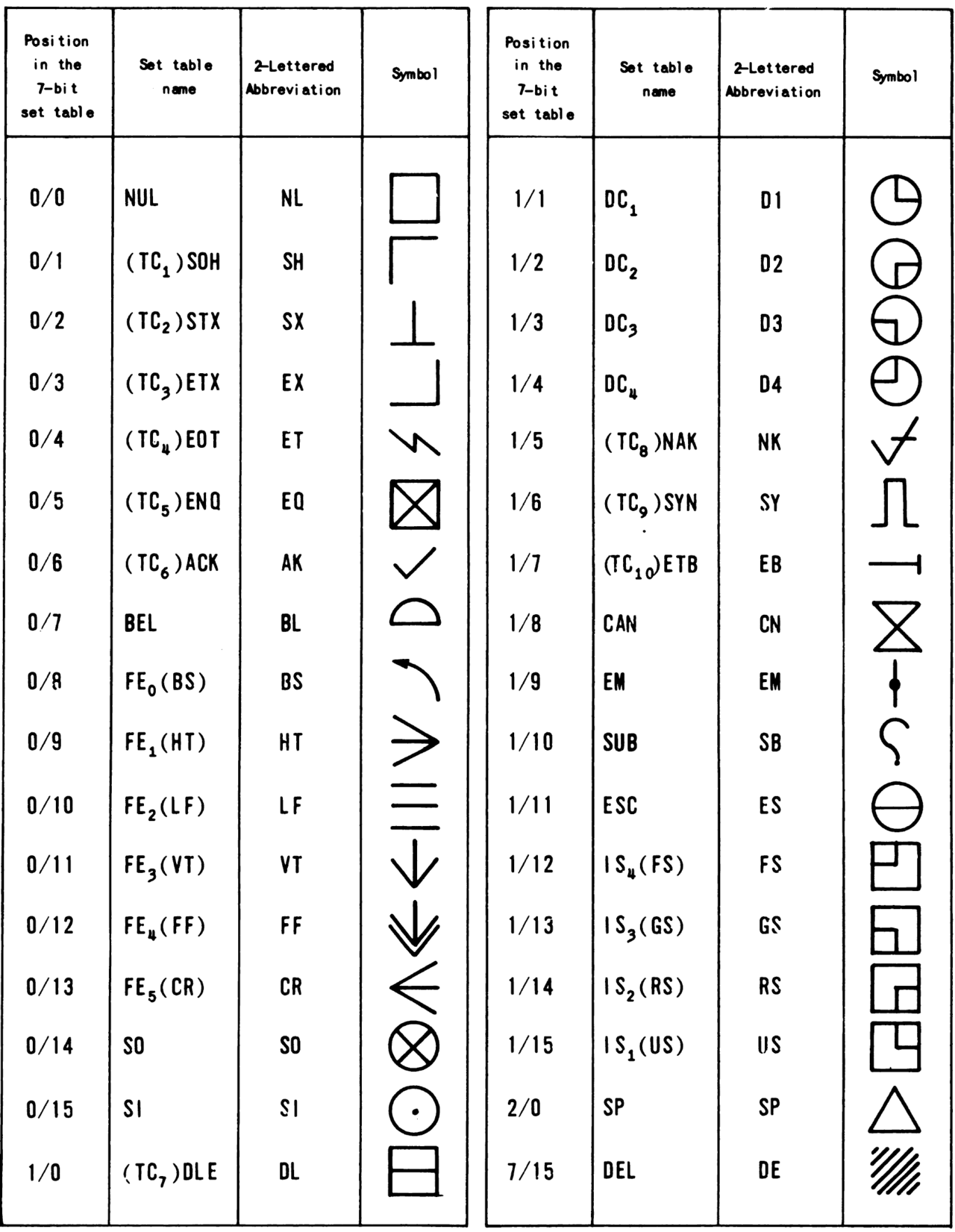
ASCII reserva los primeros 32 puntos de código (números del 0 al 31 decimal) y el último (número 127 decimal) para caracteres de control . Se trata de códigos destinados a controlar dispositivos periféricos (como impresoras ) o a proporcionar metainformación sobre flujos de datos, como los almacenados en cinta magnética. A pesar de su nombre, estos puntos de código no representan caracteres imprimibles (es decir, no son caracteres en absoluto, sino señales). Para fines de depuración, se les asignan símbolos de "marcador de posición" (como los que figuran en ISO 2047 y sus predecesores).
Por ejemplo, el carácter 0x0A representa la función "avance de línea" (que hace que la impresora avance el papel) y el carácter 8 representa " retroceso ". RFC 2822 se refiere a caracteres de control que no incluyen retorno de carro, avance de línea o espacios en blanco como caracteres de control sin espacios en blanco. [35] Excepto por los caracteres de control que prescriben el formato elemental orientado a líneas, ASCII no define ningún mecanismo para describir la estructura o apariencia del texto dentro de un documento. Otros esquemas, como lenguajes de marcado , diseño y formato de páginas de direcciones y documentos.
El estándar ASCII original utilizaba sólo frases descriptivas breves para cada carácter de control. La ambigüedad que esto causó fue a veces intencional, por ejemplo cuando un carácter se usaría de manera ligeramente diferente en un enlace de terminal que en un flujo de datos , y a veces accidental, por ejemplo, el estándar no es claro sobre el significado de "eliminar".
Probablemente el dispositivo más influyente que afectó la interpretación de estos caracteres fue el Teletipo Modelo 33 ASR, que era un terminal de impresión con una opción de lector/perforador de cinta de papel disponible. La cinta de papel fue un medio muy popular para el almacenamiento de programas a largo plazo hasta la década de 1980, menos costosa y, en cierto modo, menos frágil que la cinta magnética. En particular, las asignaciones de máquina Teletype Model 33 para los códigos 17 (control-Q, DC1, también conocido como XON), 19 (control-S, DC3, también conocido como XOFF) y 127 ( eliminar ) se convirtieron en estándares de facto . El Modelo 33 también se destacó por tomar literalmente la descripción de control-G (código 7, BEL, que significa alertar audiblemente al operador), ya que la unidad contenía una campana real que sonaba cuando recibía un carácter BEL. Debido a que la parte superior de la tecla O también mostraba un símbolo de flecha izquierda (de ASCII-1963, que tenía este carácter en lugar de guión bajo ), un uso no conforme del código 15 (control-O, mayúscula hacia adentro) se interpretó como "eliminar carácter anterior". También fue adoptado por muchos de los primeros sistemas de tiempo compartido, pero finalmente quedó abandonado.
Cuando un Teletype 33 ASR equipado con un lector automático de cintas de papel recibió un control-S (XOFF, una abreviatura de transmisión desactivada), provocó que el lector de cintas se detuviera; La recepción de control-Q (XON, transmisión activada) provocó que el lector de cintas se reanudara. Esta llamada técnica de control de flujo fue adoptada por varios de los primeros sistemas operativos informáticos como una señal de "apretón de manos" que advertía al remitente que detuviera la transmisión debido a un inminente desbordamiento del búfer ; persiste hasta el día de hoy en muchos sistemas como técnica de control de salida manual. En algunos sistemas, control-S conserva su significado, pero control-Q se reemplaza por un segundo control-S para reanudar la salida.
El 33 ASR también podría configurarse para emplear control-R (DC2) y control-T (DC4) para iniciar y detener la perforación de la cinta; en algunas unidades equipadas con esta función, las letras del carácter de control correspondiente en la tecla encima de la letra eran TAPE y TAPE respectivamente. [36]
El Teletipo no podía mover su tipografía hacia atrás, por lo que no tenía una tecla en su teclado para enviar un BS (retroceso). En cambio, había una clave marcada RUB OUTque enviaba el código 127 (DEL). El propósito de esta clave era borrar errores en una cinta de papel ingresada manualmente: el operador tenía que presionar un botón en la perforadora de cinta para respaldarla, luego escribir el borrado, que perforaba todos los agujeros y reemplazaba el error con un carácter que estaba destinado a ser ignorado. [37] Los teletipos se usaban comúnmente con las computadoras menos costosas de Digital Equipment Corporation (DEC); estos sistemas tenían que usar las teclas disponibles y, por lo tanto, se asignó el carácter DEL para borrar el carácter anterior. [38] [39] Debido a esto, los terminales de video DEC (por defecto) enviaron el carácter DEL para la tecla marcada "Retroceso" mientras que la tecla separada marcada "Eliminar" envió una secuencia de escape ; muchos otros terminales de la competencia enviaron un carácter BS para la tecla de retroceso.
Los primeros controladores tty de Unix, a diferencia de algunas implementaciones modernas, permitían configurar solo un carácter para borrar el carácter anterior en el procesamiento de entrada canónico (donde está disponible un editor de líneas muy simple); esto podría configurarse en BS o DEL, pero no en ambos, lo que resultaba en situaciones recurrentes de ambigüedad en las que los usuarios tenían que decidir dependiendo de qué terminal estaban usando ( los shells que permiten la edición de líneas, como ksh , bash y zsh , entienden ambos) . La suposición de que ninguna clave envió un carácter BS permitió que Ctrl+H se usara para otros fines, como el comando de prefijo "ayuda" en GNU Emacs . [40]
A muchos más personajes de control se les han asignado significados bastante diferentes a los originales. El carácter "escape" (ESC, código 27), por ejemplo, estaba destinado originalmente a permitir el envío de otros caracteres de control como literales en lugar de invocar su significado, una "secuencia de escape". Este es el mismo significado de "escape" que se encuentra en codificaciones de URL, cadenas de lenguaje C y otros sistemas donde ciertos caracteres tienen un significado reservado. Con el tiempo, esta interpretación ha sido adoptada y eventualmente modificada.
En el uso moderno, un ESC enviado al terminal generalmente indica el inicio de una secuencia de comandos, que se puede usar para dirigirse al cursor, desplazarse por una región, configurar/consultar varias propiedades del terminal y más. Por lo general, tienen la forma del llamado " código de escape ANSI " (a menudo comienza con un " Introductor de secuencia de control ", "CSI", " ESC [ ") de ECMA-48 (1972) y sus sucesores. Algunas secuencias de escape no tienen introductores, como el comando de reinicio completo del VT100 " ESC c ". [41]
Por el contrario, un ESC leído desde el terminal se utiliza con mayor frecuencia como un carácter fuera de banda utilizado para finalizar una operación o modo especial, como en los editores de texto TECO y vi . En la interfaz gráfica de usuario (GUI) y los sistemas de ventanas , ESC generalmente hace que una aplicación cancele su operación actual o salga (finalice) por completo.
La ambigüedad inherente de muchos caracteres de control, combinada con su uso histórico, creó problemas al transferir archivos de "texto sin formato" entre sistemas. El mejor ejemplo de esto es el problema de nueva línea en varios sistemas operativos . Las máquinas de teletipo requerían que una línea de texto terminara con "retorno de carro" (que mueve el cabezal de impresión al comienzo de la línea) y "avance de línea" (que hace avanzar el papel una línea sin mover el cabezal de impresión). El nombre "retorno de carro" proviene del hecho de que en una máquina de escribir manual el carro que sostiene el papel se mueve mientras las barras que golpean la cinta permanecen estacionarias. Todo el carro tuvo que ser empujado (devuelto) hacia la derecha para colocar el papel para la siguiente línea.
Los sistemas operativos DEC ( OS/8 , RT-11 , RSX-11 , RSTS , TOPS-10 , etc.) usaban ambos caracteres para marcar el final de una línea para que el dispositivo de consola (originalmente máquinas de teletipo) funcionara. Cuando aparecieron los llamados "TTY de cristal" (más tarde llamados CRT o "terminales tontos"), la convención estaba tan bien establecida que la compatibilidad con versiones anteriores requirió seguirla. Cuando Gary Kildall creó CP/M , se inspiró en algunas de las convenciones de interfaz de línea de comandos utilizadas en el sistema operativo RT-11 de DEC.
Hasta la introducción de PC DOS en 1981, IBM no tuvo influencia en esto porque sus sistemas operativos de la década de 1970 usaban codificación EBCDIC en lugar de ASCII, y estaban orientados hacia la entrada de tarjetas perforadas y la salida de impresoras de líneas en las que se aplicaba el concepto de "retorno de carro". sin sentido. El PC DOS de IBM (también comercializado como MS-DOS por Microsoft) heredó la convención en virtud de estar basado libremente en CP/M, [42] y Windows , a su vez, la heredó de MS-DOS.
Requerir dos caracteres para marcar el final de una línea introduce complejidad y ambigüedad innecesarias en cuanto a cómo interpretar cada carácter cuando se encuentra por sí solo. Para simplificar las cosas, los flujos de datos de texto sin formato , incluidos los archivos, en Multics utilizaban el avance de línea (LF) solo como terminador de línea. [43] : 357 El controlador tty manejaría la conversión de LF a CRLF en la salida para que los archivos se puedan imprimir directamente en la terminal, y NL (nueva línea) se usa a menudo para referirse a CRLF en documentos UNIX . Los sistemas Unix y similares , y los sistemas Amiga , adoptaron esta convención de Multics. Por otro lado, el Macintosh OS , Apple DOS y ProDOS originales utilizaban el retorno de carro (CR) únicamente como terminador de línea; sin embargo, dado que Apple luego reemplazó estos sistemas operativos obsoletos con su sistema operativo macOS basado en Unix (anteriormente llamado OS X), ahora también usan salto de línea (LF). El Radio Shack TRS-80 también utilizó un CR solitario para terminar las líneas.
Las computadoras conectadas a ARPANET incluían máquinas que ejecutaban sistemas operativos como TOPS-10 y TENEX que usaban terminaciones de línea CR-LF; máquinas que ejecutan sistemas operativos como Multics que utilizan finales de línea LF; y máquinas que ejecutaban sistemas operativos como OS/360 que representaban líneas como un recuento de caracteres seguido de los caracteres de la línea y que utilizaban codificación EBCDIC en lugar de ASCII. El protocolo Telnet definió una "Terminal virtual de red" (NVT) ASCII, de modo que se pudieran admitir conexiones entre hosts con diferentes convenciones de final de línea y conjuntos de caracteres mediante la transmisión de un formato de texto estándar a través de la red. Telnet usaba ASCII junto con finales de línea CR-LF, y el software que usaba otras convenciones se traduciría entre las convenciones locales y NVT. [44] El Protocolo de transferencia de archivos adoptó el protocolo Telnet, incluido el uso de la Terminal virtual de red, para su uso al transmitir comandos y transferir datos en el modo ASCII predeterminado. [45] [46] Esto agrega complejidad a las implementaciones de esos protocolos y a otros protocolos de red, como los utilizados para el correo electrónico y la World Wide Web, en sistemas que no utilizan la convención de final de línea CR-LF de NVT. [47] [48]
El monitor PDP-6, [38] y su sucesor PDP-10, TOPS-10, [39] utilizaron control-Z (SUB) como indicación de fin de archivo para la entrada desde un terminal. Algunos sistemas operativos, como CP/M, rastreaban la longitud del archivo solo en unidades de bloques de disco y usaban control-Z para marcar el final del texto real en el archivo. [49] Por estas razones, EOF, o fin de archivo , se usó coloquial y convencionalmente como un acrónimo de tres letras para control-Z en lugar de SUBstitute. El carácter de fin de texto ( ETX ), también conocido como control-C , era inapropiado por diversas razones, mientras que usar control-Z como carácter de control para finalizar un archivo es análogo a la posición de la letra Z al final de el alfabeto y sirve como una ayuda mnemotécnica muy conveniente . Una convención históricamente común y aún prevalente utiliza la convención de caracteres ETX para interrumpir y detener un programa mediante un flujo de datos de entrada, generalmente desde un teclado.
El controlador de terminal Unix utiliza el carácter de fin de transmisión ( EOT ), también conocido como control-D, para indicar el final de un flujo de datos.
En el lenguaje de programación C y en las convenciones de Unix, el carácter nulo se utiliza para terminar cadenas de texto ; Estas cadenas terminadas en nulo pueden conocerse abreviadamente como ASCIZ o ASCIIZ, donde aquí Z significa "cero".
Equipos especializados pueden utilizar otras representaciones, por ejemplo, gráficos ISO 2047 o números hexadecimales .
Los códigos 20 hexadecimal a 7E hexadecimal , conocidos como caracteres imprimibles, representan letras, dígitos, signos de puntuación y algunos símbolos diversos. Hay 95 caracteres imprimibles en total. [norte]
El código 20 hexadecimal , el carácter "espacio", denota el espacio entre palabras, producido por la barra espaciadora de un teclado. Dado que el carácter de espacio se considera un gráfico invisible (en lugar de un carácter de control) [3] : 223 [10] , aparece en la siguiente tabla en lugar de en la sección anterior.
El código 7F hexadecimal corresponde al carácter de control "eliminar" (DEL) no imprimible y, por lo tanto, se omite en este cuadro; está cubierto en el cuadro de la sección anterior. Las versiones anteriores de ASCII usaban la flecha hacia arriba en lugar del signo de intercalación (5E hex ) y la flecha izquierda en lugar del guión bajo (5F hex ). [6] [50]
ASCII se utilizó comercialmente por primera vez en 1963 como un código de teletipo de siete bits para la red TWX (TeletypeWriter eXchange) de American Telephone & Telegraph . TWX utilizó originalmente el anterior ITA2 de cinco bits , que también fue utilizado por el sistema de teleimpresor Telex de la competencia . Bob Bemer introdujo características como la secuencia de escape . [5] Su colega británico Hugh McGregor Ross ayudó a popularizar este trabajo; según Bemer, "tanto es así que el código que se convertiría en ASCII se llamó por primera vez Código Bemer-Ross en Europa". [51] Debido a su extenso trabajo en ASCII, Bemer ha sido llamado "el padre de ASCII". [52]
El 11 de marzo de 1968, el presidente estadounidense Lyndon B. Johnson ordenó que todas las computadoras compradas por el gobierno federal de los Estados Unidos admitieran ASCII, afirmando: [53] [54] [55]
También he aprobado recomendaciones del Secretario de Comercio [ Luther H. Hodges ] respecto de las normas para registrar el Código Estándar para el Intercambio de Información en cintas magnéticas y cintas de papel cuando se utilizan en operaciones informáticas. Todas las computadoras y configuraciones de equipos relacionados incorporadas al inventario del Gobierno Federal a partir del 1 de julio de 1969 deben tener la capacidad de utilizar el Código estándar para el intercambio de información y los formatos prescritos por las normas de cinta magnética y cinta de papel cuando se utilizan estos medios.
ASCII fue la codificación de caracteres más común en la World Wide Web hasta diciembre de 2007, cuando la codificación UTF-8 la superó; UTF-8 es compatible con versiones anteriores de ASCII. [56] [57] [58]
A medida que la tecnología informática se extendió por todo el mundo, diferentes organismos y corporaciones de normalización desarrollaron muchas variaciones de ASCII para facilitar la expresión de idiomas distintos del inglés que utilizaban alfabetos romanos. Se podrían clasificar algunas de estas variaciones como " extensiones ASCII ", aunque algunas hacen mal uso de ese término para representar todas las variantes, incluidas aquellas que no conservan el mapa de caracteres ASCII en el rango de 7 bits. Además, las extensiones ASCII también han sido etiquetadas erróneamente como ASCII.
Desde el principio de su desarrollo, [59] ASCII pretendía ser sólo una de varias variantes nacionales de un estándar de código de caracteres internacional.
Otros organismos de normalización internacionales han ratificado codificaciones de caracteres como ISO 646 (1967) que son idénticas o casi idénticas a ASCII, con extensiones para caracteres fuera del alfabeto inglés y símbolos utilizados fuera de los Estados Unidos, como el símbolo de la libra esterlina del Reino Unido. (£); por ejemplo, con la página de códigos 1104 . Casi todos los países necesitaban una versión adaptada de ASCII, ya que ASCII se adaptaba sólo a las necesidades de Estados Unidos y algunos otros países. Por ejemplo, Canadá tenía su propia versión que admitía caracteres franceses.
Muchos otros países desarrollaron variantes de ASCII para incluir letras no inglesas (por ejemplo, é , ñ , ß , Ł ), símbolos de moneda (por ejemplo, £ , ¥ ), etc. Véase también YUSCII (Yugoslavia).
Compartiría la mayoría de los caracteres en común, pero asignaría otros caracteres útiles localmente a varios puntos de código reservados para "uso nacional". Sin embargo, los cuatro años que transcurrieron entre la publicación de ASCII-1963 y la primera aceptación por parte de ISO de una recomendación internacional durante 1967 [60] causaron que las elecciones de ASCII para los caracteres de uso nacional parecieran ser estándares de facto para el mundo, causando confusión e incompatibilidad. una vez que otros países comenzaron a hacer sus propias asignaciones a estos puntos de código.
ISO/IEC 646, al igual que ASCII, es un juego de caracteres de 7 bits. No pone a disposición ningún código adicional, por lo que los mismos puntos de código codifican diferentes caracteres en diferentes países. Los códigos de escape se definieron para indicar qué variante nacional se aplicaba a un fragmento de texto, pero rara vez se usaban, por lo que a menudo era imposible saber con qué variante trabajar y, por lo tanto, qué carácter representaba un código y, en general, el texto. De todos modos, los sistemas de procesamiento sólo podían hacer frente a una variante.
Debido a que los caracteres de corchetes y llaves de ASCII se asignaron a puntos de código de "uso nacional" que se usaron para letras acentuadas en otras variantes nacionales de ISO/IEC 646, un programador alemán, francés o sueco, etc., utilizó su variante nacional de ISO. /IEC 646, en lugar de ASCII, tenía que escribir, y por tanto leer, algo como
ä aÄiÜ = 'Ön'; üen lugar de
{ a[i] = '\n'; }Los trigrafos C se crearon para resolver este problema para ANSI C , aunque su introducción tardía y su implementación inconsistente en los compiladores limitaron su uso. Muchos programadores mantuvieron sus computadoras en ASCII, por lo que el texto plano en sueco, alemán, etc. (por ejemplo, en correo electrónico o Usenet ) contenía "{, }" y variantes similares en medio de las palabras, algo a lo que esos programadores se acostumbraron. . Por ejemplo, un programador sueco que envía un correo electrónico a otro programador preguntándole si debería ir a almorzar, podría obtener "N{ jag har sm|rg}sar" como respuesta, que debería ser "Nä jag har smörgåsar", que significa "No, tengo sándwiches".
En Japón y Corea, todavía a partir de la década de 2020, [actualizar]se utiliza una variación de ASCII, en la que la barra invertida (5C hexadecimal) se representa como ¥ (un signo de yen , en Japón) o ₩ (un signo de won , en Corea). Esto significa que, por ejemplo, la ruta del archivo C:\Users\Smith se muestra como C:¥Users¥Smith (en Japón) o C:₩Users₩Smith (en Corea).
En Europa, los juegos de caracteres de teletexto , que son variantes de ASCII, se utilizan para subtítulos de televisión, definidos por World System Teletext y transmitidos utilizando el estándar DVB-TXT para incorporar teletexto en transmisiones DVB. [61] En el caso de que los subtítulos fueran inicialmente creados para teletexto y convertidos, los formatos de subtítulos derivados están restringidos a los mismos conjuntos de caracteres.
Con el tiempo, cuando las computadoras de 8, 16 y 32 bits (y más tarde de 64 bits ) comenzaron a reemplazar a las de 12 , 18 y 36 bits como norma, se volvió común usar un byte de 8 bits para almacena cada carácter en la memoria, brindando una oportunidad para parientes extendidos de 8 bits de ASCII. En la mayoría de los casos, estos se desarrollaron como verdaderas extensiones de ASCII, dejando intacto el mapeo de caracteres original, pero agregando definiciones de caracteres adicionales después de los primeros 128 caracteres (es decir, 7 bits). El propio ASCII siguió siendo un código de siete bits: el término "ASCII ampliado" no tiene estatus oficial.
Para algunos países, se desarrollaron extensiones de ASCII de 8 bits que incluían soporte para caracteres utilizados en idiomas locales; por ejemplo, ISCII para India y VISCII para Vietnam. Las computadoras Kaypro CP/M utilizaban los 128 caracteres "superiores" del alfabeto griego. [ cita necesaria ]
Incluso para los mercados donde no era necesario agregar muchos caracteres para admitir idiomas adicionales, los fabricantes de los primeros sistemas informáticos domésticos a menudo desarrollaban sus propias extensiones de 8 bits de ASCII para incluir caracteres adicionales, como caracteres de dibujo de cuadros , semigráficos y videojuegos. duendes . A menudo, estas adiciones también reemplazaron los caracteres de control (índice 0 a 31, así como el índice 127) con extensiones aún más específicas de la plataforma. En otros casos, el bit extra se utilizó para algún otro propósito, como alternar vídeo inverso ; este enfoque fue utilizado por ATASCII , una extensión de ASCII desarrollada por Atari .
La mayoría de las extensiones ASCII se basan en ASCII-1967 (el estándar actual), pero algunas extensiones se basan en el ASCII-1963 anterior. Por ejemplo, PETSCII , desarrollado por Commodore International para sus sistemas de 8 bits , está basado en ASCII-1963. Asimismo, muchos conjuntos de caracteres Sharp MZ se basan en ASCII-1963.
IBM definió la página de códigos 437 para IBM PC , reemplazando los caracteres de control con símbolos gráficos como caras sonrientes y asignando caracteres gráficos adicionales a las 128 posiciones superiores. [62] Digital Equipment Corporation desarrolló el conjunto de caracteres multinacional (DEC-MCS) para su uso en el popular terminal VT220 como una de las primeras extensiones diseñadas más para idiomas internacionales que para gráficos de bloques. Apple definió Mac OS Roman para Macintosh y Adobe definió la codificación estándar PostScript para PostScript ; Ambos conjuntos contenían letras "internacionales", símbolos tipográficos y signos de puntuación en lugar de gráficos, más parecidos a conjuntos de caracteres modernos.
El estándar ISO/IEC 8859 (derivado del DEC-MCS) proporcionó un estándar que la mayoría de los sistemas copiaron (o al menos en el que se basaron, cuando no se copiaron exactamente). Una extensión adicional popular diseñada por Microsoft, Windows-1252 (a menudo mal etiquetada como ISO-8859-1 ), agregó los signos de puntuación tipográficos necesarios para la impresión de texto tradicional. ISO-8859-1, Windows-1252 y el ASCII original de 7 bits fueron los métodos de codificación de caracteres más comunes en la World Wide Web hasta 2008, cuando UTF-8 los superó. [57]
ISO/IEC 4873 introdujo 32 códigos de control adicionales definidos en el rango hexadecimal 80–9F , como parte de la ampliación de la codificación ASCII de 7 bits para convertirla en un sistema de 8 bits. [63]
Unicode y el conjunto de caracteres universales (UCS) ISO/IEC 10646 tienen una gama mucho más amplia de caracteres y sus diversas formas de codificación han comenzado a suplantar rápidamente a ISO/IEC 8859 y ASCII en muchos entornos. Si bien ASCII está limitado a 128 caracteres, Unicode y UCS admiten más caracteres al separar los conceptos de identificación única (usando números naturales llamados puntos de código ) y codificación (en formatos binarios de 8, 16 o 32 bits, llamados UTF). 8 , UTF-16 y UTF-32 , respectivamente).
ASCII se incorporó al juego de caracteres Unicode (1991) como los primeros 128 símbolos, por lo que los caracteres ASCII de 7 bits tienen los mismos códigos numéricos en ambos juegos. Esto permite que UTF-8 sea compatible con ASCII de 7 bits, ya que un archivo UTF-8 que contiene solo caracteres ASCII es idéntico a un archivo ASCII que contiene la misma secuencia de caracteres. Aún más importante, la compatibilidad hacia adelante está garantizada como software que reconoce sólo caracteres ASCII de 7 bits como especiales y no altera los bytes con el conjunto de bits más alto (como se hace a menudo para admitir extensiones ASCII de 8 bits como ISO-8859-1). conservará los datos UTF-8 sin cambios. [64]
^@ !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~Además, define códigos para 33 caracteres de control no imprimibles, en su mayoría obsoletos, que afectan la forma en que se procesa el texto.
Usar una función de "nueva línea" (retorno de carro y avance de línea combinados) es más sencillo tanto para el hombre como para la máquina que requerir ambas funciones para comenzar una nueva línea; el Estándar Nacional Estadounidense X3.4-1968 permite que el código de avance de línea lleve el significado de nueva línea.
Hubo el cambio de 1961 ASCII a 1968 ASCII. Algunos lenguajes informáticos utilizaban caracteres en ASCII de 1961, como la flecha hacia arriba y la flecha hacia la izquierda. Estos caracteres desaparecieron del ASCII de 1968. Trabajamos con Fred Mocking, que ahora estaba en Ventas en
Teletype
, en un cilindro tipográfico que comprometería los caracteres cambiantes para que los significados de 1961 ASCII no se perdieran por completo. El carácter de subrayado se hizo en forma de cuña para que también pudiera servir como flecha hacia la izquierda.