Ley de Zipf sobre la guerra y la paz . [1] El gráfico inferior muestra el resto cuando se elimina la ley de Zipf. Muestra que queda un patrón significativo que no se ajusta a la ley de Zipf.Gráfico de la frecuencia de cada palabra en función de su rango de frecuencia para dos textos en inglés: Culpeper 's Complete Herbal (1652) y HG Wells 's The War of the Worlds (1898) en una escala logarítmica . La línea de puntos es la ley ideal y ∝ 1/ x .
La ley de Zipf ( / z ɪ f / , alemán: [t͡sɪpf] ) es una ley empírica que establece que cuando una lista de valores medidos se ordena en orden decreciente, el valor de la entrada n es a menudo aproximadamente inversamente proporcional a n .
El ejemplo más conocido de la ley de Zipf se aplica a la tabla de frecuencias de palabras en un texto o corpus de lenguaje natural : se suele encontrar que la palabra más común aparece aproximadamente el doble de veces que la siguiente, el triple que la tercera más común, y así sucesivamente. Por ejemplo, en el Brown Corpus de textos en inglés americano, la palabra " the " es la palabra que aparece con más frecuencia y, por sí sola, representa casi el 7 % de todas las apariciones de palabras (69 971 de un poco más de 1 millón). Fiel a la ley de Zipf, la palabra que ocupa el segundo lugar, " of ", representa un poco más del 3,5 % de las palabras (36 411 apariciones), seguida de " and " (28 852). [2] A menudo se utiliza en la siguiente forma, llamada ley de Zipf-Mandelbrot : donde son parámetros ajustados, con , y . [1]
Algunos conjuntos de datos empíricos dependientes del tiempo se desvían un poco de la ley de Zipf. Se dice que estas distribuciones empíricas son cuasi-zipfianas .
Historia
En 1913, el físico alemán Felix Auerbach observó una proporcionalidad inversa entre el tamaño de la población de las ciudades y su clasificación cuando se ordenaban por orden decreciente de esa variable. [6]
La ley de Zipf fue descubierta antes que Zipf, [a] por el taquígrafo francés Jean-Baptiste Estoup ( Gammes Stenographiques , 4.ª ed.) en 1916, [7] por G. Dewey en 1923, [8] y por E. Condon en 1928. [9]
La misma relación para las frecuencias de las palabras en textos en lenguaje natural fue observada por George Zipf en 1932, [4] pero nunca afirmó haberla originado. De hecho, a Zipf no le gustaban las matemáticas. En su publicación de 1932, [10] el autor habla con desdén sobre la participación de las matemáticas en la lingüística, entre otras cosas, ibídem, p. 21: (…) permítanme decir aquí por el bien de cualquier matemático que pueda planear formular los datos resultantes con mayor exactitud, la capacidad del positivo altamente intenso de convertirse en el negativo altamente intenso, en mi opinión, introduce el diablo en la fórmula en la forma de . La única expresión matemática que Zipf usó parece ser a . b 2 = constante, que "tomó prestada" de la publicación de Alfred J. Lotka de 1926. [11]
Se encontró que la misma relación ocurre en muchos otros contextos y para otras variables además de la frecuencia. [1] Por ejemplo, cuando las corporaciones se clasifican por tamaño decreciente, se encuentra que sus tamaños son inversamente proporcionales al rango. [12] La misma relación se encuentra para los ingresos personales (donde se llama principio de Pareto [13] ), el número de personas que ven el mismo canal de televisión, [14] las notas en la música, [15] los transcriptomas de las células , [16] [17] y más.
En 1992, el bioinformático Wentian Li publicó un breve artículo [18] que demostraba que la ley de Zipf surge incluso en textos generados aleatoriamente. Incluía pruebas de que la forma de ley de potencia de la ley de Zipf era un subproducto de ordenar las palabras por rango.
Definición formal
Formalmente, la distribución Zipf sobre N elementos asigna al elemento de rango k (contando desde 1) la probabilidad
donde H N es una constante de normalización, el N -ésimo número armónico :
La distribución a veces se generaliza a una ley de potencia inversa con exponente s en lugar de 1. [19] Es decir,
La distribución Zipf generalizada se puede extender a un número infinito de elementos ( N = ∞) solo si el exponente s supera 1. En ese caso, la constante de normalización H N , s se convierte en la función zeta de Riemann ,
El caso de elementos infinitos se caracteriza por la distribución Zeta y se denomina ley de Lotka . Si el exponente s es 1 o menor, la constante de normalización H N , s diverge cuando N tiende al infinito.
Pruebas empíricas
Empíricamente, se puede probar un conjunto de datos para ver si se aplica la ley de Zipf verificando la bondad de ajuste de una distribución empírica a la distribución de ley de potencia hipotética con una prueba de Kolmogorov-Smirnov y luego comparando la razón de verosimilitud (logaritmo) de la distribución de ley de potencia con distribuciones alternativas como una distribución exponencial o una distribución lognormal. [20]
La ley de Zipf se puede visualizar trazando los datos de frecuencia de los ítems en un gráfico logarítmico , con los ejes siendo el logaritmo del orden de rango y el logaritmo de la frecuencia. Los datos se ajustan a la ley de Zipf con exponente s en la medida en que el gráfico se aproxima a una función lineal (más precisamente, afín ) con pendiente − s . Para el exponente s = 1, también se puede trazar el recíproco de la frecuencia (intervalo medio entre palabras) contra el rango, o el recíproco del rango contra la frecuencia, y comparar el resultado con la línea que pasa por el origen con pendiente 1. [3]
Explicaciones estadísticas
Aunque la Ley de Zipf se cumple para la mayoría de las lenguas naturales, e incluso para algunas no naturales como el esperanto [21] y el toki pona [22] , la razón aún no se entiende bien. [23] Las revisiones recientes de los procesos generativos para la ley de Zipf incluyen a Mitzenmacher , "A Brief History of Generative Models for Power Law and Lognormal Distributions", [24] y Simkin, "Re-inventing Willis". [25]
Sin embargo, esto puede explicarse en parte mediante el análisis estadístico de textos generados aleatoriamente. Wentian Li ha demostrado que en un documento en el que cada carácter ha sido elegido aleatoriamente de una distribución uniforme de todas las letras (más un carácter de espacio), las "palabras" con diferentes longitudes siguen la macrotendencia de la ley de Zipf (las palabras más probables son las más cortas y tienen la misma probabilidad). [26] En 1959, Vitold Belevitch observó que si cualquiera de una gran clase de distribuciones estadísticas de buen comportamiento (no solo la distribución normal ) se expresa en términos de rango y se expande en una serie de Taylor , el truncamiento de primer orden de la serie da como resultado la ley de Zipf. Además, un truncamiento de segundo orden de la serie de Taylor dio como resultado la ley de Mandelbrot . [27] [28]
El principio del mínimo esfuerzo es otra explicación posible: el propio Zipf propuso que ni los hablantes ni los oyentes que utilizan una lengua determinada quieren trabajar más de lo necesario para alcanzar la comprensión, y el proceso que resulta en una distribución aproximadamente igual del esfuerzo conduce a la distribución Zipf observada. [5] [29]
Una explicación mínima supone que las palabras son generadas por monos que escriben al azar . Si el lenguaje es generado por un solo mono que escribe al azar, con una probabilidad fija y distinta de cero de pulsar cada tecla de letra o espacio en blanco, entonces las palabras (cadenas de letras separadas por espacios en blanco) producidas por el mono siguen la ley de Zipf. [30]
Otra posible causa de la distribución Zipf es un proceso de apego preferencial , en el que el valor x de un elemento tiende a crecer a una tasa proporcional a x (intuitivamente, " los ricos se hacen más ricos " o "el éxito genera éxito"). Este proceso de crecimiento da como resultado la distribución Yule-Simon , que se ha demostrado que se ajusta a la frecuencia de palabras versus el rango en el lenguaje [31] y a la población versus el rango de la ciudad [32] mejor que la ley de Zipf. Originalmente fue derivada para explicar la población versus el rango en las especies por Yule, y aplicada a las ciudades por Simon.
Una explicación similar se basa en los modelos Atlas, sistemas de procesos de difusión de valor positivo intercambiables con parámetros de deriva y varianza que dependen únicamente del rango del proceso. Se ha demostrado matemáticamente que la ley de Zipf se cumple para los modelos Atlas que satisfacen ciertas condiciones de regularidad natural. [33] [34]
En la distribución fractal parabólica , el logaritmo de la frecuencia es un polinomio cuadrático del logaritmo del rango. Esto puede mejorar notablemente el ajuste en una relación de ley de potencia simple. [36] Al igual que la dimensión fractal, es posible calcular la dimensión Zipf, que es un parámetro útil en el análisis de textos. [37]
Se ha argumentado que la ley de Benford es un caso acotado especial de la ley de Zipf, [36] y que la conexión entre estas dos leyes se explica por el hecho de que ambas se originan a partir de relaciones funcionales invariantes de escala de la física estadística y de fenómenos críticos. [38] Las razones de probabilidades en la ley de Benford no son constantes. Los dígitos iniciales de los datos que satisfacen la ley de Zipf con s = 1 satisfacen la ley de Benford.
Ocurrencias
Tamaños de las ciudades
Tras la observación de Auerbach en 1913, se han realizado estudios sustanciales sobre la ley de Zipf para el tamaño de las ciudades. [39] Sin embargo, estudios empíricos [40] [41] y teóricos [42] más recientes han cuestionado la relevancia de la ley de Zipf para las ciudades.
Frecuencias de palabras en lenguajes naturales
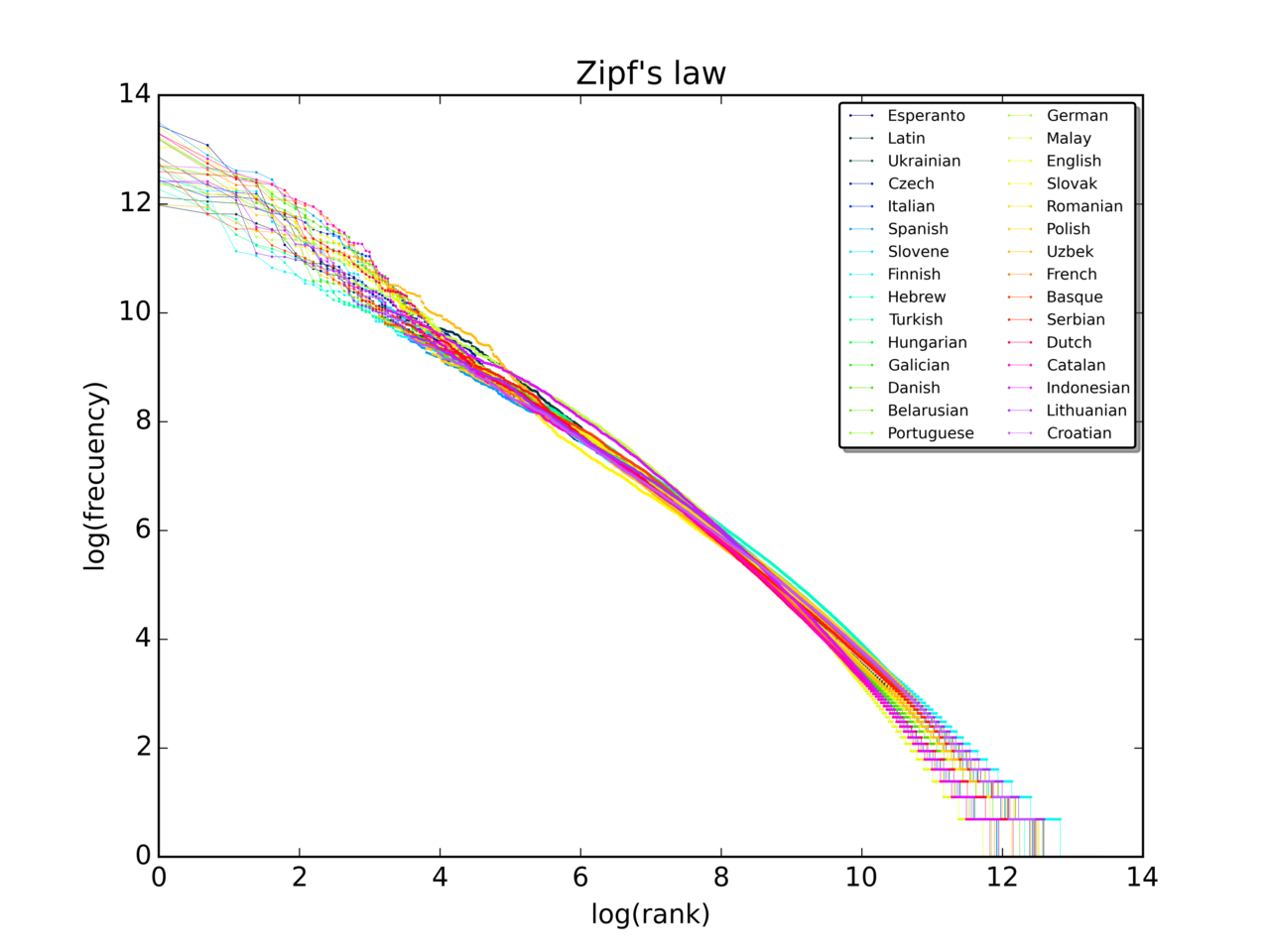
Gráfico de la ley de Zipf para los primeros 10 millones de palabras en 30 Wikipedias (a octubre de 2015) en una escala logarítmica
En muchos textos en idiomas humanos, las frecuencias de las palabras siguen aproximadamente una distribución Zipf con exponentes cercanos a 1: es decir, la palabra más común aparece aproximadamente n veces la n -ésima palabra más común.
La gráfica de rango-frecuencia real de un texto en lenguaje natural se desvía en cierta medida de la distribución Zipf ideal, especialmente en los dos extremos del rango. Las desviaciones pueden depender del idioma, del tema del texto, del autor, de si el texto fue traducido de otro idioma y de las reglas ortográficas utilizadas. [ cita requerida ] Es inevitable que haya alguna desviación debido a errores de muestreo .
En el extremo de baja frecuencia, donde el rango se acerca a N , la gráfica toma forma de escalera, porque cada palabra puede aparecer solo un número entero de veces.
Gráficos de la ley de Zipf para varios idiomas
Textos en alemán (1669), ruso (1972), francés (1865), italiano (1840) e inglés medieval (1460)
Un gráfico logarítmico de la frecuencia de palabras en Wikipedia (27 de noviembre de 2006). 'Las palabras más populares son "the", "of" y "and", como se esperaba. La ley de Zipf corresponde a la porción lineal media de la curva, que sigue aproximadamente la línea verde (1/ x ), mientras que la parte inicial está más cerca de la línea magenta (1/ x 0,5 ) mientras que la parte posterior está más cerca de la línea cian (1/( k + x ) 2,0 ). Estas líneas corresponden a tres parametrizaciones distintas de la distribución de Zipf-Mandelbrot, en general una ley de potencia rota con tres segmentos: una cabeza, un medio y una cola.
En algunas lenguas romances , las frecuencias de aproximadamente una docena de palabras más frecuentes se desvían significativamente de la distribución Zipf ideal, debido a que esas palabras incluyen artículos flexionados por género y número gramaticales . [ cita requerida ]
En muchos idiomas del este de Asia , como el chino , el tibetano de Lhasa y el vietnamita , cada "palabra" consta de una sola sílaba ; una palabra en inglés suele traducirse como un compuesto de dos sílabas de este tipo. La tabla de frecuencia de rangos para esas "palabras" se desvía significativamente de la ley de Zipf ideal, en ambos extremos del rango. [ cita requerida ]
Incluso en inglés, las desviaciones de la ley de Zipf ideal se hacen más evidentes cuando se examinan grandes colecciones de textos. El análisis de un corpus de 30.000 textos en inglés mostró que sólo alrededor del 15% de los textos incluidos en él se ajustan bien a la ley de Zipf. Pequeños cambios en la definición de la ley de Zipf pueden aumentar este porcentaje hasta cerca del 50%. [43]
En estos casos, la relación frecuencia-rango observada se puede modelar con mayor precisión mediante distribuciones separadas de las leyes de Zipf-Mandelbrot para diferentes subconjuntos o subtipos de palabras. Este es el caso del gráfico de frecuencia-rango de los primeros 10 millones de palabras de la Wikipedia en inglés. En particular, las frecuencias de la clase cerrada de palabras funcionales en inglés se describen mejor con s menor que 1, mientras que el crecimiento del vocabulario abierto con el tamaño del documento y el tamaño del corpus requiere s mayor que 1 para la convergencia de la Serie Armónica Generalizada . [3]
Cuando un texto está cifrado de tal manera que cada ocurrencia de cada palabra distinta del texto simple siempre se asigna a la misma palabra cifrada (como en el caso de los cifrados de sustitución simple , como los cifrados César o los cifrados de libro de códigos simple ), la distribución de rango de frecuencia no se ve afectada. Por otro lado, si ocurrencias separadas de la misma palabra se pueden asignar a dos o más palabras diferentes (como sucede con el cifrado Vigenère ), la distribución Zipf normalmente tendrá una parte plana en el extremo de alta frecuencia. [ cita requerida ]
La distribución de palabras por rango de frecuencia suele ser característica del autor y cambia poco con el tiempo. Esta característica se ha utilizado en el análisis de textos para la atribución de autoría. [47] [48]
Se ha descubierto que los grupos de signos con forma de palabra del códice del Manuscrito Voynich del siglo XV satisfacen la ley de Zipf, lo que sugiere que es muy probable que el texto no sea un engaño, sino que esté escrito en un lenguaje o código oscuro. [49] [50]
Véase también
Regla del 1% (cultura de Internet) : hipótesis de que habrá más personas que se alojen en una comunidad virtual que las que participen.Pages displaying short descriptions of redirect targets
Ley de Benford : Observación de que en muchos conjuntos de datos de la vida real, es probable que el dígito inicial sea pequeño
Ley de Bradford – Patrón de referencias en revistas científicas
^ abc Piantadosi, Steven (25 de marzo de 2014). "Ley de frecuencia de palabras de Zipf en lenguaje natural: una revisión crítica y direcciones futuras". Psychon Bull Rev . 21 (5): 1112–1130. doi :10.3758/s13423-014-0585-6. PMC 4176592 . PMID 24664880.
^ Fagan, Stephen; Gençay, Ramazan (2010), "Introducción a la econometría textual", en Ullah, Aman; Giles, David EA (eds.), Handbook of Empirical Economics and Finance , CRC Press, págs. 133-153, ISBN9781420070361. P. 139: "Por ejemplo, en el Corpus Brown, que consta de más de un millón de palabras, la mitad del volumen de palabras consiste en usos repetidos de sólo 135 palabras".
^ abc Powers, David MW (1998). Aplicaciones y explicaciones de la ley de Zipf. Conferencia conjunta sobre nuevos métodos en el procesamiento del lenguaje y el aprendizaje computacional del lenguaje natural. Association for Computational Linguistics. pp. 151–160. Archivado desde el original el 10 de septiembre de 2015. Consultado el 2 de febrero de 2015 .
^ de George K. Zipf (1935): La psicobiología del lenguaje . Houghton-Mifflin.
^ abc George K. Zipf (1949). El comportamiento humano y el principio del mínimo esfuerzo. Cambridge, Massachusetts: Addison-Wesley. pág. 1.
^ Auerbach F. (1913) Das Gesetz der Bevölkerungskonzentration. Geographische Mitteilungen de Petermann 59, 74–76
^ Christopher D. Manning, Hinrich Schütze Fundamentos del procesamiento estadístico del lenguaje natural , MIT Press (1999), ISBN 978-0-262-13360-9 , pág. 24
^ Dewey, Godfrey. Frecuencia relativa de los sonidos del habla inglesa . Harvard University Press, 1923.
^ Condon, EDWARD U. "Estadísticas del vocabulario". Science 67.1733 (1928): 300-300.
^ George K. Zipf (1932): Estudios selectos sobre el principio de frecuencia relativa en el lenguaje. Harvard, MA: Harvard University Press.
^ Zipf, George Kingsley (1942). "La unidad de la naturaleza, la acción mínima y las ciencias sociales naturales". Sociometría . 5 (1): 48–62. doi :10.2307/2784953. ISSN 0038-0431. JSTOR 2784953. Archivado desde el original el 20 de noviembre de 2022 . Consultado el 20 de noviembre de 2022 .
^ Axtell, Robert L (2001): Distribución Zipf del tamaño de las empresas estadounidenses Archivado el 17 de octubre de 2023 en Wayback Machine , Science, 293, 5536, 1818, Asociación Estadounidense para el Avance de la Ciencia.
^ Sandmo, Agnar (1 de enero de 2015), Atkinson, Anthony B.; Bourguignon, François (eds.), Capítulo 1 - El problema principal de la economía política: la distribución del ingreso en la historia del pensamiento económico, Manual de distribución del ingreso, vol. 2, Elsevier, págs. 3-65, doi :10.1016/B978-0-444-59428-0.00002-3, ISBN978-0-444-59430-3, archivado desde el original el 29 de octubre de 2023 , consultado el 11 de julio de 2023
^ M. Eriksson, SM Hasibur Rahman, F. Fraille, M. Sjöström, Efficient Interactive Multicast over DVB-T2 - Utilizing Dynamic SFNs and PARPS Archivado el 2 de mayo de 2014 en Wayback Machine , Conferencia internacional IEEE sobre informática y tecnología de la información de 2013 (BMSB'13), Londres, Reino Unido, junio de 2013. Sugiere un modelo de selección de canal de TV de ley Zipf heterogéneo
^ Zanette, Damián H. (7 de junio de 2004). "La ley de Zipf y la creación del contexto musical". arXiv : cs/0406015 .
^ Lazzardi, Silvia; Valle, Filippo; Mazzolini, Andrea; Scialdone, Antonio; Caselle, Michele; Osella, Matteo (17 de junio de 2021). "Leyes estadísticas emergentes en datos transcriptómicos unicelulares". bioRxiv : 2021–16.06.448706. doi :10.1101/2021.06.16.448706. S2CID 235482777. Archivado desde el original el 17 de junio de 2021 . Consultado el 18 de junio de 2021 .
^ Ramu Chenna, Toby Gibson; Evaluación de la idoneidad de un modelo de brecha zipfiana para la alineación de secuencias por pares Archivado el 6 de marzo de 2014 en Wayback Machine , Conferencia internacional sobre biología computacional bioinformática: 2011.
^ Li, Wentian (1992). "Los textos aleatorios presentan una distribución de frecuencia de palabras similar a la de la ley de Zipf". IEEE Transactions on Information Theory . 38 (6): 1842–1845. doi :10.1109/18.165464 – vía IEEE Xplore.
^ ab Adamic, Lada A. (2000). Zipf, leyes de potencia y Pareto: un tutorial de clasificación (Informe). Hewlett-Packard Company. Archivado desde el original el 2023-04-01 . Consultado el 2023-10-12 . "publicado originalmente". www.parc.xerox.com . Xerox Corporation . Archivado desde el original el 2001-11-07 . Consultado el 2016-02-23 .
^ Clauset, A., Shalizi, CR y Newman, MEJ (2009). Distribuciones de ley de potencia en datos empíricos. SIAM Review, 51(4), 661–703. doi :10.1137/070710111
^ Bill Manaris; Luca Pellicoro; George Pothering; Harland Hodges (13 de febrero de 2006). Investigación de las proporciones estadísticas del esperanto en relación con otras lenguas utilizando redes neuronales y la ley de Zipf (PDF) . Inteligencia artificial y aplicaciones . Innsbruck, Austria. pp. 102–108. Archivado desde el original (PDF) el 5 de marzo de 2016.
^ Skotarek, Dariusz (2020). Ley de Zipf en Toki Pona (PDF) . Sociedad ExLing. doi : 10.36505/ExLing-2020/11/0047/000462. ISBN978-618-84585-1-2.
^ Léon Brillouin , La science et la théorie de l'information , 1959, réédité en 1988, traducción inglesa rééditée en 2004
^ Mitzenmacher, Michael (enero de 2004). "Una breve historia de los modelos generativos para la ley de potencia y las distribuciones lognormales". Internet Mathematics . 1 (2): 226–251. doi : 10.1080/15427951.2004.10129088 . ISSN 1542-7951. S2CID 1671059. Archivado desde el original el 22 de julio de 2023 . Consultado el 25 de julio de 2023 .
^ Simkin, MV; Roychowdhury, VP (1 de mayo de 2011). "Re-inventando a Willis". Physics Reports . 502 (1): 1–35. arXiv : physics/0601192 . Bibcode :2011PhR...502....1S. doi :10.1016/j.physrep.2010.12.004. ISSN 0370-1573. S2CID 88517297. Archivado desde el original el 29 de enero de 2012 . Consultado el 25 de julio de 2023 .
^ Wentian Li (1992). "Los textos aleatorios presentan una distribución de frecuencia de palabras similar a la de la ley de Zipf". IEEE Transactions on Information Theory . 38 (6): 1842–1845. CiteSeerX 10.1.1.164.8422 . doi :10.1109/18.165464.
↑ Belevitch V (18 de diciembre de 1959). «Sobre las leyes estadísticas de las distribuciones lingüísticas» (PDF) . Annales de la Société Scientifique de Bruxelles . 73 : 310–326. Archivado (PDF) desde el original el 15 de diciembre de 2020. Consultado el 24 de abril de 2020 .
^ Neumann, Peter G. "Metalingüística estadística y Zipf/Pareto/Mandelbrot", SRI International Computer Science Laboratory , consultado y archivado el 29 de mayo de 2011.
^ Conrad, B.; Mitzenmacher, M. (julio de 2004). "Leyes de potencia para monos que escriben al azar: el caso de probabilidades desiguales". IEEE Transactions on Information Theory . 50 (7): 1403–1414. doi :10.1109/TIT.2004.830752. ISSN 1557-9654. S2CID 8913575. Archivado desde el original el 17 de octubre de 2022 . Consultado el 20 de agosto de 2023 .
^ Lin, Ruokuang; Ma, Qianli DY; Bian, Chunhua (2014). "Leyes de escala en el habla humana, disminución de la aparición de nuevas palabras y un modelo generalizado". arXiv : 1412.4846 [cs.CL].
^ Vitanov, Nikolay K.; Ausloos, Marcel; Bian, Chunhua (2015). "Prueba de dos hipótesis que explican el tamaño de las poblaciones en un sistema de ciudades". Journal of Applied Statistics . 42 (12): 2686–2693. arXiv : 1506.08535 . Bibcode :2015JApSt..42.2686V. doi :10.1080/02664763.2015.1047744. S2CID 10599428.
^ Ricardo T. Fernholz; Robert Fernholz (diciembre de 2020). «Ley de Zipf para modelos atlas». Journal of Applied Probability . 57 (4): 1276–1297. doi :10.1017/jpr.2020.64. S2CID 146808080. Archivado desde el original el 29 de enero de 2021 . Consultado el 26 de marzo de 2021 .
^ Terence Tao (2012). "E Pluribus Unum: De la complejidad a la universalidad". Daedalus . 141 (3): 23–34. doi : 10.1162/DAED_a_00158 . S2CID 14535989. Archivado desde el original el 2021-08-05 . Consultado el 2021-03-26 .
^ NL Johnson; S. Kotz y AW Kemp (1992). Distribuciones discretas univariadas (segunda edición). Nueva York: John Wiley & Sons, Inc. ISBN978-0-471-54897-3., pág. 466.
^ por Johan Gerard van der Galien (8 de noviembre de 2003). «Aleatoriedad factorial: las leyes de Benford y Zipf con respecto a la distribución del primer dígito de la secuencia de factores de los números naturales». Archivado desde el original el 5 de marzo de 2007. Consultado el 8 de julio de 2016 .
^ Eftekhari, Ali (2006). "Geometría fractal de textos: una aplicación inicial a las obras de Shakespeare". Revista de lingüística cuantitativa . 13 (2–3): 177–193. doi :10.1080/09296170600850106. S2CID 17657731.
^ Pietronero, L.; Tosatti, E.; Tosatti, V.; Vespignani, A. (2001). "Explicación de la distribución desigual de números en la naturaleza: las leyes de Benford y Zipf". Physica A . 293 (1–2): 297–304. arXiv : cond-mat/9808305 . Código Bibliográfico :2001PhyA..293..297P. doi :10.1016/S0378-4371(00)00633-6.
^ Gabaix, Xavier (1999). "Ley de Zipf para ciudades: una explicación". The Quarterly Journal of Economics . 114 (3): 739–767. doi :10.1162/003355399556133. ISSN 0033-5533. JSTOR 2586883. Archivado desde el original el 2021-10-26 . Consultado el 2021-10-26 .
^ Arshad, Sidra; Hu, Shougeng; Ashraf, Badar Nadeem (15 de febrero de 2018). "Ley de Zipf y distribución del tamaño de las ciudades: un estudio de la literatura y la agenda de investigación futura". Physica A: Mecánica estadística y sus aplicaciones . 492 : 75–92. Bibcode :2018PhyA..492...75A. doi :10.1016/j.physa.2017.10.005. ISSN 0378-4371. Archivado desde el original el 29 de octubre de 2023 . Consultado el 26 de octubre de 2021 .
^ Gan, Li; Li, Dong; Song, Shunfeng (1 de agosto de 2006). "¿Es espuria la ley de Zipf al explicar las distribuciones de tamaño de las ciudades?". Economics Letters . 92 (2): 256–262. doi :10.1016/j.econlet.2006.03.004. ISSN 0165-1765. Archivado desde el original el 13 de abril de 2019 . Consultado el 26 de octubre de 2021 .
^ Verbavatz, Vincent; Barthelemy, Marc (noviembre de 2020). «La ecuación de crecimiento de las ciudades». Nature . 587 (7834): 397–401. arXiv : 2011.09403 . Código Bibliográfico :2020Natur.587..397V. doi :10.1038/s41586-020-2900-x. ISSN 1476-4687. PMID 33208958. S2CID 227012701. Archivado desde el original el 29 de octubre de 2021 . Consultado el 26 de octubre de 2021 .
^ Moreno-Sánchez, I.; Font-Clos, F.; Corral, A. (2016). "Análisis a gran escala de la Ley de Zipf en textos ingleses". PLOS ONE . 11 (1): e0147073. arXiv : 1509.04486 . Bibcode :2016PLoSO..1147073M. doi : 10.1371/journal.pone.0147073 . PMC 4723055 . PMID 26800025.
^ Mohammadi, Mehdi (2016). "Identificación paralela de documentos mediante la ley de Zipf" (PDF) . Actas del Noveno taller sobre construcción y uso de corpus comparables . LREC 2016. Portorož, Eslovenia. págs. 21–25. Archivado (PDF) desde el original el 23 de marzo de 2018.
^ Doyle, Laurance R. (18 de noviembre de 2016). «Por qué el lenguaje extraterrestre se destacaría entre todo el ruido del universo». Nautilus Quarterly . Archivado desde el original el 29 de julio de 2020. Consultado el 30 de agosto de 2020 .
^ Frans J. Van Droogenbroeck (2016): Manejo de la distribución Zipf en la atribución de autoría computarizada Archivado el 4 de octubre de 2023 en Wayback Machine
^ Frans J. Van Droogenbroeck (2019): Una reformulación esencial de la ley de Zipf-Mandelbrot para resolver aplicaciones de atribución de autoría mediante estadísticas gaussianas Archivado el 30 de septiembre de 2023 en Wayback Machine.
^ Boyle, Rebecca. «Los patrones similares al lenguaje del texto misterioso pueden ser un engaño elaborado». New Scientist . Archivado desde el original el 18 de mayo de 2022. Consultado el 25 de febrero de 2022 .
^ Montemurro, Marcelo A.; Zanette, Damián H. (2013-06-21). "Palabras clave y patrones de co-ocurrencia en el manuscrito Voynich: un análisis de la teoría de la información". PLOS ONE . 8 (6): e66344. Bibcode :2013PLoSO...866344M. doi : 10.1371/journal.pone.0066344 . ISSN 1932-6203. PMC 3689824 . PMID 23805215.
Lectura adicional
Alexander Gelbukh y Grigori Sidorov (2001) "Los coeficientes de las leyes de Zipf y Heaps dependen del lenguaje". Proc. CICLing -2001, Conferencia sobre procesamiento inteligente de textos y lingüística computacional , 18-24 de febrero de 2001, Ciudad de México. Lecture Notes in Computer Science N 2004, ISSN 0302-9743, ISBN 3-540-41687-0 , Springer-Verlag: 332-335.
Kali R. (2003) "La ciudad como un componente gigante: un enfoque de gráfico aleatorio para la ley de Zipf", Applied Economics Letters 10 : 717–720(4)
Shyklo A. (2017); Explicación simple del misterio de Zipf a través de una nueva distribución de reparto de rango, derivada de la combinatoria del proceso de clasificación, disponible en SSRN: https://ssrn.com/abstract=2918642.
Clara Moskowitz , Jen Christiansen y Ni-Ka Ford, "Cells by Count and Size: The largest a cell type is, the rare it is in the body – and vice versa", Scientific American , vol. 330, no. 1 (enero de 2024), pp. 94-95. "'A medida que se duplica el volumen de una célula, la frecuencia de células de ese tamaño se reduce a la mitad'", descubrió el ecólogo Ian A. Hatton de la Universidad McGill y sus colegas investigadores de la ley de Zipf, dice Hatton. " Los glóbulos rojos diminutos y no nucleados son, con mucho, las células más comunes en nuestros cuerpos, mientras que las células musculares comparativamente gigantescas en nuestros brazos y piernas son las más escasas. Poder usar el tamaño de una célula para estimar su frecuencia en el cuerpo podría ayudar a los médicos a comprender mejor ciertos sistemas corporales y tipos de células difíciles de contar... El estudio sugiere, por ejemplo, que las células inmunes llamadas linfocitos son mucho más comunes de lo que los biólogos creían". (pág. 94.)
Wikimedia Commons tiene medios relacionados con Ley de Zipf .
Strogatz, Steven (2009-05-29). "Columna invitada: Matemáticas y la ciudad". The New York Times . Archivado desde el original el 2015-09-27 . Consultado el 2009-05-29 .—Un artículo sobre la ley de Zipf aplicada a las poblaciones urbanas
Ver alrededor de las esquinas (Las sociedades artificiales hacen surgir la ley de Zipf)
Artículo de PlanetMath sobre la ley de Zipf
Distribuciones de tipo "fractal parabolique" en la naturaleza (en francés, con resumen en inglés) Archivado el 24 de octubre de 2004 en Wayback Machine
Un análisis de la distribución del ingreso
Lista Zipf de palabras en francés Archivado el 23 de junio de 2007 en Wayback Machine.
Lista Zipf para inglés, francés, español, italiano, sueco, islandés, latín, portugués y finlandés del Proyecto Gutenberg y calculadora en línea para clasificar palabras en textos Archivado el 8 de abril de 2011 en Wayback Machine
Citas y la ley de Zipf-Mandelbrot
Ejemplos y modelos de la ley de Zipf (1985)
Sistemas complejos: descifrando la ley de Zipf (2011)
Ley de Benford, ley de Zipf y la distribución de Pareto de Terence Tao.



_and_Portuguese_(Dom_Casmurro).svg/1280px-Zipf-euro-3_Spanish_(Don_Quixote)_and_Portuguese_(Dom_Casmurro).svg.png)





















![{\displaystyle f(k;\rho )\approx {\frac {[{\text{constante}}]}{k^{\rho +1}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/78fb2a5a8523f03c5e11716e40fd9627c18ff49f)