La frecuencia de las letras es el número de veces que aparecen en promedio las letras del alfabeto en el lenguaje escrito . El análisis de frecuencia de letras se remonta al matemático árabe Al-Kindi ( c. 801 –873 d.C.), quien desarrolló formalmente el método para descifrar cifrados . El análisis de la frecuencia de las letras ganó importancia en Europa con el desarrollo de los tipos móviles en 1450 d.C., donde se debe estimar la cantidad de tipografía necesaria para cada forma de letra . Los lingüistas utilizan el análisis de frecuencia de letras como una técnica rudimentaria para la identificación de idiomas , donde es particularmente eficaz como indicación de si un sistema de escritura desconocido es alfabético, silábico o ideográfico .
El uso de frecuencias de letras y el análisis de frecuencias juega un papel fundamental en los criptogramas y en varios juegos de rompecabezas de palabras, incluidos Hangman , Scrabble , Wordle [2] y el programa de televisión Wheel of Fortune . Una de las primeras descripciones en la literatura clásica sobre la aplicación del conocimiento de la frecuencia de las letras en inglés para resolver un criptograma se encuentra en la famosa historia de Edgar Allan Poe The Gold-Bug , donde el método se aplica con éxito para descifrar un mensaje que proporciona la ubicación de un Tesoro escondido por el Capitán Kidd . [3] [ cita necesaria ]
Herbert S. Zim , en su clásico texto introductorio a la criptografía "Códigos y escritura secreta", proporciona la secuencia de frecuencia de letras en inglés como " ETAON RISHD LFCMU GYPWB VKJXZQ ", los pares de letras más comunes como "TH HE AN RE ER IN ON AT ND ST ES EN OF TE ED OR TI HI AS TO", y las letras duplicadas más comunes como "LL EE SS OO TT FF RR NN PP CC". [4] Diferentes formas de contar pueden producir órdenes algo diferentes.
Las frecuencias de las letras también tienen un fuerte efecto en el diseño de algunas distribuciones de teclado . Las letras más frecuentes se colocan en la fila de inicio de la máquina de escribir Blickensderfer , el diseño del teclado Dvorak , Colemak y otros diseños optimizados.

La frecuencia de las letras en el texto se ha estudiado para su uso en criptoanálisis , y en el análisis de frecuencia en particular, y se remonta al matemático árabe al-Kindi (c. 801-873 d. C.), quien desarrolló formalmente el método (las cifras descifrables mediante esta técnica). retroceda al menos al cifrado César inventado por Julio César [ cita necesaria ] , por lo que este método podría haber sido explorado en la época clásica). El análisis de la frecuencia de las letras ganó importancia adicional en Europa con el desarrollo de los tipos móviles en 1450 d.C., donde se debe estimar la cantidad de tipo requerido para cada forma de letra, como lo demuestran las variaciones en el tamaño del compartimento de las letras en los estuches tipográficos del tipógrafo.
No existe una distribución exacta de la frecuencia de las letras en un idioma determinado, ya que todos los escritores escriben de manera ligeramente diferente. Sin embargo, la mayoría de las lenguas tienen una distribución característica que se hace muy evidente en los textos más extensos. Incluso cambios de idioma tan extremos como del inglés antiguo al inglés moderno (considerados mutuamente ininteligibles) muestran fuertes tendencias en las frecuencias de letras relacionadas: en una pequeña muestra de pasajes bíblicos, del más frecuente al menos frecuente, enaid sorhm tgþlwu æcfy ðbpxz del inglés antiguo compara a eotha sinrd luymw fgcbp kvjqxz del inglés moderno, y no se comparten las diferencias más extremas en cuanto a las formas de las letras. [5]
Las máquinas de linotipo para el idioma inglés asumieron que el orden de las letras, de mayor a menor común, era etaoin shrdlu cmfwyp vbgkjq xz según la experiencia y costumbre de los compositores manuales. El equivalente para el idioma francés era elaoin sdrétu cmfhyp vbgwqj xz .
Al organizar el alfabeto en Morse en grupos de letras que requieren cantidades iguales de tiempo para transmitirse y luego clasificar estos grupos en orden creciente, se obtiene e it san hurdm wgvlfbk opxcz jyq . [a] La frecuencia de las letras fue utilizada por otros sistemas telegráficos, como el Código Murray .
Se utilizan ideas similares en técnicas modernas de compresión de datos , como la codificación Huffman .
Las frecuencias de las letras, al igual que las frecuencias de las palabras , tienden a variar, tanto según el escritor como el tema. Por ejemplo, ⟨d⟩ ocurre con mayor frecuencia en la ficción, ya que la mayor parte de la ficción está escrita en tiempo pasado y, por lo tanto, la mayoría de los verbos terminarán en el sufijo flexivo -ed / -d . No se puede escribir un ensayo sobre rayos X sin utilizar ⟨x⟩ con frecuencia. Diferentes autores tienen hábitos que pueden reflejarse en el uso de las letras. El estilo de escritura de Hemingway , por ejemplo, es visiblemente diferente del de Faulkner . Las letras, bigramas , trigramas , frecuencias de palabras, longitud de palabras y longitud de oraciones se pueden calcular para autores específicos y usarse para probar o refutar la autoría de textos, incluso para autores cuyos estilos no son tan divergentes.
Las frecuencias promedio exactas de las letras solo se pueden obtener analizando una gran cantidad de texto representativo. Con la disponibilidad de informática moderna y colecciones de grandes corpus de texto , estos cálculos se realizan fácilmente. Se pueden extraer ejemplos de una variedad de fuentes (reportajes de prensa, textos religiosos, textos científicos y ficción en general) y existen diferencias, especialmente para la ficción general, con la posición de ⟨h⟩ y ⟨i⟩ , siendo ⟨h⟩ cada vez más común.
Además, tenga en cuenta que los diferentes dialectos de un idioma también afectarán la frecuencia de una letra. Por ejemplo, un autor en los Estados Unidos produciría algo en el que ⟨z⟩ sea más común que un autor en el Reino Unido que escriba sobre el mismo tema: palabras como "analizar", "disculparse" y "reconocer" contienen la letra en inglés americano, mientras que las mismas palabras se escriben "analyse", "apologise" y "recognise" en inglés británico. Esto afectaría en gran medida la frecuencia de la letra ⟨z⟩ , ya que es una letra que los hablantes británicos rara vez utilizan en el idioma inglés. [6]
Las "doce letras principales" constituyen aproximadamente el 80% del uso total. Las "ocho primeras" letras constituyen aproximadamente el 65% del uso total. La frecuencia de las letras como función del rango puede adaptarse bien a varias funciones de rango, siendo la mejor la función de rango Cocho/Beta de dos parámetros. [7] Otra función de rango sin parámetro libre ajustable también se ajusta razonablemente bien a la distribución de frecuencia de letras [8] (la misma función se ha utilizado para ajustar la frecuencia de aminoácidos en secuencias de proteínas. [9] ) Un espía que usa el cifrado VIC o algún otro cifrado basado en un tablero de ajedrez a caballo normalmente usa una mnemónica como "un pecado para errar" (eliminando la segunda "r") [10] [11] o "a la vez, señor" [12] para recordar los ocho caracteres principales.

Hay tres formas de contar la frecuencia de las letras que dan como resultado gráficos muy diferentes para las letras comunes. El primer método, utilizado en el cuadro siguiente, consiste en contar la frecuencia de las letras en las raíces de las palabras de un diccionario. La segunda es incluir todas las variantes de palabras al contar, como "abstracts", "abstracted" y "abstracting", y no sólo la raíz de "abstract". Este sistema hace que letras como ⟨s⟩ aparezcan con mucha más frecuencia, como cuando se cuentan letras de listas de las palabras en inglés más utilizadas en Internet. Una última variante es contar las letras según su frecuencia de uso en los textos reales, lo que hace que ciertas combinaciones de letras como ⟨th⟩ se vuelvan más comunes debido al uso frecuente de palabras comunes como "the", "then", "both", "esto", etc. Las medidas de frecuencia de uso absoluta como esta se utilizan al crear diseños de teclado o frecuencias de letras en imprentas antiguas.
Un análisis de las entradas del diccionario Concise Oxford, ignorando la frecuencia de uso de las palabras, da un orden de "EARIOTNSLCUDPMHGBFYWKVXZJQ". [13]
La siguiente tabla de frecuencia de letras está tomada del sitio web de Pavel Mička, que cita Cryptoological Mathematics de Robert Lewand . [14]
Según Lewand, ordenadas de apariencia más a menos común, las letras son: etaoinshrdlcumwfgypbvkjxqz . El orden de Lewand difiere ligeramente de otros, como el Proyecto Math Explorer de la Universidad de Cornell, que produjo una tabla después de medir 40.000 palabras. [15]
En inglés, el carácter de espacio aparece casi el doble de frecuente que la letra superior ( ⟨e⟩ ) [16] y los caracteres no alfabéticos (dígitos, puntuación, etc.) ocupan colectivamente la cuarta posición (habiendo incluido ya el espacio) entre ⟨t⟩ y ⟨a⟩ . [17]
La frecuencia de las primeras letras de palabras o nombres es útil para preasignar espacio en archivos e índices físicos. [18] Dados 26 cajones de un archivador , en lugar de una asignación 1:1 de un cajón a una letra del alfabeto, a menudo es útil utilizar un código de letras de frecuencia más igual asignando varias letras de baja frecuencia al mismo cajón (a menudo un cajón tiene la etiqueta VWXYZ) y dividir las letras iniciales más frecuentes ( ⟨s, a, c⟩ ) en varios cajones (a menudo 6 cajones Aa-An, Ao-Az, Ca-Cj, Ck- Cz, Sa-Si, Sj-Sz). El mismo sistema se utiliza en algunas obras de varios volúmenes como algunas enciclopedias . En algunas bibliotecas se utilizan números de corte , otra asignación de nombres a un código de frecuencia más igual.
Tanto la distribución general de letras como la distribución de letras iniciales de palabra coinciden aproximadamente con la distribución Zipf y aún más con la distribución Yule . [19]
A menudo, la distribución de frecuencia del primer dígito de cada dato es significativamente diferente de la frecuencia general de todos los dígitos de un conjunto de datos numéricos, una observación conocida como ley de Benford .
Un análisis realizado por Peter Norvig sobre palabras que aparecen 100.000 veces o más en los datos de Google Books transcritos mediante reconocimiento óptico de caracteres (OCR) determinó, entre otras cosas, la frecuencia de las primeras letras de las palabras en inglés. [20]
*Ver © y I sin puntos .
La siguiente figura ilustra las distribuciones de frecuencia de las 26 letras latinas más comunes en algunos idiomas. Todos estos idiomas utilizan un alfabeto similar de más de 25 caracteres.
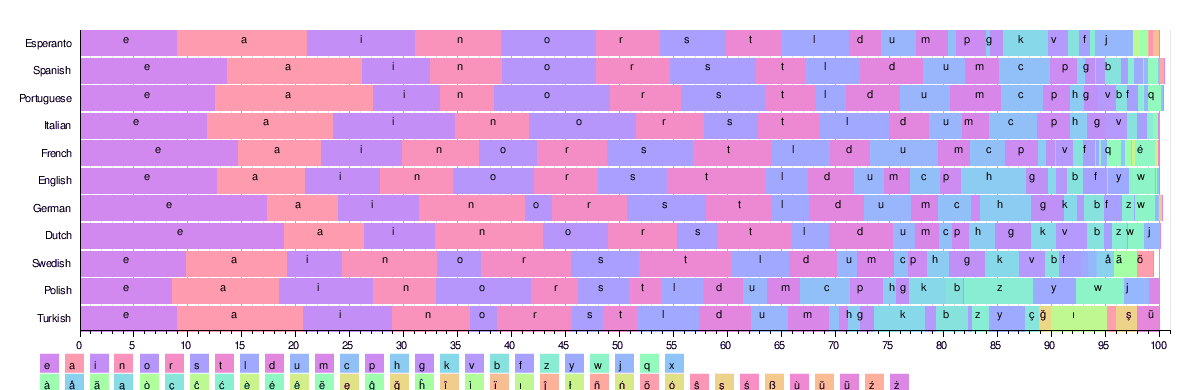
Según estas tablas, el equivalente a ' etaoin shrdlu ' para cada idioma es el siguiente:
La fuente es Leland, Robert. Matemáticas criptológicas. [sl]: Asociación Matemática de América, 2000. 199 p. ISBN 0-88385-719-7
Tablas útiles para frecuencias de una sola letra, digrama, trigrama, tetragrama y pentagrama basadas en 20.000 palabras que tienen en cuenta combinaciones de longitud de palabra y posición de letra para palabras de 3 a 7 letras de longitud: