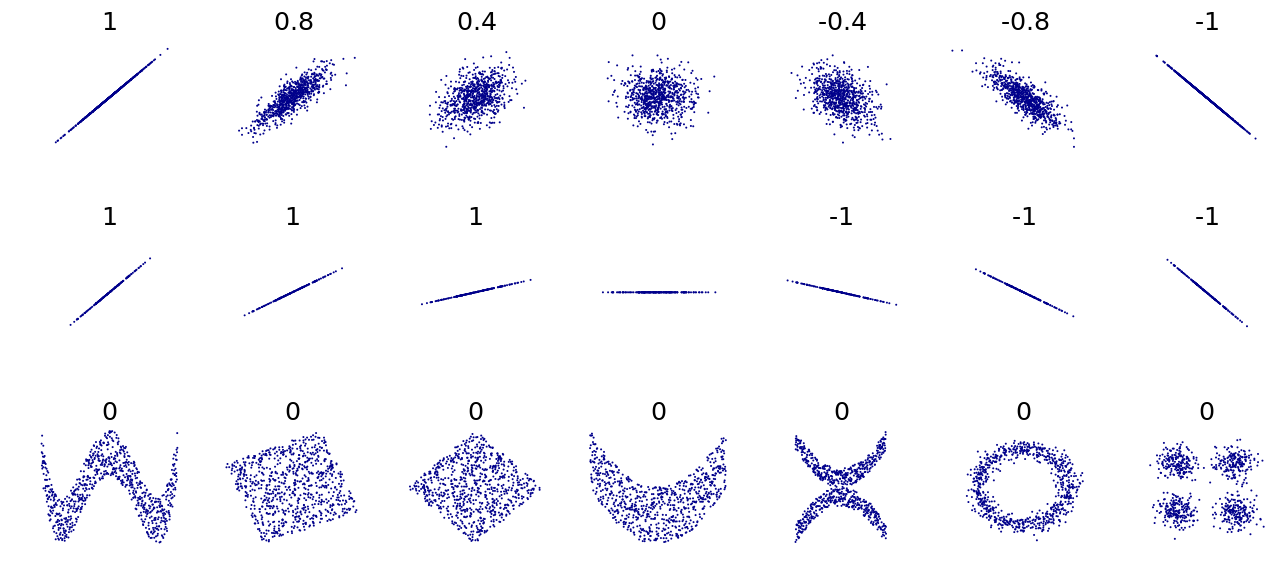
Ejemplos de diagramas de dispersión con diferentes valores del coeficiente de correlación ( ρ )Varios conjuntos de puntos ( x , y ) con el coeficiente de correlación de x e y para cada conjunto. La correlación refleja la fuerza y la dirección de una relación lineal (fila superior), pero no la pendiente de esa relación (fila central), ni muchos aspectos de las relaciones no lineales (fila inferior). Nota: la figura del centro tiene una pendiente de 0, pero en ese caso el coeficiente de correlación no está definido porque la varianza de Y es cero.
En estadística , el coeficiente de correlación de Pearson ( PCC ) [a] es un coeficiente de correlación que mide la correlación lineal entre dos conjuntos de datos. Es la relación entre la covarianza de dos variables y el producto de sus desviaciones estándar ; por lo tanto, es esencialmente una medida normalizada de la covarianza, de modo que el resultado siempre tiene un valor entre −1 y 1. Al igual que con la propia covarianza, la medida solo puede reflejar una correlación lineal de variables e ignora muchos otros tipos de relaciones o correlaciones. Como ejemplo simple, uno esperaría que la edad y la altura de una muestra de niños de una escuela primaria tuvieran un coeficiente de correlación de Pearson significativamente mayor que 0, pero menor que 1 (ya que 1 representaría una correlación irrealmente perfecta).
Nombre e historia
Fue desarrollado por Karl Pearson a partir de una idea relacionada introducida por Francis Galton en la década de 1880, y para la cual la fórmula matemática fue derivada y publicada por Auguste Bravais en 1844. [b] [6] [7] [8] [9] La denominación del coeficiente es, por tanto, un ejemplo de la Ley de Stigler .
Motivación/Intuición y Derivación
El coeficiente de correlación se puede derivar considerando el coseno del ángulo entre dos puntos que representan los dos conjuntos de datos de coordenadas x e y. [10] Por lo tanto, esta expresión es un número entre -1 y 1 y es igual a la unidad cuando todos los puntos se encuentran en una línea recta.
Definición
El coeficiente de correlación de Pearson es la covarianza de las dos variables dividida por el producto de sus desviaciones estándar. La forma de la definición implica un "momento producto", es decir, la media (el primer momento respecto del origen) del producto de las variables aleatorias ajustadas a la media; de ahí el modificador momento producto en el nombre. [ verificación necesaria ]
Para una población
El coeficiente de correlación de Pearson, cuando se aplica a una población , se representa comúnmente con la letra griega ρ (rho) y puede denominarse coeficiente de correlación de población o coeficiente de correlación de Pearson de población . Dado un par de variables aleatorias (por ejemplo, altura y peso), la fórmula para ρ [11] es [12]
La fórmula para se puede expresar en términos de media y expectativa . Dado que [11]
La fórmula para también se puede escribir como
dónde
y se definen como arriba
es la media de
es la media de
Es la expectativa.
La fórmula para se puede expresar en términos de momentos no centrados.
La fórmula para también se puede escribir como
Para una muestra
El coeficiente de correlación de Pearson, cuando se aplica a una muestra , se representa comúnmente por y puede denominarse coeficiente de correlación de la muestra o coeficiente de correlación de Pearson de la muestra . Podemos obtener una fórmula para sustituyendo las estimaciones de las covarianzas y varianzas basadas en una muestra en la fórmula anterior. Dados datos pareados que constan de pares, se define como
dónde
¿Es el tamaño de la muestra?
¿Los puntos de muestra individuales están indexados con i?
(la media de la muestra); y análogamente para .
Reordenando obtenemos esta fórmula [11] para :
donde se definen como anteriormente.
Reordenando nuevamente obtenemos esta fórmula para :
donde se definen como anteriormente.
Esta fórmula sugiere un algoritmo conveniente de un solo paso para calcular correlaciones de muestras, aunque dependiendo de los números involucrados, a veces puede ser numéricamente inestable .
Una expresión equivalente da la fórmula para la media de los productos de las puntuaciones estándar de la siguiente manera:
dónde
se definen como se indica más arriba y se definen a continuación
es la puntuación estándar (y análogamente para la puntuación estándar de ).
También existen fórmulas alternativas para . Por ejemplo, se puede utilizar la siguiente fórmula para :
En condiciones de mucho ruido, extraer el coeficiente de correlación entre dos conjuntos de variables estocásticas no es trivial, en particular cuando el análisis de correlación canónica arroja valores de correlación degradados debido a las fuertes contribuciones del ruido. En otro lugar se ofrece una generalización del enfoque. [13]
Los valores de los coeficientes de correlación de Pearson de la muestra y de la población están en o entre −1 y 1. Las correlaciones iguales a +1 o −1 corresponden a puntos de datos que se encuentran exactamente sobre una línea (en el caso de la correlación de la muestra), o a una distribución bivariada totalmente apoyada sobre una línea (en el caso de la correlación de la población). El coeficiente de correlación de Pearson es simétrico: corr( X , Y ) = corr( Y , X ).
Una propiedad matemática clave del coeficiente de correlación de Pearson es que es invariante ante cambios separados en la ubicación y la escala de las dos variables. Es decir, podemos transformar X en a + bX y transformar Y en c + dY , donde a , b , c y d son constantes con b , d > 0 , sin cambiar el coeficiente de correlación. (Esto es válido tanto para los coeficientes de correlación de Pearson de la población como de la muestra). Las transformaciones lineales más generales sí cambian la correlación: véase § Decorrelación de n variables aleatorias para una aplicación de esto.
Interpretación
El coeficiente de correlación varía de −1 a 1. Un valor absoluto de exactamente 1 implica que una ecuación lineal describe la relación entre X e Y perfectamente, con todos los puntos de datos en una línea . El signo de correlación está determinado por la pendiente de regresión : un valor de +1 implica que todos los puntos de datos se encuentran en una línea para la cual Y aumenta a medida que X aumenta, mientras que un valor de -1 implica una línea donde Y aumenta mientras que X disminuye. [15] Un valor de 0 implica que no hay dependencia lineal entre las variables. [16]
En términos más generales, ( X i − X )( Y i − Y ) es positivo si y solo si X i e Y i se encuentran en el mismo lado de sus respectivas medias. Por lo tanto, el coeficiente de correlación es positivo si X i e Y i tienden a ser simultáneamente mayores o simultáneamente menores que sus respectivas medias. El coeficiente de correlación es negativo ( anticorrelación ) si X i e Y i tienden a estar en lados opuestos de sus respectivas medias. Además, cuanto más fuerte sea una tendencia, mayor será el valor absoluto del coeficiente de correlación.
Rodgers y Nicewander [17] catalogaron trece formas de interpretar la correlación o funciones simples de la misma:
Función de las puntuaciones brutas y medias
Covarianza estandarizada
Pendiente estandarizada de la recta de regresión
Media geométrica de las dos pendientes de regresión
Raíz cuadrada del cociente de dos varianzas
Producto cruzado medio de variables estandarizadas
Función del ángulo entre dos rectas de regresión estandarizadas
Función del ángulo entre dos vectores variables
Varianza reescalada de la diferencia entre puntuaciones estandarizadas
Estimado a partir de la regla del globo
Relacionado con las elipses bivariadas de isoconcentración
Función de las estadísticas de prueba a partir de experimentos diseñados
Razón de dos medias
Interpretación geométrica
Rectas de regresión para y = g X ( x ) [ rojo ] y x = g Y ( y ) [ azul ]
Para datos no centrados, existe una relación entre el coeficiente de correlación y el ángulo φ entre las dos líneas de regresión, y = g X ( x ) y x = g Y ( y ) , obtenido al regresionar y sobre x y x sobre y respectivamente. (Aquí, φ se mide en sentido antihorario dentro del primer cuadrante formado alrededor del punto de intersección de las líneas si r > 0 , o en sentido antihorario desde el cuarto al segundo cuadrante si r < 0 .) Se puede demostrar [18] que si las desviaciones estándar son iguales, entonces r = sec φ − tan φ , donde sec y tan son funciones trigonométricas .
Para datos centrados (es decir, datos que han sido desplazados por las medias muestrales de sus respectivas variables de modo de tener un promedio de cero para cada variable), el coeficiente de correlación también puede verse como el coseno del ángulo θ entre los dos vectores observados en el espacio N -dimensional (para N observaciones de cada variable). [19]
Tanto los coeficientes de correlación centrados como los no centrados (no conformes con Pearson) se pueden determinar para un conjunto de datos. Como ejemplo, supongamos que se encuentra que cinco países tienen productos nacionales brutos de 1, 2, 3, 5 y 8 mil millones de dólares, respectivamente. Supongamos que se encuentra que estos mismos cinco países (en el mismo orden) tienen un 11%, 12%, 13%, 15% y 18% de pobreza. Entonces, sean x e y vectores ordenados de 5 elementos que contienen los datos anteriores: x = (1, 2, 3, 5, 8) e y = (0,11, 0,12, 0,13, 0,15, 0,18) .
Mediante el procedimiento habitual para encontrar el ángulo θ entre dos vectores (ver producto escalar ), el coeficiente de correlación no centrado es
Este coeficiente de correlación no centrado es idéntico a la similitud del coseno . Los datos anteriores se eligieron deliberadamente para que estuvieran perfectamente correlacionados: y = 0,10 + 0,01 x . Por lo tanto, el coeficiente de correlación de Pearson debe ser exactamente uno. Centrando los datos (desplazando x por ℰ( x ) = 3,8 e y por ℰ( y ) = 0,138 ) se obtiene x = (−2,8, −1,8, −0,8, 1,2, 4,2) e y = (−0,028, −0,018, −0,008, 0,012, 0,042) , de donde
Como se esperaba.
Interpretación del tamaño de una correlación
Esta figura da una idea de cómo la utilidad de una correlación de Pearson para predecir valores varía con su magnitud. Dados los valores normales conjuntos X , Y con correlación ρ , (graficado aquí como una función de ρ ) es el factor por el cual un intervalo de predicción dado para Y puede reducirse dado el valor correspondiente de X . Por ejemplo, si ρ = 0,5, entonces el intervalo de predicción del 95% de Y | X será aproximadamente un 13% más pequeño que el intervalo de predicción del 95% de Y .
Varios autores han ofrecido pautas para la interpretación de un coeficiente de correlación. [20] [21] Sin embargo, todos estos criterios son en cierto modo arbitrarios. [21] La interpretación de un coeficiente de correlación depende del contexto y los propósitos. Una correlación de 0,8 puede ser muy baja si se está verificando una ley física utilizando instrumentos de alta calidad, pero puede considerarse muy alta en las ciencias sociales, donde puede haber una mayor contribución de los factores que complican la situación.
Inferencia
La inferencia estadística basada en el coeficiente de correlación de Pearson a menudo se centra en uno de los dos objetivos siguientes:
Un objetivo es probar la hipótesis nula de que el verdadero coeficiente de correlación ρ es igual a 0, basado en el valor del coeficiente de correlación de muestra r .
El otro objetivo es derivar un intervalo de confianza que, en un muestreo repetido, tenga una probabilidad dada de contener ρ .
A continuación se analizan los métodos para lograr uno o ambos de estos objetivos.
Usando una prueba de permutación
Las pruebas de permutación proporcionan un enfoque directo para realizar pruebas de hipótesis y construir intervalos de confianza. Una prueba de permutación para el coeficiente de correlación de Pearson implica los dos pasos siguientes:
Utilizando los datos pareados originales ( x i , y i ), redefina aleatoriamente los pares para crear un nuevo conjunto de datos ( x i , y i′ ), donde los i′ son una permutación del conjunto {1,..., n }. La permutación i′ se selecciona aleatoriamente, con probabilidades iguales en todas las n ! permutaciones posibles. Esto es equivalente a extraer los i′ aleatoriamente sin reemplazo del conjunto {1,..., n }. En el bootstrap , un enfoque estrechamente relacionado, los i y los i′ son iguales y se extraen con reemplazo de {1,..., n };
Construya un coeficiente de correlación r a partir de los datos aleatorios.
Para realizar la prueba de permutación, repita los pasos (1) y (2) una gran cantidad de veces. El valor p para la prueba de permutación es la proporción de los valores r generados en el paso (2) que son mayores que el coeficiente de correlación de Pearson que se calculó a partir de los datos originales. Aquí, "mayor" puede significar que el valor es mayor en magnitud o mayor en valor con signo, dependiendo de si se desea una prueba bilateral o unilateral .
Usando un bootstrap
El método bootstrap se puede utilizar para construir intervalos de confianza para el coeficiente de correlación de Pearson. En el método bootstrap "no paramétrico", se vuelven a muestrear n pares ( x i , y i ) "con reemplazo" a partir del conjunto observado de n pares, y se calcula el coeficiente de correlación r en función de los datos remuestreados. Este proceso se repite una gran cantidad de veces, y la distribución empírica de los valores r remuestreados se utiliza para aproximar la distribución de muestreo de la estadística. Un intervalo de confianza del 95 % para ρ se puede definir como el intervalo que abarca desde el percentil 2,5 hasta el 97,5 de los valores r remuestreados .
Error estándar
Si y son variables aleatorias, con una relación lineal simple entre ellas con un ruido normal aditivo (es decir, y = a + bx + e), entonces un error estándar asociado a la correlación es
donde es la correlación y el tamaño de la muestra. [22] [23]
Pruebas utilizando el estudiantea-distribución
Valores críticos del coeficiente de correlación de Pearson que deben superarse para considerarse significativamente distintos de cero en el nivel 0,05
tiene una distribución t de Student en el caso nulo (correlación cero). [24] Esto se cumple aproximadamente en el caso de valores observados no normales si los tamaños de muestra son lo suficientemente grandes. [25] Para determinar los valores críticos para r se necesita la función inversa:
Alternativamente, se pueden utilizar enfoques asintóticos con muestras grandes.
Otro artículo temprano [26] proporciona gráficos y tablas para valores generales de ρ , para tamaños de muestra pequeños, y analiza enfoques computacionales.
En el caso en que las variables subyacentes no sean normales, la distribución de muestreo del coeficiente de correlación de Pearson sigue una distribución t de Student , pero los grados de libertad se reducen. [27]
Utilizando la distribución exacta
Para los datos que siguen una distribución normal bivariada , la función de densidad exacta f ( r ) para el coeficiente de correlación de muestra r de una distribución normal bivariada es [28] [29] [30]
En el caso especial cuando (correlación poblacional cero), la función de densidad exacta f ( r ) se puede escribir como
donde es la función beta , que es una forma de escribir la densidad de una distribución t de Student para un coeficiente de correlación de muestra estudentizado , como se muestra arriba.
Utilizando la distribución de confianza exacta
Los intervalos de confianza y las pruebas se pueden calcular a partir de una distribución de confianza . Una densidad de confianza exacta para ρ es [31]
Para obtener un intervalo de confianza para ρ, primero calculamos un intervalo de confianza para F ( ):
La transformación inversa de Fisher devuelve el intervalo a la escala de correlación.
Por ejemplo, supongamos que observamos r = 0,7 con un tamaño de muestra de n = 50 y deseamos obtener un intervalo de confianza del 95 % para ρ . El valor transformado es , por lo que el intervalo de confianza en la escala transformada es , o (0,5814, 1,1532). Al convertir de nuevo a la escala de correlación, obtenemos (0,5237, 0,8188).
En el análisis de regresión de mínimos cuadrados
El cuadrado del coeficiente de correlación de la muestra se denota típicamente como r 2 y es un caso especial del coeficiente de determinación . En este caso, estima la fracción de la varianza en Y que se explica por X en una regresión lineal simple . Por lo tanto, si tenemos el conjunto de datos observados y el conjunto de datos ajustado , entonces, como punto de partida, la variación total en Y i alrededor de su valor promedio se puede descomponer de la siguiente manera
donde son los valores ajustados del análisis de regresión. Esto se puede reorganizar para dar
Los dos sumandos anteriores son la fracción de varianza en Y que se explica por X (derecha) y que no se explica por X (izquierda).
A continuación, aplicamos una propiedad de los modelos de regresión de mínimos cuadrados , según la cual la covarianza muestral entre y es cero. Por lo tanto, el coeficiente de correlación muestral entre los valores de respuesta observados y ajustados en la regresión se puede escribir (el cálculo se realiza bajo expectativas, supone estadísticas gaussianas)
De este modo
donde es la proporción de varianza en Y explicada por una función lineal de X.
En la derivación anterior, el hecho de que
se puede demostrar observando que las derivadas parciales de la suma residual de cuadrados ( RSS ) sobre β 0 y β 1 son iguales a 0 en el modelo de mínimos cuadrados, donde
El coeficiente de correlación de Pearson de la población se define en términos de momentos y, por lo tanto, existe para cualquier distribución de probabilidad bivariada para la que se define la covarianza de la población y las varianzas marginales de la población están definidas y son distintas de cero. Algunas distribuciones de probabilidad, como la distribución de Cauchy , tienen una varianza indefinida y, por lo tanto, ρ no está definido si X o Y siguen dicha distribución. En algunas aplicaciones prácticas, como las que involucran datos que se sospecha que siguen una distribución de cola pesada , esta es una consideración importante. Sin embargo, la existencia del coeficiente de correlación generalmente no es una preocupación; por ejemplo, si el rango de la distribución está acotado, ρ siempre está definido.
Tamaño de la muestra
Si el tamaño de la muestra es moderado o grande y la población es normal, entonces, en el caso de la distribución normal bivariada , el coeficiente de correlación de la muestra es la estimación de máxima verosimilitud del coeficiente de correlación de la población, y es asintóticamente imparcial y eficiente , lo que significa aproximadamente que es imposible construir una estimación más precisa que el coeficiente de correlación de la muestra.
Si el tamaño de la muestra es grande y la población no es normal, entonces el coeficiente de correlación de la muestra permanece aproximadamente imparcial, pero puede no ser eficiente.
Si el tamaño de la muestra es grande, entonces el coeficiente de correlación de la muestra es un estimador consistente del coeficiente de correlación de la población siempre que las medias, varianzas y covarianzas de la muestra sean consistentes (lo cual se garantiza cuando se puede aplicar la ley de los grandes números ).
Si el tamaño de la muestra es pequeño, entonces el coeficiente de correlación de la muestra r no es una estimación imparcial de ρ . [11] En su lugar, se debe utilizar el coeficiente de correlación ajustado: consulte la definición en otra parte de este artículo.
Las correlaciones pueden ser diferentes para datos dicotómicos desequilibrados cuando hay un error de varianza en la muestra. [32]
Robustez
Al igual que muchas estadísticas de uso común, la estadística de muestra r no es robusta , [33] por lo que su valor puede ser engañoso si hay valores atípicos . [34] [35] Específicamente, el PMCC no es distributivamente robusto, [36] ni resistente a los valores atípicos [33] (ver Estadísticas robustas § Definición ). La inspección del diagrama de dispersión entre X e Y generalmente revelará una situación en la que la falta de robustez podría ser un problema y, en tales casos, puede ser aconsejable utilizar una medida robusta de asociación. Sin embargo, tenga en cuenta que, si bien la mayoría de los estimadores robustos de asociación miden la dependencia estadística de alguna manera, generalmente no son interpretables en la misma escala que el coeficiente de correlación de Pearson.
Un análisis estratificado es una forma de tener en cuenta la falta de normalidad bivariada o de aislar la correlación resultante de un factor mientras se controla otro. Si W representa la pertenencia a un grupo u otro factor que es deseable controlar, podemos estratificar los datos en función del valor de W y luego calcular un coeficiente de correlación dentro de cada estrato. Las estimaciones a nivel de estrato se pueden combinar para estimar la correlación general mientras se controla W. [ 37]
Variantes
Se pueden calcular variaciones del coeficiente de correlación para distintos fines. A continuación se ofrecen algunos ejemplos.
Coeficiente de correlación ajustado
El coeficiente de correlación muestral r no es una estimación imparcial de ρ . Para los datos que siguen una distribución normal bivariada , la expectativa E[ r ] para el coeficiente de correlación muestral r de una distribución normal bivariada es [38]
Por lo tanto, r es un estimador sesgado de
El estimador único imparcial de varianza mínima r adj viene dado por [39]
r adj también se puede obtener maximizando log( f ( r )),
r adj tiene una varianza mínima para valores grandes de n ,
r adj tiene un sesgo de orden 1 ⁄ ( n − 1) .
Otro coeficiente de correlación ajustado propuesto [11] es [ cita requerida ]
r adj ≈ r para valores grandes de n .
Coeficiente de correlación ponderado
Supongamos que las observaciones que se van a correlacionar tienen distintos grados de importancia que se pueden expresar con un vector de peso w . Para calcular la correlación entre los vectores x e y con el vector de peso w (todos de longitud n ), [40] [41]
Media ponderada:
Covarianza ponderada
Correlación ponderada
Coeficiente de correlación reflexiva
La correlación reflexiva es una variante de la correlación de Pearson en la que los datos no están centrados alrededor de sus valores medios. [ cita requerida ] La correlación reflexiva poblacional es
La correlación reflexiva es simétrica, pero no es invariante bajo la traducción:
La versión ponderada de la correlación reflexiva de la muestra es
Coeficiente de correlación escalado
La correlación escalada es una variante de la correlación de Pearson en la que el rango de los datos se restringe intencionalmente y de manera controlada para revelar correlaciones entre componentes rápidos en series de tiempo . [42] La correlación escalada se define como la correlación promedio entre segmentos cortos de datos.
Sea el número de segmentos que pueden caber en la longitud total de la señal para una escala dada :
Luego, la correlación escalada a lo largo de todas las señales se calcula como
donde es el coeficiente de correlación de Pearson para el segmento .
Al elegir el parámetro , se reduce el rango de valores y se filtran las correlaciones en escalas de tiempo largas, revelando únicamente las correlaciones en escalas de tiempo cortas. De esta manera, se eliminan las contribuciones de los componentes lentos y se conservan las de los componentes rápidos.
Distancia de Pearson
Una métrica de distancia para dos variables X e Y, conocida como distancia de Pearson, se puede definir a partir de su coeficiente de correlación como [43]
Teniendo en cuenta que el coeficiente de correlación de Pearson se encuentra entre [−1, +1], la distancia de Pearson se encuentra en [0, 2]. La distancia de Pearson se ha utilizado en análisis de conglomerados y detección de datos para comunicaciones y almacenamiento con ganancia y desplazamiento desconocidos. [44]
La "distancia" de Pearson definida de esta manera asigna una distancia mayor que 1 a las correlaciones negativas. En realidad, tanto las correlaciones positivas fuertes como las negativas son significativas, por lo que se debe tener cuidado cuando se utiliza la "distancia" de Pearson para el algoritmo del vecino más cercano, ya que dicho algoritmo solo incluirá vecinos con correlación positiva y excluirá vecinos con correlación negativa. Alternativamente, se puede aplicar una distancia de valor absoluto, , que tendrá en cuenta tanto las correlaciones positivas como las negativas. La información sobre la asociación positiva y negativa se puede extraer por separado, más adelante.
Coeficiente de correlación circular
Para las variables X = { x 1 ,..., x n } e Y = { y 1 ,..., y n } que están definidas en el círculo unitario [0, 2π) , es posible definir un análogo circular del coeficiente de Pearson. [45] Esto se hace transformando los puntos de datos en X e Y con una función seno de modo que el coeficiente de correlación se dé como:
donde y son las medias circulares de X e Y. Esta medida puede ser útil en campos como la meteorología, donde la dirección angular de los datos es importante.
Correlación parcial
Si una población o un conjunto de datos se caracteriza por más de dos variables, un coeficiente de correlación parcial mide la fuerza de dependencia entre un par de variables que no se explica por la forma en que ambas cambian en respuesta a variaciones en un subconjunto seleccionado de las otras variables.
Coeficiente de correlación de Pearson en sistemas cuánticos
Para dos observables, y , en un sistema cuántico bipartito, el coeficiente de correlación de Pearson se define como [46] [47]
dónde
es el valor esperado del observable ,
es el valor esperado del observable ,
es el valor esperado del observable ,
es la varianza del observable , y
es la varianza del observable .
es simétrico, es decir , y su valor absoluto es invariante bajo transformaciones afines.
Decorrelación denortevariables aleatorias
Siempre es posible eliminar las correlaciones entre todos los pares de un número arbitrario de variables aleatorias mediante una transformación de datos, incluso si la relación entre las variables no es lineal. Cox y Hinkley presentan este resultado para distribuciones de población. [48]
Existe un resultado correspondiente para reducir las correlaciones de muestra a cero. Supongamos que se observa m veces un vector de n variables aleatorias . Sea X una matriz donde es la j -ésima variable de la observación i . Sea una matriz cuadrada de m por m con cada elemento 1. Entonces D son los datos transformados de modo que cada variable aleatoria tiene media cero, y T son los datos transformados de modo que todas las variables tienen media cero y correlación cero con todas las demás variables – la matriz de correlación de muestra de T será la matriz identidad. Esto tiene que ser dividido por la desviación estándar para obtener la varianza unitaria. Las variables transformadas no estarán correlacionadas, aunque pueden no ser independientes .
donde un exponente de −+1 ⁄ 2 representa lade la matriz inversa de una matriz. La matriz de correlación de T será la matriz identidad. Si una nueva observación de datos x es un vector fila de n elementos, entonces se puede aplicar la misma transformación a x para obtener los vectores transformados d y t :
^ También conocido como r de Pearson , coeficiente de correlación producto-momento de Pearson ( PPMCC ), correlación bivariada , [1] o simplemente coeficiente de correlación no calificado [2]
^ Ya en 1877, Galton utilizaba el término "reversión" y el símbolo " r " para lo que luego se convertiría en "regresión". [3] [4] [5]
Referencias
^ "Tutoriales de SPSS: Correlación de Pearson".
^ "Coeficiente de correlación: definición sencilla, fórmula, pasos sencillos". Cómo hacer estadísticas .
^ Galton, F. (5–19 de abril de 1877). «Leyes típicas de la herencia». Nature . 15 (388, 389, 390): 492–495, 512–514, 532–533. Bibcode :1877Natur..15..492.. doi : 10.1038/015492a0 . S2CID 4136393.En el “Apéndice” de la página 532, Galton utiliza el término “reversión” y el símbolo r .
^ Galton, F. (24 de septiembre de 1885). "La Asociación Británica: Sección II, Antropología: Discurso de apertura por Francis Galton, FRS, etc., Presidente del Instituto Antropológico, Presidente de la Sección". Nature . 32 (830): 507–510.
^ Galton, F. (1886). "Regresión hacia la mediocridad en la estatura hereditaria". Revista del Instituto Antropológico de Gran Bretaña e Irlanda . 15 : 246–263. doi :10.2307/2841583. JSTOR 2841583.
^ Pearson, Karl (20 de junio de 1895). «Notas sobre regresión y herencia en el caso de dos padres». Actas de la Royal Society de Londres . 58 : 240–242. Código Bibliográfico :1895RSPS...58..240P.
^ Stigler, Stephen M. (1989). "Relato de Francis Galton sobre la invención de la correlación". Ciencia estadística . 4 (2): 73–79. doi : 10.1214/ss/1177012580 . JSTOR 2245329.
^ "Analyse mathematique sur les probabilités des errores de situación de un punto". Memoria. Acad. Roy. Ciencia. Inst. Francia . Ciencia. Matemáticas y Física. (en francés). 9 : 255–332. 1844 - a través de Google Books.
^ Wright, S. (1921). "Correlación y causalidad". Revista de investigación agrícola . 20 (7): 557–585.
^ "¿Cómo se obtuvo la fórmula del coeficiente de correlación?". Validación cruzada . Consultado el 26 de octubre de 2024 .
^ abcde Estadísticas reales con Excel, "Conceptos básicos de correlación", recuperado el 22 de febrero de 2015.
^ Weisstein, Eric W. "Correlación estadística". Wolfram MathWorld . Consultado el 22 de agosto de 2020 .
^ Moriya, N. (2008). "Análisis conjunto óptimo multivariado relacionado con el ruido en procesos estocásticos longitudinales". En Yang, Fengshan (ed.). Progreso en el modelado matemático aplicado . Nova Science Publishers, Inc., págs. 223–260. ISBN978-1-60021-976-4.
^ Garren, Steven T. (15 de junio de 1998). "Estimación de máxima verosimilitud del coeficiente de correlación en un modelo normal bivariado, con datos faltantes". Statistics & Probability Letters . 38 (3): 281–288. doi :10.1016/S0167-7152(98)00035-2.
^ "2.6 - Coeficiente de correlación (de Pearson) r". STAT 462 . Consultado el 10 de julio de 2021 .
^ "Estadística empresarial introductoria: el coeficiente de correlación r". opentextbc.ca . Consultado el 21 de agosto de 2020 .
^ Rodgers; Nicewander (1988). "Trece maneras de analizar el coeficiente de correlación" (PDF) . The American Statistician . 42 (1): 59–66. doi :10.2307/2685263. JSTOR 2685263.
^ Schmid, John Jr. (diciembre de 1947). "La relación entre el coeficiente de correlación y el ángulo incluido entre las líneas de regresión". The Journal of Educational Research . 41 (4): 311–313. doi :10.1080/00220671.1947.10881608. JSTOR 27528906.
^ Rummel, RJ (1976). "Entendiendo la correlación". Cap. 5 (como se ilustra para un caso especial en el párrafo siguiente).
^ Buda, Andrzej; Jarynowski, Andrzej (diciembre de 2010). Vida útil de las correlaciones y sus aplicaciones . Wydawnictwo Niezależne. págs. 5-21. ISBN9788391527290.
^ ab Cohen, J. (1988). Análisis de potencia estadística para las ciencias del comportamiento (2.ª ed.).
^ Bowley, AL (1928). "La desviación estándar del coeficiente de correlación". Revista de la Asociación Estadounidense de Estadística . 23 (161): 31–34. doi :10.2307/2277400. ISSN 0162-1459. JSTOR 2277400.
^ "Derivación del error estándar para el coeficiente de correlación de Pearson". Validación cruzada . Consultado el 30 de julio de 2021 .
^ Rahman, NA (1968) Un curso de estadística teórica , Charles Griffin and Company, 1968
^ Kendall, MG, Stuart, A. (1973) La teoría avanzada de las estadísticas, volumen 2: inferencia y relación , Griffin. ISBN 0-85264-215-6 (sección 31.19)
^ Soper, HE ; Young, AW; Cave, BM; Lee, A.; Pearson, K. (1917). "Sobre la distribución del coeficiente de correlación en muestras pequeñas. Apéndice II a los artículos de "Student" y RA Fisher. Un estudio cooperativo". Biometrika . 11 (4): 328–413. doi :10.1093/biomet/11.4.328.
^ Davey, Catherine E.; Grayden, David B.; Egan, Gary F.; Johnston, Leigh A. (enero de 2013). "El filtrado induce correlación en datos de estado de reposo fMRI". NeuroImage . 64 : 728–740. doi :10.1016/j.neuroimage.2012.08.022. hdl : 11343/44035 . PMID 22939874. S2CID 207184701.
^ Hotelling, Harold (1953). "Nueva luz sobre el coeficiente de correlación y sus transformadas". Revista de la Royal Statistical Society . Serie B (Metodológica). 15 (2): 193–232. doi :10.1111/j.2517-6161.1953.tb00135.x. JSTOR 2983768.
^ Kenney, JF; Keeping, ES (1951). Matemáticas de la estadística . Vol. Parte 2 (2.ª ed.). Princeton, NJ: Van Nostrand.
^ Weisstein, Eric W. "Coeficiente de correlación: distribución normal bivariada". Wolfram MathWorld .
^ Taraldsen, Gunnar (2020). "Confianza en la correlación". doi : 10.13140/RG.2.2.23673.49769 .{{cite journal}}: Requiere citar revista |journal=( ayuda )
^ Lai, Chun Sing; Tao, Yingshan; Xu, Fangyuan; Ng, Wing WY; Jia, Youwei; Yuan, Haoliang; Huang, Chao; Lai, Loi Lei; Xu, Zhao; Locatelli, Giorgio (enero de 2019). "Un marco de análisis de correlación robusto para datos desequilibrados y dicotómicos con incertidumbre" (PDF) . Ciencias de la información . 470 : 58–77. doi :10.1016/j.ins.2018.08.017. S2CID 52878443.
^ ab Wilcox, Rand R. (2005). Introducción a la estimación robusta y prueba de hipótesis . Academic Press.
^ Devlin, Susan J. ; Gnanadesikan, R.; Kettenring JR (1975). "Estimación robusta y detección de valores atípicos con coeficientes de correlación". Biometrika . 62 (3): 531–545. doi :10.1093/biomet/62.3.531. JSTOR 2335508.
^ Vaart, AW van der (13 de octubre de 1998). Estadística asintótica. Cambridge University Press. doi :10.1017/cbo9780511802256. ISBN978-0-511-80225-6.
^ Katz., Mitchell H. (2006) Análisis multivariable: una guía práctica para médicos . Segunda edición. Cambridge University Press. ISBN 978-0-521-54985-1 . ISBN 0-521-54985-X.
^ Hotelling, H. (1953). "Nueva luz sobre el coeficiente de correlación y sus transformadas". Revista de la Royal Statistical Society. Serie B (Metodológica) . 15 (2): 193–232. doi :10.1111/j.2517-6161.1953.tb00135.x. JSTOR 2983768.
^ Olkin, Ingram; Pratt, John W. (marzo de 1958). "Estimación imparcial de ciertos coeficientes de correlación". Anales de estadística matemática . 29 (1): 201–211. doi : 10.1214/aoms/1177706717 . JSTOR 2237306..
^ "Re: Calcular una correlación ponderada". sci.tech-archive.net .
^ "Matriz de correlación ponderada – Intercambio de archivos – MATLAB Central".
^ Nikolić, D; Muresan, RC; Feng, W; Singer, W (2012). "Análisis de correlación a escala: una mejor manera de calcular un correlograma cruzado" (PDF) . Revista Europea de Neurociencia . 35 (5): 1–21. doi :10.1111/j.1460-9568.2011.07987.x. PMID 22324876. S2CID 4694570.
^ Fulekar (Ed.), MH (2009) Bioinformática: aplicaciones en ciencias ambientales y de la vida , Springer (pp. 110) ISBN 1-4020-8879-5
^ Immink, K. Schouhamer; Weber, J. (octubre de 2010). "Detección de distancia mínima de Pearson para canales multinivel con desajuste de ganancia y/o compensación". IEEE Transactions on Information Theory . 60 (10): 5966–5974. CiteSeerX 10.1.1.642.9971 . doi :10.1109/tit.2014.2342744. S2CID 1027502. Consultado el 11 de febrero de 2018 .
^ Jammalamadaka, S. Rao; SenGupta, A. (2001). Temas de estadística circular. Nueva Jersey: World Scientific. p. 176. ISBN978-981-02-3778-3. Recuperado el 21 de septiembre de 2016 .
^ Reid, MD (1 de julio de 1989). "Demostración de la paradoja de Einstein-Podolsky-Rosen utilizando amplificación paramétrica no degenerada". Physical Review A . 40 (2): 913–923. doi :10.1103/PhysRevA.40.913.
^ Maccone, L.; Dagmar, B.; Macchiavello, C. (1 de abril de 2015). "Complementariedad y correlaciones". Physical Review Letters . 114 (13): 130401. arXiv : 1408.6851 . doi :10.1103/PhysRevLett.114.130401.
Wikiversidad tiene recursos de aprendizaje sobre correlación lineal
"coco". comparandocorrelaciones.org .– Una interfaz web gratuita y un paquete R para la comparación estadística de dos correlaciones dependientes o independientes con variables superpuestas o no superpuestas.
"Correlación". nagysandor.eu .– una simulación Flash interactiva sobre la correlación de dos variables distribuidas normalmente.
"Calculadora de coeficiente de correlación". hackmath.net . Regresión lineal.
"Valores críticos para el coeficiente de correlación de Pearson" (PDF) . frank.mtsu.edu/~dkfuller .– mesa grande.
"Adivina la correlación".– Un juego en el que los jugadores adivinan qué tan correlacionadas están dos variables en un diagrama de dispersión, para comprender mejor el concepto de correlación.












![{\displaystyle \operatorname {cov} (X,Y)=\operatorname {\mathbb {E} } [(X-\mu _{X})(Y-\mu _{Y})],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1e88bc4ba085b98d5cca09b958ad378d50127308)

![{\displaystyle \rho _{X,Y}={\frac {\operatorname {\mathbb {E} } [(X-\mu _{X})(Y-\mu _{Y})]}{\ sigma _{X}\sigma _{Y}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/042c646e848d2dc6e15d7b5c7a5b891941b2eab6)



![{\displaystyle {\begin{aligned}\mu _{X}={}&\operatorname {\mathbb {E} } [\,X\,]\\\mu _{Y}={}&\operatorname {\mathbb {E} } [\,Y\,]\\\sigma _{X}^{2}={}&\operatorname {\mathbb {E} } \left[\,\left(X-\operatorname {\mathbb {E} } [X]\right)^{2}\,\right]=\operatorname {\mathbb {E} } \left[\,X^{2}\,\right]-\left(\operatorname {\mathbb {E} } [\,X\,]\right)^{2}\\\sigma _{Y}^{2}={}&\operatorname {\mathbb {E} } \left[\,\left(Y-\nombreoperador {\mathbb {E} } [Y]\right)^{2}\,\right]=\nombreoperador {\mathbb {E} } \left[\,Y^{2}\,\right]-\left(\,\nombreoperador {\mathbb {E} } [\,Y\,]\right)^{2}\\&\nombreoperador {\mathbb {E} } [\,\left(X-\mu _{X}\right)\left(Y-\mu _{Y}\right)\,]=\nombreoperador {\mathbb {E} } [\,\left(X-\nombreoperador {\mathbb {E} } [\,X\,]\right)\left(Y-\nombreoperador {\mathbb {E} } [\,Y\,]\right)\,]=\nombreoperador {\mathbb {E} } [\,X\,Y\,]-\nombre del operador {\mathbb {E} } [\,X\,]\nombre del operador {\mathbb {E} } [\,Y\,]\,,\end{alineado}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a2469cdb397ef7d50c200b03c9e9f7311f0ab2b1)
![{\displaystyle \rho _{X,Y}={\frac {\operatorname {\mathbb {E} } [\,X\,Y\,]-\operatorname {\mathbb {E} } [\,X\,]\operatorname {\mathbb {E} } [\,Y\,]}{{\sqrt {\operatorname {\mathbb {E} } \left[\,X^{2}\,\right]-\left(\operatorname {\mathbb {E} } [\,X\,]\right)^{2}}}~{\sqrt {\operatorname {\mathbb {E} } \left[\,Y^{2}\,\right]-\left(\operatorname {\mathbb {E} } [\,Y\,]\right)^{2}}}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5984dfb290912b0e0b92a984bf49cdd628c38b2c)










































![{\displaystyle z={\frac {x-{\text{media}}}{\text{SE}}}=[F(r)-F(\rho _{0})]{\sqrt {n-3}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/da7a3d54a70f9005e3bf9a2accf62cbf0fa0ea71)

![{\displaystyle 100(1-\alpha )\%{\text{CI}}:\nombre_operador {artanh} (\rho )\in [\nombre_operador {artanh} (r)\pm z_{\alpha /2}{\text{SE}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/affc3f0ee39499c97bb851229113f49d83100bf2)
![{\displaystyle 100(1-\alpha )\%{\text{CI}}:\rho \in [\tanh(\operatorname {artanh} (r)-z_{\alpha /2}{\text{SE}}),\tanh(\operatorname {artanh} (r)+z_{\alpha /2}{\text{SE}})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf658969d39ea848505750b5cd76db21da78dd5c)








![{\displaystyle {\begin{aligned}r(Y,{\hat {Y}})&={\frac {\sum _{i}(Y_{i}-{\bar {Y}})({\hat {Y}}_{i}-{\bar {Y}})}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\frac {\sum _{i}(Y_{i}-{\hat {Y}}_{i}+{\hat {Y}}_{i}-{\bar {Y}})({\hat {Y}}_{i}-{\bar {Y}})}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \suma _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\frac {\sum _{i}[(Y_{i}-{\hat {Y}}_{i})({\hat {Y}}_{i}-{\bar {Y}})+({\hat {Y}}_{i}-{\bar {Y}})^{2}]}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \suma _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\frac {\sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \suma _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\sqrt {\frac {\sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}{\sum _{i}(Y_{i}-{\bar {Y}})^{2}}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d86595f3f77e8ee96952760d9176a5fa140cc562)









![{\displaystyle \operatorname {\mathbb {E} } \left[r\right]=\rho -{\frac {\rho \left(1-\rho ^{2}\right)}{2n}}+\cdots ,\quad }](https://wikimedia.org/api/rest_v1/media/math/render/svg/683b838e709e3b32a3c22dfec4fa665a593f42ad)







![{\displaystyle \operatorname {corr} _{r}(X,Y)={\frac {\operatorname {\mathbb {E} } [\,X\,Y\,]}{\sqrt {\operatorname {\mathbb {E} } [\,X^{2}\,]\cdot \operatorname {\mathbb {E} } [\,Y^{2}\,]}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6d897e4b303a062ed14cc9f88f35f5c8ffc91f7)















![{\displaystyle \mathbb {Cor} (X,Y)={\frac {\mathbb {E} [X\otimes Y]-\mathbb {E} [X]\cdot \mathbb {E} [Y]}{\sqrt {\mathbb {V} [X]\cdot \mathbb {V} [Y]}}}\,,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/66e11a93834596dc5412bb175d74f57a217d5d0b)
![{\displaystyle \mathbb {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/09de7acbba84104ff260708b6e9b8bae32c3fafa)
![{\displaystyle \mathbb {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f74f6124a0e4a70bc6fda6c2b0f7c43d13ee0e2d)
![{\displaystyle \mathbb {E} [X\o veces Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0153ecd83015d566f496dbbeb8e25d9641193ac3)

![{\displaystyle \mathbb {V} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/025a7353276eda435ee8a3d04758a41b363061c8)
![{\displaystyle \mathbb {V} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8414159ddf57b8d840ce8288bddb634ecf563f9a)







