En estadística , correlación o dependencia es cualquier relación estadística, ya sea causal o no, entre dos variables aleatorias o datos bivariados . Aunque en el sentido más amplio, "correlación" puede indicar cualquier tipo de asociación, en estadística suele referirse al grado en que un par de variables están relacionadas linealmente . Ejemplos familiares de fenómenos dependientes incluyen la correlación entre la altura de los padres y sus hijos, y la correlación entre el precio de un bien y la cantidad que los consumidores están dispuestos a comprar, como se representa en la llamada curva de demanda .
Las correlaciones son útiles porque pueden indicar una relación predictiva que puede explotarse en la práctica. Por ejemplo, una empresa de servicios eléctricos puede producir menos energía en un día templado según la correlación entre la demanda de electricidad y el clima. En este ejemplo, existe una relación causal , porque el clima extremo hace que las personas usen más electricidad para calentar o enfriar. Sin embargo, en general, la presencia de una correlación no es suficiente para inferir la presencia de una relación causal (es decir, correlación no implica causalidad ).
Formalmente, las variables aleatorias son dependientes si no satisfacen una propiedad matemática de independencia probabilística . En el lenguaje informal, correlación es sinónimo de dependencia . Sin embargo, cuando se usa en un sentido técnico, la correlación se refiere a cualquiera de varios tipos específicos de operaciones matemáticas entre las variables probadas y sus respectivos valores esperados . Básicamente, la correlación es la medida de cómo dos o más variables se relacionan entre sí. Hay varios coeficientes de correlación , a menudo denominados o , que miden el grado de correlación. El más común de ellos es el coeficiente de correlación de Pearson , que es sensible sólo a una relación lineal entre dos variables (que puede estar presente incluso cuando una variable es una función no lineal de la otra). Se han desarrollado otros coeficientes de correlación, como la correlación de rangos de Spearman , para que sean más robustos que los de Pearson, es decir, más sensibles a relaciones no lineales. [1] [2] [3] La información mutua también se puede aplicar para medir la dependencia entre dos variables.

La medida más familiar de dependencia entre dos cantidades es el coeficiente de correlación momento-producto de Pearson (PPMCC), o "coeficiente de correlación de Pearson", comúnmente llamado simplemente "coeficiente de correlación". Se obtiene tomando la relación de la covarianza de las dos variables en cuestión de nuestro conjunto de datos numéricos, normalizada a la raíz cuadrada de sus varianzas. Matemáticamente, simplemente se divide la covarianza de las dos variables por el producto de sus desviaciones estándar . Karl Pearson desarrolló el coeficiente a partir de una idea similar pero ligeramente diferente de Francis Galton . [4]
Un coeficiente de correlación momento-producto de Pearson intenta establecer una línea de mejor ajuste a través de un conjunto de datos de dos variables esencialmente presentando los valores esperados y el coeficiente de correlación de Pearson resultante indica qué tan lejos está el conjunto de datos real de los valores esperados. Dependiendo del signo de nuestro coeficiente de correlación de Pearson, podemos terminar con una correlación negativa o positiva si existe algún tipo de relación entre las variables de nuestro conjunto de datos. [ cita necesaria ]
El coeficiente de correlación poblacional entre dos variables aleatorias y con valores esperados y desviaciones estándar se define como :
donde es el operador del valor esperado , significa covarianza y es una notación alternativa ampliamente utilizada para el coeficiente de correlación. La correlación de Pearson se define sólo si ambas desviaciones estándar son finitas y positivas. Una fórmula alternativa puramente en términos de momentos es:
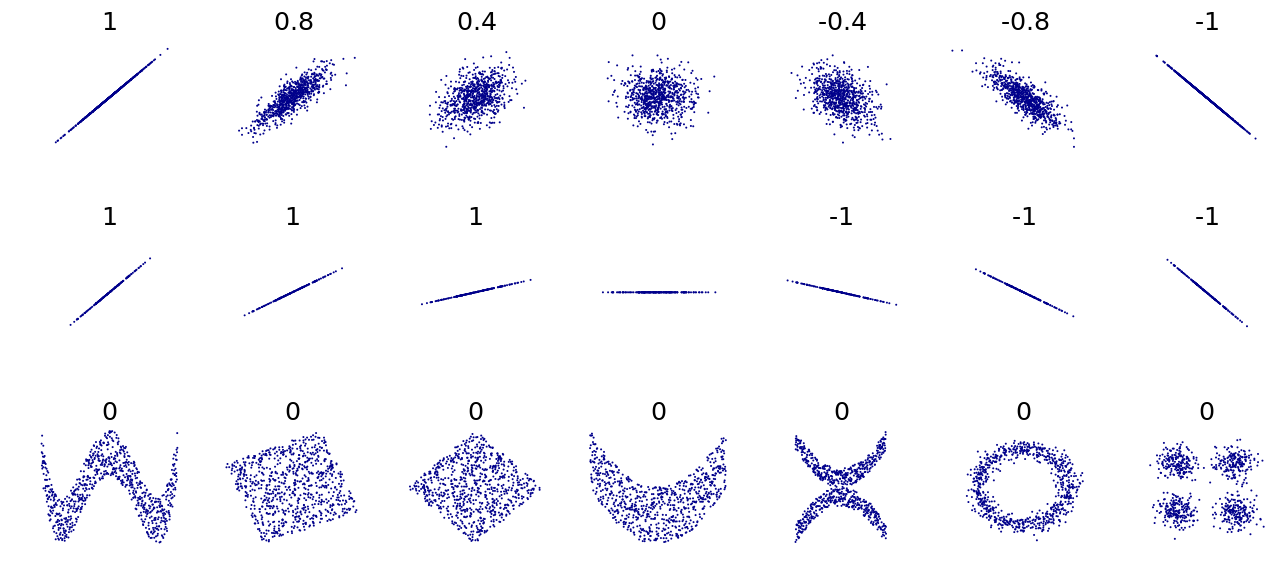
Un corolario de la desigualdad de Cauchy-Schwarz es que el valor absoluto del coeficiente de correlación de Pearson no es mayor que 1. Por lo tanto, el valor de un coeficiente de correlación oscila entre −1 y +1. El coeficiente de correlación es +1 en el caso de una relación lineal perfecta directa (creciente) (correlación), −1 en el caso de una relación lineal perfecta inversa (decreciente) ( anti-correlación ), [5] y algún valor en el intervalo abierto en todos los demás casos, que indica el grado de dependencia lineal entre las variables. A medida que se acerca a cero, hay menos relación (más cercana a no correlacionada). Cuanto más cerca esté el coeficiente de −1 o 1, más fuerte será la correlación entre las variables.
Si las variables son independientes , el coeficiente de correlación de Pearson es 0, pero lo contrario no es cierto porque el coeficiente de correlación detecta sólo dependencias lineales entre dos variables. En palabras más simples, si dos variables aleatorias X e Y son independientes, entonces no están correlacionadas, pero si dos variables aleatorias no están correlacionadas, entonces pueden ser independientes o no.
Por ejemplo, supongamos que la variable aleatoria está distribuida simétricamente con respecto a cero y . Entonces está completamente determinado por , de modo que y son perfectamente dependientes, pero su correlación es cero; no están correlacionados . Sin embargo, en el caso especial en el que y son conjuntamente normales , la falta de correlación equivale a la independencia.
Aunque los datos no correlacionados no implican necesariamente independencia, se puede comprobar si las variables aleatorias son independientes si su información mutua es 0.
Dada una serie de mediciones del par indexado por , el coeficiente de correlación muestral se puede utilizar para estimar la correlación poblacional de Pearson entre y . El coeficiente de correlación muestral se define como
donde y son las medias muestrales de y , y y son las desviaciones estándar muestrales corregidas de y .
Expresiones equivalentes para son
donde y son las desviaciones estándar muestrales sin corregir de y .
Si y son resultados de mediciones que contienen errores de medición, los límites realistas del coeficiente de correlación no son −1 a +1 sino un rango más pequeño. [6] Para el caso de un modelo lineal con una única variable independiente, el coeficiente de determinación (R al cuadrado) es el cuadrado de , coeficiente producto-momento de Pearson.
Considere la distribución de probabilidad conjunta de X e Y que figura en la siguiente tabla.
Para esta distribución conjunta, las distribuciones marginales son:
Esto produce las siguientes expectativas y variaciones:
Por lo tanto:
Los coeficientes de correlación de rangos , como el coeficiente de correlación de rangos de Spearman y el coeficiente de correlación de rangos de Kendall (τ), miden el grado en que, a medida que una variable aumenta, la otra variable tiende a aumentar, sin requerir que ese aumento esté representado por una relación lineal. Si, a medida que una variable aumenta, la otra disminuye , los coeficientes de correlación de rango serán negativos. Es común considerar estos coeficientes de correlación de rango como alternativas al coeficiente de Pearson, utilizados para reducir la cantidad de cálculo o para hacer que el coeficiente sea menos sensible a la no normalidad en las distribuciones. Sin embargo, este punto de vista tiene poca base matemática, ya que los coeficientes de correlación de rango miden un tipo de relación diferente al coeficiente de correlación momento-producto de Pearson , y es mejor verlos como medidas de un tipo diferente de asociación, en lugar de como una medida alternativa de la población. coeficiente de correlación. [7] [8]
Para ilustrar la naturaleza de la correlación de rango y su diferencia con la correlación lineal, considere los siguientes cuatro pares de números :
A medida que pasamos de cada par al siguiente, el par aumenta, y también lo hace . Esta relación es perfecta, en el sentido de que un aumento de siempre va acompañado de un aumento de . Esto significa que tenemos una correlación de rango perfecta, y los coeficientes de correlación de Spearman y Kendall son 1, mientras que en este ejemplo el coeficiente de correlación momento-producto de Pearson es 0,7544, lo que indica que los puntos están lejos de estar en línea recta. De la misma manera, si siempre disminuye cuando aumenta , los coeficientes de correlación de rango serán −1, mientras que el coeficiente de correlación producto-momento de Pearson puede estar cerca o no de −1, dependiendo de qué tan cerca estén los puntos de una línea recta. Aunque en los casos extremos de correlación de rango perfecta los dos coeficientes son ambos iguales (ambos +1 o ambos −1), este no es generalmente el caso, por lo que los valores de los dos coeficientes no se pueden comparar de manera significativa. [7] Por ejemplo, para los tres pares (1, 1) (2, 3) (3, 2) el coeficiente de Spearman es 1/2, mientras que el coeficiente de Kendall es 1/3.
La información proporcionada por un coeficiente de correlación no es suficiente para definir la estructura de dependencia entre variables aleatorias. [9] El coeficiente de correlación define completamente la estructura de dependencia sólo en casos muy particulares, por ejemplo cuando la distribución es una distribución normal multivariada . (Ver diagrama arriba.) En el caso de distribuciones elípticas , caracteriza las (hiper)elipses de igual densidad; sin embargo, no caracteriza completamente la estructura de dependencia (por ejemplo, los grados de libertad de una distribución t multivariada determinan el nivel de dependencia de la cola).
La correlación de distancia [10] [11] se introdujo para abordar la deficiencia de la correlación de Pearson de que puede ser cero para variables aleatorias dependientes; la correlación de distancia cero implica independencia.
El coeficiente de dependencia aleatoria [12] es una medida de dependencia computacionalmente eficiente basada en cópulas entre variables aleatorias multivariadas. RDC es invariante con respecto a escalas no lineales de variables aleatorias, es capaz de descubrir una amplia gama de patrones de asociación funcional y toma valor cero en la independencia.
Para dos variables binarias , la razón de posibilidades mide su dependencia y toma un rango de números no negativos, posiblemente infinito :. Las estadísticas relacionadas, como la Y de Yule y la Q de Yule , normalizan esto al rango similar a una correlación . El modelo logístico generaliza el odds ratio para modelar casos en los que las variables dependientes son discretas y puede haber una o más variables independientes.
El índice de correlación , la información mutua basada en entropía , la correlación total , la correlación total dual y la correlación policórica también son capaces de detectar dependencias más generales, al igual que la consideración de la cópula entre ellas, mientras que el coeficiente de determinación generaliza el coeficiente de correlación a una regresión múltiple. .
El grado de dependencia entre las variables X e Y no depende de la escala en la que se expresan las variables. Es decir, si estamos analizando la relación entre X e Y , la mayoría de las medidas de correlación no se ven afectadas al transformar X en a + bX e Y en c + dY , donde a , b , c y d son constantes ( siendo b y d positivos ). Esto se aplica a algunas estadísticas de correlación , así como a sus análogos poblacionales . Algunas estadísticas de correlación, como el coeficiente de correlación de rango, también son invariantes a las transformaciones monótonas de las distribuciones marginales de X y/o Y.

La mayoría de las medidas de correlación son sensibles a la forma en que se muestrean X e Y. Las dependencias tienden a ser más fuertes si se analizan desde una gama más amplia de valores. Por lo tanto, si consideramos el coeficiente de correlación entre las alturas de los padres y sus hijos sobre todos los hombres adultos, y lo comparamos con el mismo coeficiente de correlación calculado cuando se selecciona que los padres tengan entre 165 cm y 170 cm de altura, la correlación será más débil en este último caso. Se han desarrollado varias técnicas que intentan corregir la restricción de rango en una o ambas variables, y se utilizan comúnmente en el metanálisis; las más comunes son las ecuaciones del caso II y del caso III de Thorndike. [13]
Varias medidas de correlación en uso pueden no estar definidas para ciertas distribuciones conjuntas de X e Y. Por ejemplo, el coeficiente de correlación de Pearson se define en términos de momentos y, por lo tanto, no estará definido si los momentos no están definidos. Siempre se definen medidas de dependencia basadas en cuantiles . Las estadísticas basadas en muestras destinadas a estimar medidas poblacionales de dependencia pueden tener o no propiedades estadísticas deseables, como ser imparciales o asintóticamente consistentes , basadas en la estructura espacial de la población de la cual se tomaron las muestras.
La sensibilidad a la distribución de datos puede resultar ventajosa. Por ejemplo, la correlación escalada está diseñada para utilizar la sensibilidad al rango para detectar correlaciones entre componentes rápidos de series temporales. [14] Al reducir el rango de valores de manera controlada, las correlaciones en escalas de tiempo largas se filtran y solo se revelan las correlaciones en escalas de tiempo cortas.
La matriz de correlación de variables aleatorias es la matriz cuya entrada es
Por tanto, las entradas diagonales son todas idénticamente una . Si las medidas de correlación utilizadas son coeficientes producto-momento, la matriz de correlación es la misma que la matriz de covarianza de las variables aleatorias estandarizadas para . Esto se aplica tanto a la matriz de correlaciones poblacionales (en cuyo caso es la desviación estándar de la población) como a la matriz de correlaciones muestrales (en cuyo caso denota la desviación estándar de la muestra). En consecuencia, cada una es necesariamente una matriz semidefinida positiva . Además, la matriz de correlación es estrictamente positiva definida si ninguna variable puede generar todos sus valores exactamente como una función lineal de los valores de las demás.
La matriz de correlación es simétrica porque la correlación entre y es la misma que la correlación entre y .
Una matriz de correlación aparece, por ejemplo, en una fórmula para el coeficiente de determinación múltiple , una medida de bondad de ajuste en la regresión múltiple .
En el modelado estadístico , las matrices de correlación que representan las relaciones entre variables se clasifican en diferentes estructuras de correlación, que se distinguen por factores como la cantidad de parámetros necesarios para estimarlas. Por ejemplo, en una matriz de correlación intercambiable , se modela que todos los pares de variables tienen la misma correlación, por lo que todos los elementos no diagonales de la matriz son iguales entre sí. Por otro lado, una matriz autorregresiva se utiliza a menudo cuando las variables representan una serie de tiempo, ya que es probable que las correlaciones sean mayores cuando las mediciones son más cercanas en el tiempo. Otros ejemplos incluyen independientes, no estructurados, dependientes de M y Toeplitz .
En el análisis exploratorio de datos , la iconografía de las correlaciones consiste en sustituir una matriz de correlaciones por un diagrama donde las correlaciones "notables" están representadas por una línea continua (correlación positiva), o una línea de puntos (correlación negativa).
En algunas aplicaciones (p. ej., construcción de modelos de datos a partir de datos observados sólo parcialmente) se desea encontrar la matriz de correlación "más cercana" a una matriz de correlación "aproximada" (p. ej., una matriz que normalmente carece de positividad semidefinida debido a la forma en que se presenta). sido calculado).
En 2002, Higham [15] formalizó la noción de cercanía utilizando la norma de Frobenius y proporcionó un método para calcular la matriz de correlación más cercana utilizando el algoritmo de proyección de Dykstra , cuya implementación está disponible como una API web en línea. [dieciséis]
Esto despertó el interés en el tema, con nuevos resultados teóricos (por ejemplo, calcular la matriz de correlación más cercana con estructura factorial [17] ) y numéricos (por ejemplo, utilizar el método de Newton para calcular la matriz de correlación más cercana [18] ) obtenidos en los años siguientes.
Lo mismo ocurre con dos procesos estocásticos y : si son independientes, entonces no están correlacionados. [19] : pág. 151 Lo contrario de esta afirmación podría no ser cierto. Incluso si dos variables no están correlacionadas, es posible que no sean independientes entre sí.
La máxima convencional de que " correlación no implica causalidad " significa que la correlación no puede usarse por sí sola para inferir una relación causal entre las variables. [20] Esta máxima no debe interpretarse en el sentido de que las correlaciones no pueden indicar la existencia potencial de relaciones causales. Sin embargo, las causas subyacentes a la correlación, si las hay, pueden ser indirectas y desconocidas, y las correlaciones altas también se superponen con relaciones de identidad ( tautologías ), donde no existe ningún proceso causal. En consecuencia, una correlación entre dos variables no es condición suficiente para establecer una relación causal (en cualquier dirección).
La correlación entre la edad y la altura en los niños es bastante transparente desde el punto de vista causal, pero la correlación entre el estado de ánimo y la salud en las personas lo es menos. ¿Un mejor estado de ánimo conduce a una mejor salud, o una buena salud conduce a un buen humor, o ambas cosas? ¿O hay algún otro factor detrás de ambos? En otras palabras, una correlación puede tomarse como evidencia de una posible relación causal, pero no puede indicar cuál podría ser la relación causal, si la hubiera.

El coeficiente de correlación de Pearson indica la fuerza de una relación lineal entre dos variables, pero su valor generalmente no caracteriza completamente su relación. [21] En particular, si la media condicional de dado , denotado , no es lineal en , el coeficiente de correlación no determinará completamente la forma de .
La imagen adyacente muestra diagramas de dispersión del cuarteto de Anscombe , un conjunto de cuatro pares diferentes de variables creado por Francis Anscombe . [22] Las cuatro variables tienen la misma media (7,5), varianza (4,12), correlación (0,816) y línea de regresión ( ). Sin embargo, como se puede observar en los gráficos, la distribución de las variables es muy diferente. La primera (arriba a la izquierda) parece tener una distribución normal y corresponde a lo que se esperaría al considerar dos variables correlacionadas y siguiendo el supuesto de normalidad. El segundo (arriba a la derecha) no se distribuye normalmente; Si bien se puede observar una relación obvia entre las dos variables, no es lineal. En este caso, el coeficiente de correlación de Pearson no indica que exista una relación funcional exacta: sólo el grado en que esa relación puede aproximarse mediante una relación lineal. En el tercer caso (abajo a la izquierda), la relación lineal es perfecta, excepto por un valor atípico que ejerce suficiente influencia para reducir el coeficiente de correlación de 1 a 0,816. Finalmente, el cuarto ejemplo (abajo a la derecha) muestra otro ejemplo en el que un valor atípico es suficiente para producir un coeficiente de correlación alto, aunque la relación entre las dos variables no sea lineal.
Estos ejemplos indican que el coeficiente de correlación, como estadística resumida , no puede reemplazar el examen visual de los datos. A veces se dice que los ejemplos demuestran que la correlación de Pearson supone que los datos siguen una distribución normal , pero esto sólo es parcialmente correcto. [4] La correlación de Pearson se puede calcular con precisión para cualquier distribución que tenga una matriz de covarianza finita , que incluye la mayoría de las distribuciones encontradas en la práctica. Sin embargo, el coeficiente de correlación de Pearson (tomado junto con la media y la varianza de la muestra) solo es una estadística suficiente si los datos se extraen de una distribución normal multivariada . Como resultado, el coeficiente de correlación de Pearson caracteriza completamente la relación entre variables si y sólo si los datos se extraen de una distribución normal multivariada.
Si un par de variables aleatorias sigue una distribución normal bivariada , la media condicional es una función lineal de y la media condicional es una función lineal de El coeficiente de correlación entre y y las medias marginales y las varianzas de y determinan esta relación lineal:
donde y son los valores esperados de y respectivamente, y y son las desviaciones estándar de y respectivamente.
La correlación empírica es una estimación del coeficiente de correlación. Una estimación de distribución está dada por
¿Dónde está la función hipergeométrica gaussiana ?
Esta densidad es tanto una densidad posterior bayesiana como una densidad de distribución de confianza óptima exacta . [23] [24]









![{\displaystyle \rho _{X,Y}=\operatorname {corr} (X,Y)={\operatorname {cov} (X,Y) \over \sigma _{X}\sigma _{Y}}= {\operatorname {E} [(X-\mu _{X})(Y-\mu _{Y})] \over \sigma _{X}\sigma _{Y}},\quad {\text{ si}}\ \sigma _{X}\sigma _{Y}>0.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b551ad29592ae746bf05fe397fbdc56201f483a5)
















![{\displaystyle {\begin{aligned}r_{xy}&={\frac {\sum x_{i}y_{i}-n{\bar {x}}{\bar {y}}}{ns'_ {x}s'_{y}}}\\[5pt]&={\frac {n\sum x_{i}y_{i}-\sum x_{i}\sum y_{i}}{{\ sqrt {n\sum x_{i}^{2}-(\sum x_{i})^{2}}}~{\sqrt {n\sum y_{i}^{2}-(\sum y_{ i})^{2}}}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6da33b8144a5e67959969ef2c4830ece1938bbb2)










![{\displaystyle {\begin{alineado}\rho _{X,Y}&={\frac {1}{\sigma _{X}\sigma _{Y}}}\mathrm {E} [(X-\ mu _{X})(Y-\mu _{Y})]\\[5pt]&={\frac {1}{\sigma _{X}\sigma _{Y}}}\sum _{x ,y}{(x-\mu _{X})(y-\mu _{Y})\mathrm {P} (X=x,Y=y)}\\[5pt]&=\left(1 -{\frac {2}{3}}\right)(-1-0){\frac {1}{3}}+\left(0-{\frac {2}{3}}\right)( 0-0){\frac {1}{3}}+\left(1-{\frac {2}{3}}\right)(1-0){\frac {1}{3}}=0 .\end{alineado}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/75bf2b7806338758b4c55d7b4f18a5071b8e919b)

![{\displaystyle [0,+\infty]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f32245981f739c86ea8f68ce89b1ad6807428d35)
![{\displaystyle [-1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51e3b7f14a6f70e614728c583409a0b9a8b9de01)






























