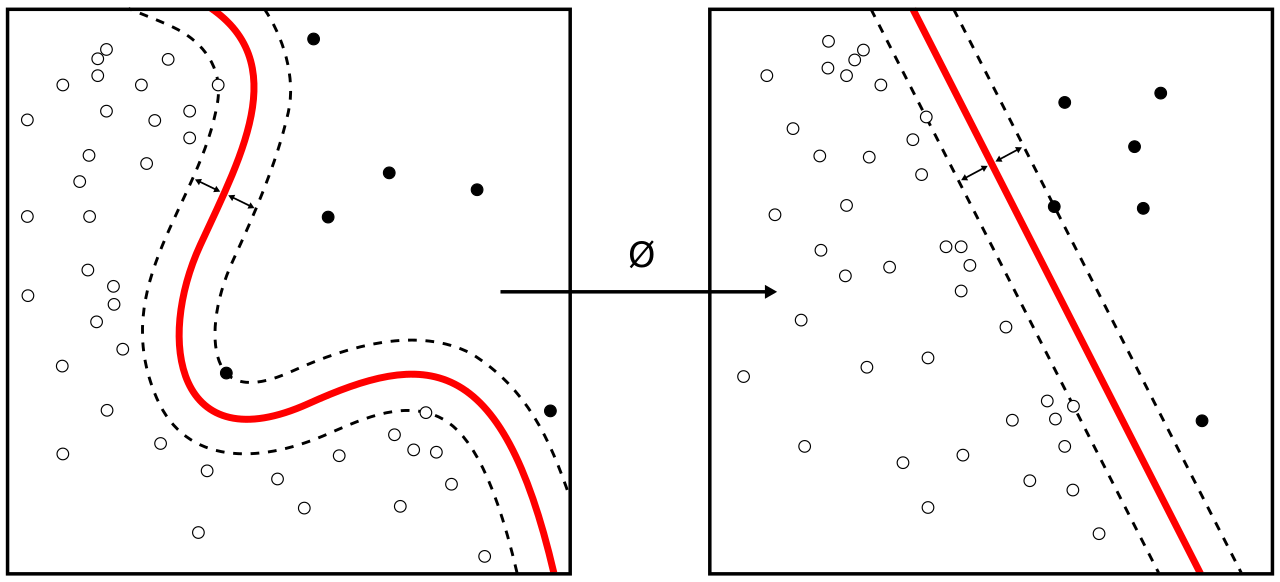
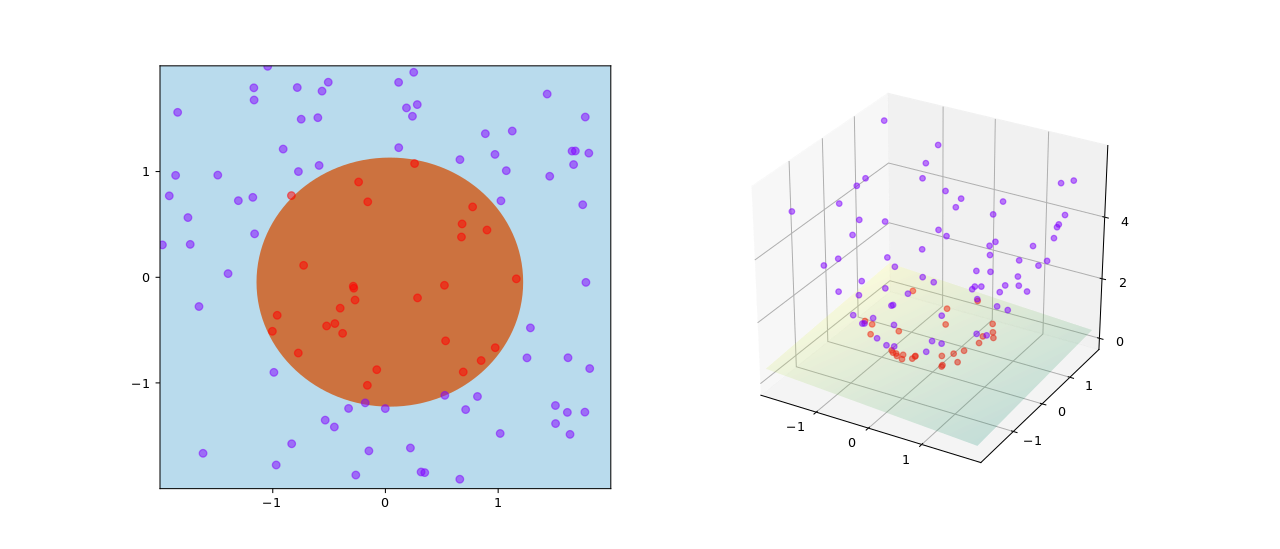
Además de realizar una clasificación lineal , las SVM pueden realizar de manera eficiente una clasificación no lineal utilizando el truco del núcleo , representando los datos solo a través de un conjunto de comparaciones de similitud por pares entre los puntos de datos originales utilizando una función del núcleo, que los transforma en coordenadas en un espacio de características de dimensión superior . Por lo tanto, las SVM utilizan el truco del núcleo para mapear implícitamente sus entradas en espacios de características de alta dimensión, donde se puede realizar una clasificación lineal. [3] Al ser modelos de margen máximo, las SVM son resistentes a datos ruidosos (por ejemplo, ejemplos mal clasificados). Las SVM también se pueden utilizar para tareas de regresión , donde el objetivo se vuelve sensible.
El algoritmo de agrupamiento de vectores de soporte [4] , creado por Hava Siegelmann y Vladimir Vapnik , aplica las estadísticas de los vectores de soporte, desarrolladas en el algoritmo de máquinas de vectores de soporte, para categorizar datos no etiquetados. [ cita requerida ] Estos conjuntos de datos requieren enfoques de aprendizaje no supervisado , que intentan encontrar la agrupación natural de los datos en grupos y luego mapear nuevos datos de acuerdo con estas agrupaciones.
La popularidad de los SVM se debe probablemente a su facilidad para el análisis teórico y a su flexibilidad para ser aplicados a una amplia variedad de tareas, incluidos los problemas de predicción estructurada . No está claro que los SVM tengan un mejor rendimiento predictivo que otros modelos lineales, como la regresión logística y la regresión lineal . [ cita requerida ]
Motivación
H 1 no separa las clases. H 2 sí lo hace, pero con un pequeño margen. H 3 las separa con el margen máximo.
La clasificación de datos es una tarea común en el aprendizaje automático . Supongamos que algunos puntos de datos dados pertenecen a una de dos clases, y el objetivo es decidir en qué clase estará un nuevo punto de datos . En el caso de las máquinas de vectores de soporte, un punto de datos se ve como un vector dimensional (una lista de números), y queremos saber si podemos separar dichos puntos con un hiperplano dimensional . Esto se llama clasificador lineal . Hay muchos hiperplanos que podrían clasificar los datos. Una opción razonable como el mejor hiperplano es el que representa la mayor separación, o margen , entre las dos clases. Por lo tanto, elegimos el hiperplano de modo que se maximice la distancia desde él hasta el punto de datos más cercano en cada lado. Si existe un hiperplano de este tipo, se lo conoce como hiperplano de margen máximo y el clasificador lineal que define se conoce como clasificador de margen máximo ; o equivalentemente, el perceptrón de estabilidad óptima . [ cita requerida ]
Más formalmente, una máquina de vectores de soporte construye un hiperplano o un conjunto de hiperplanos en un espacio de dimensión alta o infinita, que se puede usar para clasificación , regresión u otras tareas como la detección de valores atípicos. [5] Intuitivamente, una buena separación se logra mediante el hiperplano que tiene la mayor distancia al punto de datos de entrenamiento más cercano de cualquier clase (el llamado margen funcional), ya que, en general, cuanto mayor sea el margen, menor será el error de generalización del clasificador. [6] Un error de generalización menor significa que es menos probable que el implementador experimente sobreajuste .
Máquina de núcleo
Aunque el problema original puede plantearse en un espacio de dimensión finita, a menudo sucede que los conjuntos a discriminar no son linealmente separables en ese espacio. Por esta razón, se propuso [7] que el espacio de dimensión finita original se mapeara en un espacio de dimensión mucho mayor, presumiblemente haciendo más fácil la separación en ese espacio. Para mantener la carga computacional razonable, las asignaciones utilizadas por los esquemas SVM están diseñadas para asegurar que los productos escalares de pares de vectores de datos de entrada se puedan calcular fácilmente en términos de las variables en el espacio original, definiéndolos en términos de una función kernel seleccionada para adaptarse al problema. [8] Los hiperplanos en el espacio de dimensión mayor se definen como el conjunto de puntos cuyo producto escalar con un vector en ese espacio es constante, donde dicho conjunto de vectores es un conjunto ortogonal (y por lo tanto mínimo) de vectores que define un hiperplano. Los vectores que definen los hiperplanos pueden elegirse para que sean combinaciones lineales con parámetros de imágenes de vectores de características que aparecen en la base de datos. Con esta elección de un hiperplano, los puntos en el espacio de características que se mapean en el hiperplano se definen por la relación Nótese que si se vuelve pequeño a medida que se aleja de , cada término en la suma mide el grado de cercanía del punto de prueba al punto de base de datos correspondiente . De esta manera, la suma de kernels anterior se puede utilizar para medir la cercanía relativa de cada punto de prueba a los puntos de datos originados en uno u otro de los conjuntos a discriminar. Nótese el hecho de que el conjunto de puntos mapeados en cualquier hiperplano puede ser bastante convolucionado como resultado, permitiendo una discriminación mucho más compleja entre conjuntos que no son convexos en absoluto en el espacio original.
Aplicaciones
Las SVM se pueden utilizar para resolver diversos problemas del mundo real:
La clasificación de imágenes también se puede realizar mediante máquinas de clasificación de imágenes. Los resultados experimentales muestran que las máquinas de clasificación de imágenes logran una precisión de búsqueda significativamente mayor que los esquemas de refinamiento de consultas tradicionales después de solo tres o cuatro rondas de retroalimentación de relevancia. Esto también es cierto para los sistemas de segmentación de imágenes , incluidos aquellos que utilizan una versión modificada de la máquina de clasificación de imágenes que utiliza el enfoque privilegiado sugerido por Vapnik. [11] [12]
Clasificación de datos satelitales como datos SAR utilizando SVM supervisado. [13]
Los caracteres escritos a mano se pueden reconocer utilizando SVM. [14] [15]
El algoritmo SVM se ha aplicado ampliamente en las ciencias biológicas y en otras ciencias. Se ha utilizado para clasificar proteínas con hasta el 90% de los compuestos clasificados correctamente. Se han sugerido pruebas de permutación basadas en pesos SVM como un mecanismo para la interpretación de los modelos SVM. [16] [17] Los pesos de las máquinas de vectores de soporte también se han utilizado para interpretar modelos SVM en el pasado. [18] La interpretación post hoc de los modelos de máquinas de vectores de soporte para identificar las características utilizadas por el modelo para hacer predicciones es un área de investigación relativamente nueva con especial importancia en las ciencias biológicas.
Historia
El algoritmo SVM original fue inventado por Vladimir N. Vapnik y Alexey Ya. Chervonenkis en 1964. [ cita requerida ] En 1992, Bernhard Boser, Isabelle Guyon y Vladimir Vapnik sugirieron una forma de crear clasificadores no lineales aplicando el truco del núcleo a hiperplanos de margen máximo. [7] La encarnación de "margen suave", como se usa comúnmente en los paquetes de software, fue propuesta por Corinna Cortes y Vapnik en 1993 y publicada en 1995. [1]
SVM lineal
Hiperplano de margen máximo y márgenes para un SVM entrenado con muestras de dos clases. Las muestras en el margen se denominan vectores de soporte.
Se nos proporciona un conjunto de datos de entrenamiento de puntos de la forma
donde son 1 o −1, cada uno indicando la clase a la que pertenece el punto. Cada uno es un vector real de dimensión . Queremos encontrar el "hiperplano de margen máximo" que divide el grupo de puntos para el cual del grupo de puntos para el cual , que se define de modo que se maximice la distancia entre el hiperplano y el punto más cercano de cualquiera de los grupos.
Cualquier hiperplano puede escribirse como el conjunto de puntos que satisfacen
donde es el vector normal (no necesariamente normalizado) al hiperplano. Esto es muy parecido a la forma normal de Hesse , excepto que no es necesariamente un vector unitario. El parámetro determina el desplazamiento del hiperplano desde el origen a lo largo del vector normal .
Advertencia: la mayor parte de la literatura sobre el tema define el sesgo de manera que
Margen duro
Si los datos de entrenamiento son linealmente separables , podemos seleccionar dos hiperplanos paralelos que separen las dos clases de datos, de modo que la distancia entre ellos sea lo más grande posible. La región delimitada por estos dos hiperplanos se denomina "margen", y el hiperplano de margen máximo es el hiperplano que se encuentra a medio camino entre ellos. Con un conjunto de datos normalizado o estandarizado, estos hiperplanos se pueden describir mediante las ecuaciones
(todo lo que se encuentre en este límite o por encima de él es de una clase, con etiqueta 1)
y
(todo lo que esté en este límite o por debajo de él es de la otra clase, con etiqueta −1).
Geométricamente, la distancia entre estos dos hiperplanos es , [19] por lo que para maximizar la distancia entre los planos queremos minimizar . La distancia se calcula utilizando la ecuación de la distancia de un punto a un plano . También tenemos que evitar que los puntos de datos caigan en el margen, agregamos la siguiente restricción: para cada uno
o
Estas restricciones establecen que cada punto de datos debe estar en el lado correcto del margen.
Esto se puede reescribir como
Podemos juntar todo esto para obtener el problema de optimización:
Los y que resuelven este problema determinan el clasificador final, , donde es la función de signo .
Una consecuencia importante de esta descripción geométrica es que el hiperplano de margen máximo está completamente determinado por aquellos que se encuentran más cerca de él (explicado más adelante). Estos se denominan vectores de soporte .
Margen suave
Para ampliar SVM a casos en los que los datos no son linealmente separables, la función de pérdida de bisagra es útil.
Tenga en cuenta que es el i -ésimo objetivo (es decir, en este caso, 1 o −1), y es la i -ésima salida.
Esta función es cero si se cumple la restricción en (1) , es decir, si se encuentra en el lado correcto del margen. Para los datos que se encuentran en el lado incorrecto del margen, el valor de la función es proporcional a la distancia desde el margen.
El objetivo de la optimización es entonces minimizar:
donde el parámetro determina la compensación entre aumentar el tamaño del margen y garantizar que se encuentre en el lado correcto del margen (nótese que podemos agregar un peso a cualquiera de los términos en la ecuación anterior). Al deconstruir la pérdida de la bisagra, este problema de optimización se puede simplificar de la siguiente manera:
Por lo tanto, para valores grandes de , se comportará de manera similar al SVM de margen duro, si los datos de entrada son clasificables linealmente, pero aún aprenderá si una regla de clasificación es viable o no.
Núcleos no lineales
Máquina de núcleo
El algoritmo original de hiperplano de margen máximo propuesto por Vapnik en 1963 construyó un clasificador lineal . Sin embargo, en 1992, Bernhard Boser, Isabelle Guyon y Vladimir Vapnik sugirieron una forma de crear clasificadores no lineales aplicando el truco del núcleo (originalmente propuesto por Aizerman et al. [20] ) a hiperplanos de margen máximo. [7] El truco del núcleo, donde los productos escalares se reemplazan por núcleos, se deriva fácilmente en la representación dual del problema SVM. Esto permite que el algoritmo ajuste el hiperplano de margen máximo en un espacio de características transformado . La transformación puede ser no lineal y el espacio transformado de alta dimensión; aunque el clasificador es un hiperplano en el espacio de características transformado, puede ser no lineal en el espacio de entrada original.
Cabe destacar que trabajar en un espacio de características de mayor dimensión aumenta el error de generalización de las máquinas de vectores de soporte, aunque dadas suficientes muestras el algoritmo aún funciona bien. [21]
El núcleo está relacionado con la transformación mediante la ecuación . El valor w también está en el espacio transformado, con . Los productos escalares con w para la clasificación se pueden calcular nuevamente mediante el truco del núcleo, es decir .
Cálculo del clasificador SVM
Calcular el clasificador SVM (de margen suave) equivale a minimizar una expresión de la forma
Nos centraremos en el clasificador de margen blando, ya que, como se ha señalado anteriormente, la elección de un valor suficientemente pequeño para da como resultado el clasificador de margen duro para datos de entrada clasificables linealmente. El enfoque clásico, que implica reducir (2) a un problema de programación cuadrática , se detalla a continuación. A continuación, se analizarán enfoques más recientes, como el descenso por subgradiente y el descenso por coordenadas.
Primitivo
La minimización de (2) se puede reescribir como un problema de optimización restringida con una función objetivo diferenciable de la siguiente manera.
Para cada uno introducimos una variable . Nótese que es el número no negativo más pequeño que satisface
Por lo tanto, podemos reescribir el problema de optimización de la siguiente manera
Esto se llama el problema primal .
Dual
Al resolver el dual lagrangiano del problema anterior, se obtiene el problema simplificado
Esto se denomina problema dual . Dado que el problema de maximización dual es una función cuadrática sujeta a restricciones lineales, se puede resolver de manera eficiente mediante algoritmos de programación cuadrática .
Aquí, las variables se definen de tal manera que
Además, exactamente cuando se encuentra en el lado correcto del margen y cuando se encuentra en el límite del margen, se deduce que se puede escribir como una combinación lineal de los vectores de soporte.
El desplazamiento, , se puede recuperar encontrando un en el límite del margen y resolviendo
(Tenga en cuenta que desde .)
Truco del kernel
Un ejemplo de entrenamiento de SVM con kernel dado por φ(( a , b )) = ( a , b , a 2 + b 2 )
Supongamos ahora que queremos aprender una regla de clasificación no lineal que corresponde a una regla de clasificación lineal para los puntos de datos transformados. Además, se nos da una función kernel que satisface .
Sabemos que el vector de clasificación en el espacio transformado satisface
donde, se obtienen al resolver el problema de optimización
Los coeficientes se pueden resolver utilizando programación cuadrática, como antes. Nuevamente, podemos encontrar un índice tal que , de modo que se encuentre en el límite del margen en el espacio transformado, y luego resolver
Finalmente,
Métodos modernos
Los algoritmos recientes para encontrar el clasificador SVM incluyen el descenso por subgradiente y el descenso por coordenadas. Ambas técnicas han demostrado ofrecer ventajas significativas sobre el enfoque tradicional cuando se trabaja con conjuntos de datos grandes y dispersos: los métodos por subgradiente son especialmente eficientes cuando hay muchos ejemplos de entrenamiento y el descenso por coordenadas cuando la dimensión del espacio de características es alta.
Nótese que es una función convexa de y . Como tal, los métodos tradicionales de descenso de gradiente (o SGD ) se pueden adaptar, donde en lugar de dar un paso en la dirección del gradiente de la función, se da un paso en la dirección de un vector seleccionado del subgradiente de la función . Este enfoque tiene la ventaja de que, para ciertas implementaciones, el número de iteraciones no escala con , el número de puntos de datos. [22]
Para cada , iterativamente, el coeficiente se ajusta en la dirección de . Luego, el vector de coeficientes resultante se proyecta sobre el vector de coeficientes más cercano que satisface las restricciones dadas. (Normalmente se utilizan distancias euclidianas). Luego, el proceso se repite hasta que se obtiene un vector de coeficientes casi óptimo. El algoritmo resultante es extremadamente rápido en la práctica, aunque se han demostrado pocas garantías de rendimiento. [23]
Minimización del riesgo empírico
La máquina de vectores de soporte de margen suave descrita anteriormente es un ejemplo de un algoritmo de minimización de riesgo empírico (ERM) para la pérdida de bisagra . Vistas de esta manera, las máquinas de vectores de soporte pertenecen a una clase natural de algoritmos para la inferencia estadística, y muchas de sus características únicas se deben al comportamiento de la pérdida de bisagra. Esta perspectiva puede proporcionar una mayor comprensión de cómo y por qué funcionan las máquinas de vectores de soporte, y nos permite analizar mejor sus propiedades estadísticas.
Minimización de riesgos
En el aprendizaje supervisado, se proporciona un conjunto de ejemplos de entrenamiento con etiquetas , y se desea predecir dado . Para ello, se formula una hipótesis , , tal que es una aproximación "buena" de . Una aproximación "buena" se define habitualmente con la ayuda de una función de pérdida , , que caracteriza lo mala que es una predicción de . Entonces nos gustaría elegir una hipótesis que minimice el riesgo esperado :
En la mayoría de los casos, no conocemos la distribución conjunta de los riesgos empíricos. En estos casos, una estrategia habitual es elegir la hipótesis que minimice el riesgo empírico:
Bajo ciertas suposiciones sobre la secuencia de variables aleatorias (por ejemplo, que se generan mediante un proceso de Markov finito), si el conjunto de hipótesis que se considera es lo suficientemente pequeño, el minimizador del riesgo empírico se aproximará mucho al minimizador del riesgo esperado a medida que aumenta. Este enfoque se denomina minimización del riesgo empírico o ERM.
Regularización y estabilidad
Para que el problema de minimización tenga una solución bien definida, tenemos que poner restricciones al conjunto de hipótesis que se están considerando. Si es un espacio normalizado (como es el caso de SVM), una técnica particularmente eficaz es considerar solo aquellas hipótesis para las que . Esto es equivalente a imponer una penalización de regularización y resolver el nuevo problema de optimización.
De manera más general, puede ser alguna medida de la complejidad de la hipótesis , de modo que se prefieren las hipótesis más simples.
SVM y la pérdida de bisagra
Recuerde que el clasificador SVM (de margen suave) se elige para minimizar la siguiente expresión:
A la luz de la discusión anterior, vemos que la técnica SVM es equivalente a la minimización de riesgo empírico con regularización de Tikhonov, donde en este caso la función de pérdida es la pérdida de bisagra.
La diferencia entre la pérdida de bisagra y estas otras funciones de pérdida se expresa mejor en términos de funciones objetivo: la función que minimiza el riesgo esperado para un par dado de variables aleatorias .
En particular, denotemos condicional al evento de que . En el contexto de la clasificación, tenemos:
El clasificador óptimo es por tanto:
Para la pérdida al cuadrado, la función objetivo es la función de expectativa condicional, ; para la pérdida logística, es la función logit, . Si bien ambas funciones objetivo producen el clasificador correcto, como , nos brindan más información de la que necesitamos. De hecho, nos brindan suficiente información para describir completamente la distribución de .
Por otra parte, se puede comprobar que la función objetivo para la pérdida de bisagra es exactamente . Por lo tanto, en un espacio de hipótesis suficientemente rico (o equivalentemente, para un núcleo elegido adecuadamente), el clasificador SVM convergerá a la función más simple (en términos de ) que clasifique correctamente los datos. Esto extiende la interpretación geométrica de SVM: para la clasificación lineal, el riesgo empírico se minimiza con cualquier función cuyos márgenes se encuentren entre los vectores de soporte, y el más simple de estos es el clasificador de margen máximo. [24]
Propiedades
Los SVM pertenecen a una familia de clasificadores lineales generalizados y pueden interpretarse como una extensión del perceptrón . [25] También pueden considerarse un caso especial de regularización de Tikhonov . Una propiedad especial es que minimizan simultáneamente el error de clasificación empírico y maximizan el margen geométrico ; por lo tanto, también se conocen como clasificadores de margen máximo .
Meyer, Leisch y Hornik realizaron una comparación del SVM con otros clasificadores. [26]
Selección de parámetros
La eficacia de SVM depende de la selección del kernel, los parámetros del kernel y el parámetro de margen suave . Una opción común es un kernel gaussiano, que tiene un único parámetro . La mejor combinación de y a menudo se selecciona mediante una búsqueda en cuadrícula con secuencias de y que crecen exponencialmente , por ejemplo, ; . Normalmente, cada combinación de opciones de parámetros se comprueba mediante validación cruzada , y se eligen los parámetros con la mejor precisión de validación cruzada. Alternativamente, se puede utilizar el trabajo reciente en optimización bayesiana para seleccionar y , que a menudo requiere la evaluación de muchas menos combinaciones de parámetros que la búsqueda en cuadrícula. El modelo final, que se utiliza para probar y clasificar nuevos datos, se entrena luego en todo el conjunto de entrenamiento utilizando los parámetros seleccionados. [27]
Asuntos
Las posibles desventajas del SVM incluyen los siguientes aspectos:
Requiere etiquetado completo de los datos de entrada
El SVM solo es directamente aplicable a tareas de dos clases. Por lo tanto, se deben aplicar algoritmos que reduzcan la tarea multiclase a varios problemas binarios; consulte la sección SVM multiclase.
Los parámetros de un modelo resuelto son difíciles de interpretar.
Extensiones
SVM multiclase
El SVM multiclase tiene como objetivo asignar etiquetas a instancias mediante el uso de máquinas de vectores de soporte, donde las etiquetas se extraen de un conjunto finito de varios elementos.
El enfoque dominante para hacerlo es reducir el problema multiclase único a múltiples problemas de clasificación binaria . [28] Los métodos comunes para dicha reducción incluyen: [28] [29]
Construcción de clasificadores binarios que distinguen entre una de las etiquetas y el resto ( uno contra todos ) o entre cada par de clases ( uno contra uno ). La clasificación de nuevas instancias para el caso de uno contra todos se realiza mediante una estrategia de "el ganador se lleva todo", en la que el clasificador con la función de salida más alta asigna la clase (es importante que las funciones de salida estén calibradas para producir puntuaciones comparables). Para el enfoque de uno contra uno, la clasificación se realiza mediante una estrategia de votación de máximos ganadores, en la que cada clasificador asigna la instancia a una de las dos clases, luego el voto para la clase asignada se incrementa en un voto y, finalmente, la clase con más votos determina la clasificación de la instancia.
Crammer y Singer propusieron un método SVM multiclase que convierte el problema de clasificación multiclase en un único problema de optimización, en lugar de descomponerlo en múltiples problemas de clasificación binaria. [32] Véase también Lee, Lin y Wahba [33] [34] y Van den Burg y Groenen. [35]
Máquinas de vectores de soporte transductivos
Las máquinas de vectores de soporte transductivas amplían las máquinas de vectores de soporte en el sentido de que también podrían tratar datos parcialmente etiquetados en el aprendizaje semisupervisado siguiendo los principios de la transducción . Aquí, además del conjunto de entrenamiento , el alumno también recibe un conjunto
de ejemplos de prueba a clasificar. Formalmente, una máquina de vectores de soporte transductiva se define mediante el siguiente problema de optimización primal: [36]
Minimizar (en )
sujeto a (para cualquier y cualquier )
y
Las máquinas de vectores de soporte transductivos fueron introducidas por Vladimir N. Vapnik en 1998.
SVM estructurado
La máquina de vectores de soporte estructurada es una extensión del modelo SVM tradicional. Si bien el modelo SVM está diseñado principalmente para tareas de clasificación binaria, clasificación multiclase y regresión, la SVM estructurada amplía su aplicación para manejar etiquetas de salida estructuradas generales, por ejemplo, árboles de análisis, clasificación con taxonomías, alineación de secuencias y muchas más. [37]
Regresión
Regresión de vectores de soporte (predicción) con diferentes umbrales ε . A medida que ε aumenta, la predicción se vuelve menos sensible a los errores.
En 1996, Vladimir N. Vapnik , Harris Drucker, Christopher JC Burges, Linda Kaufman y Alexander J. Smola propusieron una versión de SVM para regresión . [38] Este método se denomina regresión de vectores de soporte (SVR). El modelo producido por la clasificación de vectores de soporte (como se describió anteriormente) depende solo de un subconjunto de los datos de entrenamiento, porque la función de costo para construir el modelo no se preocupa por los puntos de entrenamiento que se encuentran más allá del margen. Análogamente, el modelo producido por SVR depende solo de un subconjunto de los datos de entrenamiento, porque la función de costo para construir el modelo ignora cualquier dato de entrenamiento cercano a la predicción del modelo. Suykens y Vandewalle propusieron otra versión de SVM conocida como máquina de vectores de soporte de mínimos cuadrados (LS-SVM). [39]
Entrenar el SVR original significa resolver [40]
minimizar
sujeto a
donde es una muestra de entrenamiento con valor objetivo . El producto interno más la intersección es la predicción para esa muestra y es un parámetro libre que sirve como umbral: todas las predicciones deben estar dentro de un rango de las predicciones verdaderas. Las variables de holgura se agregan generalmente a lo anterior para permitir errores y una aproximación en caso de que el problema anterior sea inviable.
SVM bayesiano
En 2011, Polson y Scott demostraron que el SVM admite una interpretación bayesiana a través de la técnica de aumento de datos . [41] En este enfoque, el SVM se considera como un modelo gráfico (donde los parámetros están conectados a través de distribuciones de probabilidad). Esta vista extendida permite la aplicación de técnicas bayesianas a los SVM, como el modelado de características flexibles, el ajuste automático de hiperparámetros y la cuantificación predictiva de la incertidumbre . Recientemente, Florian Wenzel desarrolló una versión escalable del SVM bayesiano, lo que permite la aplicación de SVM bayesianos a big data . [42] Florian Wenzel desarrolló dos versiones diferentes, un esquema de inferencia variacional (VI) para la máquina de vectores de soporte (SVM) del núcleo bayesiano y una versión estocástica (SVI) para la SVM bayesiana lineal. [43]
Implementación
Los parámetros del hiperplano de margen máximo se derivan de la solución de la optimización. Existen varios algoritmos especializados para resolver rápidamente el problema de programación cuadrática (QP) que surge de las máquinas de modelado de ecuaciones diferenciales, que se basan principalmente en heurísticas para dividir el problema en partes más pequeñas y manejables.
Otro enfoque consiste en utilizar un método de punto interior que utiliza iteraciones similares a las de Newton para encontrar una solución de las condiciones de Karush-Kuhn-Tucker de los problemas primal y dual. [44]
En lugar de resolver una secuencia de problemas descompuestos, este enfoque resuelve directamente el problema en su totalidad. Para evitar resolver un sistema lineal que involucra la matriz kernel grande, a menudo se utiliza una aproximación de bajo rango a la matriz en el truco del kernel.
Otro método común es el algoritmo de optimización mínima secuencial (SMO) de Platt , que divide el problema en subproblemas bidimensionales que se resuelven analíticamente, eliminando la necesidad de un algoritmo de optimización numérica y de almacenamiento matricial. Este algoritmo es conceptualmente simple, fácil de implementar, generalmente más rápido y tiene mejores propiedades de escalamiento para problemas SVM difíciles. [45]
El caso especial de las máquinas de vectores de soporte lineales se puede resolver de manera más eficiente con el mismo tipo de algoritmos utilizados para optimizar su primo cercano, la regresión logística ; esta clase de algoritmos incluye el descenso de subgradiente (por ejemplo, PEGASOS [46] ) y el descenso de coordenadas (por ejemplo, LIBLINEAR [47] ). LIBLINEAR tiene algunas propiedades de tiempo de entrenamiento atractivas. Cada iteración de convergencia toma tiempo lineal en el tiempo que se tarda en leer los datos de entrenamiento, y las iteraciones también tienen una propiedad de convergencia Q-lineal , lo que hace que el algoritmo sea extremadamente rápido.
Los SVM de núcleo general también se pueden resolver de manera más eficiente utilizando el descenso de subgradiente (por ejemplo, P-packSVM [48] ), especialmente cuando se permite la paralelización .
Las SVM de kernel están disponibles en muchos kits de herramientas de aprendizaje automático, incluidos LIBSVM , MATLAB , SAS, SVMlight, kernlab, scikit-learn , Shogun , Weka , Shark, JKernelMachines, OpenCV y otros.
Se recomienda encarecidamente el preprocesamiento de datos (estandarización) para mejorar la precisión de la clasificación. [49] Existen algunos métodos de estandarización, como mínimo-máximo, normalización por escala decimal y puntuación Z. [50] La resta de la media y la división por la varianza de cada característica se utilizan generalmente para SVM. [51]
^ Vapnik, Vladimir N. (1997). "El método de vectores de soporte". En Gerstner, Wulfram; Germond, Alain; Hasler, Martin; Nicoud, Jean-Daniel (eds.). Redes neuronales artificiales — ICANN'97 . Apuntes de clase en informática. Vol. 1327. Berlín, Heidelberg: Springer. págs. 261–271. doi :10.1007/BFb0020166. ISBN978-3-540-69620-9.
^ Awad, Mariette; Khanna, Rahul (2015). "Máquinas de vectores de soporte para la clasificación". Efficient Learning Machines . Apress. págs. 39–66. doi : 10.1007/978-1-4302-5990-9_3 . ISBN978-1-4302-5990-9.
^ Ben-Hur, Asa; Cuerno, David; Siegelmann, Hava; Vapnik, Vladimir N.""Agrupamiento de vectores de soporte" (2001);". Revista de investigación en aprendizaje automático . 2 : 125–137.
^ "1.4. Máquinas de vectores de soporte — documentación de scikit-learn 0.20.2". Archivado desde el original el 8 de noviembre de 2017. Consultado el 8 de noviembre de 2017 .
^ Hastie, Trevor ; Tibshirani, Robert ; Friedman, Jerome (2008). Los elementos del aprendizaje estadístico: minería de datos, inferencia y predicción (PDF) (segunda edición). Nueva York: Springer. pág. 134.
^ abc Boser, Bernhard E.; Guyon, Isabelle M.; Vapnik, Vladimir N. (1992). "Un algoritmo de entrenamiento para clasificadores de margen óptimos". Actas del quinto taller anual sobre teoría del aprendizaje computacional – COLT '92 . p. 144. CiteSeerX 10.1.1.21.3818 . doi :10.1145/130385.130401. ISBN978-0897914970.S2CID207165665 .
^ Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (2007). "Sección 16.5. Máquinas de vectores de soporte". Recetas numéricas: el arte de la computación científica (3.ª ed.). Nueva York: Cambridge University Press. ISBN978-0-521-88068-8. Archivado desde el original el 11 de agosto de 2011.
^ Joachims, Thorsten (1998). "Categorización de texto con máquinas de vectores de soporte: aprendizaje con muchas características relevantes". Aprendizaje automático: ECML-98 . Lecture Notes in Computer Science. Vol. 1398. Springer. págs. 137–142. doi : 10.1007/BFb0026683 . ISBN.978-3-540-64417-0.
^ Pradhan, Sameer S.; et al. (2 de mayo de 2004). Análisis semántico superficial mediante máquinas de vectores de soporte. Actas de la Conferencia sobre tecnología del lenguaje humano del Capítulo norteamericano de la Asociación de Lingüística Computacional: HLT-NAACL 2004. Asociación de Lingüística Computacional. págs. 233–240.
^ Vapnik, Vladimir N.: Orador invitado. IPMU Procesamiento y gestión de la información 2014).
^ Barghout, Lauren (2015). "Gránulos de información de taxones espaciales utilizados en la toma de decisiones iterativa difusa para la segmentación de imágenes" (PDF) . Computación granular y toma de decisiones . Estudios en Big Data. Vol. 10. págs. 285–318. doi :10.1007/978-3-319-16829-6_12. ISBN978-3-319-16828-9. S2CID 4154772. Archivado desde el original (PDF) el 8 de enero de 2018. Consultado el 8 de enero de 2018 .
^ A. Maity (2016). "Clasificación supervisada de datos polarimétricos de RADARSAT-2 para diferentes características terrestres". arXiv : 1608.00501 [cs.CV].
^ DeCoste, Dennis (2002). "Entrenamiento de máquinas de vectores de soporte invariantes" (PDF) . Aprendizaje automático . 46 : 161–190. doi : 10.1023/A:1012454411458 . S2CID 85843.
^ Maitra, DS; Bhattacharya, U.; Parui, SK (agosto de 2015). "Enfoque común basado en CNN para el reconocimiento de caracteres manuscritos de múltiples escrituras". 2015 13.ª Conferencia Internacional sobre Análisis y Reconocimiento de Documentos (ICDAR) . pp. 1021–1025. doi :10.1109/ICDAR.2015.7333916. ISBN978-1-4799-1805-8. Número de identificación del sujeto 25739012.
^ Gaonkar, B.; Davatzikos, C. (2013). "Estimación analítica de mapas de significancia estadística para el análisis y clasificación de imágenes multivariadas basadas en máquinas de vectores de soporte". NeuroImage . 78 : 270–283. doi :10.1016/j.neuroimage.2013.03.066. PMC 3767485 . PMID 23583748.
^ Cuingnet, Rémi; Rosso, Charlotte; Chupin, Marie; Lehéricy, Stéphane; Dormont, Didier; Benali, Habib; Samson, Yves; Colliot, Olivier (2011). "Regularización espacial de SVM para la detección de alteraciones de difusión asociadas con el resultado del accidente cerebrovascular" (PDF) . Análisis de imágenes médicas . 15 (5): 729–737. doi :10.1016/j.media.2011.05.007. PMID 21752695. Archivado desde el original (PDF) el 2018-12-22 . Consultado el 2018-01-08 .
^ Statnikov, Alexander; Hardin, Douglas; y Aliferis, Constantin; (2006); "Uso de métodos basados en el peso de SVM para identificar variables causalmente relevantes y no causalmente relevantes", Sign , 1, 4.
^ "¿Por qué el margen SVM es igual a 2 ‖ w ‖ {\displaystyle {\frac {2}{\|\mathbf {w} \|}}} ". Mathematics Stack Exchange . 30 de mayo de 2015.
^ Aizerman, Mark A.; Braverman, Emmanuel M. y Rozonoer, Lev I. (1964). "Fundamentos teóricos del método de función potencial en el aprendizaje de reconocimiento de patrones". Automatización y control remoto . 25 : 821–837.
^ Jin, Chi; Wang, Liwei (2012). Límite de margen PAC-Bayes dependiente de la dimensionalidad. Avances en sistemas de procesamiento de información neuronal. CiteSeerX 10.1.1.420.3487 . Archivado desde el original el 2 de abril de 2015.
^ Shalev-Shwartz, Shai; Singer, Yoram; Srebro, Nathan; Cotter, Andrew (16 de octubre de 2010). "Pegasos: solucionador de subgradiente estimado primario para SVM". Programación matemática . 127 (1): 3–30. CiteSeerX 10.1.1.161.9629 . doi :10.1007/s10107-010-0420-4. ISSN 0025-5610. S2CID 53306004.
^ Hsieh, Cho-Jui; Chang, Kai-Wei; Lin, Chih-Jen; Keerthi, S. Sathiya; Sundararajan, S. (1 de enero de 2008). "Un método de descenso de coordenadas dual para SVM lineal a gran escala". Actas de la 25.ª conferencia internacional sobre aprendizaje automático - ICML '08 . Nueva York, NY, EE. UU.: ACM. págs. 408–415. CiteSeerX 10.1.1.149.5594 . doi :10.1145/1390156.1390208. ISBN .978-1-60558-205-4.S2CID 7880266 .
^ Rosasco, Lorenzo; De Vito, Ernesto; Caponnetto, Andrea; Piana, Michele; Verri, Alessandro (1 de mayo de 2004). "¿Son todas las funciones de pérdida iguales?". Computación neuronal . 16 (5): 1063–1076. CiteSeerX 10.1.1.109.6786 . doi :10.1162/089976604773135104. ISSN 0899-7667. PMID 15070510. S2CID 11845688.
^ R. Collobert y S. Bengio (2004). Vínculos entre perceptrones, MLP y SVM. Proc. Int'l Conf. on Machine Learning (ICML).
^ Meyer, David; Leisch, Friedrich; Hornik, Kurt (septiembre de 2003). "La máquina de vectores de soporte bajo prueba". Neurocomputing . 55 (1–2): 169–186. doi :10.1016/S0925-2312(03)00431-4.
^ Hsu, Chih-Wei; Chang, Chih-Chung y Lin, Chih-Jen (2003). A Practical Guide to Support Vector Classification (PDF) (Informe técnico). Departamento de Ciencias de la Computación e Ingeniería de la Información, Universidad Nacional de Taiwán. Archivado (PDF) desde el original el 25 de junio de 2013.
^ ab Duan, Kai-Bo; Keerthi, S. Sathiya (2005). "¿Cuál es el mejor método SVM multiclase? Un estudio empírico" (PDF) . Sistemas de clasificación múltiple . LNCS . Vol. 3541. págs. 278–285. CiteSeerX 10.1.1.110.6789 . doi :10.1007/11494683_28. ISBN .978-3-540-26306-7Archivado desde el original (PDF) el 3 de mayo de 2013. Consultado el 18 de julio de 2019 .
^ Hsu, Chih-Wei y Lin, Chih-Jen (2002). "Una comparación de métodos para máquinas de vectores de soporte multiclase" (PDF) . IEEE Transactions on Neural Networks . 13 (2): 415–25. doi :10.1109/72.991427. PMID 18244442. Archivado desde el original (PDF) el 2013-05-03 . Consultado el 2018-01-08 .
^ Platt, John; Cristianini, Nello ; Shawe-Taylor, John (2000). "DAG de margen grande para clasificación multiclase" (PDF) . En Solla, Sara A .; Leen, Todd K.; Müller, Klaus-Robert (eds.). Avances en sistemas de procesamiento de información neuronal . MIT Press. págs. 547–553. Archivado (PDF) desde el original el 16 de junio de 2012.
^ Dietterich, Thomas G.; Bakiri, Ghulum (1995). "Resolución de problemas de aprendizaje multiclase mediante códigos de salida de corrección de errores" (PDF) . Journal of Artificial Intelligence Research . 2 : 263–286. arXiv : cs/9501101 . Bibcode :1995cs........1101D. doi :10.1613/jair.105. S2CID 47109072. Archivado (PDF) desde el original el 2013-05-09.
^ Crammer, Koby y Singer, Yoram (2001). "Sobre la implementación algorítmica de máquinas vectoriales basadas en núcleo multiclase" (PDF) . Journal of Machine Learning Research . 2 : 265–292. Archivado (PDF) desde el original el 29 de agosto de 2015.
^ Lee, Yoonkyung; Lin, Yi y Wahba, Grace (2001). "Máquinas de vectores de soporte multicategoría" (PDF) . Ciencias de la computación y estadística . 33 . Archivado (PDF) desde el original el 17 de junio de 2013.
^ Lee, Yoonkyung; Lin, Yi; Wahba, Grace (2004). "Máquinas de vectores de soporte multicategoría". Revista de la Asociación Estadounidense de Estadística . 99 (465): 67–81. CiteSeerX 10.1.1.22.1879 . doi :10.1198/016214504000000098. S2CID 7066611.
^ Van den Burg, Gerrit JJ y Groenen, Patrick JF (2016). "GenSVM: una máquina de vectores de soporte multiclase generalizada" (PDF) . Revista de investigación sobre aprendizaje automático . 17 (224): 1–42.
^ Joachims, Thorsten. Inferencia transductiva para la clasificación de textos mediante máquinas de vectores de soporte (PDF) . Actas de la Conferencia internacional sobre aprendizaje automático de 1999 (ICML 1999). pp. 200–209.
^ https://www.cs.cornell.edu/people/tj/publications/tsochantaridis_etal_04a.pdf [ URL básica PDF ]
^ Drucker, Harris; Burges, Christ. C.; Kaufman, Linda; Smola, Alexander J.; y Vapnik, Vladimir N. (1997); "Máquinas de regresión de vectores de soporte", en Advances in Neural Information Processing Systems 9, NIPS 1996 , 155–161, MIT Press.
^ Suykens, Johan AK; Vandewalle, Joos PL; "Clasificadores de máquinas de vectores de soporte de mínimos cuadrados", Neural Processing Letters , vol. 9, núm. 3, junio de 1999, págs. 293–300.
^ Smola, Alex J.; Schölkopf, Bernhard (2004). "Un tutorial sobre regresión de vectores de soporte" (PDF) . Estadísticas y computación . 14 (3): 199–222. CiteSeerX 10.1.1.41.1452 . doi :10.1023/B:STCO.0000035301.49549.88. S2CID 15475. Archivado (PDF) desde el original el 2012-01-31.
^ Polson, Nicholas G.; Scott, Steven L. (2011). "Aumento de datos para máquinas de vectores de soporte". Análisis bayesiano . 6 (1): 1–23. doi : 10.1214/11-BA601 .
^ Wenzel, Florian; Galy-Fajou, Theo; Deutsch, Matthäus; Kloft, Marius (2017). "Máquinas de vectores de soporte no lineales bayesianas para big data". Aprendizaje automático y descubrimiento de conocimiento en bases de datos . Apuntes de clase en informática. Vol. 10534. págs. 307–322. arXiv : 1707.05532 . Código Bibliográfico :2017arXiv170705532W. doi :10.1007/978-3-319-71249-9_19. ISBN978-3-319-71248-2. Número de identificación del sujeto 4018290.
^ Florian Wenzel; Matthäus Deutsch; Théo Galy-Fajou; Marius Kloft; ”Inferencia aproximada escalable para la máquina de vectores de soporte no lineal bayesiana”
^ Ferris, Michael C.; Munson, Todd S. (2002). "Métodos de punto interior para máquinas de vectores de soporte masivos" (PDF) . Revista SIAM sobre optimización . 13 (3): 783–804. CiteSeerX 10.1.1.216.6893 . doi :10.1137/S1052623400374379. S2CID 13563302. Archivado (PDF) desde el original el 2008-12-04.
^ Platt, John C. (1998). Optimización mínima secuencial: un algoritmo rápido para entrenar máquinas de vectores de soporte (PDF) . NIPS. Archivado (PDF) desde el original el 2 de julio de 2015.
^ Shalev-Shwartz, Shai; Singer, Yoram; Srebro, Nathan (2007). Pegasos: Solución primaria estimada de subgradientes para SVM (PDF) . ICML. Archivado (PDF) desde el original el 15 de diciembre de 2013.
^ Fan, Rong-En; Chang, Kai-Wei; Hsieh, Cho-Jui; Wang, Xiang-Rui; Lin, Chih-Jen (2008). "LIBLINEAR: una biblioteca para la clasificación lineal de gran tamaño" (PDF) . Revista de investigación en aprendizaje automático . 9 : 1871–1874.
^ Allen Zhu, Zeyuan; Chen, Weizhu; Wang, Gang; Zhu, Chenguang; Chen, Zheng (2009). P-packSVM: SVM de núcleo descentante de gradiente primario paralelo (PDF) . ICDM. Archivado (PDF) desde el original el 7 de abril de 2014.
^ Fan, Rong-En; Chang, Kai-Wei; Hsieh, Cho-Jui; Wang, Xiang-Rui; Lin, Chih-Jen (2008). "LIBLINEAR: una biblioteca para la clasificación lineal de gran tamaño". Journal of Machine Learning Research . 9 (agosto): 1871–1874.
^ Mohamad, Ismail; Usman, Dauda (1 de septiembre de 2013). "Estandarización y sus efectos en el algoritmo de agrupamiento K-Means". Revista de investigación de ciencias aplicadas, ingeniería y tecnología . 6 (17): 3299–3303. doi : 10.19026/rjaset.6.3638 .
^ Fennell, Peter; Zuo, Zhiya; Lerman, Kristina (1 de diciembre de 2019). "Predicción y explicación de datos de comportamiento con descomposición del espacio de características estructurado". EPJ Data Science . 8 . arXiv : 1810.09841 . doi : 10.1140/epjds/s13688-019-0201-0 .
Lectura adicional
Bennett, Kristin P.; Campbell, Colin (2000). "Máquinas de vectores de soporte: ¿exageración o aleluya?" (PDF) . SIGKDD Explorations . 2 (2): 1–13. doi :10.1145/380995.380999. S2CID 207753020.
Cristianini, Nello; Shawe-Taylor, John (2000). Introducción a las máquinas de vectores de soporte y otros métodos de aprendizaje basados en kernel . Cambridge University Press. ISBN 0-521-78019-5.
Fradkin, Dmitriy; Muchnik, Ilya (2006). "Máquinas de vectores de soporte para la clasificación" (PDF) . En Abello, J.; Carmode, G. (eds.). Métodos discretos en epidemiología . Serie DIMACS en matemáticas discretas y ciencias de la computación teórica. Vol. 70. págs. 13–20.[ cita no encontrada ]
Joachims, Thorsten (1998). "Categorización de texto con máquinas de vectores de soporte: aprendizaje con muchas características relevantes". En Nédellec, Claire; Rouveirol, Céline (eds.). "Aprendizaje automático: ECML-98" . Lecture Notes in Computer Science. Vol. 1398. Berlín, Heidelberg: Springer. p. 137-142. doi :10.1007/BFb0026683. ISBN.978-3-540-64417-0. Número de identificación del sujeto 2427083.
Ivanciuc, Ovidiu (2007). "Aplicaciones de las máquinas de vectores de soporte en química" (PDF) . Reseñas en química computacional . 23 : 291–400. doi :10.1002/9780470116449.ch6. ISBN 9780470116449.
James, Gareth; Witten, Daniela; Hastie, Trevor; Tibshirani, Robert (2013). "Máquinas de vectores de soporte" (PDF) . Introducción al aprendizaje estadístico: con aplicaciones en R. Nueva York: Springer. pp. 337–372. ISBN.978-1-4614-7137-0.
Schölkopf, Bernhard; Smola, Alexander J. (2002). Aprendiendo con Kernels . Cambridge, MA: MIT Press. ISBN 0-262-19475-9.
Steinwart, Ingo; Christmann, Andreas (2008). Máquinas de vectores de soporte . Nueva York: Springer. ISBN 978-0-387-77241-7.
Theodoridis, Sergios; Koutroumbas, Konstantinos (2009). Reconocimiento de patrones (4.ª ed.). Academic Press. ISBN 978-1-59749-272-0.
Enlaces externos
libsvm, LIBSVM es una biblioteca popular entre los estudiantes de SVM
liblinear es una biblioteca para clasificación lineal grande que incluye algunas SVM
SVM light es una colección de herramientas de software para el aprendizaje y la clasificación mediante SVM
Demostración en vivo de SVMJS Archivado el 5 de mayo de 2013 en Wayback Machine es una demostración de GUI para la implementación de JavaScript de SVM
.svg/1280px-Svm_separating_hyperplanes_(SVG).svg.png)



































![{\displaystyle \lVert \mathbf {w} \rVert ^{2}+C\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(\mathbf {w} ^{\mathsf {T}}\mathbf {x} _{i}-b)\right)\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b5dc624654eef8f3a8994da013e19dd98774e28f)





















![{\displaystyle {\begin{aligned}&{\text{minimizar }}{\frac {1}{n}}\sum _{i=1}^{n}\zeta _{i}+\lambda \|\mathbf {w} \|^{2}\\[0.5ex]&{\text{sujeto a }}y_{i}\left(\mathbf {w} ^{\mathsf {T}}\mathbf {x} _{i}-b\right)\geq 1-\zeta _{i}\,{\text{ y }}\,\zeta _{i}\geq 0,\,{\text{para todo }}i.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/55f31fe5bcd9363b51ab5a4c4387202f32f047ee)













![{\displaystyle {\begin{aligned}b=\mathbf {w} ^{\mathsf {T}}\varphi (\mathbf {x} _{i})-y_{i}&=\left[\sum _ {j=1}^{n}c_{j}y_{j}\varphi (\mathbf {x} _{j})\cdot \varphi (\mathbf {x} _{i})\right]-y_ {i}\\&=\left[\sum _{j=1}^{n}c_{j}y_{j}k(\mathbf {x} _{j},\mathbf {x} _{i })\right]-y_{i}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/84f72e9d29c896b17db3c3640ed94a2395ef5ce8)
![{\displaystyle \mathbf {z} \mapsto \nombre_operador {sgn}(\mathbf {w} ^{\mathsf {T}}\varphi (\mathbf {z} )-b)=\nombre_operador {sgn} \left(\left[\sum _{i=1}^{n}c_{i}y_{i}k(\mathbf {x} _{i},\mathbf {z} )\right]-b\right).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5ad3c52254fc4372047bc849648b0b8554e47ab4)
![{\displaystyle f(\mathbf {w},b)=\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(\mathbf {w} ^{\mathsf {T}}\mathbf {x} _{i}-b)\right)\right]+\lambda \|\mathbf {w} \|^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/458eaac43a20c151eb9c977c96b6df2d6066bae9)











![{\displaystyle \varepsilon (f)=\mathbb {E} \left[\ell (y_{n+1},f(X_{n+1}))\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4b39a0005cd33d8ba9a9c9b18998577b32b6f519)









![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(\mathbf {w} ^{\mathsf {T}}\mathbf {x} -b)\right)\right]+\lambda \|\mathbf {w} \|^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/85d62a82b5412759d590dea809a53f63b41bb697)








![{\displaystyle f_{sq}(x)=\mathbb {E} \left[y_{x}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/db61f0b198879db710784726430ff7acf542d724)


















