Programación basada en flujo
Estos procesos de caja negra pueden ser reconectados un sinnúmero de veces para formar diferentes aplicaciones sin tener que ser cambiados internamente.
Los puertos pueden ser simples o de tipo matriz, como se usa por ejemplo para el puerto de entrada del componente intercalar que se describe a continuación.
Debido a que los procesos PBF pueden continuar ejecutándose siempre que tengan datos para trabajar y en algún lugar colocar su salida, las aplicaciones PBF generalmente se ejecutan en menos lapsos de tiempo que los programas convencionales y hacen un uso óptimo de todos los procesadores en una máquina sin necesidad de programación especial para lograrlo.
PBF es a menudo un lenguaje de programación visual en este nivel.
La programación basada en flujo fue inventada por Paul J. Morrison a comienzos de 1970, inicialmente implementó un software para un banco canadiense.
Dicho diagrama se puede convertir directamente en una lista de conexiones, que luego puede ejecutar un motor apropiado (software o hardware).
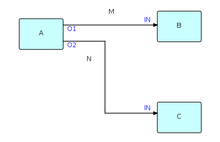
A, B y C son procesos que ejecutan componentes de código.
M y N son lo que a menudo se denominan "memorias intermedias limitadas" y tienen una capacidad fija en términos de la cantidad de IP que pueden tener en cualquier momento.
[12] Las IP suelen ser fragmentos estructurados de datos; sin embargo, algunas IP pueden no contener datos reales, sino que se utilizan simplemente como señales.
El sistema de conexiones y procesos descritos anteriormente puede "ramificarse" a cualquier tamaño.
PBF por lo tanto se presta a la creación rápida de prototipos .
Las "máquinas" se pueden volver a conectar fácilmente, desconectar para repararlas, reemplazarlas, etc.
En PBF, por otro lado, la descripción del problema en sí sugiere una solución: Aquí está la solución más natural en PBF (no hay una única solución "correcta" en PBF, pero esto parece un ajuste natural): donde DC y RC significan "Descomponer" y "Recomponer", respectivamente.
Los PII son fragmentos de datos asociados con un puerto en la definición de red que se convierten en IP "normales" cuando se emite una "recepción" para el puerto correspondiente.
En este esquema general, las solicitudes (transacciones) de los usuarios ingresan al diagrama en la esquina superior izquierda y las respuestas se devuelven en la esquina inferior izquierda.
Los "back-ends" (en el lado derecho) se comunican con los sistemas en otros sitios, por ejemplo, utilizando CORBA, MQSeries, etc.
Además, los bloques en el diagrama pueden representar "subredes": redes pequeñas con una o más conexiones abiertas.
Esta metodología supone que un programa debe ser estructurado como una jerarquía procesal única de subrutinas.
Jackson analiza la posibilidad de ejecutar directamente el modelo de red que existe antes de este paso, en la sección 1.3 de su libro (cursiva agregada): MA Jackson reconoció la PBF como un enfoque que sigue su método de "Descomposición del programa en procesos secuenciales que se comunican mediante un mecanismo similar a la corutina" [15] WB Ackerman define un lenguaje aplicativo como aquel que realiza todo su procesamiento mediante operadores aplicados a valores.
Estas funciones se combinan para hacer transformaciones más complejas, como se muestra aquí: Si etiquetamos las secuencias, como se muestra, con letras minúsculas, entonces el diagrama anterior se puede representar sucintamente de la siguiente manera: Al igual que en la notación funcional, F se puede usar dos veces porque solo funciona con valores y, por lo tanto, no tiene efectos secundarios, en la PBF dos instancias de un componente dado pueden ejecutarse simultáneamente entre sí y, por lo tanto, los componentes de la PBF no deben tener efectos secundarios ya sea.
Esto permite que una transmisión se realice dinámicamente desde el frente, pero con un back-end no realizado.
Un objeto en POO puede describirse como una unidad semiautónoma que comprende información y comportamiento.
Solo se puede acceder a los datos internos del objeto mediante llamadas a métodos, por lo que esta es una forma de ocultación de información o "encapsulación".
La encapsulación, sin embargo, es anterior a POO: David Parnas escribió uno de los artículos fundamentales sobre ella a principios de los años 70,[18] y es un concepto básico en informática.
Además, solo se puede acceder directamente a los datos en una IP mediante el proceso actual.
La encapsulación también se puede implementar a nivel de red, haciendo que los procesos externos protejan los internos.