
En estadística , la desviación estándar es una medida de la cantidad de variación de los valores de una variable con respecto a su media . [1] Una desviación estándar baja indica que los valores tienden a estar cerca de la media (también llamada valor esperado ) del conjunto, mientras que una desviación estándar alta indica que los valores están distribuidos en un rango más amplio. La desviación estándar se utiliza comúnmente para determinar qué constituye un valor atípico y qué no.
La desviación estándar puede abreviarse como SD , y generalmente se representa en textos y ecuaciones matemáticas con la letra griega minúscula σ (sigma), para la desviación estándar de la población, o la letra latina s , para la desviación estándar de la muestra.
La desviación estándar de una variable aleatoria , muestra , población estadística , conjunto de datos o distribución de probabilidad es la raíz cuadrada de su varianza. Es algebraicamente más simple, aunque en la práctica menos robusta , que la desviación absoluta promedio . [2] [3] Una propiedad útil de la desviación estándar es que, a diferencia de la varianza, se expresa en la misma unidad que los datos.
La desviación estándar de una población o muestra y el error estándar de una estadística (por ejemplo, de la media de la muestra) son bastante diferentes, pero están relacionados. El error estándar de la media de la muestra es la desviación estándar del conjunto de medias que se encontraría extrayendo un número infinito de muestras repetidas de la población y calculando una media para cada muestra. El error estándar de la media resulta ser igual a la desviación estándar de la población dividida por la raíz cuadrada del tamaño de la muestra, y se estima utilizando la desviación estándar de la muestra dividida por la raíz cuadrada del tamaño de la muestra. Por ejemplo, el error estándar de una encuesta (lo que se informa como el margen de error de la encuesta), es la desviación estándar esperada de la media estimada si la misma encuesta se realizara varias veces. Por lo tanto, el error estándar estima la desviación estándar de una estimación, que a su vez mide cuánto depende la estimación de la muestra particular que se tomó de la población.
En ciencia , es común informar tanto la desviación estándar de los datos (como estadística de resumen) como el error estándar de la estimación (como medida del error potencial en los hallazgos). Por convención, solo los efectos que se alejan más de dos errores estándar de una expectativa nula se consideran "estadísticamente significativos" , una salvaguarda contra conclusiones falsas que en realidad se deben a un error de muestreo aleatorio.
Cuando sólo se dispone de una muestra de datos de una población, el término desviación estándar de la muestra o desviación estándar de la muestra puede referirse a la cantidad mencionada anteriormente tal como se aplica a esos datos, o a una cantidad modificada que es una estimación imparcial de la desviación estándar de la población (la desviación estándar de toda la población).
Supongamos que la población total de interés está formada por ocho estudiantes de una clase determinada. Para un conjunto finito de números, la desviación estándar de la población se obtiene tomando la raíz cuadrada del promedio de las desviaciones al cuadrado de los valores restados de su valor promedio. Las notas de una clase de ocho estudiantes (es decir, una población estadística ) son los ocho valores siguientes:
Estos ocho puntos de datos tienen una media (promedio) de 5:
Primero, calcula las desviaciones de cada punto de datos con respecto a la media y eleva al cuadrado el resultado de cada uno:
La varianza es la media de estos valores:
y la desviación estándar de la población es igual a la raíz cuadrada de la varianza:
Esta fórmula es válida solo si los ocho valores con los que comenzamos forman la población completa. Si los valores en cambio fueran una muestra aleatoria extraída de una gran población parental (por ejemplo, fueran 8 estudiantes elegidos aleatoriamente e independientemente de una clase de 2 millones), entonces uno divide por 7 (que es n − 1) en lugar de 8 (que es n ) en el denominador de la última fórmula, y el resultado es En ese caso, el resultado de la fórmula original se llamaría desviación estándar de la muestra y se denotaría por en lugar de Dividir por en lugar de por da una estimación no sesgada de la varianza de la población parental más grande. Esto se conoce como corrección de Bessel . [4] [5] Aproximadamente, la razón es que la fórmula para la varianza de la muestra se basa en el cálculo de las diferencias de las observaciones a partir de la media de la muestra, y la media de la muestra en sí se construyó para que fuera lo más cercana posible a las observaciones, por lo que simplemente dividir por n subestimaría la variabilidad.
Si la población de interés se distribuye de forma aproximadamente normal, la desviación estándar proporciona información sobre la proporción de observaciones por encima o por debajo de ciertos valores. Por ejemplo, la altura media de los hombres adultos en los Estados Unidos es de aproximadamente 69 pulgadas , [6] con una desviación estándar de alrededor de 3 pulgadas . Esto significa que la mayoría de los hombres (alrededor del 68 %, suponiendo una distribución normal ) tienen una altura dentro de las 3 pulgadas de la media ( 66–72 pulgadas ) -una desviación estándar- y casi todos los hombres (alrededor del 95 %) tienen una altura dentro de las 6 pulgadas de la media ( 63–75 pulgadas ) -dos desviaciones estándar-. Si la desviación estándar fuera cero, entonces todos los hombres compartirían una altura idéntica de 69 pulgadas. Tres desviaciones estándar representan el 99,73 % de la población de muestra que se está estudiando, suponiendo que la distribución es normal o en forma de campana (consulte la regla 68–95–99,7 , o la regla empírica, para obtener más información).
Sea μ el valor esperado (el promedio) de la variable aleatoria X con densidad f ( x ) : La desviación estándar σ de X se define como que se puede demostrar que es igual
Usando palabras , la desviación estándar es la raíz cuadrada de la varianza de X.
La desviación estándar de una distribución de probabilidad es la misma que la de una variable aleatoria que tiene esa distribución.
No todas las variables aleatorias tienen una desviación estándar. Si la distribución tiene colas gruesas que se extienden hasta el infinito, la desviación estándar podría no existir, porque la integral podría no converger. La distribución normal tiene colas que se extienden hasta el infinito, pero su media y desviación estándar sí existen, porque las colas disminuyen con la suficiente rapidez. La distribución de Pareto con parámetro tiene una media, pero no una desviación estándar (en términos generales, la desviación estándar es infinita). La distribución de Cauchy no tiene ni media ni desviación estándar.
En el caso en que X toma valores aleatorios de un conjunto de datos finito x 1 , x 2 , ..., x N , y cada valor tiene la misma probabilidad, la desviación estándar es
Nota: La expresión anterior tiene un sesgo incorporado. Véase el análisis de la corrección de Bessel más abajo.
o, utilizando la notación de suma ,
Si, en lugar de tener probabilidades iguales, los valores tienen probabilidades diferentes, sea x 1 con probabilidad p 1 , x 2 con probabilidad p 2 , ..., x N con probabilidad p N . En este caso, la desviación estándar será
La desviación estándar de una variable aleatoria continua de valor real X con función de densidad de probabilidad p ( x ) es
y donde las integrales son integrales definidas tomadas para x que abarcan el conjunto de valores posibles de la variable aleatoria X.
En el caso de una familia paramétrica de distribuciones , la desviación típica se puede expresar en términos de los parámetros. Por ejemplo, en el caso de la distribución log-normal con parámetros μ y σ 2 , la desviación típica es
Se puede encontrar la desviación estándar de una población entera en casos (como en las pruebas estandarizadas ) en los que se toma una muestra de cada miembro de una población. En los casos en los que esto no se puede hacer, la desviación estándar σ se estima examinando una muestra aleatoria tomada de la población y calculando una estadística de la muestra, que se utiliza como una estimación de la desviación estándar de la población. Dicha estadística se denomina estimador , y el estimador (o el valor del estimador, es decir, la estimación) se denomina desviación estándar de la muestra y se denota por s (posiblemente con modificadores).
A diferencia del caso de la estimación de la media poblacional de una distribución normal, para la cual la media muestral es un estimador simple con muchas propiedades deseables ( imparcial , eficiente , máxima verosimilitud), no existe un estimador único para la desviación estándar con todas estas propiedades, y la estimación imparcial de la desviación estándar es un problema muy complejo desde el punto de vista técnico. La mayoría de las veces, la desviación estándar se estima utilizando la desviación estándar muestral corregida (utilizando N − 1), definida a continuación, y a esto a menudo se le denomina "desviación estándar muestral", sin calificadores. Sin embargo, otros estimadores son mejores en otros aspectos: el estimador no corregido (utilizando N ) produce un error cuadrático medio menor, mientras que el uso de N − 1,5 (para la distribución normal) elimina casi por completo el sesgo.
La fórmula para la desviación estándar de la población (de una población finita) se puede aplicar a la muestra, utilizando el tamaño de la muestra como el tamaño de la población (aunque el tamaño real de la población de la que se extrae la muestra puede ser mucho mayor). Este estimador, denotado por s N , se conoce como desviación estándar de la muestra no corregida o, a veces, desviación estándar de la muestra (considerada como la población completa), y se define de la siguiente manera: [7]
donde son los valores observados de los elementos de la muestra, y es el valor medio de estas observaciones, mientras que el denominador N representa el tamaño de la muestra: esta es la raíz cuadrada de la varianza de la muestra, que es el promedio de las desviaciones al cuadrado sobre la media de la muestra.
Este es un estimador consistente (converge en probabilidad al valor de la población a medida que el número de muestras tiende a infinito), y es la estimación de máxima verosimilitud cuando la población se distribuye normalmente. [8] Sin embargo, este es un estimador sesgado , ya que las estimaciones son generalmente demasiado bajas. El sesgo disminuye a medida que aumenta el tamaño de la muestra, cayendo a 1/ N , y por lo tanto es más significativo para tamaños de muestra pequeños o moderados; para el sesgo es inferior al 1%. Por lo tanto, para tamaños de muestra muy grandes, la desviación estándar de la muestra sin corregir es generalmente aceptable. Este estimador también tiene un error cuadrático medio uniformemente menor que la desviación estándar de la muestra corregida.
Si se utiliza la varianza de muestra sesgada (el segundo momento central de la muestra, que es una estimación sesgada hacia abajo de la varianza de la población) para calcular una estimación de la desviación estándar de la población, el resultado es
En este caso, la extracción de la raíz cuadrada introduce un sesgo descendente adicional, debido a la desigualdad de Jensen , debido a que la raíz cuadrada es una función cóncava . El sesgo en la varianza se corrige fácilmente, pero el sesgo de la raíz cuadrada es más difícil de corregir y depende de la distribución en cuestión.
Se obtiene un estimador imparcial de la varianza aplicando la corrección de Bessel , utilizando N − 1 en lugar de N para obtener la varianza de muestra imparcial, denotada s 2 :
Este estimador es insesgado si existe varianza y los valores de la muestra se extraen de forma independiente con reemplazo. N − 1 corresponde al número de grados de libertad en el vector de desviaciones de la media,
Al tomar raíces cuadradas se vuelve a introducir un sesgo (porque la raíz cuadrada es una función no lineal que no conmuta con la expectativa, es decir, a menudo ), lo que produce la desviación estándar de la muestra corregida, denotada por s:
Como se explicó anteriormente, si bien s 2 es un estimador insesgado de la varianza de la población, s sigue siendo un estimador sesgado de la desviación estándar de la población, aunque notablemente menos sesgado que la desviación estándar de la muestra sin corregir. Este estimador se utiliza comúnmente y se conoce simplemente como "desviación estándar de la muestra". El sesgo puede seguir siendo grande para muestras pequeñas ( N menor que 10). A medida que aumenta el tamaño de la muestra, la cantidad de sesgo disminuye. Obtenemos más información y la diferencia entre y se vuelve más pequeña.
Para la estimación imparcial de la desviación estándar , no existe una fórmula que funcione en todas las distribuciones, a diferencia de la media y la varianza. En cambio, se utiliza s como base y se escala mediante un factor de corrección para producir una estimación imparcial. Para la distribución normal, un estimador imparcial viene dado por s/c 4 , donde el factor de corrección (que depende de N ) se da en términos de la función Gamma , y es igual a:
Esto surge porque la distribución de muestreo de la desviación estándar de la muestra sigue una distribución chi (escalada) y el factor de corrección es la media de la distribución chi.
Se puede dar una aproximación reemplazando N − 1 por N − 1,5 , obteniendo:
El error en esta aproximación decae cuadráticamente ( como1/N.º 2 ), y es adecuado para todas las muestras excepto las más pequeñas o de mayor precisión: para N = 3, el sesgo es igual al 1,3%, y para N = 9, el sesgo ya es inferior al 0,1%.
Una aproximación más precisa es reemplazar N − 1,5 anterior por N − 1,5 + 1/8( N -1) . [9]
Para otras distribuciones, la fórmula correcta depende de la distribución, pero una regla general es utilizar el refinamiento adicional de la aproximación:
donde γ 2 denota el exceso de curtosis de la población . El exceso de curtosis puede conocerse de antemano para ciertas distribuciones o estimarse a partir de los datos. [10]
La desviación típica que obtenemos al muestrear una distribución no es en sí misma absolutamente exacta, tanto por razones matemáticas (explicadas aquí por el intervalo de confianza) como por razones prácticas de medición (error de medición). El efecto matemático puede describirse mediante el intervalo de confianza o IC.
Para demostrar cómo una muestra más grande hará que el intervalo de confianza sea más estrecho, considere los siguientes ejemplos: Una población pequeña de N = 2 tiene solo un grado de libertad para estimar la desviación estándar. El resultado es que un IC del 95% de la desviación estándar va desde 0,45 × DE hasta 31,9 × DE; los factores aquí son los siguientes :
donde es el cuartil p de la distribución chi-cuadrado con k grados de libertad, y 1 − α es el nivel de confianza. Esto es equivalente a lo siguiente:
Con k = 1 , q 0,025 = 0,000982 y q 0,975 = 5,024 . Los recíprocos de las raíces cuadradas de estos dos números nos dan los factores 0,45 y 31,9 indicados anteriormente.
Una población mayor de N = 10 tiene 9 grados de libertad para estimar la desviación estándar. Los mismos cálculos que los anteriores nos dan en este caso un IC del 95 % que va desde 0,69 × DE hasta 1,83 × DE. Por lo tanto, incluso con una población de muestra de 10, la DE real puede ser casi un factor 2 mayor que la DE muestreada. Para una población de muestra N = 100 , esto se reduce a 0,88 × DE hasta 1,16 × DE. Para estar más seguros de que la DE muestreada está cerca de la DE real, necesitamos muestrear una gran cantidad de puntos.
Estas mismas fórmulas se pueden utilizar para obtener intervalos de confianza sobre la varianza de los residuos a partir de un ajuste de mínimos cuadrados bajo la teoría normal estándar, donde k es ahora el número de grados de libertad para el error.
Para un conjunto de N > 4 datos que abarcan un rango de valores R , un límite superior en la desviación estándar s viene dado por s = 0,6 R . [11] Una estimación de la desviación estándar para N > 100 datos tomados como aproximadamente normales se deduce de la heurística de que el 95% del área bajo la curva normal se encuentra aproximadamente a dos desviaciones estándar a cada lado de la media, de modo que, con una probabilidad del 95%, el rango total de valores R representa cuatro desviaciones estándar, de modo que s ≈ R /4 . Esta denominada regla de rango es útil en la estimación del tamaño de la muestra , ya que el rango de valores posibles es más fácil de estimar que la desviación estándar. Otros divisores K ( N ) del rango tales que s ≈ R / K ( N ) están disponibles para otros valores de N y para distribuciones no normales. [12]
La desviación estándar es invariante ante cambios de ubicación y escala directamente con la escala de la variable aleatoria. Por lo tanto, para una constante c y variables aleatorias X e Y :
La desviación estándar de la suma de dos variables aleatorias se puede relacionar con sus desviaciones estándar individuales y la covarianza entre ellas:
donde y representan varianza y covarianza , respectivamente.
El cálculo de la suma de las desviaciones al cuadrado se puede relacionar con los momentos calculados directamente a partir de los datos. En la siguiente fórmula, la letra E se interpreta como valor esperado, es decir, media.
La desviación estándar de la muestra se puede calcular como:
Para una población finita con probabilidades iguales en todos los puntos, tenemos
lo que significa que la desviación estándar es igual a la raíz cuadrada de la diferencia entre el promedio de los cuadrados de los valores y el cuadrado del valor promedio.
Consulte la fórmula de cálculo para la varianza como prueba y para obtener un resultado análogo para la desviación estándar de la muestra.

Una desviación estándar grande indica que los puntos de datos pueden dispersarse lejos de la media y una desviación estándar pequeña indica que están agrupados estrechamente alrededor de la media.
Por ejemplo, cada una de las tres poblaciones {0, 0, 14, 14}, {0, 6, 8, 14} y {6, 6, 8, 8} tiene una media de 7. Sus desviaciones típicas son 7, 5 y 1, respectivamente. La tercera población tiene una desviación típica mucho menor que las otras dos porque sus valores están todos cerca de 7. Estas desviaciones típicas tienen las mismas unidades que los propios puntos de datos. Si, por ejemplo, el conjunto de datos {0, 6, 8, 14} representa las edades de una población de cuatro hermanos en años, la desviación típica es de 5 años. Como otro ejemplo, la población {1000, 1006, 1008, 1014} puede representar las distancias recorridas por cuatro atletas, medidas en metros. Tiene una media de 1007 metros y una desviación típica de 5 metros.
La desviación estándar puede servir como medida de incertidumbre. En la ciencia física, por ejemplo, la desviación estándar informada de un grupo de mediciones repetidas proporciona la precisión de esas mediciones. Al decidir si las mediciones concuerdan con una predicción teórica, la desviación estándar de esas mediciones es de importancia crucial: si la media de las mediciones está demasiado alejada de la predicción (y la distancia se mide en desviaciones estándar), entonces probablemente sea necesario revisar la teoría que se está probando. Esto tiene sentido, ya que quedan fuera del rango de valores que se podría esperar razonablemente que ocurrieran si la predicción fuera correcta y la desviación estándar se cuantificara adecuadamente. Véase intervalo de predicción .
Si bien la desviación estándar mide la distancia que los valores típicos tienden a tener respecto de la media, existen otras medidas disponibles. Un ejemplo es la desviación absoluta media , que podría considerarse una medida más directa de la distancia promedio, en comparación con la distancia cuadrática media inherente a la desviación estándar.
El valor práctico de comprender la desviación estándar de un conjunto de valores radica en apreciar cuánta variación hay con respecto al promedio (media).
La desviación estándar se utiliza a menudo para comparar datos del mundo real con un modelo para probar el modelo. Por ejemplo, en aplicaciones industriales, el peso de los productos que salen de una línea de producción puede tener que cumplir con un valor requerido por ley. Al pesar una fracción de los productos, se puede encontrar un peso promedio, que siempre será ligeramente diferente del promedio a largo plazo. Al utilizar desviaciones estándar, se puede calcular un valor mínimo y máximo que indica que el peso promedio estará dentro de un porcentaje muy alto del tiempo (99,9 % o más). Si está fuera del rango, es posible que sea necesario corregir el proceso de producción. Las pruebas estadísticas como estas son particularmente importantes cuando la prueba es relativamente costosa. Por ejemplo, si el producto necesita abrirse, drenarse y pesarse, o si el producto se agotó de alguna otra manera durante la prueba.
En la ciencia experimental se utiliza un modelo teórico de la realidad. La física de partículas utiliza convencionalmente un estándar de " 5 sigma " para la declaración de un descubrimiento. Un nivel de cinco sigma se traduce en una probabilidad entre 3,5 millones de que una fluctuación aleatoria produzca el resultado. Este nivel de certeza era necesario para afirmar que se había descubierto una partícula compatible con el bosón de Higgs en dos experimentos independientes en el CERN , [13] lo que también llevó a la declaración de la primera observación de ondas gravitacionales . [14]
Como ejemplo sencillo, consideremos las temperaturas máximas diarias promedio de dos ciudades, una en el interior y otra en la costa. Es útil entender que el rango de temperaturas máximas diarias para las ciudades cercanas a la costa es menor que para las ciudades del interior. Por lo tanto, si bien estas dos ciudades pueden tener la misma temperatura máxima promedio, la desviación estándar de la temperatura máxima diaria para la ciudad costera será menor que la de la ciudad del interior, ya que, en un día en particular, es más probable que la temperatura máxima real esté más alejada de la temperatura máxima promedio para la ciudad del interior que para la ciudad de la costa.
En finanzas, la desviación típica se utiliza a menudo como una medida del riesgo asociado con las fluctuaciones de precios de un activo determinado (acciones, bonos, propiedades, etc.), o el riesgo de una cartera de activos [15] (fondos mutuos gestionados activamente, fondos mutuos indexados o ETF). El riesgo es un factor importante para determinar cómo gestionar eficientemente una cartera de inversiones porque determina la variación en los rendimientos del activo o la cartera y proporciona a los inversores una base matemática para las decisiones de inversión (conocida como optimización de media-varianza ). El concepto fundamental del riesgo es que a medida que aumenta, el rendimiento esperado de una inversión también debería aumentar, un aumento conocido como la prima de riesgo. En otras palabras, los inversores deberían esperar un mayor rendimiento de una inversión cuando esa inversión conlleva un mayor nivel de riesgo o incertidumbre. Al evaluar las inversiones, los inversores deben estimar tanto el rendimiento esperado como la incertidumbre de los rendimientos futuros. La desviación típica proporciona una estimación cuantificada de la incertidumbre de los rendimientos futuros.
Por ejemplo, supongamos que un inversor tuviera que elegir entre dos acciones. La acción A en los últimos 20 años tuvo un rendimiento promedio del 10 por ciento, con una desviación estándar de 20 puntos porcentuales (pp) y la acción B, durante el mismo período, tuvo rendimientos promedio del 12 por ciento pero una desviación estándar más alta de 30 pp. Sobre la base del riesgo y el rendimiento, un inversor puede decidir que la acción A es la opción más segura, porque los dos puntos porcentuales adicionales de rendimiento de la acción B no valen la desviación estándar adicional de 10 pp (mayor riesgo o incertidumbre del rendimiento esperado). Es probable que la acción B no alcance la inversión inicial (pero también la supere) con más frecuencia que la acción A en las mismas circunstancias, y se estima que solo rinde un dos por ciento más en promedio. En este ejemplo, se espera que la acción A gane alrededor del 10 por ciento, más o menos 20 pp (un rango de 30 por ciento a -10 por ciento), aproximadamente dos tercios de los rendimientos del año futuro. Al considerar posibles retornos o resultados más extremos en el futuro, un inversor debería esperar resultados de hasta un 10 por ciento más o menos 60 pp, o un rango de 70 por ciento a -50 por ciento, que incluye resultados para tres desviaciones estándar del retorno promedio (alrededor del 99,7 por ciento de los retornos probables).
Calcular el promedio (o la media aritmética) de la rentabilidad de un valor durante un período determinado generará la rentabilidad esperada del activo. Para cada período, restar la rentabilidad esperada de la rentabilidad real da como resultado la diferencia con la media. Elevar al cuadrado la diferencia en cada período y tomar la media da como resultado la varianza general de la rentabilidad del activo. Cuanto mayor sea la varianza, mayor será el riesgo que conlleva el valor. Hallar la raíz cuadrada de esta varianza dará como resultado la desviación estándar de la herramienta de inversión en cuestión.
Se sabe que las series temporales financieras son series no estacionarias, mientras que los cálculos estadísticos anteriores, como la desviación estándar, se aplican únicamente a las series estacionarias. Para aplicar las herramientas estadísticas anteriores a las series no estacionarias, primero se debe transformar la serie en una serie estacionaria, lo que permite el uso de herramientas estadísticas que ahora tienen una base válida a partir de la cual trabajar.
Para obtener algunas ideas y aclaraciones geométricas, comenzaremos con una población de tres valores, x 1 , x 2 , x 3 . Esto define un punto P = ( x 1 , x 2 , x 3 ) en R 3 . Considere la línea L = {( r , r , r ) : r ∈ R } . Esta es la "diagonal principal" que pasa por el origen. Si nuestros tres valores dados fueran todos iguales, entonces la desviación estándar sería cero y P estaría en L . Por lo tanto, no es ilógico suponer que la desviación estándar está relacionada con la distancia de P a L . Ese es de hecho el caso. Para moverse ortogonalmente desde L al punto P , uno comienza en el punto:
cuyas coordenadas son la media de los valores con los que comenzamos.
Un poco de álgebra muestra que la distancia entre P y M (que es la misma que la distancia ortogonal entre P y la línea L ) es igual a la desviación estándar del vector ( x 1 , x 2 , x 3 ) multiplicada por la raíz cuadrada del número de dimensiones del vector (3 en este caso).
Una observación rara vez se encuentra a más de unas pocas desviaciones estándar de la media. La desigualdad de Chebyshev garantiza que, para todas las distribuciones para las que se define la desviación estándar, la cantidad de datos dentro de un cierto número de desviaciones estándar de la media sea al menos la misma que se indica en la siguiente tabla.
El teorema del límite central establece que la distribución de un promedio de muchas variables aleatorias independientes distribuidas de manera idéntica tiende hacia la famosa distribución normal en forma de campana con una función de densidad de probabilidad de
donde μ es el valor esperado de las variables aleatorias, σ es igual a la desviación estándar de su distribución dividida por n 1 ⁄ 2 y n es el número de variables aleatorias. Por lo tanto, la desviación estándar es simplemente una variable de escala que ajusta la amplitud de la curva, aunque también aparece en la constante de normalización .
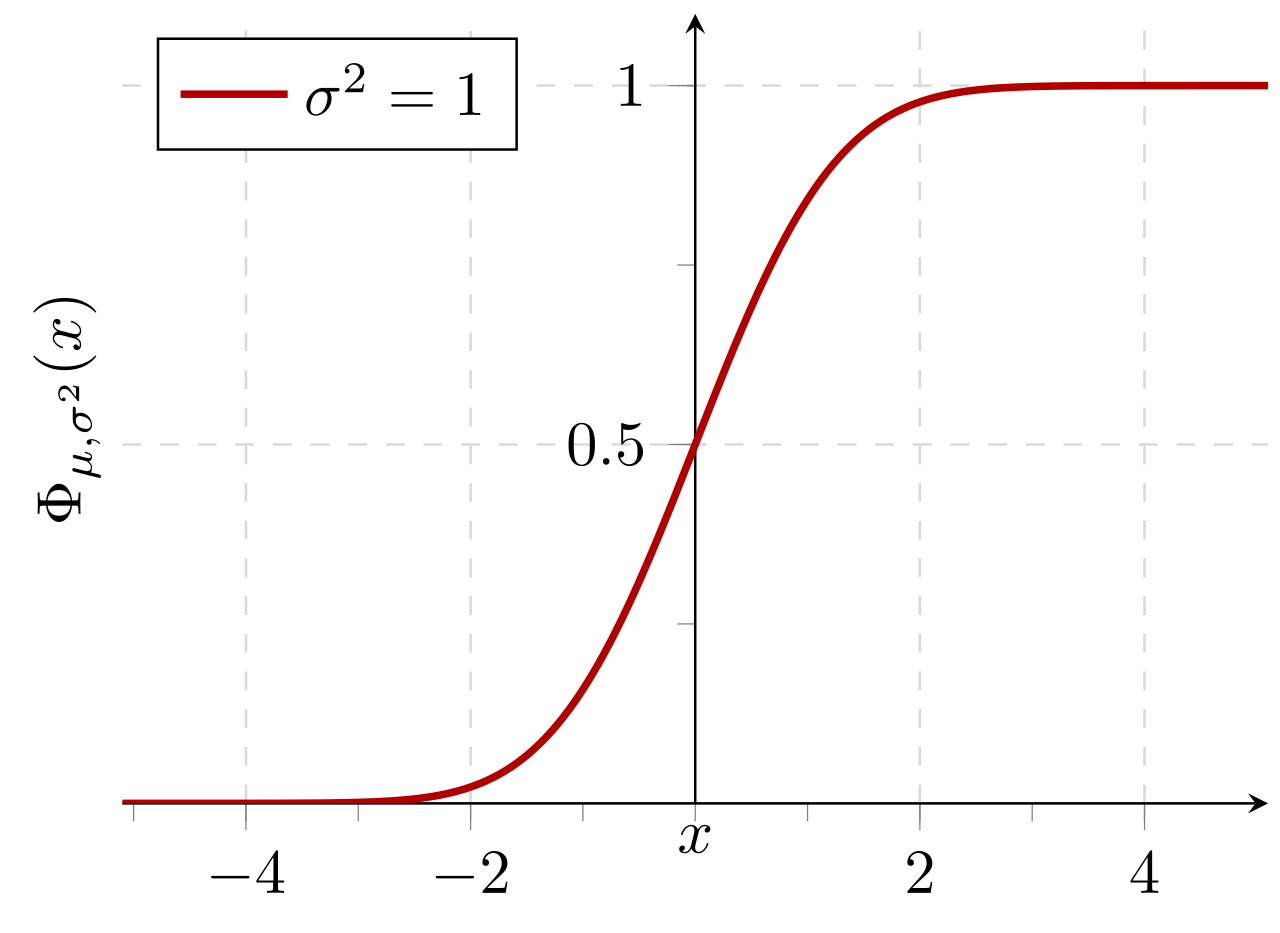
Si una distribución de datos es aproximadamente normal, entonces la proporción de valores de datos dentro de z desviaciones estándar de la media se define por:
donde es la función de error . La proporción que es menor o igual a un número, x , está dada por la función de distribución acumulativa : [17]
Si una distribución de datos es aproximadamente normal, entonces aproximadamente el 68 por ciento de los valores de los datos están dentro de una desviación estándar de la media (matemáticamente, μ ± σ , donde μ es la media aritmética), aproximadamente el 95 por ciento están dentro de dos desviaciones estándar ( μ ± 2 σ ), y aproximadamente el 99,7 por ciento se encuentran dentro de tres desviaciones estándar ( μ ± 3 σ ). Esto se conoce como la regla 68-95-99,7 o la regla empírica .
Para varios valores de z , el porcentaje de valores que se espera que se encuentren dentro y fuera del intervalo simétrico, CI = (− z σ , z σ ) , son los siguientes:


La media y la desviación típica de un conjunto de datos son estadísticas descriptivas que suelen presentarse juntas. En cierto sentido, la desviación típica es una medida "natural" de dispersión estadística si el centro de los datos se mide en torno a la media. Esto se debe a que la desviación típica con respecto a la media es menor que con respecto a cualquier otro punto. La afirmación precisa es la siguiente: supongamos que x 1 , ..., x n son números reales y definamos la función:
Utilizando cálculo o completando el cuadrado , es posible demostrar que σ ( r ) tiene un mínimo único en la media:
La variabilidad también se puede medir mediante el coeficiente de variación , que es la relación entre la desviación estándar y la media. Es un número adimensional .
A menudo, queremos obtener información sobre la precisión de la media que obtuvimos. Podemos obtenerla determinando la desviación estándar de la media muestreada. Suponiendo que los valores de la muestra son independientes estadísticamente, la desviación estándar de la media está relacionada con la desviación estándar de la distribución mediante:
donde N es el número de observaciones en la muestra utilizada para estimar la media. Esto se puede demostrar fácilmente con (ver propiedades básicas de la varianza ):
(Se supone independencia estadística).
por eso
Resultando en:
Para estimar la desviación típica de la media σ , es necesario conocer de antemano la desviación típica de toda la población σ . Sin embargo, en la mayoría de las aplicaciones, este parámetro es desconocido. Por ejemplo, si se realiza una serie de 10 mediciones de una cantidad previamente desconocida en un laboratorio, es posible calcular la media de la muestra resultante y la desviación típica de la muestra, pero es imposible calcular la desviación típica de la media. Sin embargo, se puede estimar la desviación típica de toda la población a partir de la muestra y, de este modo, obtener una estimación del error típico de la media.
Las dos fórmulas siguientes pueden representar una desviación estándar continua (actualizada repetidamente). Se calcula un conjunto de dos sumas de potencias s 1 y s 2 sobre un conjunto de N valores de x , denotados como x 1 , ..., x N :
Dados los resultados de estas sumas móviles, los valores N , s1 , s2 se pueden utilizar en cualquier momento para calcular el valor actual de la desviación estándar móvil:
Donde N , como se mencionó anteriormente, es el tamaño del conjunto de valores (o también puede considerarse como s 0 ).
De manera similar, para la desviación estándar de la muestra,
En una implementación informática, a medida que las dos sumas s j se hacen grandes, debemos considerar el error de redondeo , el desbordamiento aritmético y el desbordamiento aritmético . El método siguiente calcula el método de sumas continuas con errores de redondeo reducidos. [18] Este es un algoritmo de "una pasada" para calcular la varianza de n muestras sin la necesidad de almacenar datos anteriores durante el cálculo. La aplicación de este método a una serie temporal dará como resultado valores sucesivos de desviación estándar correspondientes a n puntos de datos a medida que n se hace más grande con cada nueva muestra, en lugar de un cálculo de ventana deslizante de ancho constante.
Para k = 1, ..., n :
donde A es el valor medio.
Nota: Q 1 = 0 ya que k − 1 = 0 o x 1 = A 1 .
Varianza de la muestra:
Varianza poblacional:
Cuando los valores se ponderan con pesos desiguales , las sumas de potencias s 0 , s 1 , s 2 se calculan cada una como:
Y las ecuaciones de desviación estándar permanecen sin cambios. s 0 es ahora la suma de los pesos y no el número de muestras N .
También se puede aplicar el método incremental con errores de redondeo reducidos, con cierta complejidad adicional.
Se debe calcular una suma acumulada de pesos para cada k desde 1 hasta n :
y los lugares donde se utiliza 1/ k arriba deben reemplazarse por :
En la división final,
y
o
donde n es el número total de elementos y n ′ es el número de elementos con pesos distintos de cero.
Las fórmulas anteriores se vuelven iguales a las fórmulas más simples dadas anteriormente si los pesos se toman como iguales a uno.
El término desviación estándar fue utilizado por primera vez por escrito por Karl Pearson en 1894, después de su uso en conferencias. [19] [20] Esto fue como un reemplazo de nombres alternativos anteriores para la misma idea: por ejemplo, Gauss utilizó error medio . [21]
El índice de desviación estándar (IDE) se utiliza en evaluaciones externas de calidad , en particular para laboratorios médicos . Se calcula como: [22]

En dos dimensiones, la desviación estándar se puede ilustrar con la elipse de desviación estándar (ver Distribución normal multivariada § Interpretación geométrica ).










![{\displaystyle \mu \equiv \operatorname {E} [X]=\int _{-\infty }^{+\infty }xf(x)\,\mathrm {d} x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fb2a61843da0d05619c0dd691dbf3fe315b395ad)
![{\displaystyle \sigma \equiv {\sqrt {\operatorname {E} \left[(X-\mu )^{2}\right]}}={\sqrt {\int _{-\infty }^{+\infty }(x-\mu )^{2}f(x)\,\mathrm {d} x}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e3a1cfef8ad100fbcae387d9581763f0b389bbc3)
![{\textstyle {\sqrt {\operatorname {E} \left[X^{2}\right]-(\operatorname {E} [X])^{2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e2dd8d466c3ecb05713377fefcb7e7f787b29ce7)
![{\displaystyle \alpha \en (1,2]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/782b1d598278b0238ee817c658744e8a7ed3a06e)
![{\displaystyle \sigma ={\sqrt {{\frac {1}{N}}\left[(x_{1}-\mu )^{2}+(x_{2}-\mu )^{2}+\cdots +(x_{N}-\mu )^{2}\right]}},{\text{ donde }}\mu ={\frac {1}{N}}(x_{1}+\cdots +x_{N}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/827beb1be760eed3cb07b20d29f01d326f728071)











![{\textstyle E[{\sqrt {X}}]\neq {\sqrt {E[X]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3dbf273b716d2bdaac95f31a6890ded4645d8709)













![{\displaystyle \sigma (X)={\sqrt {\operatorname {E} \left[(X-\operatorname {E} [X])^{2}\right]}}={\sqrt {\operatorname {E} \left[X^{2}\right]-(\operatorname {E} [X])^{2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d3ab12089bd2027790ef060ff7cc2ec05ae2021f)
![{\displaystyle s(X)={\sqrt {\frac {N}{N-1}}}{\sqrt {\operatorname {E} \left[(X-\operatorname {E} [X])^{2}\right]}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/702e9da21c721697e6e81932bf8b7443028f7d6d)






![{\displaystyle {\text{Proporción}}\leq x={\frac {1}{2}}\left[1+\operatorname {erf} \left({\frac {x-\mu }{\sigma {\sqrt {2}}}}\right)\right]={\frac {1}{2}}\left[1+\operatorname {erf} \left({\frac {z}{\sqrt {2}}}\right)\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/19a6aad42f0352f855f10ad517460517ae848e4f)























