Tipo de visualización de datos para regiones geográficas.
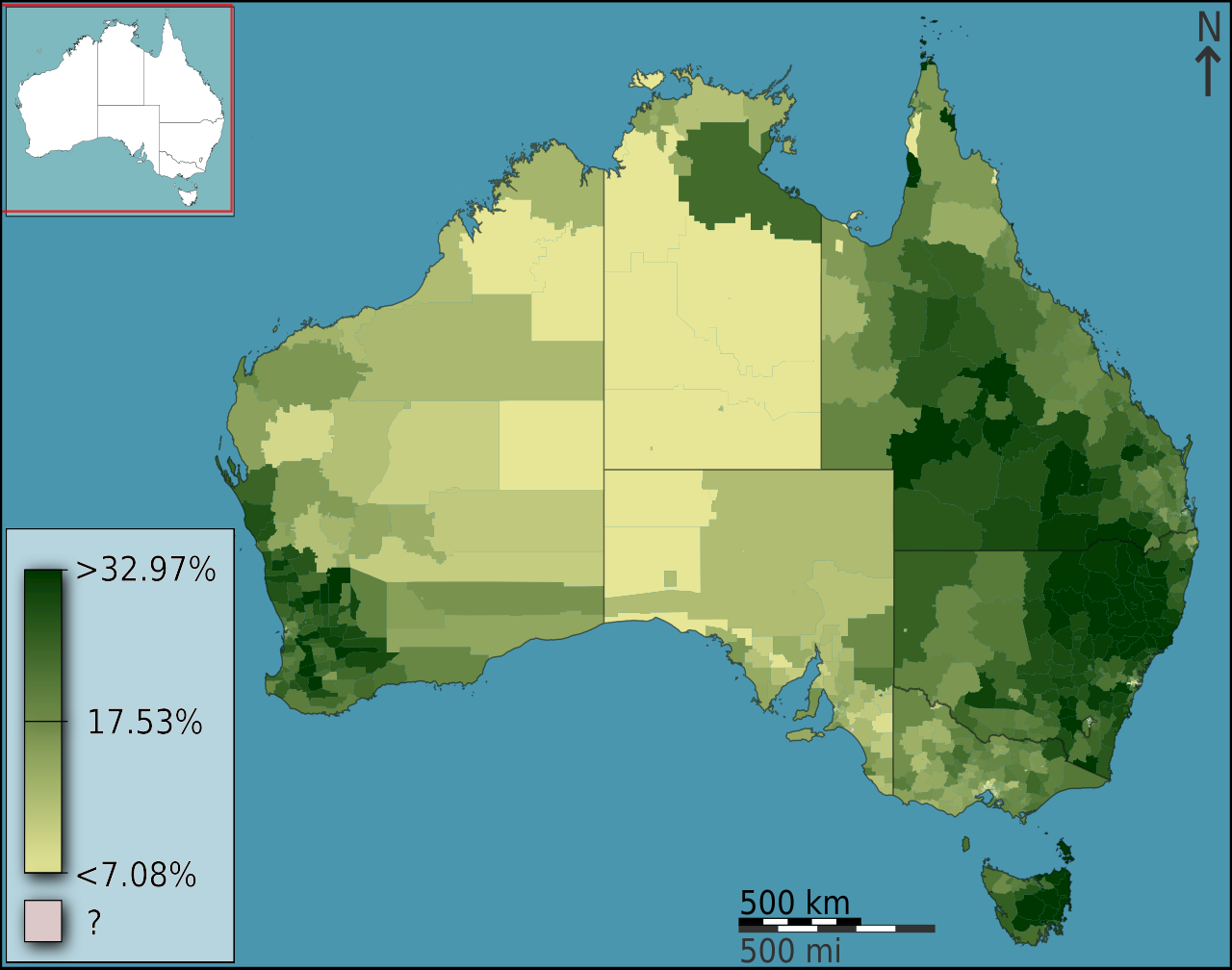
Un mapa de coropletas que visualiza la fracción de australianos que se identificaron como anglicanos en el censo de 2011. Los distritos seleccionados son áreas de gobierno local , la variable es espacialmente intensiva (una proporción) que no está clasificada y se utiliza un esquema de color secuencial parcialmente espectral.
Un mapa coroplético (del griego χῶρος (choros) 'área/región' y πλῆθος (plethos) 'multitud') es un tipo de mapa temático estadístico que utiliza pseudocolor , es decir, color correspondiente a un resumen agregado de una característica geográfica dentro de la enumeración espacial. unidades, como la densidad de población o el ingreso per cápita . [1] [2] [3]
Los mapas de coropletas proporcionan una manera fácil de visualizar cómo varía una variable en un área geográfica o muestran el nivel de variabilidad dentro de una región. Un mapa de calor o mapa isarítmico es similar pero utiliza regiones dibujadas según el patrón de la variable, en lugar de las áreas geográficas a priori de los mapas coropletas. La coropleta es probablemente el tipo más común de mapa temático porque los datos estadísticos publicados (del gobierno u otras fuentes) generalmente se agregan en unidades geográficas bien conocidas, como países, estados, provincias y condados, y por lo tanto son relativamente fáciles de identificar. cree utilizando SIG , hojas de cálculo u otras herramientas de software.
Historia
Mapa de alfabetización de Dupin de 1826 en Francia
El mapa coroplético más antiguo conocido fue creado en 1826 por el barón Pierre Charles Dupin y representa la disponibilidad de educación básica en Francia por departamento . [4] Pronto se produjeron en Francia más " cartes teintées " ("mapas teñidos") para visualizar otras "estadísticas morales" sobre educación, enfermedades, delincuencia y condiciones de vida. [5] : 158 mapas de coropletas rápidamente ganaron popularidad en varios países debido a la creciente disponibilidad de datos demográficos compilados a partir de censos nacionales, comenzando con una serie de mapas de coropletas publicados en los informes oficiales del censo de Irlanda de 1841. [6] Cuando la cromolitografía estuvo ampliamente disponible después de 1850, se añadió cada vez más color a los mapas de coropletas. [5] : 193
El término "mapa de coropletas" fue introducido en 1938 por el geógrafo John Kirtland Wright , y era de uso común entre los cartógrafos en la década de 1940. [7] [8] También en 1938, Glenn Trewartha los reintrodujo como "mapas de proporciones", pero este término no sobrevivió. [9]
Estructura
Un mapa de coropletas reúne dos conjuntos de datos: datos espaciales que representan una partición del espacio geográfico en distritos distintos y datos estadísticos que representan una variable agregada dentro de cada distrito. Hay dos modelos conceptuales comunes de cómo interactúan en un mapa coroplético: en una vista, que puede denominarse "distrito dominante", los distritos (a menudo unidades gubernamentales existentes) son el foco, en el que se recopilan una variedad de atributos, incluidos la variable que se está mapeando. En el otro punto de vista, que podría denominarse "variable dominante", la atención se centra en la variable como un fenómeno geográfico (digamos, la población latina), con una distribución en el mundo real, y su división en distritos es simplemente una opción conveniente. técnica de medición. [10]
En este mapa de coropletas, los distritos son países, la variable es espacialmente intensiva (una asignación media) con una clasificación de progresión geométrica modificada y se utiliza un esquema de color espectral divergente.
Geometría: distritos de agregación
En un mapa coroplético, los distritos suelen ser entidades previamente definidas, como unidades gubernamentales o administrativas (p. ej., condados, provincias, países) o distritos creados específicamente para la agregación estadística (p. ej., sectores censales ) y, por lo tanto, no tienen expectativas de correlación con la geografía de la variable. Es decir, los límites de los distritos coloreados pueden coincidir o no con la ubicación de los cambios en la distribución geográfica que se estudia. Esto contrasta directamente con los mapas corocromáticos e isarítmicos , en los que los límites de las regiones están definidos por patrones en la distribución geográfica del fenómeno en cuestión.
El uso de regiones de agregación predefinidas tiene una serie de ventajas, entre ellas: compilación y mapeo más fáciles de la variable (especialmente en la era de los SIG e Internet con sus numerosas fuentes de datos), el reconocimiento de los distritos y la aplicabilidad de la información. a una mayor investigación y políticas vinculadas a los distritos individuales. Un excelente ejemplo de esto serían las elecciones, en las que el total de votos de cada distrito determina su representante electo.
Sin embargo, puede dar lugar a una serie de problemas, generalmente debido al hecho de que el color constante aplicado a cada distrito de agregación hace que parezca homogéneo, enmascarando un grado desconocido de variación de la variable dentro del distrito. Por ejemplo, una ciudad puede incluir vecindarios de ingresos familiares bajos, moderados y altos, pero estar coloreada con un color "moderado" constante. Por tanto, los patrones espaciales del mundo real pueden no ajustarse a la unidad regional simbolizada. [11] Debido a esto, cuestiones como la falacia ecológica y el problema de la unidad de área modificable (MAUP) pueden dar lugar a importantes interpretaciones erróneas de los datos representados, y otras técnicas son preferibles si se pueden obtener los datos necesarios. [12] [13] [14]
Estos problemas pueden mitigarse en cierta medida utilizando distritos más pequeños, porque muestran variaciones más finas en la variable mapeada, y su tamaño visual más pequeño y su mayor número reducen la probabilidad de que el usuario del mapa haga juicios sobre la variación dentro de un solo distrito. Sin embargo, pueden hacer que el mapa sea demasiado complejo, especialmente si no hay un patrón geográfico significativo en la variable (es decir, el mapa parece colores dispersos aleatoriamente). Aunque representar datos específicos en regiones grandes puede resultar engañoso, las formas familiares de los distritos pueden hacer que el mapa sea más claro y más fácil de interpretar y recordar. [15] La elección de las regiones dependerá en última instancia del público objetivo y del propósito del mapa. Alternativamente, a veces se puede emplear la técnica dasimétrica para refinar los límites de la región para que coincidan más estrechamente con los cambios reales en el fenómeno en cuestión.
Debido a estos problemas, para muchas variables, se puede preferir un mapa isarítmico (para una variable cuantitativa) o corocromático (para una variable cualitativa), en el que los límites de la región se basan en los datos mismos. Sin embargo, en muchos casos esa información detallada simplemente no está disponible y el mapa de coropletas es la única opción viable.
Un mapa de coropletas en el que los distritos son condados de EE. UU., la variable es espacialmente intensiva (una proporción) con una clasificación cuantil y utiliza un esquema de color secuencial de un solo tono.
Propiedad: resúmenes estadísticos agregados
La variable a mapear puede provenir de una amplia variedad de disciplinas del mundo humano o natural, aunque los temas humanos (por ejemplo, demografía, economía, agricultura) son generalmente más comunes debido al papel de las unidades gubernamentales en la actividad humana, lo que a menudo conduce a la recopilación original de los datos estadísticos. La variable también puede estar en cualquiera de los niveles de medición de Stevens : nominal, ordinal, intervalo o relación, aunque las variables cuantitativas (intervalo/relación) se utilizan más comúnmente en mapas coropletas que las variables cualitativas (nominales/ordinales). Es importante señalar que el nivel de medición del dato individual puede ser diferente de la estadística resumida agregada. Por ejemplo, un censo puede preguntar a cada individuo cuál es su "lengua hablada principal" (nominal), pero esto puede resumirse para todos los individuos de un condado como "porcentaje de habla principalmente española" (proporción) o como "porcentaje de lengua primaria predominante". idioma" (nominal).
Una variable espacialmente extensa (a veces llamada propiedad global ) es aquella que sólo puede aplicarse a todo el distrito, comúnmente en forma de recuentos totales o cantidades de un fenómeno (similar a la masa o el peso en física). Se dice que las variables extensivas son acumulativas en el espacio; por ejemplo, si la población del Reino Unido es de 65 millones, no es posible que las poblaciones de Inglaterra, Gales, Escocia e Irlanda del Norte también sean de 65 millones. En cambio, sus poblaciones totales deben sumar (acumular) para calcular la población total de la entidad colectiva. Sin embargo, si bien es posible mapear una variable extensa en un mapa coroplético, casi universalmente se desaconseja hacerlo porque los patrones pueden malinterpretarse fácilmente. Por ejemplo, si un mapa coroplético asignara un tono particular de rojo a poblaciones totales entre 60 y 70 millones, una situación en la que el Reino Unido (como distrito único) tiene 65 millones de habitantes sería indistinguible de una situación en la que los cuatro países que lo componen cada uno tenía 65 millones de habitantes, aunque se trata de realidades geográficas muy diferentes. Otra fuente de error de interpretación es que si un distrito grande y un distrito pequeño tienen el mismo valor (y por lo tanto el mismo color), el más grande naturalmente se parecerá más. [16] Otros tipos de mapas temáticos , especialmente símbolos proporcionales y cartogramas , están diseñados para representar variables extensas y generalmente son los preferidos. [1] : 131
Una variable espacialmente intensiva , también conocida como campo , superficie estadística o variable localizada , representa una propiedad que podría medirse en cualquier ubicación (un punto o área pequeña, dependiendo de su naturaleza) en el espacio, independientemente de cualquier límite, aunque su La variación en un distrito se puede resumir como un valor único. Las variables intensivas comunes incluyen densidades, proporciones, tasas de cambio, asignaciones medias (p. ej., PIB per cápita) y estadísticas descriptivas (p. ej., media, mediana, desviación estándar). Se dice que las variables intensivas son distributivas en el espacio; por ejemplo, si la densidad de población del Reino Unido es de 250 personas por kilómetro cuadrado, entonces sería razonable estimar (en ausencia de otros datos) que la densidad más probable (si no correcta) de cada uno de los cinco países constituyentes también es de 250/km 2 . Tradicionalmente en cartografía, el modelo conceptual predominante para este tipo de fenómenos ha sido la superficie estadística , en la que la variable se imagina como una "altura" de tercera dimensión sobre el espacio bidimensional que varía continuamente. [17] En la ciencia de la información geográfica , la conceptualización más común es la de campo , adoptada de la Física y generalmente modelada como una función escalar de ubicación. Los mapas de coropletas se adaptan mejor a variables intensivas que extensivas; Si un usuario de un mapa ve el Reino Unido lleno de un color que indica "100-200 personas por kilómetro cuadrado", estimar que Gales e Inglaterra pueden tener entre 100 y 200 personas por kilómetro cuadrado puede no ser exacto, pero es posible y razonable. estimar.
Normalización: el mapa de la izquierda utiliza la población total para determinar el color. Esto hace que los polígonos más grandes parezcan más urbanizados que las áreas urbanas más pequeñas y densas de Boston , Massachusetts. El mapa de la derecha utiliza la densidad de población. Un mapa correctamente normalizado mostrará variables independientes del tamaño de los polígonos.
Normalización
La normalización es la técnica de derivar una variable espacialmente intensiva a partir de una o más variables espacialmente extensivas, de modo que pueda usarse apropiadamente en un mapa coroplético. [3] Es similar, pero no idéntica, a la técnica de normalización o estandarización en estadística. Normalmente, se logra calculando la relación entre dos variables espacialmente extensas. [12] : 252 Aunque cualquier proporción de este tipo dará como resultado una variable intensiva, solo unas pocas son especialmente significativas y se usan comúnmente en mapas de coropletas:
Densidad = total / área. Ejemplo: densidad de población
Proporción = total del subgrupo / total general. Ejemplo: Hogares ricos como porcentaje de todos los hogares.
Asignación media = monto total / total de individuos. Ejemplo: producto interno bruto per cápita (PIB total / población total)
Tasa de cambio = total en el momento posterior / total en el momento anterior. Ejemplo: tasa de crecimiento anual de la población.
Estos no son equivalentes ni uno mejor que otro. Más bien, cuentan diferentes aspectos de una narrativa geográfica. Por ejemplo, un mapa coroplético de la densidad de población latina en Texas visualiza una narrativa sobre la agrupación espacial y la distribución de ese grupo, mientras que un mapa del porcentaje de latinos visualiza una narrativa de composición y predominio. No emplear una normalización adecuada dará lugar a un mapa inapropiado y potencialmente engañoso en casi todos los casos. [16] [18] [19] Este es uno de los errores más comunes en cartografía, y un estudio encontró que en un momento, más de la mitad de los paneles de control de COVID-19 de los Estados Unidos alojados por los gobiernos estatales no empleaban la normalización de sus coropletas. mapas. [19] Este es uno de los muchos problemas que contribuyeron a la infodemia que rodeó la pandemia de COVID-19, y "también podría ser un facilitador sutil de la polarización política extrema en torno a las medidas para combatir el COVID que ha ocurrido en los Estados Unidos". [18] [20]
Clasificación
Este mapa de las elecciones presidenciales de EE. UU. de 2004-2016 utiliza distritos de condado, una variable espacialmente intensiva (diferencia en proporción) que no está clasificada y una progresión de color espectral divergente. Tenga en cuenta la leyenda de gradiente continuo que refleja la falta de clasificación.
Cada mapa de coropletas tiene una estrategia para asignar valores a colores. Un mapa coroplético clasificado separa el rango de valores en clases, asignando el mismo color a todos los distritos de cada clase. Un mapa sin clasificar (a veces llamado clase n ) asigna directamente un color proporcional al valor de cada distrito. A partir del mapa de Dupin de 1826, los mapas de coropletas clasificados han sido mucho más comunes. [2] Es probable que esto se debiera originalmente a la mayor simplicidad de aplicar un conjunto limitado de tintes; Sólo en la era de la cartografía computarizada han sido factibles los mapas de coropletas sin clasificar y, hasta hace poco, todavía no eran fáciles de crear en la mayoría de los programas cartográficos. [21] [2] [22] [23] Waldo R. Tobler , al presentar formalmente el esquema sin clasificar en 1973, afirmó que era una descripción más precisa de los datos originales y afirmó que el principal argumento a favor de la clasificación, que es más legible, necesitaba ser probado. [2] El debate y los experimentos que siguieron llegaron a la conclusión general de que la principal ventaja de los mapas de coropletas sin clasificar, además de la afirmación de Tobler de una precisión bruta, era que permitían a los lectores ver variaciones sutiles en la variable, sin hacerles creer. que los distritos que pertenecían a la misma clase tenían valores idénticos. Así, pueden ver mejor los patrones generales del fenómeno geográfico, pero no los valores específicos. [1] : 109 [24] [25] El argumento principal a favor de los mapas coropléticos clasificados es que es más fácil de procesar para los lectores, debido a la menor cantidad de tonos distintos para reconocer, lo que reduce la carga cognitiva y les permite identificar con precisión. Haga coincidir los colores del mapa con los valores enumerados en la leyenda. [2] [22] [23]
La clasificación se realiza estableciendo una regla de clasificación , una serie de umbrales que divide el rango cuantitativo de valores variables en una serie de clases ordenadas. Por ejemplo, si un conjunto de datos de ingresos medios anuales por condado de EE. UU. incluye valores entre 20 000 y 150 000 dólares, podría dividirse en tres clases con umbrales de 45 000 y 83 000 dólares. Para evitar confusiones, cualquier regla de clasificación debe ser mutuamente excluyente y colectivamente exhaustiva , lo que significa que cualquier valor posible pertenece exactamente a una clase. Por ejemplo, si una regla establece un umbral en el valor 6,5, debe quedar claro si un distrito con un valor de exactamente 6,5 se clasificará en la clase baja o alta (es decir, si la definición de la clase baja es < 6,5 o ≤6,5 y si la clase alta es >6,5 o ≥6,5). Se han desarrollado una variedad de tipos de reglas de clasificación para mapas de coropletas: [26] [1] : 87
Las reglas exógenas importan umbrales sin tener en cuenta los patrones de los datos disponibles.
Las reglas establecidas son aquellas que ya son de uso común debido a investigaciones científicas pasadas o políticas oficiales. Un ejemplo sería utilizar tramos impositivos gubernamentales o un umbral de pobreza estándar al clasificar los niveles de ingresos.
Las estrategias ad hoc o de sentido común son esencialmente inventadas por el cartógrafo utilizando umbrales que tienen algún sentido intuitivo. Un ejemplo sería clasificar los ingresos según lo que el cartógrafo cree que es "rico", "clase media" y "pobre". Por lo general, no se recomiendan estas estrategias a menos que todos los demás métodos no sean viables.
Las reglas endógenas se basan en patrones del propio conjunto de datos.
Las reglas de rupturas naturales buscan agrupaciones naturales en los datos, en las que un gran número de distritos tienen valores similares con grandes brechas entre ellos. Si este es el caso, estos grupos probablemente sean geográficamente significativos.
La optimización de rupturas naturales de Jenks , desarrollada por George F. Jenks , es un algoritmo heurístico para identificar automáticamente dichos grupos, si existen; Es esencialmente una forma unidimensional del algoritmo de agrupamiento de k-medias . [27] Si no existen agrupaciones naturales, las rupturas que genera a menudo se reconocen como un buen compromiso entre los otros métodos, y comúnmente es el clasificador predeterminado utilizado en el software SIG.
Intervalos iguales o una progresión aritmética dividen el rango de valores para que cada clase tenga un rango igual de valores: ( max - min )/ n . Por ejemplo, el rango de ingresos anterior ($20 000 - $150 000) se dividiría en cuatro clases: $52 500, $85 000 y $117 500.
Una regla de desviación estándar también genera rangos iguales de valores, pero en lugar de comenzar con los valores mínimo y máximo, comienza en la media aritmética de los datos y establece una ruptura en cada múltiplo de un número constante de desviaciones estándar por encima y por debajo de la media. .
Quantiles divide el conjunto de datos para que cada clase tenga el mismo número de distritos. Por ejemplo, si los 3.141 condados de los Estados Unidos se dividieran en cuatro clases de cuantiles (es decir, cuartiles ), entonces la primera clase incluiría los 785 condados más pobres y luego los 785 siguientes. Es posible que sea necesario hacer ajustes cuando el número de distritos no se divide uniformemente, o cuando valores idénticos se sitúan a ambos lados del umbral.
Una regla de progresión geométrica divide el rango de valores de modo que la proporción de umbrales sea constante (en lugar de su intervalo como en una progresión aritmética). Por ejemplo, el rango de ingresos anterior se dividiría utilizando una proporción de 2 con umbrales de $40 000 y $80 000. Este tipo de regla se utiliza comúnmente cuando la distribución de frecuencia de los datos tiene un sesgo positivo muy alto , especialmente si es geométrica o exponencial .
Una regla de medias anidadas o rupturas de cabeza/cola es un algoritmo que divide recursivamente el conjunto de datos estableciendo un umbral en la media aritmética , luego subdivide cada una de las dos clases creadas en sus respectivas medias, y así sucesivamente. Así, el número de clases no es arbitrario, sino que debe ser una potencia de dos (2, 4, 8, etc.). Se ha sugerido que esto también funciona bien para distribuciones muy asimétricas .
Debido a que los umbrales calculados a menudo pueden tener valores precisos que los lectores de mapas no pueden interpretar fácilmente (por ejemplo, $74,326.9734), es común crear una regla de clasificación modificada redondeando los valores de umbral a un número simple similar. Un ejemplo común es una progresión geométrica modificada que subdivide potencias de diez, como [1, 2,5, 5, 10, 25, 50, 100,...] o [1, 3, 10, 30, 100,... ].
Progresión de color
El elemento final de un mapa de coropletas es el conjunto de colores utilizados para representar los diferentes valores de la variable. Hay una variedad de enfoques diferentes para esta tarea, pero el principio principal es que cualquier orden en la variable (p. ej., valores cuantitativos bajos a altos) debe reflejarse en el orden percibido de los colores (p. ej., claro a oscuro), como esto permitirá a los lectores de mapas hacer juicios intuitivos sobre "más versus menos" y ver tendencias y patrones con una mínima referencia a la leyenda. [1] : 114 Una segunda pauta general, al menos para mapas clasificados, es que los colores deben ser fácilmente distinguibles, de modo que los colores del mapa puedan coincidir sin ambigüedades con los de la leyenda para determinar los valores representados. Este requisito limita el número de clases que se pueden incluir; Para los tonos de gris, las pruebas han demostrado que cuando se utiliza el valor solo (por ejemplo, de claro a oscuro, ya sea gris o cualquier tono ), es difícil utilizar en la práctica más de siete clases. [19] [28] Si se incorporan diferencias en tono y/o saturación, ese límite aumenta significativamente hasta 10-12 clases. La necesidad de discriminación de colores se ve afectada aún más por las deficiencias en la visión de los colores ; por ejemplo, los esquemas de color que utilizan rojo y verde para distinguir valores no serán útiles para una parte importante de la población . [29]
Los tipos más comunes de progresiones de color utilizados en mapas coropletas (y otros mapas temáticos) incluyen: [30] [31]
Una progresión secuencial representa valores variables como valor de color
Una progresión en escala de grises utiliza sólo tonos de gris.Progresión en escala de grises
Una progresión de un solo tono se desvanece desde un tono oscuro del color elegido (o gris) a un tono muy claro o blanco de relativamente el mismo tono. Este es un método común utilizado para mapear la magnitud. El tono más oscuro representa el mayor número en el conjunto de datos y el tono más claro representa el menor número.Progresión de un solo tono
Una progresión espectral parcial utiliza una gama limitada de tonos para agregar más contraste al contraste de valores, lo que permite utilizar una mayor cantidad de clases. El amarillo se usa comúnmente para el extremo más claro de la progresión debido a su aparente ligereza natural. Los rangos de tonos comunes son amarillo-verde-azul y amarillo-naranja-rojo.Progresión espectral parcial
Una progresión divergente o bipolar es esencialmente dos progresiones de color secuenciales (de los tipos anteriores) unidas con un color de luz común o blanco. Normalmente se utilizan para representar valores positivos y negativos o divergencias de una tendencia central, como la media de la variable que se está mapeando. Por ejemplo, una progresión típica al mapear temperaturas es del azul oscuro (para el frío) al rojo oscuro (para el calor) con blanco en el medio. Estos se utilizan a menudo cuando se dan juicios de valor a los dos extremos, como mostrar el extremo "bueno" en verde y el extremo "malo" en rojo. [32]Progresión de color bipolar
Una progresión espectral utiliza una amplia gama de tonos (posiblemente toda la rueda de colores) sin diferencias de valor previstas. Esto se usa más comúnmente cuando hay un orden para los valores, pero no es un orden "más versus menos", como en el caso de la estacionalidad. Lo utilizan con frecuencia quienes no son cartógrafos en situaciones en las que otras progresiones de color serían mucho más efectivas. [33] [34]Progresión de color de espectro completo
Una progresión cualitativa utiliza un conjunto disperso de tonos sin ningún orden en particular, sin ninguna diferencia de valor prevista. Esto se usa más comúnmente con categorías nominales en un mapa coroplético cualitativo, como "religión más predominante".Progresión de color cualitativa
Mapas coropléticos bivariados
Mapa de coropletas bivariado que compara las poblaciones negra (azul) e hispana (roja) en los Estados Unidos, censo de 2010; Los tonos de violeta muestran proporciones significativas de ambos grupos.
Es posible representar dos (y a veces tres) variables simultáneamente en un solo mapa de coropletas representando cada una con una progresión de un solo tono y combinando los colores de cada distrito. Esta técnica fue publicada por primera vez por la Oficina del Censo de EE. UU. en la década de 1970 y se ha utilizado muchas veces desde entonces, con distintos grados de éxito. [35] Esta técnica se utiliza generalmente para visualizar la correlación y el contraste entre dos variables que se supone que están estrechamente relacionadas, como el nivel educativo y los ingresos. Generalmente se utilizan colores contrastantes pero no complementarios, de modo que su combinación se reconoce intuitivamente como "entre" los dos colores originales, como por ejemplo rojo+azul=púrpura. La técnica funciona mejor cuando la geografía de la variable tiene un alto grado de autocorrelación espacial , de modo que existen grandes regiones de colores similares con cambios graduales entre ellos; de lo contrario, el mapa puede parecer una mezcla confusa de colores aleatorios. [12] : 331 Se ha descubierto que se utilizan más fácilmente si el mapa incluye una leyenda cuidadosamente diseñada y una explicación de la técnica. [36]
Leyenda
Un mapa de coropletas utiliza símbolos ad hoc para representar la variable mapeada. Si bien la estrategia general puede resultar intuitiva si se elige una progresión de colores que refleje el orden adecuado, los lectores de mapas no pueden descifrar el valor real de cada distrito sin una leyenda. Una leyenda de coropletas típica para un mapa de coropletas clasificado incluye una serie de parches de muestra del símbolo para cada clase, con una descripción de texto del rango de valores correspondiente. En un mapa de coropletas sin clasificar, es común que la leyenda muestre un gradiente de color suave entre los valores mínimo y máximo, con dos o más puntos etiquetados con los valores correspondientes. [1] : 111
Un enfoque alternativo es la leyenda del histograma , que incluye un histograma que muestra la distribución de frecuencia de la variable mapeada (es decir, el número de distritos en cada clase). Cada clase puede representarse mediante una sola barra con su ancho determinado por sus valores de umbral mínimo y máximo y su altura calculada de manera que el área del cuadro sea proporcional al número de distritos incluidos, luego coloreada con el símbolo del mapa utilizado para esa clase. Alternativamente, el histograma se puede dividir en un gran número de barras, de modo que cada clase incluya una o más barras, simbolizadas según su símbolo en el mapa. [37] Esta forma de leyenda muestra no solo los valores umbral para cada clase, sino que también brinda cierto contexto para la fuente de esos valores, especialmente para las reglas de clasificación endógenas que se basan en la distribución de frecuencia, como los cuantiles. Sin embargo, actualmente no son compatibles con SIG ni con software de mapeo y, por lo general, deben construirse manualmente.
^ abcdef Dent, Borden D.; Torguson, Jeffrey S.; Hodler, Thomas W. (2009). Cartografía: Diseño de mapas temáticos (6ª ed.). McGraw-Hill.
^ ABCDE Tobler, Waldo (1973). "¿Mapas de coropletas sin intervalos de clase?". Análisis Geográfico . 5 (3): 262–265. Código bibliográfico : 1973GeoAn...5..262T. doi : 10.1111/j.1538-4632.1973.tb01012.x .
^ ab Adams, Aarón; Chen, Xiang; Li, Wei Dong; Zhang, Chuanrong (2020). "La pandemia encubierta: la importancia de la normalización de datos en el mapeo web COVID-19". Salud pública . 183 : 36–37. doi :10.1016/j.puhe.2020.04.034. PMC 7203028 . PMID 32416476.
^ Dupin, Charles (1826). Carta figurativa de la instrucción popular de la Francia. Bruselas: sn
^ ab Robinson, Arthur H. (1982). Mapeo temático temprano en la historia de la cartografía . Prensa de la Universidad de Chicago.
^ Irlanda (1843). Informe de los comisionados designados para realizar el censo de Irlanda para el año 1841. Dublín: HM Stationery Office. pag. lv.
^ John Kirtland Wright (1938). “Problemas en la cartografía demográfica” en Notas sobre cartografía estadística, con especial referencia a la cartografía de fenómenos poblacionales, p.12.
^ Trewartha, Glenn T. (enero de 1938). "Mapas de proporciones de las granjas y cultivos de China". Revisión geográfica . 28 (1): 102-111. Código Bib : 1938GeoRv..28..102T. doi :10.2307/210569. JSTOR 210569.
^ Chrisman, Nicolás (2002). Exploración de los sistemas de información geográfica (2ª ed.). Wiley. pag. 65.ISBN0-471-31425-0.
^ Jenks, George F.; Caspall, Fred C. (junio de 1971). "Error en mapas coropléticos: definición, medición, reducción". Anales de la Asociación de Geógrafos Americanos . 61 (2): 217–244. doi :10.1111/j.1467-8306.1971.tb00779.x. ISSN 0004-5608.
^ abc T. Slocum, R. McMaster, F. Kessler, H. Howard (2009). Cartografía temática y geovisualización, tercera edición, página 252. Pearson Prentice Hall: Upper Saddle River, Nueva Jersey.
^ Openshaw, Stan (1983). El problema de la unidad de área modificable (PDF) . ISBN0-86094-134-5.
^ Chen, Xiang; Sí, Xinyue; Ampliador, Michael J.; Delmelle, Eric; Kwan, Mei-Po; Shannon, Jerry; Racine, Racine F.; Adams, Aarón; Liang, Lu; Peng, Jia (27 de diciembre de 2022). "Una revisión sistemática del problema de la unidad de área modificable (MAUP) en la investigación ambiental alimentaria comunitaria". Informática Urbana . 1 (1): 22. Código Bib : 2022UrbIn...1...22C. doi : 10.1007/s44212-022-00021-1 .
^ Rittschof, Kent (1998). "Aprender y recordar de mapas temáticos de regiones familiares". Investigación y Desarrollo de Tecnología Educativa . 46 : 19–38. doi :10.1007/BF02299827. S2CID 145086925.
^ ab Mark Monmonier (1991). Cómo mentir con mapas . págs. 22-23. Prensa de la Universidad de Chicago
^ Jenks, George F. (1963). "Generalización en cartografía estadística". Anales de la Asociación de Geógrafos Americanos . 53 (1): 15. doi :10.1111/j.1467-8306.1963.tb00429.x.
^ ab Mooney, Peter (julio de 2020). "Mapeo de COVID-19: cómo los mapas basados en web contribuyen a la infodemia". Diálogos en geografía humana . 10 (2): 265–270. doi : 10.1177/2043820620934926 .
^ abc Adams, Aaron M.; Chen, Xiang; Li, Weidong; Chuanrong, Zhang (27 de julio de 2023). "Normalizar la pandemia: explorar las cuestiones cartográficas en los paneles de control COVID-19 del gobierno estatal". Revista de Mapas . 19 (5): 1–9. Código Bib : 2023JMaps..19Q...1A. doi : 10.1080/17445647.2023.2235385 .
^ Engel, Claudia; Rodden, Jonathan; Tabellini, Marco (18 de marzo de 2022). "Políticas para influir en las percepciones sobre el riesgo de COVID-19: el caso de los mapas". Avances científicos . 8 (11): eabm5106. Código Bib : 2022SciA....8M5106E. doi :10.1126/sciadv.abm5106. PMC 8932671 . PMID 35302842.
^ Kelly, Brett (2017). "Revisión del mapeo de coropletas sin clasificar". Perspectivas cartográficas (86): 30. doi : 10.14714/CP86.1424 .
^ ab Dobson, Michael W. (octubre de 1973). "¿Mapas de coropletas sin intervalos de clase? Un comentario". Análisis Geográfico . 5 (4): 358–360. Código bibliográfico : 1973GeoAn...5..358D. doi : 10.1111/j.1538-4632.1973.tb00498.x .
^ ab Dobson, Michael W.; Peterson, Michael P. (1980). "Mapas de coropletas sin clasificar: un comentario, una respuesta". El cartógrafo americano . 7 (1): 78–81. doi :10.1559/152304080784522928.
^ Peterson, Michael P. (1979). "Una evaluación del mapeo de coropletas de líneas cruzadas sin clasificar". El cartógrafo americano . 6 (1): 21–37. doi :10.1559/152304079784022736.
^ Muller, Jean-Claude (junio de 1979). "Percepción de mapas continuamente sombreados". Anales de la Asociación de Geógrafos Americanos . 69 (2): 240. doi :10.1111/j.1467-8306.1979.tb01254.x.
^ Kraak, Menno-Jan; Ormeling, Ferjan (2003). Cartografía: visualización de datos espaciales (2ª ed.). Prentice Hall. págs. 116-121. ISBN978-0-13-088890-7.
^ Jenks, George F. 1967. "El concepto de modelo de datos en la cartografía estadística", Anuario internacional de cartografía 7: 186–190.
^ Monmonier, Mark (1977). Mapas, distorsión y significado . Asociación de Geógrafos Americanos.
^ Olson, Judy M.; Cervecero, Cynthia (1997). "Una evaluación de las selecciones de color para adaptarse a los usuarios de mapas con problemas de visión de los colores". Anales de la Asociación de Geógrafos Americanos . 87 (1): 103-134. doi :10.1111/0004-5608.00043.
^ Robinson, AH, Morrison, JL, Muehrke, PC, Kimmerling, AJ y Guptill, SC (1995) Elementos de cartografía. (6ª edición), Nueva York: Wiley.
^ Brewer, Cynthia A. "Pautas de uso del color para mapeo y visualización". En MacEachren, Alan M.; Taylor, DRF (eds.). Visualización en Cartografía Moderna . Pérgamo. págs. 123-147.
^ Patricia Cohen (9 de agosto de 2011). "Lo que los mapas digitales pueden decirnos sobre el estilo americano". New York Times .
^ Luz; et al. (2004). "¿El fin del arco iris? Combinaciones de colores para gráficos de datos mejorados" (PDF) . Eos . 85 (40): 385–91. Código Bib : 2004EOSTr..85..385L. doi : 10.1029/2004EO400002 .
^ Stauffer, Reto. "En algún lugar sobre el arco iris". Asistente de HCL . Consultado el 14 de agosto de 2019 .
^ Meyer, Morton A.; Broome, Federico R.; Schweitzer, Richard H. Jr. (1975). "Mapeo estadístico de colores realizado por la Oficina del Censo de Estados Unidos". El cartógrafo americano . 2 (2): 101–117. doi :10.1559/152304075784313250.
^ Olson, Judy M. (1981). "Mapas de dos variables codificados espectralmente". Anales de la Asociación de Geógrafos Americanos . 71 (2): 259–276. doi :10.1111/j.1467-8306.1981.tb01352.x.
^ Kumar, Naresh (2004). "Leyenda del histograma de frecuencia en el mapa de coropletas: un sustituto de las leyendas tradicionales". Cartografía y Ciencias de la Información Geográfica . 31 (4): 217–236. Código Bib : 2004CGISc..31..217K. doi :10.1559/1523040042742411. S2CID 119795925.
Otras lecturas
Dent, Borden; Torguson, Jeffrey; Hodler, Thomas (21 de agosto de 2008). Cartografía Diseño de Mapas Temáticos . McGraw-Hill. ISBN 978-0-072-94382-5.
enlaces externos
Busque el mapa de coropletas en Wikcionario, el diccionario gratuito.
Wikimedia Commons tiene medios relacionados con mapas y mapas de coropletas .