Velvet es un paquete de algoritmos que ha sido diseñado para manejar el ensamblaje de genomas de novo y alineaciones de secuenciación de lecturas cortas . Esto se logra mediante la manipulación de gráficos de De Bruijn para el ensamblaje de secuencias genómicas mediante la eliminación de errores y la simplificación de regiones repetidas. [2] Velvet también se ha implementado en paquetes comerciales, como Sequencher , Geneious , MacVector y BioNumerics .
El desarrollo de secuenciadores de nueva generación (NGS) permitió una mayor rentabilidad en la secuenciación de lecturas muy cortas. La manipulación de los gráficos de De Bruijn como método de alineación se volvió más realista, pero se necesitaban más desarrollos para abordar problemas con errores y repeticiones. [3] Esto condujo al desarrollo de Velvet por Daniel Zerbino y Ewan Birney en el Instituto Europeo de Bioinformática en el Reino Unido. [4]
Velvet funciona manipulando de manera eficiente los gráficos de Bruijn mediante la simplificación y la compresión, sin pérdida de información gráfica, al hacer converger caminos que no se intersecan en nodos individuales. Elimina errores y resuelve repeticiones utilizando primero un algoritmo de corrección de errores que fusiona las secuencias. Luego, las repeticiones se eliminan de la secuencia a través del solucionador de repeticiones que separa los caminos que comparten superposiciones locales.
La combinación de lecturas cortas y pares de lecturas permite a Velvet resolver repeticiones pequeñas y producir contigs de longitud razonable. Esta aplicación de Velvet puede producir contigs con una longitud N50 de 50 kb en datos procariotas de extremos emparejados y una longitud de 3 kb para regiones de datos de mamíferos .
Como ya se mencionó, Velvet utiliza el gráfico de De Bruijn para ensamblar lecturas cortas. Más específicamente, Velvet representa cada k-mero diferente obtenido a partir de las lecturas por un nodo único en el gráfico. Dos nodos están conectados si sus k-meros tienen una superposición de k-1. En otras palabras, existe un arco desde el nodo A hasta el nodo B si los últimos k-1 caracteres del k-mero, representados por A, son los primeros k-1 caracteres del k-mero representado por B. La siguiente figura muestra un ejemplo de un gráfico de De Bruijn generado con Velvet:

El mismo proceso se realiza simultáneamente con el complemento inverso de todos los k-meros para tener en cuenta las superposiciones entre las lecturas de cadenas opuestas. Se pueden realizar varias optimizaciones sobre el gráfico, que incluyen la simplificación y la eliminación de errores.
Una forma sencilla de ahorrar costes de memoria es fusionar nodos que no afecten a la trayectoria generada en el grafo, es decir, siempre que un nodo A tenga un solo arco de salida que apunte al nodo B, con un solo arco de entrada, se pueden fusionar los nodos. Es posible representar ambos nodos como uno solo, fusionándolos y toda su información. La siguiente figura ilustra este proceso en la simplificación del ejemplo inicial.

Los errores en el gráfico pueden ser causados por el proceso de secuenciación o simplemente podría ser que la muestra biológica contenga algunos errores (por ejemplo, polimorfismos ). Velvet reconoce tres tipos de errores: puntas, burbujas y conexiones erróneas.
Un nodo se considera una punta y debe borrarse si está desconectado en uno de sus extremos, la longitud de la información almacenada en el nodo es menor a 2k y el arco que conduce a este nodo tiene una multiplicidad baja (número de veces que se encontró el arco durante la construcción del grafo) y, como resultado, no se puede comparar con otros caminos alternativos. Una vez eliminados estos errores, el grafo vuelve a someterse a una simplificación.

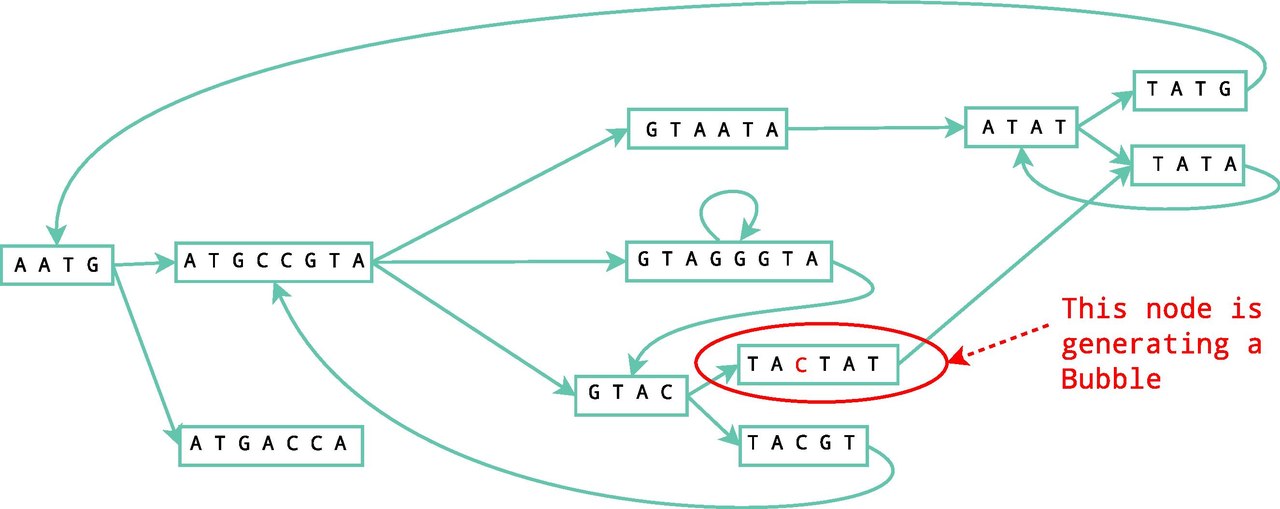
Las burbujas se generan cuando dos caminos distintos comienzan y terminan en los mismos nodos. Normalmente, las burbujas son causadas por errores o variantes biológicas. Estos errores se eliminan utilizando el algoritmo Tour Bus, que es similar al algoritmo de Dijkstra , una búsqueda en amplitud que detecta el mejor camino a seguir y determina cuáles deben eliminarse. En la figura 4 se muestra un ejemplo sencillo.

Este proceso también se muestra en la figura 5 siguiendo los ejemplos mostrados en las figuras 1 y 2.
Se trata de conexiones que no generan rutas correctas o no crean estructuras reconocibles dentro del grafo. Velvet borra estos errores una vez finalizado el algoritmo Tour Bus, aplicando un corte de cobertura simple que debe ser definido por el usuario.
Velvet proporciona las siguientes funciones:
Después de ejecutar velvetg, se generan varios archivos. Lo más importante es que un archivo de contigs contiene las secuencias de contigs de más de 2k de longitud, donde k es la longitud de palabra utilizada en velveth.
Para obtener más detalles y ejemplos, consulte el Manual Velvet [5].
Las tecnologías actuales de secuenciación de ADN, incluida la NGS, son limitadas debido a que los genomas son mucho más grandes que cualquier longitud de lectura. Por lo general, las NGS funcionan con lecturas pequeñas, de menos de 400 pb, y tienen un costo por lectura mucho menor que las máquinas de primera generación anteriores . También son más simples de operar, con mayor operación en paralelo y mayor rendimiento. [3]
Sin embargo, las lecturas cortas contienen menos información que las lecturas más largas, por lo que se requiere una mayor cobertura de lecturas de ensamblaje para permitir superposiciones detectables. Esto, a su vez, aumenta la complejidad de la secuenciación y aumenta significativamente los requisitos computacionales. Una mayor cantidad de lecturas también aumenta el tamaño del gráfico de superposición, lo que hace que sea más difícil y largo de calcular. Las conexiones entre las lecturas se vuelven más indistintas debido a la disminución de las secciones superpuestas, lo que genera una mayor posibilidad de errores.
Para superar estos problemas, se desarrollaron programas de secuenciación dinámica que son eficientes, muy rentables y capaces de resolver errores y repeticiones. Los algoritmos Velvet fueron diseñados para esto y son capaces de realizar alineaciones de secuenciación de novo de lectura corta en un tiempo computacional relativamente corto y con un uso de memoria menor en comparación con otros ensambladores. [6]
Uno de los principales inconvenientes en el uso de Velvet es el uso de la interfaz de línea de comandos y las dificultades que los usuarios, especialmente los principiantes, encuentran en la implementación de sus datos. En 2012 se desarrolló una interfaz gráfica de usuario para el ensamblador Velvet diseñada para superar este problema y simplificar el funcionamiento de Velvet. [7]
{{cite book}}: |journal=ignorado ( ayuda )