En el aprendizaje automático , las máquinas kernel son una clase de algoritmos para el análisis de patrones , cuyo miembro más conocido es la máquina de vectores de soporte (SVM). Estos métodos implican el uso de clasificadores lineales para resolver problemas no lineales. [1] La tarea general del análisis de patrones es encontrar y estudiar tipos generales de relaciones (por ejemplo , clústeres , clasificaciones , componentes principales , correlaciones , clasificaciones ) en conjuntos de datos. Para muchos algoritmos que resuelven estas tareas, los datos en representación bruta deben transformarse explícitamente en representaciones de vectores de características a través de un mapa de características especificado por el usuario : por el contrario, los métodos kernel solo requieren un kernel especificado por el usuario , es decir, una función de similitud sobre todos los pares de puntos de datos calculados utilizando productos internos . El mapa de características en las máquinas kernel es de dimensión infinita, pero solo requiere una matriz de dimensión finita a partir de la entrada del usuario de acuerdo con el teorema del Representante . Las máquinas kernel son lentas para calcular conjuntos de datos más grandes que un par de miles de ejemplos sin procesamiento paralelo.
Los métodos kernel deben su nombre al uso de funciones kernel , que les permiten operar en un espacio de características implícito de alta dimensión sin calcular nunca las coordenadas de los datos en ese espacio, sino simplemente calculando los productos internos entre las imágenes de todos los pares de datos en el espacio de características. Esta operación suele ser computacionalmente más barata que el cálculo explícito de las coordenadas. Este enfoque se denomina " truco kernel ". [2] Las funciones kernel se han introducido para datos de secuencia, gráficos , texto, imágenes y vectores.
Los algoritmos capaces de operar con kernels incluyen el perceptrón de kernel , las máquinas de vectores de soporte (SVM), los procesos gaussianos , el análisis de componentes principales (PCA), el análisis de correlación canónica , la regresión de cresta , el agrupamiento espectral , los filtros adaptativos lineales y muchos otros.
La mayoría de los algoritmos de kernel se basan en la optimización convexa o en problemas propios y están bien fundamentados estadísticamente. Normalmente, sus propiedades estadísticas se analizan utilizando la teoría del aprendizaje estadístico (por ejemplo, utilizando la complejidad de Rademacher ).
Los métodos kernel pueden considerarse como aprendices basados en instancias : en lugar de aprender un conjunto fijo de parámetros correspondientes a las características de sus entradas, "recuerdan" el ejemplo de entrenamiento -ésimo y aprenden para él un peso correspondiente . La predicción para entradas no etiquetadas, es decir, aquellas que no están en el conjunto de entrenamiento, se trata mediante la aplicación de una función de similitud , llamada kernel , entre la entrada no etiquetada y cada una de las entradas de entrenamiento . Por ejemplo, un clasificador binario kernelizado normalmente calcula una suma ponderada de similitudes donde
Los clasificadores de kernel fueron descritos ya en la década de 1960, con la invención del perceptrón de kernel . [3] Alcanzaron gran prominencia con la popularidad de la máquina de vectores de soporte (SVM) en la década de 1990, cuando se descubrió que la SVM era competitiva con las redes neuronales en tareas como el reconocimiento de escritura a mano .
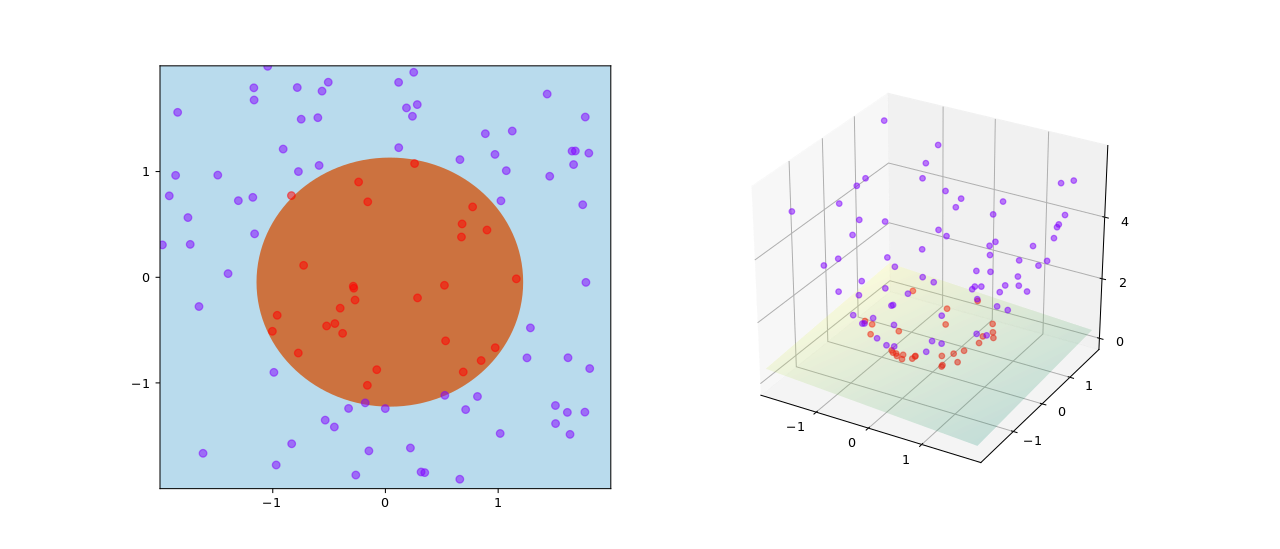
El truco del núcleo evita el mapeo explícito que se necesita para que los algoritmos de aprendizaje lineal aprendan una función no lineal o un límite de decisión . Para todos y en el espacio de entrada , ciertas funciones se pueden expresar como un producto interno en otro espacio . La función se conoce a menudo como núcleo o función de núcleo . La palabra "núcleo" se utiliza en matemáticas para denotar una función de ponderación para una suma o integral ponderada .
Ciertos problemas en el aprendizaje automático tienen más estructura que una función de ponderación arbitraria . El cálculo se hace mucho más simple si el núcleo se puede escribir en forma de un "mapa de características" que satisface La restricción clave es que debe ser un producto interno adecuado. Por otro lado, no es necesaria una representación explícita para, siempre que sea un espacio de producto interno . La alternativa se desprende del teorema de Mercer : existe una función definida implícitamente siempre que el espacio pueda equiparse con una medida adecuada que garantice que la función satisface la condición de Mercer .
El teorema de Mercer es similar a una generalización del resultado del álgebra lineal que asocia un producto interno a cualquier matriz definida positiva . De hecho, la condición de Mercer se puede reducir a este caso más simple. Si elegimos como medida la medida de conteo para todos los , que cuenta el número de puntos dentro del conjunto , entonces la integral en el teorema de Mercer se reduce a una suma Si esta suma se cumple para todas las secuencias finitas de puntos en y todas las elecciones de coeficientes de valor real (cf. kernel definido positivo ), entonces la función satisface la condición de Mercer.
Algunos algoritmos que dependen de relaciones arbitrarias en el espacio nativo tendrían, de hecho, una interpretación lineal en un entorno diferente: el espacio de rango de . La interpretación lineal nos da una idea sobre el algoritmo. Además, a menudo no hay necesidad de calcular directamente durante el cálculo, como es el caso de las máquinas de vectores de soporte . Algunos citan este atajo en el tiempo de ejecución como el beneficio principal. Los investigadores también lo utilizan para justificar los significados y las propiedades de los algoritmos existentes.
Teóricamente, una matriz de Gram con respecto a (a veces también llamada "matriz kernel" [4] ), donde , debe ser semidefinida positiva (PSD) . [5] Empíricamente, para las heurísticas de aprendizaje automático, las elecciones de una función que no satisfacen la condición de Mercer aún pueden funcionar razonablemente si al menos se aproximan a la idea intuitiva de similitud. [6] Independientemente de si es un kernel de Mercer, aún puede denominarse "kernel".
Si la función kernel es también una función de covarianza como la utilizada en los procesos gaussianos , entonces la matriz de Gram también puede denominarse matriz de covarianza . [7]
Las áreas de aplicación de los métodos kernel son diversas e incluyen geoestadística , [8] kriging , ponderación de distancia inversa , reconstrucción 3D , bioinformática , quimioinformática , extracción de información y reconocimiento de escritura a mano .




































