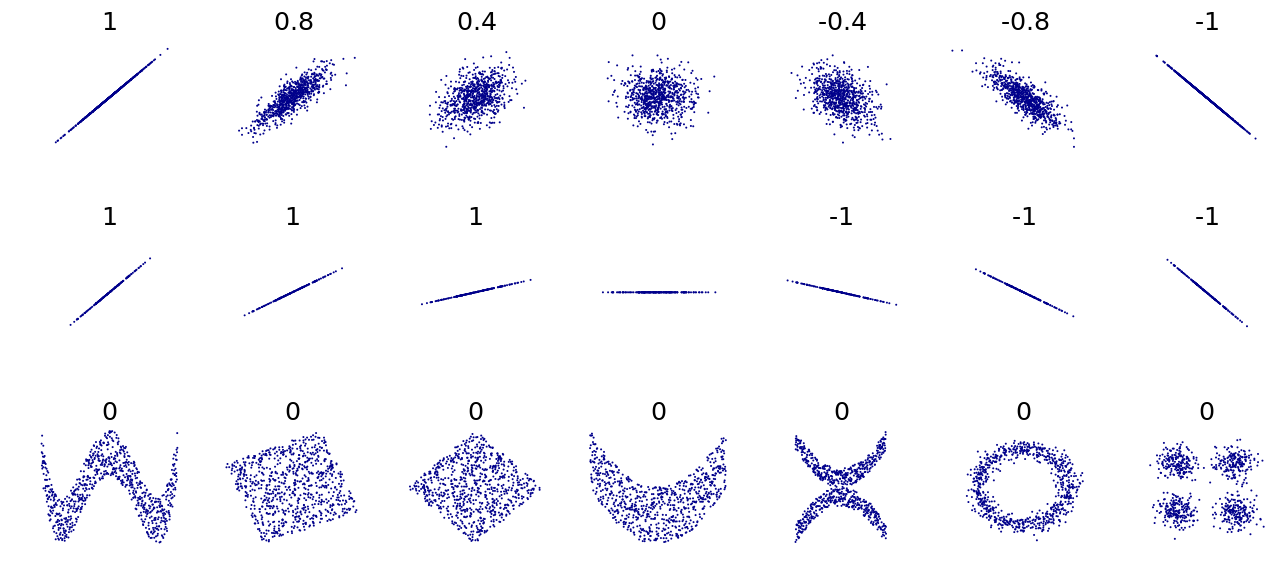
In statistics, correlation or dependence is any statistical relationship, whether causal or not, between two random variables or bivariate data. Although in the broadest sense, "correlation" may indicate any type of association, in statistics it usually refers to the degree to which a pair of variables are linearly related. Familiar examples of dependent phenomena include the correlation between the height of parents and their offspring, and the correlation between the price of a good and the quantity the consumers are willing to purchase, as it is depicted in the so-called demand curve.
Correlations are useful because they can indicate a predictive relationship that can be exploited in practice. For example, an electrical utility may produce less power on a mild day based on the correlation between electricity demand and weather. In this example, there is a causal relationship, because extreme weather causes people to use more electricity for heating or cooling. However, in general, the presence of a correlation is not sufficient to infer the presence of a causal relationship (i.e., correlation does not imply causation).
Formally, random variables are dependent if they do not satisfy a mathematical property of probabilistic independence. In informal parlance, correlation is synonymous with dependence. However, when used in a technical sense, correlation refers to any of several specific types of mathematical relationship between the conditional expectation of one variable given the other is not constant as the conditioning variable changes; broadly correlation in this specific sense is used when is related to in some manner (such as linearly, monotonically, or perhaps according to some particular functional form such as logarithmic). Essentially, correlation is the measure of how two or more variables are related to one another. There are several correlation coefficients, often denoted or , measuring the degree of correlation. The most common of these is the Pearson correlation coefficient, which is sensitive only to a linear relationship between two variables (which may be present even when one variable is a nonlinear function of the other). Other correlation coefficients – such as Spearman's rank correlation – have been developed to be more robust than Pearson's, that is, more sensitive to nonlinear relationships.[1][2][3] Mutual information can also be applied to measure dependence between two variables.

The most familiar measure of dependence between two quantities is the Pearson product-moment correlation coefficient (PPMCC), or "Pearson's correlation coefficient", commonly called simply "the correlation coefficient". It is obtained by taking the ratio of the covariance of the two variables in question of our numerical dataset, normalized to the square root of their variances. Mathematically, one simply divides the covariance of the two variables by the product of their standard deviations. Karl Pearson developed the coefficient from a similar but slightly different idea by Francis Galton.[4]
A Pearson product-moment correlation coefficient attempts to establish a line of best fit through a dataset of two variables by essentially laying out the expected values and the resulting Pearson's correlation coefficient indicates how far away the actual dataset is from the expected values. Depending on the sign of our Pearson's correlation coefficient, we can end up with either a negative or positive correlation if there is any sort of relationship between the variables of our data set.[citation needed]
The population correlation coefficient between two random variables and with expected values and and standard deviations and is defined as:
where is the expected value operator, means covariance, and is a widely used alternative notation for the correlation coefficient. The Pearson correlation is defined only if both standard deviations are finite and positive. An alternative formula purely in terms of moments is:
It is a corollary of the Cauchy–Schwarz inequality that the absolute value of the Pearson correlation coefficient is not bigger than 1. Therefore, the value of a correlation coefficient ranges between −1 and +1. The correlation coefficient is +1 in the case of a perfect direct (increasing) linear relationship (correlation), −1 in the case of a perfect inverse (decreasing) linear relationship (anti-correlation),[5] and some value in the open interval in all other cases, indicating the degree of linear dependence between the variables. As it approaches zero there is less of a relationship (closer to uncorrelated). The closer the coefficient is to either −1 or 1, the stronger the correlation between the variables.
If the variables are independent, Pearson's correlation coefficient is 0. However, because the correlation coefficient detects only linear dependencies between two variables, the converse is not necessarily true. A correlation coefficient of 0 does not imply that the variables are independent[citation needed].
For example, suppose the random variable is symmetrically distributed about zero, and . Then is completely determined by , so that and are perfectly dependent, but their correlation is zero; they are uncorrelated. However, in the special case when and are jointly normal, uncorrelatedness is equivalent to independence.
Even though uncorrelated data does not necessarily imply independence, one can check if random variables are independent if their mutual information is 0.
Given a series of measurements of the pair indexed by , the sample correlation coefficient can be used to estimate the population Pearson correlation between and . The sample correlation coefficient is defined as
where and are the sample means of and , and and are the corrected sample standard deviations of and .
Equivalent expressions for are
where and are the uncorrected sample standard deviations of and .
If and are results of measurements that contain measurement error, the realistic limits on the correlation coefficient are not −1 to +1 but a smaller range.[6] For the case of a linear model with a single independent variable, the coefficient of determination (R squared) is the square of , Pearson's product-moment coefficient.
Consider the joint probability distribution of X and Y given in the table below.
For this joint distribution, the marginal distributions are:
This yields the following expectations and variances:
Therefore:
Rank correlation coefficients, such as Spearman's rank correlation coefficient and Kendall's rank correlation coefficient (τ) measure the extent to which, as one variable increases, the other variable tends to increase, without requiring that increase to be represented by a linear relationship. If, as the one variable increases, the other decreases, the rank correlation coefficients will be negative. It is common to regard these rank correlation coefficients as alternatives to Pearson's coefficient, used either to reduce the amount of calculation or to make the coefficient less sensitive to non-normality in distributions. However, this view has little mathematical basis, as rank correlation coefficients measure a different type of relationship than the Pearson product-moment correlation coefficient, and are best seen as measures of a different type of association, rather than as an alternative measure of the population correlation coefficient.[7][8]
To illustrate the nature of rank correlation, and its difference from linear correlation, consider the following four pairs of numbers :
As we go from each pair to the next pair increases, and so does . This relationship is perfect, in the sense that an increase in is always accompanied by an increase in . This means that we have a perfect rank correlation, and both Spearman's and Kendall's correlation coefficients are 1, whereas in this example Pearson product-moment correlation coefficient is 0.7544, indicating that the points are far from lying on a straight line. In the same way if always decreases when increases, the rank correlation coefficients will be −1, while the Pearson product-moment correlation coefficient may or may not be close to −1, depending on how close the points are to a straight line. Although in the extreme cases of perfect rank correlation the two coefficients are both equal (being both +1 or both −1), this is not generally the case, and so values of the two coefficients cannot meaningfully be compared.[7] For example, for the three pairs (1, 1) (2, 3) (3, 2) Spearman's coefficient is 1/2, while Kendall's coefficient is 1/3.
The information given by a correlation coefficient is not enough to define the dependence structure between random variables.[9] The correlation coefficient completely defines the dependence structure only in very particular cases, for example when the distribution is a multivariate normal distribution. (See diagram above.) In the case of elliptical distributions it characterizes the (hyper-)ellipses of equal density; however, it does not completely characterize the dependence structure (for example, a multivariate t-distribution's degrees of freedom determine the level of tail dependence).
For continuous variables, multiple alternative measures of dependence were introduced to address the deficiency of Pearson's correlation that it can be zero for dependent random variables (see [10] and reference references therein for an overview). They all share the important property that a value of zero implies independence. This led some authors [10][11] to recommend their routine usage, particularly of Distance correlation[12][13]. Another alternative measure is the Randomized Dependence Coefficient[14]. The RDC is a computationally efficient, copula-based measure of dependence between multivariate random variables and is invariant with respect to non-linear scalings of random variables.
One important disadvantage of the alternative, more general measures is that, when used to test whether two variables are associated, they tend to have lower power compared to Pearson's correlation when the data follow a multivariate normal distribution [10]. This is an implication of the No free lunch theorem theorem. To detect all kinds of relationships, these measures have to sacrifice power on other relationships, particularly for the important special case of a linear relationship with Gaussian marginals, for which Pearson's correlation is optimal. Another problem concerns interpretation. While Person's correlation can be interpreted for all values, the alternative measures can generally only be interpreted meaningfull at the extremes [15].
For two binary variables, the odds ratio measures their dependence, and takes range non-negative numbers, possibly infinity: . Related statistics such as Yule's Y and Yule's Q normalize this to the correlation-like range . The odds ratio is generalized by the logistic model to model cases where the dependent variables are discrete and there may be one or more independent variables.
The correlation ratio, entropy-based mutual information, total correlation, dual total correlation and polychoric correlation are all also capable of detecting more general dependencies, as is consideration of the copula between them, while the coefficient of determination generalizes the correlation coefficient to multiple regression.
The degree of dependence between variables X and Y does not depend on the scale on which the variables are expressed. That is, if we are analyzing the relationship between X and Y, most correlation measures are unaffected by transforming X to a + bX and Y to c + dY, where a, b, c, and d are constants (b and d being positive). This is true of some correlation statistics as well as their population analogues. Some correlation statistics, such as the rank correlation coefficient, are also invariant to monotone transformations of the marginal distributions of X and/or Y.

Most correlation measures are sensitive to the manner in which X and Y are sampled. Dependencies tend to be stronger if viewed over a wider range of values. Thus, if we consider the correlation coefficient between the heights of fathers and their sons over all adult males, and compare it to the same correlation coefficient calculated when the fathers are selected to be between 165 cm and 170 cm in height, the correlation will be weaker in the latter case. Several techniques have been developed that attempt to correct for range restriction in one or both variables, and are commonly used in meta-analysis; the most common are Thorndike's case II and case III equations.[16]
Various correlation measures in use may be undefined for certain joint distributions of X and Y. For example, the Pearson correlation coefficient is defined in terms of moments, and hence will be undefined if the moments are undefined. Measures of dependence based on quantiles are always defined. Sample-based statistics intended to estimate population measures of dependence may or may not have desirable statistical properties such as being unbiased, or asymptotically consistent, based on the spatial structure of the population from which the data were sampled.
Sensitivity to the data distribution can be used to an advantage. For example, scaled correlation is designed to use the sensitivity to the range in order to pick out correlations between fast components of time series.[17] By reducing the range of values in a controlled manner, the correlations on long time scale are filtered out and only the correlations on short time scales are revealed.
The correlation matrix of random variables is the matrix whose entry is
Thus the diagonal entries are all identically one. If the measures of correlation used are product-moment coefficients, the correlation matrix is the same as the covariance matrix of the standardized random variables for . This applies both to the matrix of population correlations (in which case is the population standard deviation), and to the matrix of sample correlations (in which case denotes the sample standard deviation). Consequently, each is necessarily a positive-semidefinite matrix. Moreover, the correlation matrix is strictly positive definite if no variable can have all its values exactly generated as a linear function of the values of the others.
The correlation matrix is symmetric because the correlation between and is the same as the correlation between and .
A correlation matrix appears, for example, in one formula for the coefficient of multiple determination, a measure of goodness of fit in multiple regression.
In statistical modelling, correlation matrices representing the relationships between variables are categorized into different correlation structures, which are distinguished by factors such as the number of parameters required to estimate them. For example, in an exchangeable correlation matrix, all pairs of variables are modeled as having the same correlation, so all non-diagonal elements of the matrix are equal to each other. On the other hand, an autoregressive matrix is often used when variables represent a time series, since correlations are likely to be greater when measurements are closer in time. Other examples include independent, unstructured, M-dependent, and Toeplitz.
In exploratory data analysis, the iconography of correlations consists in replacing a correlation matrix by a diagram where the "remarkable" correlations are represented by a solid line (positive correlation), or a dotted line (negative correlation).
In some applications (e.g., building data models from only partially observed data) one wants to find the "nearest" correlation matrix to an "approximate" correlation matrix (e.g., a matrix which typically lacks semi-definite positiveness due to the way it has been computed).
In 2002, Higham[18] formalized the notion of nearness using the Frobenius norm and provided a method for computing the nearest correlation matrix using the Dykstra's projection algorithm, of which an implementation is available as an online Web API.[19]
This sparked interest in the subject, with new theoretical (e.g., computing the nearest correlation matrix with factor structure[20]) and numerical (e.g. usage the Newton's method for computing the nearest correlation matrix[21]) results obtained in the subsequent years.
Similarly for two stochastic processes and : If they are independent, then they are uncorrelated.[22]: p. 151 The opposite of this statement might not be true. Even if two variables are uncorrelated, they might not be independent to each other.
The conventional dictum that "correlation does not imply causation" means that correlation cannot be used by itself to infer a causal relationship between the variables.[23] This dictum should not be taken to mean that correlations cannot indicate the potential existence of causal relations. However, the causes underlying the correlation, if any, may be indirect and unknown, and high correlations also overlap with identity relations (tautologies), where no causal process exists. Consequently, a correlation between two variables is not a sufficient condition to establish a causal relationship (in either direction).
A correlation between age and height in children is fairly causally transparent, but a correlation between mood and health in people is less so. Does improved mood lead to improved health, or does good health lead to good mood, or both? Or does some other factor underlie both? In other words, a correlation can be taken as evidence for a possible causal relationship, but cannot indicate what the causal relationship, if any, might be.

The Pearson correlation coefficient indicates the strength of a linear relationship between two variables, but its value generally does not completely characterize their relationship.[24] In particular, if the conditional mean of given , denoted , is not linear in , the correlation coefficient will not fully determine the form of .
The adjacent image shows scatter plots of Anscombe's quartet, a set of four different pairs of variables created by Francis Anscombe.[25] The four variables have the same mean (7.5), variance (4.12), correlation (0.816) and regression line (). However, as can be seen on the plots, the distribution of the variables is very different. The first one (top left) seems to be distributed normally, and corresponds to what one would expect when considering two variables correlated and following the assumption of normality. The second one (top right) is not distributed normally; while an obvious relationship between the two variables can be observed, it is not linear. In this case the Pearson correlation coefficient does not indicate that there is an exact functional relationship: only the extent to which that relationship can be approximated by a linear relationship. In the third case (bottom left), the linear relationship is perfect, except for one outlier which exerts enough influence to lower the correlation coefficient from 1 to 0.816. Finally, the fourth example (bottom right) shows another example when one outlier is enough to produce a high correlation coefficient, even though the relationship between the two variables is not linear.
These examples indicate that the correlation coefficient, as a summary statistic, cannot replace visual examination of the data. The examples are sometimes said to demonstrate that the Pearson correlation assumes that the data follow a normal distribution, but this is only partially correct.[4] The Pearson correlation can be accurately calculated for any distribution that has a finite covariance matrix, which includes most distributions encountered in practice. However, the Pearson correlation coefficient (taken together with the sample mean and variance) is only a sufficient statistic if the data is drawn from a multivariate normal distribution. As a result, the Pearson correlation coefficient fully characterizes the relationship between variables if and only if the data are drawn from a multivariate normal distribution.
If a pair of random variables follows a bivariate normal distribution, the conditional mean is a linear function of , and the conditional mean is a linear function of The correlation coefficient between and and the marginal means and variances of and determine this linear relationship:
where and are the expected values of and respectively, and and are the standard deviations of and respectively.
The empirical correlation is an estimate of the correlation coefficient A distribution estimate for is given by
where is the Gaussian hypergeometric function.
This density is both a Bayesian posterior density and an exact optimal confidence distribution density.[26][27]
{{cite journal}}: CS1 maint: date and year (link)










![{\displaystyle \rho _{X,Y}=\operatorname {corr} (X,Y)={\operatorname {cov} (X,Y) \over \sigma _{X}\sigma _{Y}}={\operatorname {E} [(X-\mu _{X})(Y-\mu _{Y})] \over \sigma _{X}\sigma _{Y}},\quad {\text{if}}\ \sigma _{X}\sigma _{Y}>0.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b551ad29592ae746bf05fe397fbdc56201f483a5)
















![{\displaystyle {\begin{aligned}r_{xy}&={\frac {\sum x_{i}y_{i}-n{\bar {x}}{\bar {y}}}{ns'_{x}s'_{y}}}\\[5pt]&={\frac {n\sum x_{i}y_{i}-\sum x_{i}\sum y_{i}}{{\sqrt {n\sum x_{i}^{2}-(\sum x_{i})^{2}}}~{\sqrt {n\sum y_{i}^{2}-(\sum y_{i})^{2}}}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6da33b8144a5e67959969ef2c4830ece1938bbb2)









![{\displaystyle {\begin{aligned}\rho _{X,Y}&={\frac {1}{\sigma _{X}\sigma _{Y}}}\mathrm {E} [(X-\mu _{X})(Y-\mu _{Y})]\\[5pt]&={\frac {1}{\sigma _{X}\sigma _{Y}}}\sum _{x,y}{(x-\mu _{X})(y-\mu _{Y})\mathrm {P} (X=x,Y=y)}\\[5pt]&={\frac {3{\sqrt {3}}}{2}}\left(\left(1-{\frac {2}{3}}\right)(-1-0){\frac {1}{3}}+\left(0-{\frac {2}{3}}\right)(0-0){\frac {1}{3}}+\left(1-{\frac {2}{3}}\right)(1-0){\frac {1}{3}}\right)=0.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5c3ce03c3f9ad954e17f3a92d5314a9a3f669c29)

![{\displaystyle [0,+\infty ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f32245981f739c86ea8f68ce89b1ad6807428d35)
![{\displaystyle [-1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51e3b7f14a6f70e614728c583409a0b9a8b9de01)






























