Método estadístico de análisis que busca construir una jerarquía de conglomerados.
En minería de datos y estadística , la agrupación jerárquica (también denominada análisis de conglomerados jerárquico o HCA ) es un método de análisis de conglomerados que busca construir una jerarquía de conglomerados. Las estrategias para la agrupación jerárquica generalmente se dividen en dos categorías:
Aglomerativo : se trata de un enfoque " de abajo hacia arriba ": cada observación comienza en su propio grupo y los pares de grupos se fusionan a medida que uno asciende en la jerarquía.
Divisivo : este es un enfoque " de arriba hacia abajo ": todas las observaciones comienzan en un grupo y las divisiones se realizan de forma recursiva a medida que uno se desplaza hacia abajo en la jerarquía.
En general, las fusiones y divisiones se determinan de manera voraz . Los resultados de la agrupación jerárquica [1] suelen presentarse en un dendrograma .
La agrupación jerárquica tiene la clara ventaja de que se puede utilizar cualquier medida válida de distancia. De hecho, no se requieren las observaciones en sí: todo lo que se utiliza es una matriz de distancias . Por otro lado, excepto en el caso especial de la distancia de enlace único, no se puede garantizar que ninguno de los algoritmos (excepto la búsqueda exhaustiva en ) encuentre la solución óptima.
Complejidad
El algoritmo estándar para el agrupamiento aglomerativo jerárquico (HAC) tiene una complejidad temporal de y requiere memoria, lo que lo hace demasiado lento incluso para conjuntos de datos medianos. Sin embargo, para algunos casos especiales, se conocen métodos aglomerativos eficientes óptimos (de complejidad ): SLINK [2] para agrupamiento de enlace único y CLINK [3] para agrupamiento de enlace completo . Con un montón , el tiempo de ejecución del caso general se puede reducir a , una mejora en el límite mencionado anteriormente de , a costa de aumentar aún más los requisitos de memoria. En muchos casos, los gastos generales de memoria de este enfoque son demasiado grandes para que sea prácticamente utilizable. Existen métodos que utilizan árboles cuádruples que demuestran el tiempo de ejecución total con el espacio. [4]
La agrupación divisiva con una búsqueda exhaustiva es , pero es común utilizar heurísticas más rápidas para elegir divisiones, como k -medias .
Vinculación de clústeres
Para decidir qué grupos se deben combinar (para aglomeración) o dónde se debe dividir un grupo (para división), se requiere una medida de disimilitud entre conjuntos de observaciones. En la mayoría de los métodos de agrupamiento jerárquico, esto se logra mediante el uso de una distancia apropiada d , como la distancia euclidiana, entre observaciones individuales del conjunto de datos, y un criterio de vinculación, que especifica la disimilitud de los conjuntos como una función de las distancias por pares de observaciones en los conjuntos. La elección de la métrica, así como la vinculación, pueden tener un impacto importante en el resultado del agrupamiento, donde la métrica de nivel inferior determina qué objetos son más similares , mientras que el criterio de vinculación influye en la forma de los grupos. Por ejemplo, la vinculación completa tiende a producir grupos más esféricos que la vinculación simple.
El criterio de vinculación determina la distancia entre conjuntos de observaciones en función de las distancias por pares entre observaciones.
Algunos criterios de vinculación comúnmente utilizados entre dos conjuntos de observaciones A y B y una distancia d son: [5] [6]
Algunas de ellas solo se pueden recalcular de forma recursiva (WPGMA, WPGMC); para muchas, un cálculo recursivo con ecuaciones de Lance-Williams es más eficiente, mientras que para otras (Hausdorff, Medoid) las distancias se deben calcular con la fórmula completa, que es más lenta. Otros criterios de vinculación incluyen:
La probabilidad de que grupos de candidatos surjan de la misma función de distribución (vinculación V).
El producto del grado de entrada y el grado de salida en un grafo de k vecinos más cercanos (vinculación de grado de grafo). [14]
El incremento de algún descriptor de clúster (es decir, una cantidad definida para medir la calidad de un clúster) después de fusionar dos clústeres. [15] [16] [17]
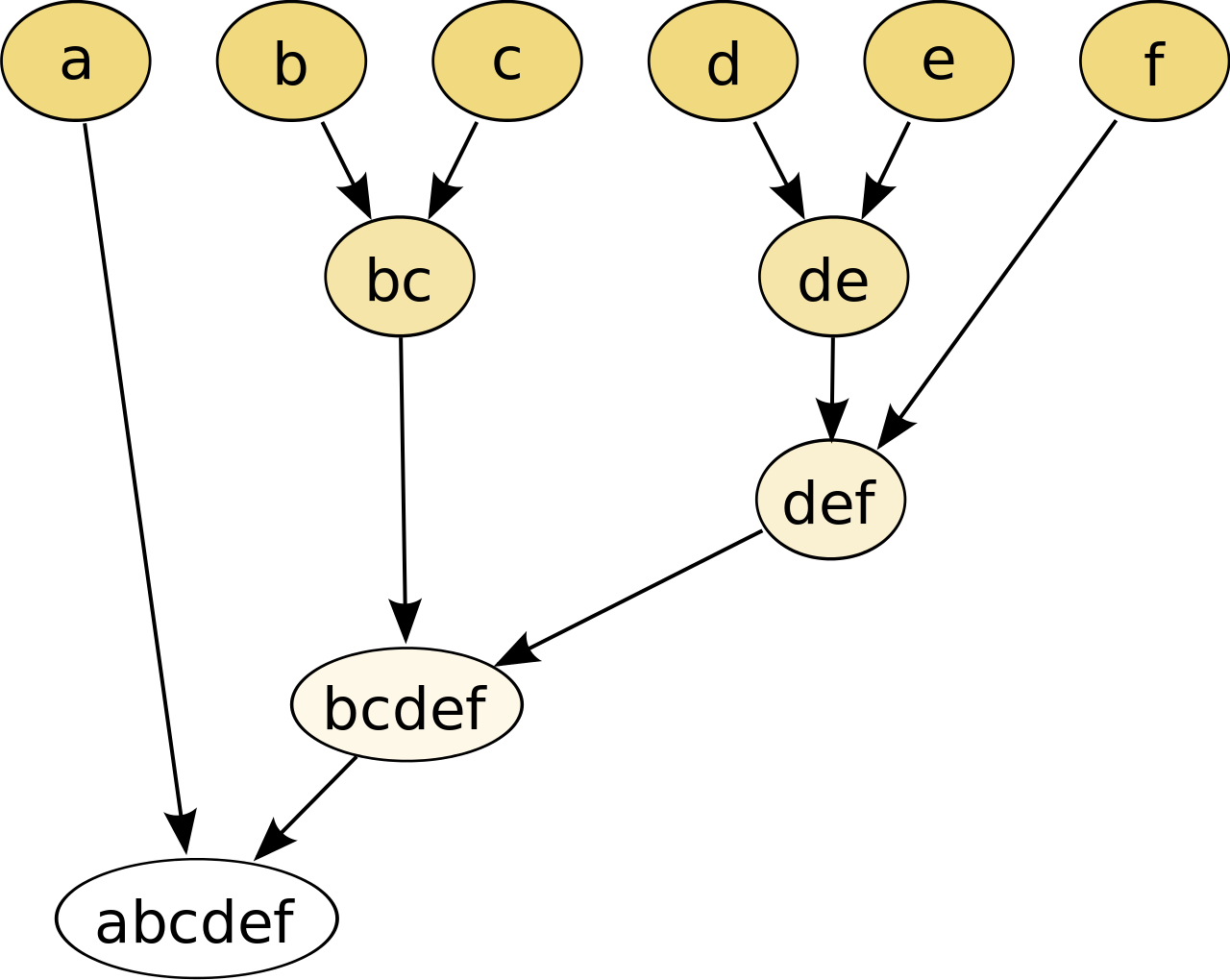
Cortar el árbol a una altura determinada dará como resultado una agrupación de particiones con una precisión seleccionada. En este ejemplo, cortar después de la segunda fila (desde arriba) del dendrograma dará como resultado agrupaciones {a} {bc} {de} {f}. Cortar después de la tercera fila dará como resultado agrupaciones {a} {bc} {def}, que es una agrupación más burda, con una cantidad menor pero agrupaciones más grandes.
Este método construye la jerarquía a partir de los elementos individuales fusionando progresivamente los clústeres. En nuestro ejemplo, tenemos seis elementos {a} {b} {c} {d} {e} y {f}. El primer paso es determinar qué elementos fusionar en un clúster. Por lo general, queremos tomar los dos elementos más cercanos, según la distancia elegida.
Opcionalmente, también se puede construir una matriz de distancia en esta etapa, donde el número en la i -ésima fila y la j -ésima columna es la distancia entre los elementos i -ésimo y j -ésimo. Luego, a medida que avanza la agrupación, las filas y columnas se fusionan a medida que se fusionan los clústeres y se actualizan las distancias. Esta es una forma común de implementar este tipo de agrupación y tiene el beneficio de almacenar en caché las distancias entre clústeres. En la página de agrupación de enlace único se describe un algoritmo de agrupación aglomerativa simple ; se puede adaptar fácilmente a diferentes tipos de enlace (ver a continuación).
Supongamos que hemos fusionado los dos elementos más cercanos b y c , ahora tenemos los siguientes clústeres { a }, { b , c }, { d }, { e } y { f }, y queremos fusionarlos aún más. Para ello, necesitamos tomar la distancia entre {a} y {bc} y, por lo tanto, definir la distancia entre dos clústeres. Por lo general, la distancia entre dos clústeres y es una de las siguientes:
La distancia media entre los elementos de cada grupo (también llamada agrupamiento por enlace promedio, utilizada, por ejemplo, en UPGMA ):
La suma de todas las varianzas dentro del grupo.
El aumento de la varianza para el grupo que se fusiona ( método de Ward [8] )
La probabilidad de que grupos de candidatos surjan de la misma función de distribución (vinculación V).
En caso de existir distancias mínimas empatadas, se elige un par al azar, pudiendo así generar varios dendrogramas estructuralmente diferentes. Alternativamente, todos los pares empatados pueden unirse al mismo tiempo, generando un dendrograma único. [18]
Siempre se puede decidir detener la agrupación cuando hay un número suficientemente pequeño de agrupaciones (criterio de número). Algunos vínculos también pueden garantizar que la aglomeración se produzca a una distancia mayor entre agrupaciones que la aglomeración anterior, y entonces se puede detener la agrupación cuando las agrupaciones están demasiado separadas para fusionarse (criterio de distancia). Sin embargo, este no es el caso, por ejemplo, del vínculo centroide donde pueden ocurrir las llamadas reversiones [19] (inversiones, desviaciones de la ultrametricidad).
Agrupamiento divisorio
El principio básico del agrupamiento divisivo se publicó como algoritmo DIANA (Divisive ANAlysis clustering). [20] Inicialmente, todos los datos están en el mismo clúster y el clúster más grande se divide hasta que cada objeto esté separado. Debido a que existen formas de dividir cada clúster, se necesitan heurísticas. DIANA elige el objeto con la máxima disimilitud promedio y luego mueve a este clúster todos los objetos que son más similares al nuevo clúster que al resto.
De manera informal, DIANA no es tanto un proceso de "división" como de "vaciamiento": en cada iteración, se elige un clúster existente (por ejemplo, el clúster inicial de todo el conjunto de datos) para formar un nuevo clúster dentro de él. Los objetos se mueven progresivamente a este clúster anidado y vacían el clúster existente. Finalmente, todo lo que queda dentro de un clúster son clústeres anidados que crecieron allí, sin que este posea ningún objeto suelto propio.
Formalmente, DIANA opera en los siguientes pasos:
Sea el conjunto de todos los índices de objetos y el conjunto de todos los clústeres formados hasta el momento.
Iterar lo siguiente hasta que :
Encuentre el grupo actual con 2 o más objetos que tenga el diámetro más grande:
Encuentre el objeto en este grupo con la mayor disimilitud con el resto del grupo:
Sácalo de su antiguo grupo y colócalo en un nuevo grupo fragmentado .
Mientras no esté vacío, siga migrando objetos desde para agregarlos a . Para elegir qué objetos migrar, no solo considere la disimilitud con , sino que también ajuste la disimilitud con el grupo fragmentado: dejemos donde definimos , luego dejemos de iterar cuando , o migremos .
Añadir .
Intuitivamente, lo anterior mide la fuerza con la que un objeto desea abandonar su grupo actual, pero se atenúa cuando el objeto tampoco encaja en el grupo fragmentado. Es probable que dichos objetos inicien su propio grupo fragmentado en algún momento.
El dendrograma de DIANA se puede construir dejando que el grupo fragmentado sea un hijo del grupo ahuecado cada vez. Esto construye un árbol que tiene como raíz grupos de objetos únicos como hojas.
ALGLIB implementa varios algoritmos de agrupamiento jerárquico (enlace único, enlace completo, Ward) en C++ y C# con memoria O(n²) y tiempo de ejecución O(n³).
ELKI incluye múltiples algoritmos de agrupamiento jerárquico, varias estrategias de vinculación y también incluye los eficientes algoritmos SLINK, [2] CLINK [3] y Anderberg, extracción de clústeres flexible a partir de dendrogramas y varios otros algoritmos de análisis de clústeres .
Julia tiene una implementación dentro del paquete Clustering.jl. [21]
Octave , el análogo GNU de MATLAB, implementa la agrupación jerárquica en la función "linkage".
Orange , una suite de software de minería de datos, incluye agrupamiento jerárquico con visualización interactiva de dendrogramas.
R tiene funciones integradas [22] y paquetes que proporcionan funciones para la agrupación jerárquica. [23] [24] [25]
SciPy implementa la agrupación jerárquica en Python, incluido el eficiente algoritmo SLINK.
scikit-learn también implementa la agrupación jerárquica en Python.
^ Nielsen, Frank (2016). "8. Agrupamiento jerárquico". Introducción a HPC con MPI para la ciencia de datos. Springer. págs. 195–211. ISBN 978-3-319-21903-5.
^ ab R. Sibson (1973). "SLINK: un algoritmo óptimamente eficiente para el método de clúster de enlace único" (PDF) . The Computer Journal . 16 (1). British Computer Society: 30–34. doi : 10.1093/comjnl/16.1.30 .
^ ab D. Defays (1977). "Un algoritmo eficiente para un método de enlace completo". The Computer Journal . 20 (4). British Computer Society: 364–6. doi :10.1093/comjnl/20.4.364.
^ Eppstein, David (31 de diciembre de 2001). "Agrupamiento jerárquico rápido y otras aplicaciones de pares dinámicos más cercanos". ACM Journal of Experimental Algorithmics . 5 : 1–es. arXiv : cs/9912014 . doi :10.1145/351827.351829. ISSN 1084-6654.
^ "El procedimiento CLUSTER: métodos de agrupamiento". Guía del usuario de SAS/STAT 9.2 . SAS Institute . Consultado el 26 de abril de 2009 .
^ Székely, GJ; Rizzo, ML (2005). "Agrupamiento jerárquico mediante distancias conjuntas entre dos grupos: extensión del método de varianza mínima de Ward". Revista de clasificación . 22 (2): 151–183. doi :10.1007/s00357-005-0012-9. S2CID 206960007.
^ Fernández, Alberto; Gómez, Sergio (2020). "Enlace versátil: una familia de estrategias de conservación de espacio para agrupamiento jerárquico aglomerativo". Revista de clasificación . 37 (3): 584–597. arXiv : 1906.09222 . doi :10.1007/s00357-019-09339-z. S2CID 195317052.
^ ab Ward, Joe H. (1963). "Agrupamiento jerárquico para optimizar una función objetivo". Revista de la Asociación Estadounidense de Estadística . 58 (301): 236–244. doi :10.2307/2282967. JSTOR 2282967. MR 0148188.
^ abcd Podani, János (1989), Mucina, L.; Dale, MB (eds.), "Nuevos métodos de agrupamiento combinatorio", Sintaxonomía numérica , Dordrecht: Springer Netherlands, págs. 61–77, doi :10.1007/978-94-009-2432-1_5, ISBN978-94-009-2432-1, consultado el 4 de noviembre de 2022
^ Basalto, Nicolás; Bellotti, Roberto; De Carlo, Francisco; Facchi, Paolo; Pantaleo, Ester; Pascazio, Saverio (15 de junio de 2007). "Agrupación de Hausdorff de series temporales financieras". Physica A: Mecánica estadística y sus aplicaciones . 379 (2): 635–644. arXiv : física/0504014 . Código Bib : 2007PhyA..379..635B. doi :10.1016/j.physa.2007.01.011. ISSN 0378-4371. S2CID 27093582.
^ ab Schubert, Erich (2021). HACAM: agrupación aglomerativa jerárquica alrededor de medoides y sus limitaciones (PDF) . LWDA'21: Lernen, Wissen, Daten, Analysen del 1 al 3 de septiembre de 2021, Múnich, Alemania. págs. 191-204 - vía CEUR-WS.
^ Miyamoto, Sadaaki; Kaizu, Yousuke; Endo, Yasunori (2016). Agrupamiento jerárquico y no jerárquico de medoides utilizando medidas de similitud asimétrica. 2016, 8.ª Conferencia internacional conjunta sobre informática blanda y sistemas inteligentes (SCIS) y 17.º Simposio internacional sobre sistemas inteligentes avanzados (ISIS). págs. 400–403. doi :10.1109/SCIS-ISIS.2016.0091.
^ Herr, Dominik; Han, Qi; Lohmann, Steffen; Ertl, Thomas (2016). Reducción del desorden visual mediante proyección basada en jerarquía de datos etiquetados de alta dimensión (PDF) . Interfaz gráfica. Interfaz gráfica . doi :10.20380/gi2016.14 . Consultado el 4 de noviembre de 2022 .
^ Zhang, Wei; Wang, Xiaogang; Zhao, Deli; Tang, Xiaoou (2012). "Graph Degree Linkage: Agglomerative Clustering on a Directed Graph". En Fitzgibbon, Andrew; Lazebnik, Svetlana ; Perona, Pietro; Sato, Yoichi; Schmid, Cordelia (eds.). Visión artificial – ECCV 2012. Apuntes de clase en informática. Vol. 7572. Springer Berlin Heidelberg. págs. 428–441. arXiv : 1208.5092 . Código Bibliográfico :2012arXiv1208.5092Z. doi :10.1007/978-3-642-33718-5_31. ISBN .9783642337185.S2CID 14751 .Véase también: https://github.com/waynezhanghk/gacluster
^ Zhang, W.; Zhao, D.; Wang, X. (2013). "Agrupamiento aglomerativo mediante la integral de ruta incremental máxima". Reconocimiento de patrones . 46 (11): 3056–65. Bibcode :2013PatRe..46.3056Z. CiteSeerX 10.1.1.719.5355 . doi :10.1016/j.patcog.2013.04.013.
^ Zhao, D.; Tang, X. (2008). "Ciclismo de clústeres mediante la función zeta de un grafo". NIPS'08: Actas de la 21.ª Conferencia Internacional sobre Sistemas de Procesamiento de Información Neural . Curran. págs. 1953–60. CiteSeerX 10.1.1.945.1649 . ISBN.9781605609492.
^ Ma, Y.; Derksen, H.; Hong, W.; Wright, J. (2007). "Segmentación de datos mixtos multivariados mediante codificación y compresión de datos con pérdida". IEEE Transactions on Pattern Analysis and Machine Intelligence . 29 (9): 1546–62. doi :10.1109/TPAMI.2007.1085. hdl : 2142/99597 . PMID 17627043. S2CID 4591894.
^ Fernández, Alberto; Gómez, Sergio (2008). "Resolución de la no unicidad en el agrupamiento jerárquico aglomerativo mediante multidendrogramas". Journal of Classification . 25 (1): 43–65. arXiv : cs/0608049 . doi :10.1007/s00357-008-9004-x. S2CID 434036.
^ Kaufman, L.; Rousseeuw, PJ (2009) [1990]. "6. Análisis divisivo (Programa DIANA)". Encontrar grupos en los datos: una introducción al análisis de conglomerados . Wiley. págs. 253–279. ISBN978-0-470-31748-8.
^ "Agrupamiento jerárquico · Clustering.jl". juliastats.org . Consultado el 28 de febrero de 2022 .
^ "Función hclust - RDocumentation". www.rdocumentation.org . Consultado el 7 de junio de 2022 .
^ Galili, Tal; Benjamini, Yoav; Simpson, Gavin; Jefferis, Gregory (28 de octubre de 2021), dendextend: Extendiendo la funcionalidad del 'dendrograma' en R , consultado el 7 de junio de 2022
^ Paradis, Emmanuel; et al. "Ape: Análisis de filogenética y evolución" . Consultado el 28 de diciembre de 2022 .
^ Fernández, Alberto; Gómez, Sergio (12 de septiembre de 2021). «mdendro: agrupamiento jerárquico aglomerativo extendido» . Consultado el 28 de diciembre de 2022 .
Lectura adicional
Kaufman, L.; Rousseeuw, PJ (1990). Encontrar grupos en los datos: Introducción al análisis de conglomerados (1.ª ed.). Nueva York: John Wiley. ISBN 0-471-87876-6.
Hastie, Trevor ; Tibshirani, Robert ; Friedman, Jerome (2009). "14.3.12 Agrupamiento jerárquico". Los elementos del aprendizaje estadístico (2.ª ed.). Nueva York: Springer. págs. 520–8. ISBN 978-0-387-84857-0Archivado desde el original (PDF) el 10 de noviembre de 2009. Consultado el 20 de octubre de 2009 .