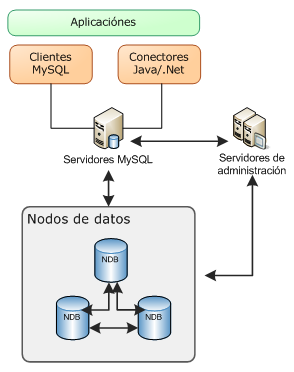
MySQL Cluster
En su implementación más sencilla, un clúster MySQL integra un servidor MySQL estándar y un motor de almacenamiento en memoria llamado NDB clúster, funcionando en un conjunto de una o más computadoras.
Estas transacciones deben cumplir con el esquema transaccional, tal y como si estuvieran trabajando directamente con un servidor no clusterizado de MySQL.
Debido a que controla y configura el resto de los nodos, debe iniciarse antes que cualquier otro tipo de nodos utilizando el comando ndb_mgmd.
Este tipo de nodo se levanta utilizando el comando ndbd.
Básicamente, consiste en un servidor MySQL Server que utiliza el motor de almacenamiento NDB.
Para conectarse a un cluster MySQL remotamente, se debe utilizar el mismo cliente utilizado para conectarse a un servidor MySQL no clusterizado.
A continuación presentamos un ejemplo con cuatro nodos de datos contenidos en dos grupos de nodos y cuatro particiones distribuidas entre estos dos grupos.
Con esto se logra un entorno con un alto grado de tolerancia a fallos.
Esto hace que si bien siempre existe la posibilidad de que uno o más nodos fallen, porciones más grandes de los datos estarán disponibles todo el tiempo, aumentando la tolerancia a falla de la manera que se considere necesaria.
Una manera fácil de asegurase que se dispone de la versión correcta para un clúster MySQL es invocando el comando SHOW ENGINES dentro del ambiente desde el servidor buscando la existencia del motor NDB.
Este comando muestra la totalidad de los motores soportados por el proceso actualmente instalado.
Análogamente a como se realiza con el nodo MySQL server, se debe especificar dirección IP y puerto del mismo en el archivo de configuración.
El proceso de ejecución utiliza un hilo para leer, escribir, escanear datos y realizar otras actividades.
El acceso a los archivos en el disco se realiza a través de múltiples hilos, manejando cada uno un archivo de datos en particular.
Es el proceso que controla el servidor de administración, siendo responsable de conocer y mantener la configuración del clúster y distribuir dicha información a todos los nodos que la soliciten al unirse al cluster.
Ese log es utilizado para realizar la sincronización de forma asíncrona en el servidor esclavo.