Atención (aprendizaje automático)
Los mecanismos similares a la atención se introdujeron en los años 90 con nombres como módulos multiplicativos, unidades sigma pi,[1] e hiperredes[.
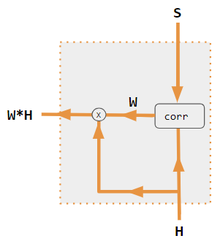
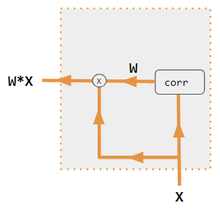
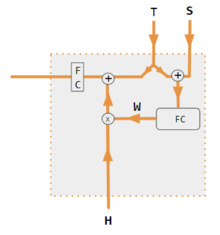
[5][6][7][8] Correlacionar las distintas partes de una frase o una imagen puede contribuir a captar su estructura.
El siguiente diagrama muestra cómo una red correctamente entrenada puede conseguirlo.
La frase de entrada se divide en 3 vías de procesamiento (izquierda) y se fusiona al final en el vector Context (derecha), que puede ser alimentado a otra capa neuronal para predecir la siguiente palabra o hacer otras tareas.
Notación: En este caso, la fórmula softmax por filas comúnmente escrita asume que los vectores son filas, lo que contradice la notación matemática estándar de vectores columna.
Esto supone una enorme ventaja sobre las redes recurrentes, que deben operar secuencialmente.
Las regiones grises de la matriz H y el vector w son valores cero.
En la segunda pasada por el descodificador, el 88% del peso de la atención está en la tercera palabra inglesa "you", por lo que ofrece "t'".
En la última pasada, el 95% de la atención se centra en la segunda palabra inglesa "love", por lo que ofrece "aime".