Modelo de regresión lineal con una única variable explicativa
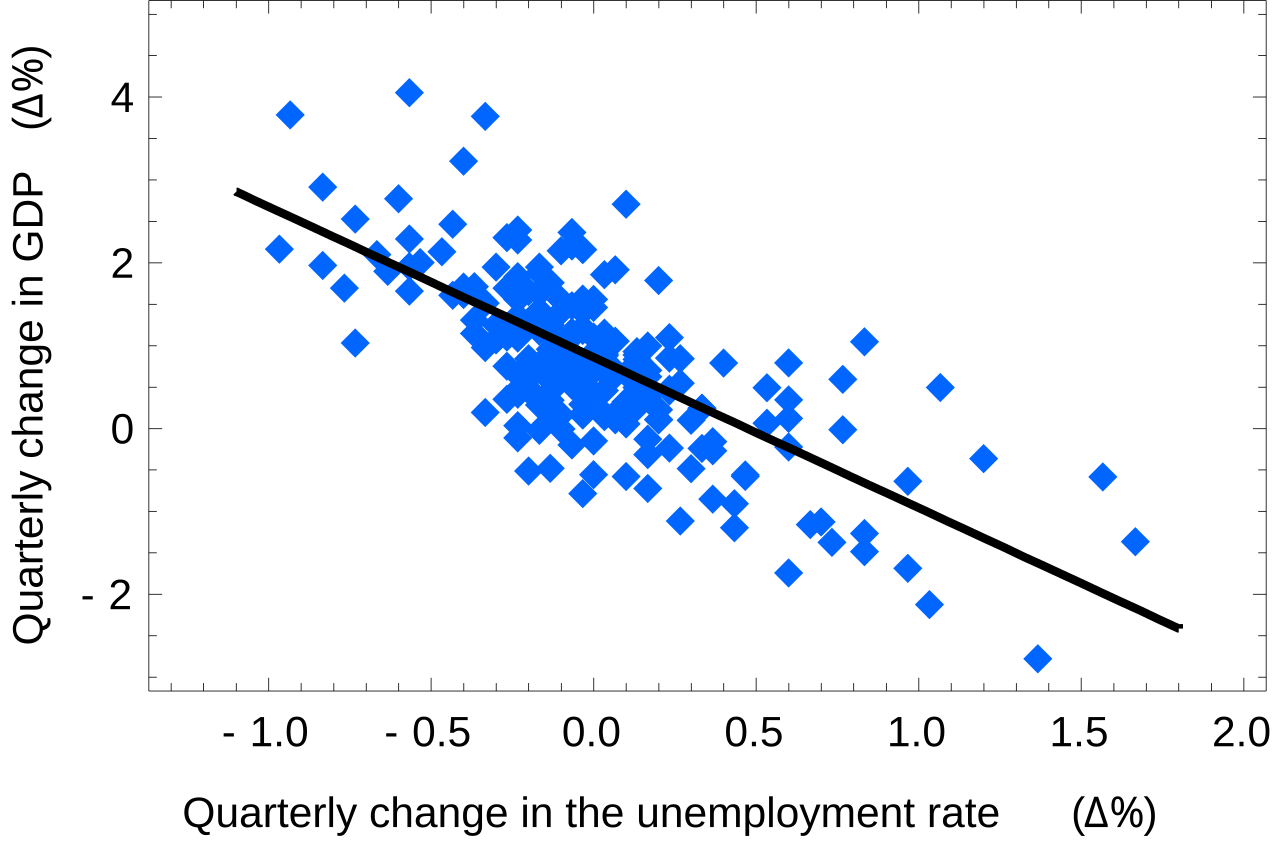
La ley de Okun en macroeconomía es un ejemplo de regresión lineal simple. En ella se supone que la variable dependiente (crecimiento del PIB) guarda una relación lineal con los cambios en la tasa de desempleo.
Es común hacer la estipulación adicional de que se debe utilizar el método de mínimos cuadrados ordinarios (MCO): la precisión de cada valor predicho se mide por su residuo al cuadrado (distancia vertical entre el punto del conjunto de datos y la línea ajustada), y el objetivo es hacer que la suma de estas desviaciones al cuadrado sea lo más pequeña posible. En este caso, la pendiente de la línea ajustada es igual a la correlación entre y y x corregida por la relación de las desviaciones estándar de estas variables. La intersección de la línea ajustada es tal que la línea pasa por el centro de masa ( x , y ) de los puntos de datos.
que describe una línea con pendiente β e intersección con el eje y α . En general, es posible que dicha relación no se cumpla exactamente para la población en gran parte no observada de valores de las variables dependientes e independientes; llamamos a las desviaciones no observadas de la ecuación anterior los errores . Supongamos que observamos n pares de datos y los llamamos {( x i , y i ), i = 1, ..., n }. Podemos describir la relación subyacente entre y i y x i que involucra este término de error ε i mediante
Esta relación entre los parámetros subyacentes verdaderos (pero no observados) α y β y los puntos de datos se denomina modelo de regresión lineal.
El objetivo es encontrar valores estimados y para los parámetros α y β que proporcionen el "mejor" ajuste en algún sentido para los puntos de datos. Como se mencionó en la introducción, en este artículo el "mejor" ajuste se entenderá como en el enfoque de mínimos cuadrados : una línea que minimiza la suma de los residuos al cuadrado (ver también Errores y residuos ) (diferencias entre los valores reales y predichos de la variable dependiente y ), cada uno de los cuales está dado por, para cualquier valor de parámetro candidato y ,
Al expandir para obtener una expresión cuadrática en y podemos derivar valores minimizadores de los argumentos de la función, denotados y : [6]
Aquí hemos presentado
y como el promedio de x i e y i , respectivamente
y como las desviaciones en x i e y i con respecto a sus respectivas medias.
Fórmulas expandidas
Las ecuaciones anteriores son eficientes si se conocen las medias de las variables x e y ( ). Si no se conocen las medias en el momento del cálculo, puede ser más eficiente utilizar la versión expandida de las ecuaciones. Estas ecuaciones expandidas se pueden derivar de las ecuaciones de regresión polinómica más generales [7] [8] definiendo el polinomio de regresión como de orden 1, de la siguiente manera.
El sistema de ecuaciones lineales anterior se puede resolver directamente, o se pueden derivar ecuaciones independientes mediante la expansión de las ecuaciones matriciales anteriores. Las ecuaciones resultantes son algebraicamente equivalentes a las que se muestran en el párrafo anterior y se muestran a continuación sin demostración. [9] [7]
Interpretación
Relación con la matriz de covarianza de la muestra
La solución se puede reformular utilizando elementos de la matriz de covarianza :
Sustituyendo las expresiones anteriores por y en la solución original se obtiene
Esto demuestra que r xy es la pendiente de la línea de regresión de los puntos de datos estandarizados (y que esta línea pasa por el origen). Por lo tanto, si x es una medición e y es una medición de seguimiento del mismo elemento, entonces esperamos que y (en promedio) esté más cerca de la medición media que del valor original de x. Este fenómeno se conoce como regresiones hacia la media .
Generalizando la notación, podemos escribir una barra horizontal sobre una expresión para indicar el valor promedio de esa expresión sobre el conjunto de muestras. Por ejemplo:
Esta notación nos permite una fórmula concisa para r xy :
Al multiplicar todos los miembros de la suma en el numerador por : (sin cambiarlo):
Podemos ver que la pendiente (tangente del ángulo) de la línea de regresión es el promedio ponderado de que es la pendiente (tangente del ángulo) de la línea que conecta el punto i-ésimo con el promedio de todos los puntos, ponderado por porque cuanto más lejos está el punto más "importante" es, ya que pequeños errores en su posición afectarán más la pendiente que lo conecta al punto central.
Interpretación sobre la intersección
Dado el ángulo que forma la línea con el eje x positivo, tenemos
Interpretación sobre la correlación
En la formulación anterior, observe que cada uno es un valor constante ("conocido de antemano"), mientras que son variables aleatorias que dependen de la función lineal de y del término aleatorio . Esta suposición se utiliza al derivar el error estándar de la pendiente y demostrar que es insesgado .
En este marco, cuando no es realmente una variable aleatoria , ¿qué tipo de parámetro estima la correlación empírica ? La cuestión es que para cada valor i tendremos: y . Una posible interpretación de es imaginar que define una variable aleatoria extraída de la distribución empírica de los valores x en nuestra muestra. Por ejemplo, si x tuviera 10 valores de los números naturales : [1,2,3...,10], entonces podemos imaginar que x es una distribución uniforme discreta . Bajo esta interpretación, todos tienen la misma expectativa y alguna varianza positiva. Con esta interpretación podemos pensar en como el estimador de la correlación de Pearson entre la variable aleatoria y y la variable aleatoria x (como la acabamos de definir).
Propiedades numéricas
La línea de regresión pasa por el punto del centro de masa , , si el modelo incluye un término de intersección (es decir, no está forzado a pasar por el origen).
La suma de los residuos es cero si el modelo incluye un término de intersección:
Los residuos y los valores x no están correlacionados (independientemente de que haya o no un término de intersección en el modelo), lo que significa que:
Para valores extremos esto es evidente. Desde cuándo entonces . Y cuándo entonces .
Propiedades estadísticas
La descripción de las propiedades estadísticas de los estimadores a partir de las estimaciones de regresión lineal simple requiere el uso de un modelo estadístico . Lo que sigue se basa en el supuesto de la validez de un modelo bajo el cual las estimaciones son óptimas. También es posible evaluar las propiedades bajo otros supuestos, como la falta de homogeneidad , pero esto se analiza en otra parte. [ Aclaración necesaria ]
Para formalizar esta afirmación debemos definir un marco en el que estos estimadores sean variables aleatorias. Consideramos los residuos ε i como variables aleatorias extraídas independientemente de alguna distribución con media cero. En otras palabras, para cada valor de x , el valor correspondiente de y se genera como una respuesta media α + βx más una variable aleatoria adicional ε llamada término de error , igual a cero en promedio. Bajo tal interpretación, los estimadores de mínimos cuadrados y serán en sí mismos variables aleatorias cuyas medias serán iguales a los "valores verdaderos" α y β . Esta es la definición de un estimador insesgado.
Varianza de la respuesta media
Dado que los datos en este contexto se definen como pares ( x , y ) para cada observación, la respuesta media en un valor dado de x , digamos x d , es una estimación de la media de los valores y en la población en el valor x de x d , es decir . La varianza de la respuesta media está dada por: [11]
Esta expresión se puede simplificar a
donde m es el número de puntos de datos.
Para demostrar esta simplificación, se puede hacer uso de la identidad
Varianza de la respuesta prevista
La distribución de respuesta prevista es la distribución prevista de los residuos en el punto dado x d . Por lo tanto, la varianza está dada por
La segunda línea se desprende del hecho de que es cero porque el nuevo punto de predicción es independiente de los datos utilizados para ajustar el modelo. Además, el término se calculó antes para la respuesta media.
Dado que (un parámetro fijo pero desconocido que se puede estimar), la varianza de la respuesta prevista está dada por
Intervalos de confianza
Las fórmulas dadas en la sección anterior permiten calcular las estimaciones puntuales de α y β , es decir, los coeficientes de la línea de regresión para el conjunto de datos dado. Sin embargo, esas fórmulas no nos dicen cuán precisas son las estimaciones, es decir, cuánto varían los estimadores de una muestra a otra para el tamaño de muestra especificado. Los intervalos de confianza se idearon para dar un conjunto plausible de valores a las estimaciones que uno podría tener si repitiera el experimento una gran cantidad de veces.
El método estándar para construir intervalos de confianza para coeficientes de regresión lineal se basa en el supuesto de normalidad, que se justifica si:
los errores en la regresión se distribuyen normalmente (el llamado supuesto de regresión clásica ), o
el número de observaciones n es suficientemente grande, en cuyo caso el estimador se distribuye aproximadamente de manera normal.
Bajo el primer supuesto anterior, el de la normalidad de los términos de error, el estimador del coeficiente de pendiente se distribuirá normalmente con media β y varianza donde σ 2 es la varianza de los términos de error (ver Demostraciones que involucran mínimos cuadrados ordinarios ). Al mismo tiempo, la suma de los residuos al cuadrado Q se distribuye proporcionalmente a χ 2 con n − 2 grados de libertad, e independientemente de . Esto nos permite construir un valor t
dónde
es el estimador de error estándar imparcial del estimador .
Este valor t tiene una distribución t de Student con n − 2 grados de libertad. Con él podemos construir un intervalo de confianza para β :
en el nivel de confianza (1 − γ ) , donde es el cuartil de la distribución t n −2 . Por ejemplo, si γ = 0,05 , entonces el nivel de confianza es del 95%.
De manera similar, el intervalo de confianza para el coeficiente de intersección α está dado por
en el nivel de confianza (1 − γ ), donde
Regresión “cambios en el desempleo – crecimiento del PIB” de EE.UU. con bandas de confianza del 95%.
Los intervalos de confianza para α y β nos dan una idea general de dónde es más probable que se encuentren estos coeficientes de regresión. Por ejemplo, en la regresión de la ley de Okun que se muestra aquí, las estimaciones puntuales son
Los intervalos de confianza del 95% para estas estimaciones son
Para representar gráficamente esta información, en forma de bandas de confianza alrededor de la línea de regresión, hay que proceder con cuidado y tener en cuenta la distribución conjunta de los estimadores. Se puede demostrar [12] que en el nivel de confianza (1 − γ ) la banda de confianza tiene forma hiperbólica dada por la ecuación
Cuando el modelo asume que la intersección es fija e igual a 0 ( ), el error estándar de la pendiente se convierte en:
Con:
Suposición asintótica
El segundo supuesto alternativo establece que cuando el número de puntos en el conjunto de datos es "suficientemente grande", la ley de los grandes números y el teorema del límite central se vuelven aplicables, y entonces la distribución de los estimadores es aproximadamente normal. Bajo este supuesto, todas las fórmulas derivadas en la sección anterior siguen siendo válidas, con la única excepción de que el cuantil t* n −2 de la distribución t de Student se reemplaza por el cuantil q* de la distribución normal estándar . Ocasionalmente, la fracción 1/n −2 se reemplaza con 1/norte . Cuando n es grande, tal cambio no altera los resultados de manera apreciable.
Ejemplo numérico
Este conjunto de datos proporciona las masas medias de las mujeres en función de su altura en una muestra de mujeres estadounidenses de entre 30 y 39 años. Aunque el artículo de MCO sostiene que sería más adecuado realizar una regresión cuadrática para estos datos, en su lugar se aplica el modelo de regresión lineal simple.
Hay n = 15 puntos en este conjunto de datos. Los cálculos manuales se iniciarían hallando las siguientes cinco sumas:
Estas cantidades se utilizarían para calcular las estimaciones de los coeficientes de regresión y sus errores estándar.
Gráfica de puntos y líneas de mínimos cuadrados lineales en el ejemplo numérico de regresión lineal simple
El cuartil 0,975 de la distribución t de Student con 13 grados de libertad es t * 13 = 2,1604 y, por lo tanto, los intervalos de confianza del 95 % para α y β son
Cálculo de los parámetros de un modelo lineal minimizando el error al cuadrado.
En SLR, existe un supuesto subyacente de que solo la variable dependiente contiene error de medición; si la variable explicativa también se mide con error, entonces la regresión simple no es apropiada para estimar la relación subyacente porque estará sesgada debido a la dilución de la regresión .
Otros métodos de estimación que pueden utilizarse en lugar de los mínimos cuadrados ordinarios incluyen las desviaciones mínimas absolutas (que minimizan la suma de los valores absolutos de los residuos) y el estimador de Theil-Sen (que elige una línea cuya pendiente es la mediana de las pendientes determinadas por pares de puntos de muestra).
La regresión de Deming (mínimos cuadrados totales) también encuentra una línea que se ajusta a un conjunto de puntos de muestra bidimensionales, pero (a diferencia de los mínimos cuadrados ordinarios, las desviaciones mínimas absolutas y la regresión de pendiente mediana) no es realmente una instancia de regresión lineal simple, porque no separa las coordenadas en una variable dependiente y una independiente y potencialmente podría devolver una línea vertical como su ajuste. puede conducir a un modelo que intente ajustar los valores atípicos más que los datos.
Enfoque de escala invariante: regresión del eje mayor Esto permite el error de medición en ambas variables y proporciona una ecuación equivalente si se alteran las unidades de medición.
Regresión lineal simple sin término de intersección (regresor único)
A veces es adecuado forzar la línea de regresión para que pase por el origen, porque se supone que x e y son proporcionales. Para el modelo sin el término de intersección, y = βx , el estimador MCO para β se simplifica a
Sustituyendo ( x − h , y − k ) en lugar de ( x , y ) se obtiene la regresión a través de ( h , k ) :
donde Cov y Var se refieren a la covarianza y varianza de los datos de muestra (sin corregir el sesgo). La última forma anterior demuestra cómo el alejamiento de la línea del centro de masa de los puntos de datos afecta la pendiente.
^ Seltman, Howard J. (8 de septiembre de 2008). Diseño y análisis experimental (PDF) . pág. 227.
^ "Muestreo estadístico y regresión: regresión lineal simple". Universidad de Columbia . Consultado el 17 de octubre de 2016. Cuando se utiliza una variable independiente en una regresión, se denomina regresión simple;(...)
^ Lane, David M. Introducción a la estadística (PDF) . pág. 462.
^ Zou KH; Tuncali K; Silverman SG (2003). "Correlación y regresión lineal simple". Radiología . 227 (3): 617–22. doi :10.1148/radiol.2273011499. ISSN 0033-8419. OCLC 110941167. PMID 12773666.
^ Kenney, JF y Keeping, ES (1962) "Regresión lineal y correlación". Cap. 15 en Matemáticas de estadística , parte 1, 3.ª ed. Princeton, NJ: Van Nostrand, págs. 252-285
^ ab Muthukrishnan, Gowri (17 de junio de 2018). "Matemáticas detrás de la regresión polinomial, Muthukrishnan". Matemáticas detrás de la regresión polinomial . Consultado el 30 de enero de 2024 .
^ "Matemáticas de la regresión polinómica". Regresión polinómica, una clase de regresión de PHP .
^ "Numeracy, Maths and Statistics - Academic Skills Kit, Newcastle University". Regresión lineal simple . Consultado el 30 de enero de 2024 .
^ Valliant, Richard, Jill A. Dever y Frauke Kreuter. Herramientas prácticas para diseñar y ponderar muestras de encuestas. Nueva York: Springer, 2013.
^ Draper, NR; Smith, H. (1998). Análisis de regresión aplicada (3.ª ed.). John Wiley. ISBN0-471-17082-8.
^ Casella, G. y Berger, RL (2002), "Inferencia estadística" (2.ª edición), Cengage, ISBN 978-0-534-24312-8 , pp. 558–559.
Enlaces externos
Explicación de Wolfram MathWorld sobre el ajuste por mínimos cuadrados y cómo calcularlo
Matemáticas de regresión simple (Robert Nau, Duke University)














![{\displaystyle {\begin{aligned}{\widehat {\alpha }}&={\bar {y}}-({\widehat {\beta }}\,{\bar {x}}),\\[5pt]{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}={\frac {\sum _{i=1}^{n}\Delta x_{i}\Delta y_{i}}{\sum _{i=1}^{n}\Delta x_{i}^{2}}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/59819b2ba266487624878946052a924ce01f12b4)







![{\displaystyle {\begin{aligned}&\qquad {\widehat {\alpha }}={\frac {\sum _{i=1}^{n}y_{i}\sum _{i=1}^{n}x_{i}^{2}-\sum _{i=1}^{n}x_{i}\sum _{i=1}^{n}x_{i}y_{i}}{n\sum _{i=1}^{n}x_{i}^{2}-(\sum _{i=1}^{n}x_{i})^{2}}}\\[5pt]\\&\qquad {\widehat {\beta }}={\frac {n\sum _{i=1}^{n}x_{i}y_{i}-\sum _{i=1}^{n}x_{i}\sum _{i=1}^{n}y_{i}}{n\sum _{i=1}^{n}x_{i}^{2}-(\sum _{i=1}^{n}x_{i})^{2}}}\\&\qquad \end{alineado}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6e22946f99289cf4bb175251c8f407edcaf4ab7)









![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}={\frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}{\frac {(y_{i}-{\bar {y}})}{(x_{i}-{\bar {x}})}}}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}=\sum _{i=1}^{n}{\frac {(x_{i}-{\bar {x}})^{2}}{\sum _{j=1}^{n}(x_{j}-{\bar {x}})^{2}}}{\frac {(y_{i}-{\bar {y}})}{(x_{i}-{\bar {x}})}}\\[6pt]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc26c9980ced33c9461b7e9b8aece55f65677e00)


![{\displaystyle {\begin{aligned}{\widehat {\alpha }}&={\bar {y}}-{\widehat {\beta }}\,{\bar {x}},\\[5pt]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e5ec3259ace40cc2734621fc00464bc5b87bc3fc)


























![{\displaystyle {\begin{aligned}\operatorname {Var} \left(y_{d}-\left[{\hat {\alpha }}+{\hat {\beta }}x_{d}\right]\right)&=\operatorname {Var} (y_{d})+\operatorname {Var} \left({\hat {\alpha }}+{\hat {\beta }}x_{d}\right)-2\operatorname {Cov} \left(y_{d},\left[{\hat {\alpha }}+{\hat {\beta }}x_{d}\right]\right)\\&=\operatorname {Var} (y_{d})+\operatorname {Var} \left({\hat {\alpha }}+{\hat {\beta }}x_{d}\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/80e47ac6a76b520bc1cda774dfb6531bf3a16383)
![{\displaystyle \operatorname {Cov} \left(y_{d},\left[{\hat {\alpha }}+{\hat {\beta }}x_{d}\right]\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fecd895228c749dd21da71a3cd5c661be5293f8e)


![{\displaystyle {\begin{aligned}\operatorname {Var} \left(y_{d}-\left[{\hat {\alpha }}+{\hat {\beta }}x_{d}\right]\right)&=\sigma ^{2}+\sigma ^{2}\left({\frac {1}{m}}+{\frac {\left(x_{d}-{\bar {x}}\right)^{2}}{\sum (x_{i}-{\bar {x}})^{2}}}\right)\\[4pt]&=\sigma ^{2}\left(1+{\frac {1}{m}}+{\frac {(x_{d}-{\bar {x}})^{2}}{\sum (x_{i}-{\bar {x}})^{2}}}\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bfc1ff83b96c55f305e73a134431d6b15cc91ffb)



![{\displaystyle \beta \in \left[{\widehat {\beta }}-s_{\widehat {\beta }}t_{n-2}^{*},\ {\widehat {\beta }}+s_{\widehat {\beta }}t_{n-2}^{*}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98a15da255d6643725a6bd9b50d02b3f6c2c497f)


![{\displaystyle \alpha \in \left[{\widehat {\alpha }}-s_{\widehat {\alpha }}t_{n-2}^{*},\ {\widehat {\alpha }}+s_{\widehat {\alpha }}t_{n-2}^{*}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6085d0ecef794ef2f78a3d3e0f9802acb9a4aada)


![{\displaystyle \alpha \en \izquierda[\,0.76,0.96\derecha],\qquad \beta \en \izquierda[-2.06,-1.58\,\derecha].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aca739a7d1ecc8fdddffbdea549b9acba00b464d)
![{\displaystyle (\alpha +\beta \xi )\in \left[\,{\widehat {\alpha }}+{\widehat {\beta }}\xi \pm t_{n-2}^{*}{\sqrt {\left({\frac {1}{n-2}}\sum {\widehat {\varepsilon }}_{i}^{\,2}\right)\cdot \left({\frac {1}{n}}+{\frac {(\xi -{\bar {x}})^{2}}{\sum (x_{i}-{\bar {x}})^{2}}}\right)}}\,\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7007e876b527e8f59c394898488fd150df4b9f61)



![{\displaystyle {\begin{aligned}S_{x}&=\sum x_{i}\,=24,76,\qquad S_{y}=\sum y_{i}\,=931,17,\\[5pt]S_{xx}&=\sum x_{i}^{2}=41,0532,\;\;\,S_{yy}=\sum y_{i}^{2}=58498,5439,\\[5pt]S_{xy}&=\sum x_{i}y_{i}=1548,2453\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a239d81a6a9897b666146526c8252a18d2603adf)
![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {nS_{xy}-S_{x}S_{y}}{nS_{xx}-S_{x}^{2}}}=61,272\\[8pt]{\widehat {\alpha }}&={\frac {1}{n}}S_{y}-{\widehat {\beta }}{\frac {1}{n}}S_{x}=-39,062\\[8pt]s_{\varepsilon }^{2}&={\frac {1}{n(n-2)}}\left[nS_{yy}-S_{y}^{2}-{\widehat {\beta }}^{2}(nS_{xx}-S_{x}^{2})\right]=0,5762\\[8pt]s_{\widehat {\beta }}^{2}&={\frac {ns_{\varepsilon }^{2}}{nS_{xx}-S_{x}^{2}}}=3,1539\\[8pt]s_{\widehat {\alpha }}^{2}&=s_{\widehat {\beta }}^{2}{\frac {1}{n}}S_{xx}=8,63185\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c171ecde06fcbcb38ea0c3e080b7c14efcfdd96)
![{\displaystyle {\begin{aligned}&\alpha \in [\,{\widehat {\alpha }}\mp t_{13}^{*}s_{\alpha }\,]=[\,{-45,4},\ {-32,7}\,]\\[5pt]&\beta \in [\,{\widehat {\beta }}\mp t_{13}^{*}s_{\beta }\,]=[\,57,4,\ 65,1\,]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f1e96281c93edfc8cb8e830744328f62081c8010)


![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}(x_{i}-h)(y_{i}-k)}{\sum _{i=1}^{n}(x_{i}-h)^{2}}}={\frac {\overline {(xh)(yk)}}{\overline {(xh)^{2}}}}\\[6pt]&={\frac {{\overline {xy}}-k{\bar {x}}-h{\bar {y}}+hk}{{\overline {x^{2}}}-2h{\bar {x}}+h^{2}}}\\[6pt]&={\frac {{\overline {xy}}-{\bar {x}}{\bar {y}}+({\bar {x}}-h)({\bar {y}}-k)}{{\overline {x^{2}}}-{\bar {x}}^{2}+({\bar {x}}-h)^{2}}}\\[6pt]&={\frac {\operatorname {Cov} (x,y)+({\bar {x}}-h)({\bar {y}}-k)}{\operatorname {Var} (x)+({\bar {x}}-h)^{2}}},\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d49812c28d9bc6840e891d5d04ae52a83397b840)