Red neuronal convolucional
Una red neuronal convolucional es un tipo de red neuronal artificial donde las neuronas artificiales, corresponden a campos receptivos de una manera muy similar a las neuronas en la corteza visual primaria (V1) de un cerebro biológico.
[3] Los fundamentos de las redes neuronales convolucionales se basan en el Neocognitron, introducido por Kunihiko Fukushima en 1980.
[4] Este modelo fue más tarde mejorado por Yann LeCun et al.
en 1998[5] al introducir un método de aprendizaje basado en la propagación hacia atrás para poder entrenar el sistema correctamente.
En el año 2012, fueron refinadas por Dan Ciresan y otros, y fueron implementadas para una unidad de procesamiento gráfico (GPU) consiguiendo así resultados impresionantes.
Dos tipos de células principales fueron identificadas aquí, teniendo éstas campos receptivos alargados, con lo cual tienen una mejor respuesta a los estímulos visuales alargados como las líneas y los bordes.
Las células simples tienen regiones excitadoras e inhibitorias, ambas formando patrones elementales alargados en una dirección, posición y tamaño en particular en cada célula.
Si un estímulo visual llega a la célula con la misma orientación y posición, de tal manera que ésta se alinea perfectamente con los patrones creados por las regiones excitadoras y al mismo tiempo se evita activar las regiones inhibitorias, la célula es activada y emite una señal.
Como las células simples, éstas tienen una orientación particular sobre la cual son sensibles.
Por ello, un estímulo visual necesita llegar únicamente en la orientación correcta para que esta célula sea activada.
Otro punto importante sobre las células en la corteza visual es la estructura que éstas forman.
Esto sucede como resultado de las células activando y propagando sus propios estímulos a otras células conectadas a esta jerarquía, principalmente gracias a la alternación entre células simples y complejas.
Después de cada capa, por lo general se añade una función para realizar un mapeo causal no-lineal.
Según progresan los datos a lo largo de esta fase, se disminuye su dimensionalidad, siendo las neuronas en capas lejanas mucho menos sensibles a perturbaciones en los datos de entrada, pero al mismo tiempo siendo estas activadas por características cada vez más complejas.
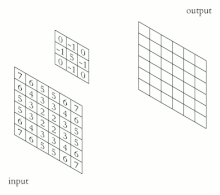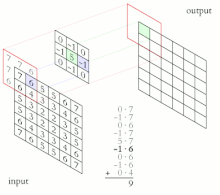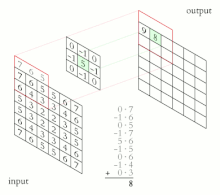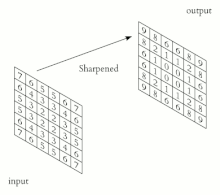
La salida de cada neurona convolucional se calcula como:
y luego se pasa por una función de activación
Esto transforma los datos de tal manera que ciertas características (determinadas por la forma del núcleo) se vuelven más dominantes en la imagen de salida al tener estas un valor numérico más alto asignados a los pixeles que las representan.
Sin embargo, los núcleos que son entrenados por una red neuronal convolucional generalmente son más complejos para poder extraer otras características más abstractas y no triviales.
Las redes neuronales cuentan con cierta tolerancia a pequeñas perturbaciones en los datos de entrada.
Por ejemplo, si dos imágenes casi idénticas (diferenciadas únicamente por un traslado de algunos pixeles lateralmente) se analizan con una red neuronal, el resultado debería de ser esencialmente el mismo.
Originalmente, las redes neuronales convolucionales utilizaban un proceso de subsampling para llevar a cabo esta operación.
Sin embargo, estudio recientes han demostrado que otras operaciones, como por ejemplo max-pooling[8] , son mucho más eficaces en resumir características sobre una región.
Además, existe evidencia que este tipo de operación es similar a como la corteza visual puede resumir información internamente.
y luego se pasa por una función de activación