CUDA
Funciona en todas las GPU Nvidia de la serie G8X en adelante, incluyendo GeForce, Quadro, ION y la línea Tesla.[1] Nvidia afirma que los programas desarrollados para la serie GeForce 8 también funcionarán sin modificaciones en todas las futuras tarjetas Nvidia, gracias a la compatibilidad binaria provista por el conjunto de instrucciones PTX (Parallel Thread Execution).El primer SDK se publicó en febrero de 2007 en un principio para Windows, Linux, y más adelante en su versión 2.0 para macOS.Ian Buck luego se unió a NVIDIA y lideró el lanzamiento de CUDA en 2006, la primera solución del mundo para computación general en GPU.[6] En 2006 Ian Buck se une a NVIDIA y lidera el lanzamiento de CUDA, la primera solución para el cómputo general en GPU.En 2007 se hace público el SDK 1.0 de CUDA para Microsoft Windows y Linux.Un aspecto importante en la historia de CUDA fue la relación que mantuvo con Apple, la cual estuvo marcada por varios conflictos y cambios en la dirección estratégica.CUDA presenta ciertas ventajas sobre otros tipos de computación sobre GPU utilizando APIs gráficas.Cada hilo en un bloque está identificado con un identificador único, que se accede con la variable threadIdx.Al igual que los hilos, los bloques se identifican mediante blockIdx (en sus componentes x, y, z).Por ejemplo: Si nuestra función f queremos que calcule la diferencia entre dos vectores A y B y lo almacene en un tercero C: Esta función se ejecutaría una vez en cada hilo, reduciendo el tiempo total de ejecución en gran medida, y dividiendo su complejidad, O(n), por una constante directamente relacionada con el número de procesadores disponibles.A cada hilo se le asignan sus propios datos de forma que cada copia realice la misma operación pero con datos diferentes, aprovechando así el paralelismo que ofrecen las GPUs.Como los distintos hilos colaboran entre ellos y pueden compartir datos, se requieren unas directivas de sincronización.Los hilos en CUDA pueden acceder a distintas memorias, unas compartidas y otras no.Todas las memorias de acceso global persisten mientras esté el kernel en ejecución.Un multiprocesador contiene ocho procesadores escalares, dos unidades especiales para funciones trascendentales, una unidad multihilo de instrucciones y una memoria compartida.Aunque el programador puede ignorar este comportamiento, conviene tenerlo en cuenta si se pretende optimizar alguna aplicación.Xcode: Si se desea trabajar en macOS y con CUDA, se puede configurar Xcode con las herramientas y extensiones adecuadas para admitir el desarrollo de CUDA en sistemas basados en macOS.Usan CUDA para todas las funciones en la rama MCH utilizadas para el pronóstico del tiempo operativo.El Driver de CUDA mantiene la compatibilidad con versiones anteriores para soportar aplicaciones creadas en Toolkits más antiguos.Con el paquete CUDA Forward Compatibility, los administradores del sistema pueden ejecutar aplicaciones creadas con un conjunto de herramientas más nuevo incluso cuando se instala en el sistema un Driver más antiguo que no cumple con la versión mínima requerida.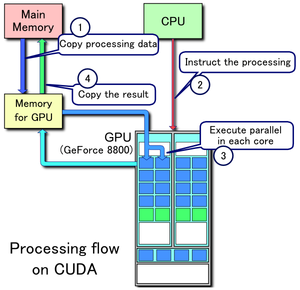
1. Se copian los datos de la memoria principal a la memoria de la GPU
2. La CPU encarga el proceso a la GPU
3. La GPU lo ejecuta en paralelo en cada núcleo
4. Se copia el resultado de la memoria de la GPU a la memoria principal