El Sistema de nombres de dominio ( DNS ) es un servicio de nombres distribuido y jerárquico que proporciona un sistema de nombres para computadoras , servicios y otros recursos en Internet u otras redes de Protocolo de Internet (IP). Asocia información diversa con nombres de dominio ( cadenas de identificación ) asignados a cada una de las entidades asociadas. Lo más destacado es que traduce nombres de dominio fácilmente memorizados a las direcciones IP numéricas necesarias para localizar e identificar servicios y dispositivos informáticos con los protocolos de red subyacentes . [1] El Sistema de nombres de dominio ha sido un componente esencial de la funcionalidad de Internet desde 1985.
El Sistema de nombres de dominio delega la responsabilidad de asignar nombres de dominio y mapear esos nombres a los recursos de Internet mediante la designación de servidores de nombres autorizados para cada dominio. Los administradores de red pueden delegar la autoridad sobre subdominios de su espacio de nombres asignado a otros servidores de nombres. Este mecanismo proporciona un servicio distribuido y tolerante a fallas y fue diseñado para evitar una única gran base de datos central. Además, el DNS especifica la funcionalidad técnica del servicio de base de datos que se encuentra en su núcleo. Define el protocolo DNS, una especificación detallada de las estructuras de datos y los intercambios de comunicación de datos utilizados en el DNS, como parte del conjunto de protocolos de Internet .
Internet mantiene dos espacios de nombres principales, la jerarquía de nombres de dominio y los espacios de direcciones IP . [2] El Sistema de nombres de dominio mantiene la jerarquía de nombres de dominio y proporciona servicios de traducción entre esta y los espacios de direcciones. Los servidores de nombres de Internet y un protocolo de comunicación implementan el Sistema de nombres de dominio. Un servidor de nombres DNS es un servidor que almacena los registros DNS de un dominio; un servidor de nombres DNS responde con respuestas a las consultas en su base de datos.
Los tipos de registros más comunes almacenados en la base de datos DNS son para inicio de autoridad ( SOA ), direcciones IP ( A y AAAA ), intercambiadores de correo SMTP (MX), servidores de nombres (NS), punteros para búsquedas DNS inversas (PTR) y alias de nombres de dominio (CNAME). Aunque no está pensado para ser una base de datos de propósito general, el DNS se ha ampliado con el tiempo para almacenar registros para otros tipos de datos para búsquedas automáticas, como registros DNSSEC , o para consultas humanas, como registros de persona responsable (RP). Como base de datos de propósito general, el DNS también se ha utilizado para combatir el correo electrónico no solicitado (spam) mediante el almacenamiento de una lista negra en tiempo real (RBL). La base de datos DNS se almacena tradicionalmente en un archivo de texto estructurado, el archivo de zona , pero otros sistemas de bases de datos son comunes.
El sistema de nombres de dominio utilizó originalmente el protocolo de datagramas de usuario (UDP) como transporte sobre IP. Las preocupaciones por la confiabilidad, la seguridad y la privacidad dieron lugar al uso del protocolo de control de transmisión (TCP), así como a numerosos otros desarrollos de protocolos.
Una analogía que se utiliza a menudo para explicar el DNS es que funciona como una guía telefónica para Internet al traducir los nombres de host de los ordenadores en direcciones IP. Por ejemplo, el nombre de host www.example.comdentro del nombre de dominio ejemplo.com se traduce a las direcciones 93.184.216.34 ( IPv4 ) y 2606:2800:220:1:248:1893:25c8:1946 ( IPv6 ). El DNS se puede actualizar de forma rápida y transparente, lo que permite cambiar la ubicación de un servicio en la red sin afectar a los usuarios finales, que siguen utilizando el mismo nombre de host. Los usuarios aprovechan esto cuando utilizan localizadores uniformes de recursos ( URL ) y direcciones de correo electrónico significativos sin tener que saber cómo localiza realmente el ordenador los servicios.
Una función importante y omnipresente del DNS es su papel central en los servicios distribuidos de Internet, como los servicios en la nube y las redes de distribución de contenido . [3] Cuando un usuario accede a un servicio distribuido de Internet mediante una URL, el nombre de dominio de la URL se traduce a la dirección IP de un servidor próximo al usuario. La funcionalidad clave del DNS explotada aquí es que diferentes usuarios pueden recibir simultáneamente diferentes traducciones para el mismo nombre de dominio, un punto clave de divergencia con respecto a una visión tradicional de la guía telefónica del DNS. Este proceso de uso del DNS para asignar servidores próximos a los usuarios es clave para proporcionar respuestas más rápidas y fiables en Internet y es ampliamente utilizado por la mayoría de los principales servicios de Internet. [4]
El DNS refleja la estructura de la responsabilidad administrativa en Internet. [5] Cada subdominio es una zona de autonomía administrativa delegada a un administrador. En el caso de las zonas operadas por un registro , la información administrativa suele complementarse con los servicios RDAP y WHOIS del registro . Esos datos se pueden utilizar para obtener información sobre un host determinado en Internet y realizar un seguimiento de la responsabilidad de dicho host. [6]
El uso de un nombre más simple y fácil de recordar en lugar de la dirección numérica de un host se remonta a la era de ARPANET . El Stanford Research Institute (ahora SRI International ) mantenía un archivo de texto llamado HOSTS.TXT que asignaba los nombres de host a las direcciones numéricas de las computadoras en ARPANET. [7] [8] Elizabeth Feinler desarrolló y mantuvo el primer directorio de ARPANET. [9] [10] El mantenimiento de las direcciones numéricas, llamada Lista de Números Asignados, estaba a cargo de Jon Postel en el Instituto de Ciencias de la Información (ISI) de la Universidad del Sur de California , cuyo equipo trabajó en estrecha colaboración con SRI. [11]
Las direcciones se asignaban manualmente. Las computadoras, incluidos sus nombres de host y direcciones, se agregaban al archivo principal contactando al Centro de Información de Red (NIC) de SRI, dirigido por Feinler, por teléfono durante el horario comercial. [12] Más tarde, Feinler configuró un directorio WHOIS en un servidor en el NIC para recuperar información sobre recursos, contactos y entidades. [13] Ella y su equipo desarrollaron el concepto de dominios. [13] Feinler sugirió que los dominios deberían basarse en la ubicación de la dirección física de la computadora. [14] Las computadoras en instituciones educativas tendrían el dominio edu , por ejemplo. [15] Ella y su equipo administraron el Registro de nombres de host desde 1972 hasta 1989. [16]
A principios de los años 1980, mantener una única tabla de host centralizada se había vuelto lento y difícil de manejar y la red emergente requería un sistema de nombres automatizado para abordar cuestiones técnicas y de personal. Postel encargó a Paul Mockapetris la tarea de forjar un compromiso entre cinco propuestas de soluciones en competencia . Mockapetris, en cambio, creó el Sistema de nombres de dominio en 1983 mientras estaba en la Universidad del Sur de California . [12] [17]
El Grupo de Trabajo de Ingeniería de Internet publicó las especificaciones originales en RFC 882 y RFC 883 en noviembre de 1983. [18] [19] Éstas se actualizaron en RFC 973 en enero de 1986.
En 1984, cuatro estudiantes de la UC Berkeley , Douglas Terry, Mark Painter, David Riggle y Songnian Zhou, escribieron la primera implementación de servidor de nombres Unix para el dominio de nombres de Internet de Berkeley, comúnmente conocido como BIND . [20] En 1985, Kevin Dunlap de DEC revisó sustancialmente la implementación de DNS. Mike Karels , Phil Almquist y Paul Vixie se hicieron cargo del mantenimiento de BIND. El Consorcio de Sistemas de Internet fue fundado en 1994 por Rick Adams , Paul Vixie y Carl Malamud , expresamente para proporcionar un hogar para el desarrollo y mantenimiento de BIND. Las versiones de BIND desde 4.9.3 en adelante fueron desarrolladas y mantenidas por ISC, con el apoyo proporcionado por los patrocinadores de ISC. Como coarquitectos/programadores, Bob Halley y Paul Vixie lanzaron la primera versión lista para producción de BIND versión 8 en mayo de 1997. Desde 2000, más de 43 desarrolladores principales diferentes han trabajado en BIND. [21]
En noviembre de 1987, las RFC 1034 [22] y RFC 1035 [5] reemplazaron las especificaciones DNS de 1983. Varias solicitudes de comentarios adicionales propusieron extensiones a los protocolos DNS básicos. [23]
El espacio de nombres de dominio consiste en una estructura de datos en forma de árbol . Cada nodo u hoja del árbol tiene una etiqueta y cero o más registros de recursos (RR), que contienen información asociada con el nombre de dominio. El nombre de dominio en sí consiste en la etiqueta, concatenada con el nombre de su nodo padre a la derecha, separados por un punto. [24]
El árbol se subdivide en zonas que comienzan en la zona raíz . Una zona DNS puede constar de tantos dominios y subdominios como elija el administrador de la zona. El DNS también se puede dividir en particiones según la clase , donde las clases separadas se pueden considerar como una matriz de árboles de espacios de nombres paralelos. [25]
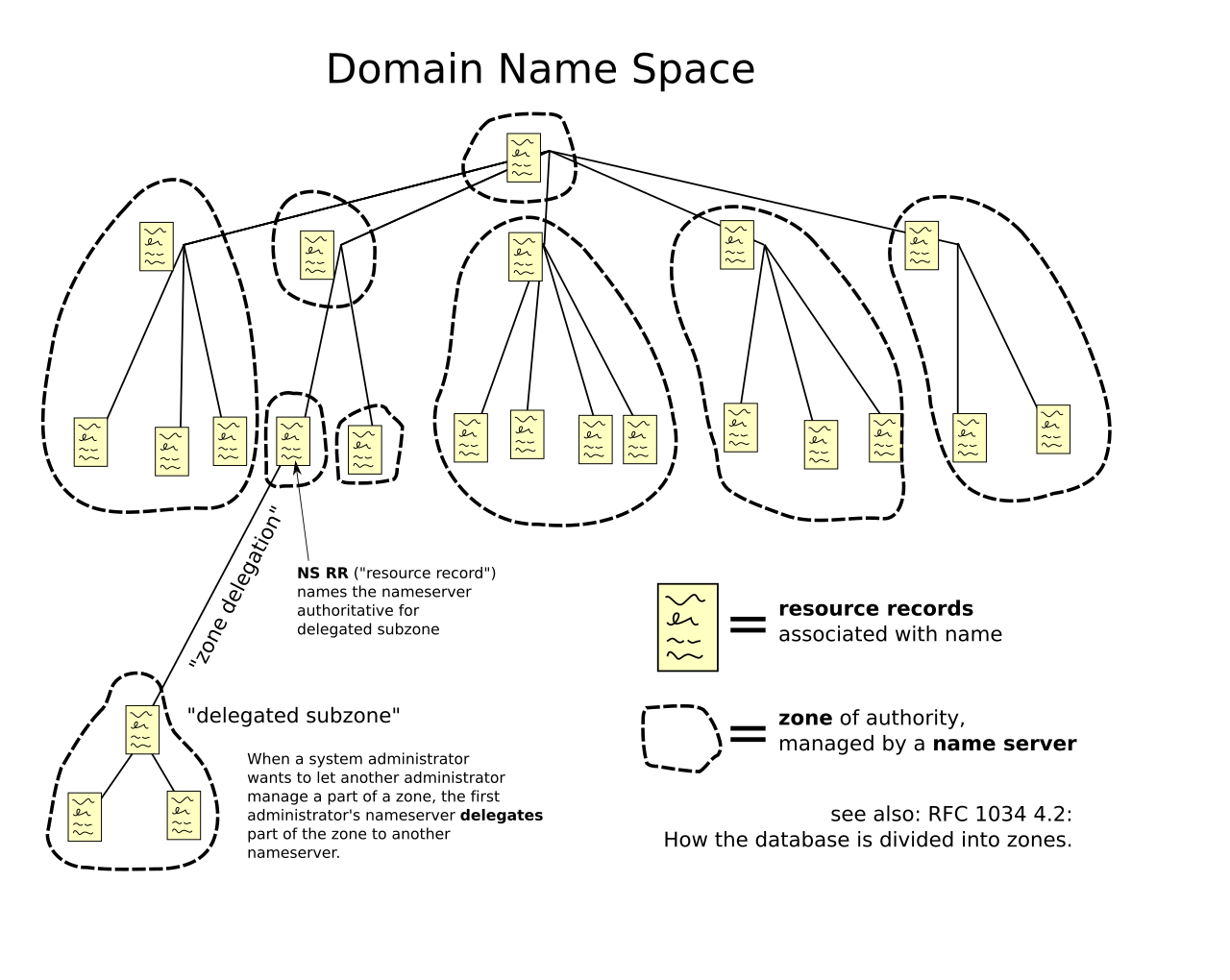
La responsabilidad administrativa de cualquier zona puede dividirse mediante la creación de zonas adicionales. Se dice que la autoridad sobre la nueva zona se delega en un servidor de nombres designado. La zona principal deja de tener autoridad sobre la nueva zona. [25]
Las descripciones definitivas de las reglas para la formación de nombres de dominio aparecen en RFC 1035, RFC 1123, RFC 2181 y RFC 5892. Un nombre de dominio consta de una o más partes, técnicamente llamadas etiquetas , que se concatenan convencionalmente y están delimitadas por puntos, como ejemplo.com.
La etiqueta más a la derecha transmite el dominio de nivel superior ; por ejemplo, el nombre de dominio www.example.com pertenece al dominio de nivel superior com .
La jerarquía de dominios desciende de derecha a izquierda; cada etiqueta de la izquierda especifica una subdivisión o subdominio del dominio de la derecha. Por ejemplo, la etiqueta ejemplo especifica un subdominio del dominio com , y www es un subdominio de ejemplo.com. Este árbol de subdivisiones puede tener hasta 127 niveles. [26]
Una etiqueta puede contener de cero a 63 caracteres. La etiqueta nula de longitud cero está reservada para la zona raíz. El nombre de dominio completo no puede superar la longitud de 253 caracteres en su representación textual. [22] En la representación binaria interna del DNS la longitud máxima requiere 255 octetos de almacenamiento, ya que también almacena la longitud del nombre. [5]
Aunque no existe ninguna limitación técnica que impida que las etiquetas de los nombres de dominio utilicen cualquier carácter que se pueda representar mediante un octeto, los nombres de host utilizan un formato y un conjunto de caracteres preferidos. Los caracteres permitidos en las etiquetas son un subconjunto del conjunto de caracteres ASCII , que consta de los caracteres de la a a la z , de la A a la Z , los dígitos del 0 al 9 y el guion. Esta regla se conoce como regla LDH (letras, dígitos, guion). Los nombres de dominio se interpretan de forma independiente de las mayúsculas y minúsculas. [27] Las etiquetas no pueden comenzar ni terminar con un guion. [28] Una regla adicional exige que los nombres de dominio de nivel superior no sean completamente numéricos. [28]
El conjunto limitado de caracteres ASCII permitidos en el DNS impidió la representación de nombres y palabras de muchos idiomas en sus alfabetos o escrituras nativas. Para hacer esto posible, la ICANN aprobó el sistema de Internacionalización de Nombres de Dominio en Aplicaciones (IDNA), por el cual las aplicaciones de usuario, como los navegadores web, asignan cadenas Unicode al conjunto de caracteres DNS válido utilizando Punycode . En 2009, la ICANN aprobó la instalación de dominios de nivel superior de código de país ( ccTLD ) de nombres de dominio internacionalizados . Además, muchos registros de los nombres de dominio de nivel superior ( TLD ) existentes han adoptado el sistema IDNA, guiados por RFC 5890, RFC 5891, RFC 5892, RFC 5893.
El sistema de nombres de dominio se mantiene mediante un sistema de base de datos distribuido , que utiliza el modelo cliente-servidor . Los nodos de esta base de datos son los servidores de nombres . Cada dominio tiene al menos un servidor DNS autorizado que publica información sobre ese dominio y los servidores de nombres de cualquier dominio subordinado a él. La parte superior de la jerarquía está atendida por los servidores de nombres raíz , los servidores a los que se realiza una consulta cuando se busca ( resuelve ) un TLD .
Un servidor de nombres autorizado es un servidor de nombres que solo da respuestas a consultas DNS a partir de datos que han sido configurados por una fuente original, por ejemplo, el administrador del dominio o por métodos DNS dinámicos, a diferencia de las respuestas obtenidas a través de una consulta a otro servidor de nombres que solo mantiene un caché de datos.
Un servidor de nombres autorizado puede ser un servidor primario o un servidor secundario . Históricamente, los términos maestro/esclavo y primario/secundario a veces se usaban indistintamente [29] pero la práctica actual es usar la segunda forma. Un servidor primario es un servidor que almacena las copias originales de todos los registros de zona. Un servidor secundario utiliza un mecanismo especial de actualización automática en el protocolo DNS en comunicación con su servidor primario para mantener una copia idéntica de los registros primarios.
A cada zona DNS se le debe asignar un conjunto de servidores de nombres autorizados. Este conjunto de servidores se almacena en la zona de dominio principal con registros de servidor de nombres (NS).
Un servidor autorizado indica su estado de suministro de respuestas definitivas, consideradas autorizadas , estableciendo un indicador de protocolo, llamado bit de " Respuesta autorizada " ( AA ) en sus respuestas. [5] Este indicador suele reproducirse de forma destacada en la salida de las herramientas de consulta de administración de DNS, como dig , para indicar que el servidor de nombres que responde es una autoridad para el nombre de dominio en cuestión. [5]
Cuando un servidor de nombres es designado como servidor autorizado para un nombre de dominio para el cual no tiene datos autorizados, presenta un tipo de error llamado "delegación deficiente" o "respuesta deficiente". [30] [31]
Los solucionadores de nombres de dominio determinan los servidores de nombres de dominio responsables del nombre de dominio en cuestión mediante una secuencia de consultas que comienzan con la etiqueta de dominio más a la derecha (de nivel superior).

Para que el solucionador de nombres de dominio funcione correctamente, un host de red se configura con un caché inicial ( hints ) de las direcciones conocidas de los servidores de nombres raíz. Un administrador actualiza periódicamente los hints recuperando un conjunto de datos de una fuente confiable.
Suponiendo que el solucionador no tiene registros en caché para acelerar el proceso, el proceso de resolución comienza con una consulta a uno de los servidores raíz. En un funcionamiento típico, los servidores raíz no responden directamente, sino que responden con una referencia a servidores más autorizados, por ejemplo, una consulta para "www.wikipedia.org" se remite a los servidores org . El solucionador ahora consulta a los servidores a los que se hace referencia y repite este proceso de forma iterativa hasta que recibe una respuesta autorizada. El diagrama ilustra este proceso para el host que tiene el nombre de dominio completo "www.wikipedia.org".
Este mecanismo supondría una gran carga de tráfico para los servidores raíz si cada resolución en Internet requiriera comenzar desde la raíz. En la práctica, el almacenamiento en caché se utiliza en los servidores DNS para descargar a los servidores raíz y, como resultado, los servidores de nombres raíz en realidad participan solo en una fracción relativamente pequeña de todas las solicitudes.
En teoría, los servidores de nombres autorizados son suficientes para el funcionamiento de Internet. Sin embargo, si sólo funcionan servidores de nombres autorizados, cada consulta DNS debe comenzar con consultas recursivas en la zona raíz del sistema de nombres de dominio y cada sistema de usuario debería implementar un software de resolución capaz de realizar operaciones recursivas. [32]
Para mejorar la eficiencia, reducir el tráfico DNS a través de Internet y aumentar el rendimiento de las aplicaciones de los usuarios finales, el Sistema de nombres de dominio admite servidores de caché DNS que almacenan los resultados de las consultas DNS durante un período de tiempo determinado en la configuración ( tiempo de vida ) del registro de nombre de dominio en cuestión. Normalmente, estos servidores DNS de almacenamiento en caché también implementan el algoritmo recursivo necesario para resolver un nombre determinado comenzando por la raíz DNS hasta los servidores de nombres autorizados del dominio consultado. Con esta función implementada en el servidor de nombres, las aplicaciones de los usuarios ganan eficiencia en el diseño y el funcionamiento.
La combinación de almacenamiento en caché de DNS y funciones recursivas en un servidor de nombres no es obligatoria; las funciones se pueden implementar de forma independiente en servidores para fines especiales.
Los proveedores de servicios de Internet suelen proporcionar servidores de nombres recursivos y con almacenamiento en caché a sus clientes. Además, muchos enrutadores de redes domésticas implementan cachés de DNS y recursión para mejorar la eficiencia en la red local.
El lado del cliente del DNS se denomina solucionador de DNS. Un solucionador es responsable de iniciar y secuenciar las consultas que finalmente conducen a una resolución completa (traducción) del recurso buscado, por ejemplo, la traducción de un nombre de dominio a una dirección IP. Los solucionadores de DNS se clasifican según una variedad de métodos de consulta, como recursivos , no recursivos e iterativos . Un proceso de resolución puede utilizar una combinación de estos métodos. [22]
En una consulta no recursiva , un solucionador de DNS consulta a un servidor DNS que proporciona un registro para el cual el servidor tiene autoridad, o proporciona un resultado parcial sin consultar a otros servidores. En el caso de un solucionador de DNS con almacenamiento en caché, la consulta no recursiva de su caché DNS local ofrece un resultado y reduce la carga en los servidores DNS ascendentes al almacenar en caché los registros de recursos DNS durante un período de tiempo después de una respuesta inicial de los servidores DNS ascendentes.
En una consulta recursiva , un solucionador DNS consulta a un único servidor DNS, que a su vez puede consultar a otros servidores DNS en nombre del solicitante. Por ejemplo, un solucionador de stub simple que se ejecuta en un enrutador doméstico normalmente realiza una consulta recursiva al servidor DNS que ejecuta el ISP del usuario . Una consulta recursiva es aquella en la que el servidor DNS responde a la consulta por completo consultando a otros servidores de nombres según sea necesario. En un funcionamiento típico, un cliente emite una consulta recursiva a un servidor DNS recursivo de almacenamiento en caché, que posteriormente emite consultas no recursivas para determinar la respuesta y enviar una única respuesta de vuelta al cliente. El solucionador, u otro servidor DNS que actúa de forma recursiva en nombre del solucionador, negocia el uso del servicio recursivo utilizando bits en los encabezados de consulta. Los servidores DNS no están obligados a admitir consultas recursivas.
El procedimiento de consulta iterativa es un proceso en el que un solucionador de DNS consulta una cadena de uno o más servidores DNS. Cada servidor remite al cliente al siguiente servidor de la cadena, hasta que el servidor actual pueda resolver por completo la solicitud. Por ejemplo, una posible resolución de www.example.com consultaría un servidor raíz global, luego un servidor "com" y, por último, un servidor "example.com".
Los servidores de nombres en las delegaciones se identifican por su nombre, en lugar de por su dirección IP. Esto significa que un servidor de nombres que realiza la resolución debe emitir otra solicitud DNS para averiguar la dirección IP del servidor al que se ha remitido. Si el nombre proporcionado en la delegación es un subdominio del dominio para el que se proporciona la delegación, existe una dependencia circular .
En este caso, el servidor de nombres que proporciona la delegación también debe proporcionar una o más direcciones IP para el servidor de nombres autorizado mencionado en la delegación. Esta información se denomina pegamento . El servidor de nombres que delega proporciona este pegamento en forma de registros en la sección adicional de la respuesta DNS y proporciona la delegación en la sección de autoridad de la respuesta. Un registro de pegamento es una combinación del servidor de nombres y la dirección IP.
Por ejemplo, si el servidor de nombres autorizado para example.org es ns1.example.org, un equipo que intente resolver www.example.org primero resolverá ns1.example.org. Como ns1 está contenido en example.org, esto requiere resolver example.org primero, lo que presenta una dependencia circular. Para romper la dependencia, el servidor de nombres para el dominio de nivel superior org incluye glue junto con la delegación para example.org. Los registros de glue son registros de dirección que proporcionan direcciones IP para ns1.example.org. El solucionador utiliza una o más de estas direcciones IP para consultar uno de los servidores autorizados del dominio, lo que le permite completar la consulta DNS.
Un método común para reducir la carga de los servidores DNS es almacenar en caché los resultados de la resolución de nombres de forma local o en hosts intermediarios de resolución. Cada resultado de una consulta DNS tiene un tiempo de vida (TTL), que indica cuánto tiempo sigue siendo válida la información antes de que sea necesario descartarla o actualizarla. Este TTL lo determina el administrador del servidor DNS autorizado y puede variar desde unos pocos segundos hasta varios días o incluso semanas. [33]
Como resultado de esta arquitectura de almacenamiento en caché distribuido, los cambios en los registros DNS no se propagan por toda la red inmediatamente, sino que requieren que todos los cachés caduquen y se actualicen después del TTL. El RFC 1912 transmite reglas básicas para determinar los valores TTL apropiados.
Algunos solucionadores pueden anular los valores TTL, ya que el protocolo admite el almacenamiento en caché durante hasta sesenta y ocho años o ningún almacenamiento en caché. El almacenamiento en caché negativo , es decir, el almacenamiento en caché del hecho de la inexistencia de un registro, lo determinan los servidores de nombres autorizados para una zona que deben incluir el registro de inicio de autoridad (SOA) cuando informan que no existen datos del tipo solicitado. El valor del campo mínimo del registro SOA y el TTL del propio SOA se utilizan para establecer el TTL para la respuesta negativa.
Una búsqueda DNS inversa es una consulta al DNS de nombres de dominio cuando se conoce la dirección IP. Se pueden asociar varios nombres de dominio con una dirección IP. El DNS almacena direcciones IP en forma de nombres de dominio como nombres con formato especial en registros de puntero (PTR) dentro del dominio de nivel superior de infraestructura arpa . Para IPv4, el dominio es in-addr.arpa. Para IPv6, el dominio de búsqueda inversa es ip6.arpa. La dirección IP se representa como un nombre en representación de octetos en orden inverso para IPv4 y en representación de nibble en orden inverso para IPv6.
Al realizar una búsqueda inversa, el cliente DNS convierte la dirección a estos formatos antes de consultar el nombre para un registro PTR siguiendo la cadena de delegación como para cualquier consulta DNS. Por ejemplo, suponiendo que la dirección IPv4 208.80.152.2 está asignada a Wikimedia, se representa como un nombre DNS en orden inverso: 2.152.80.208.in-addr.arpa. Cuando el solucionador DNS recibe una solicitud de puntero (PTR), comienza consultando los servidores raíz, que apuntan a los servidores de American Registry for Internet Numbers (ARIN) para la zona 208.in-addr.arpa. Los servidores de ARIN delegan 152.80.208.in-addr.arpa a Wikimedia, a la que el solucionador envía otra consulta para 2.152.80.208.in-addr.arpa, lo que da como resultado una respuesta autorizada.

Los usuarios generalmente no se comunican directamente con un solucionador de DNS. En cambio, la resolución de DNS se lleva a cabo de manera transparente en aplicaciones como navegadores web , clientes de correo electrónico y otras aplicaciones de Internet. Cuando una aplicación realiza una solicitud que requiere la búsqueda de un nombre de dominio, dichos programas envían una solicitud de resolución al solucionador de DNS en el sistema operativo local, que a su vez maneja las comunicaciones necesarias.
El solucionador DNS casi invariablemente tendrá un caché (ver arriba) que contiene búsquedas recientes. Si el caché puede proporcionar la respuesta a la solicitud, el solucionador devolverá el valor en el caché al programa que realizó la solicitud. Si el caché no contiene la respuesta, el solucionador enviará la solicitud a uno o más servidores DNS designados. En el caso de la mayoría de los usuarios domésticos, el proveedor de servicios de Internet al que se conecta la máquina generalmente proporcionará este servidor DNS: dicho usuario habrá configurado la dirección de ese servidor manualmente o permitirá que DHCP la configure; sin embargo, cuando los administradores de sistemas han configurado los sistemas para usar sus propios servidores DNS, sus solucionadores DNS apuntan a servidores de nombres mantenidos por separado de la organización. En cualquier caso, el servidor de nombres consultado seguirá el proceso descrito anteriormente, hasta que encuentre un resultado con éxito o no. Luego devuelve sus resultados al solucionador DNS; suponiendo que haya encontrado un resultado, el solucionador almacena debidamente en caché ese resultado para su uso futuro y devuelve el resultado al software que inició la solicitud.
Algunos grandes ISP han configurado sus servidores DNS para violar reglas, por ejemplo desobedeciendo los TTL o indicando que un nombre de dominio no existe simplemente porque uno de sus servidores de nombres no responde. [34]
Algunas aplicaciones, como los navegadores web, mantienen una caché DNS interna para evitar búsquedas repetidas a través de la red. Esta práctica puede añadir dificultad adicional a la hora de depurar problemas de DNS, ya que oculta el historial de dichos datos. Estas cachés suelen utilizar tiempos de almacenamiento en caché muy cortos, del orden de un minuto. [35]
Internet Explorer representa una notable excepción: las versiones hasta IE 3.x almacenan en caché los registros DNS durante 24 horas de forma predeterminada. Internet Explorer 4.x y versiones posteriores (hasta IE 8) reducen el valor de tiempo de espera predeterminado a media hora, que se puede cambiar modificando la configuración predeterminada. [36]
Cuando Google Chrome detecta problemas con el servidor DNS, muestra un mensaje de error específico.
El Sistema de Nombres de Dominio incluye varias otras funciones y características.
No es necesario que los nombres de host y las direcciones IP coincidan en una relación uno a uno. Varios nombres de host pueden corresponder a una única dirección IP, lo que resulta útil en el alojamiento virtual , en el que muchos sitios web se sirven desde un único host. Alternativamente, un único nombre de host puede resolverse en muchas direcciones IP para facilitar la tolerancia a fallos y la distribución de la carga a varias instancias de servidor en una empresa o en Internet global.
El DNS tiene otros propósitos además de traducir nombres a direcciones IP. Por ejemplo, los agentes de transferencia de correo utilizan el DNS para encontrar el mejor servidor de correo para entregar correo electrónico : un registro MX proporciona una correlación entre un dominio y un intercambiador de correo; esto puede proporcionar una capa adicional de tolerancia a fallas y distribución de carga.
El DNS se utiliza para el almacenamiento y la distribución eficientes de direcciones IP de servidores de correo electrónico incluidos en la lista negra. Un método común es colocar la dirección IP del servidor en cuestión en el subdominio de un nombre de dominio de nivel superior y resolver ese nombre en un registro que indique una indicación positiva o negativa.
Por ejemplo:
Los servidores de correo electrónico pueden consultar blacklist.example para averiguar si un host específico que se conecta a ellos está en la lista negra. Muchas de estas listas negras, ya sean gratuitas o basadas en suscripción, están disponibles para que las utilicen los administradores de correo electrónico y el software antispam.
Para proporcionar resistencia en caso de fallo informático o de red, se suelen proporcionar varios servidores DNS para cubrir cada dominio. En el nivel superior del DNS global, existen trece grupos de servidores de nombres raíz , con "copias" adicionales de ellos distribuidas por todo el mundo mediante direccionamiento anycast .
El DNS dinámico (DDNS) actualiza un servidor DNS con una dirección IP de cliente sobre la marcha, por ejemplo, al cambiar de ISP o punto de acceso móvil , o cuando la dirección IP cambia administrativamente.
El protocolo DNS utiliza dos tipos de mensajes DNS, consultas y respuestas; ambos tienen el mismo formato. Cada mensaje consta de un encabezado y cuatro secciones: pregunta, respuesta, autoridad y un espacio adicional. Un campo de encabezado ( flags ) controla el contenido de estas cuatro secciones. [22]
La sección de encabezado consta de los siguientes campos: Identificación , Indicadores , Número de preguntas , Número de respuestas , Número de registros de recursos de autoridad (RR) y Número de RR adicionales . Cada campo tiene una longitud de 16 bits y aparece en el orden indicado. El campo de identificación se utiliza para hacer coincidir las respuestas con las consultas. El campo de indicadores consta de los siguientes subcampos:
Después de la palabra banderas, el encabezado termina con cuatro enteros de 16 bits que contienen el número de registros en cada una de las secciones que siguen, en el mismo orden.
La sección de preguntas tiene un formato más simple que el formato de registro de recursos utilizado en las otras secciones. Cada registro de pregunta (normalmente solo hay uno en la sección) contiene los siguientes campos:
El nombre de dominio se divide en etiquetas discretas que se concatenan; cada etiqueta tiene como prefijo la longitud de esa etiqueta. [38]
El Sistema de nombres de dominio especifica una base de datos de elementos de información para los recursos de red. Los tipos de elementos de información se clasifican y organizan con una lista de tipos de registros DNS , los registros de recursos (RR). Cada registro tiene un tipo (nombre y número), un tiempo de expiración ( tiempo de vida ), una clase y datos específicos del tipo. Los registros de recursos del mismo tipo se describen como un conjunto de registros de recursos (RRset), que no tienen un orden especial. Los solucionadores DNS devuelven el conjunto completo tras la consulta, pero los servidores pueden implementar un ordenamiento por turnos para lograr el equilibrio de carga . Por el contrario, las Extensiones de seguridad del sistema de nombres de dominio (DNSSEC) funcionan en el conjunto completo de registros de recursos en orden canónico.
Cuando se envían a través de una red de Protocolo de Internet , todos los registros (respuesta, autoridad y secciones adicionales) utilizan el formato común especificado en RFC 1035: [39]
NOMBRE es el nombre de dominio completo del nodo en el árbol. [ aclaración necesaria ] En la red, el nombre se puede acortar utilizando compresión de etiquetas, donde los extremos de los nombres de dominio mencionados anteriormente en el paquete se pueden sustituir por el final del nombre de dominio actual.
TYPE es el tipo de registro. Indica el formato de los datos y da una pista de su uso previsto. Por ejemplo, el registro A se utiliza para traducir de un nombre de dominio a una dirección IPv4 , el registro NS enumera qué servidores de nombres pueden responder a las búsquedas en una zona DNS y el registro MX especifica el servidor de correo utilizado para gestionar el correo de un dominio especificado en una dirección de correo electrónico.
RDATA son datos de relevancia específica para cada tipo, como la dirección IP para los registros de direcciones o la prioridad y el nombre de host para los registros MX. Los tipos de registros conocidos pueden utilizar la compresión de etiquetas en el campo RDATA, pero los tipos de registros "desconocidos" no deben hacerlo (RFC 3597).
La CLASE de un registro se establece en IN (para Internet ) para los registros DNS comunes que involucran nombres de host, servidores o direcciones IP de Internet. Además, existen las clases Chaos (CH) y Hesiod (HS). [40] Cada clase es un espacio de nombres independiente con delegaciones de zonas DNS potencialmente diferentes.
Además de los registros de recursos definidos en un archivo de zona , el sistema de nombres de dominio también define varios tipos de solicitud que se utilizan solo en la comunicación con otros nodos DNS ( en la red ), como cuando se realizan transferencias de zona (AXFR/IXFR) o para EDNS (OPT).
El sistema de nombres de dominio admite registros DNS comodín que especifican nombres que comienzan con la etiqueta de asterisco , *, p. ej., *.example. [22] [41] Los registros DNS que pertenecen a nombres de dominio comodín especifican reglas para generar registros de recursos dentro de una única zona DNS sustituyendo etiquetas completas con componentes coincidentes del nombre de consulta, incluidos los descendientes especificados. Por ejemplo, en la siguiente configuración, la zona DNS x.example especifica que todos los subdominios, incluidos los subdominios de subdominios, de x.example usan el intercambiador de correo (MX) axexample . El registro A para axexample es necesario para especificar la dirección IP del intercambiador de correo. Como esto tiene el resultado de excluir este nombre de dominio y sus subdominios de las coincidencias de comodines, también se debe definir en la zona DNS un registro MX adicional para el subdominio axexample , así como un registro MX comodín para todos sus subdominios.
x.ejemplo. MX 10 a.x.ejemplo. *.x.ejemplo. MX 10 a.x.ejemplo. *.axejemplo. MX 10 a.x.ejemplo. axeejemplo. MX 10 a.x.ejemplo. axeejemplo. AAAA 2001:db8::1 El papel de los registros comodín se perfeccionó en RFC 4592, porque la definición original en RFC 1034 estaba incompleta y daba lugar a malas interpretaciones por parte de los implementadores. [41]
El protocolo DNS original tenía disposiciones limitadas para la extensión con nuevas características. En 1999, Paul Vixie publicó en RFC 2671 (reemplazado por RFC 6891) un mecanismo de extensión, llamado Mecanismos de extensión para DNS (EDNS), que introdujo elementos de protocolo opcionales sin aumentar la sobrecarga cuando no se utilizaban. Esto se logró mediante el registro de pseudo-recurso OPT que solo existe en transmisiones por cable del protocolo, pero no en ningún archivo de zona. También se sugirieron extensiones iniciales (EDNS0), como aumentar el tamaño del mensaje DNS en datagramas UDP.
Las actualizaciones dinámicas de DNS utilizan el código de operación UPDATE DNS para agregar o eliminar registros de recursos de manera dinámica desde una base de datos de zona mantenida en un servidor DNS autorizado. [42] Esta función es útil para registrar clientes de red en el DNS cuando se inician o se vuelven disponibles en la red. Como a un cliente que se inicia se le puede asignar una dirección IP diferente cada vez desde un servidor DHCP , no es posible proporcionar asignaciones de DNS estáticas para dichos clientes.
Desde su origen en 1983, el DNS ha utilizado el Protocolo de Datagramas de Usuario (UDP) para el transporte sobre IP. Sus limitaciones han motivado numerosos desarrollos de protocolos en las décadas posteriores en cuanto a fiabilidad, seguridad, privacidad y otros criterios.
UDP reserva el puerto número 53 para los servidores que escuchan consultas. [5] Dichas consultas consisten en una solicitud de texto claro enviada en un único paquete UDP desde el cliente, a la que se responde con una respuesta de texto claro enviada en un único paquete UDP desde el servidor. Cuando la longitud de la respuesta supera los 512 bytes y tanto el cliente como el servidor admiten los mecanismos de extensión para DNS (EDNS), se pueden utilizar paquetes UDP más grandes. [43] El uso de DNS sobre UDP está limitado, entre otras cosas, por su falta de cifrado de capa de transporte, autenticación, entrega confiable y longitud de mensaje. En 1989, RFC 1123 especificó el transporte opcional de Protocolo de control de transmisión (TCP) para consultas DNS, respuestas y, en particular, transferencias de zona . A través de la fragmentación de respuestas largas, TCP permite respuestas más largas, entrega confiable y reutilización de conexiones de larga duración entre clientes y servidores. Para respuestas más grandes, el servidor remite al cliente al transporte TCP.
El DNS sobre TLS surgió como un estándar de IETF para DNS cifrado en 2016, utilizando Transport Layer Security (TLS) para proteger toda la conexión, en lugar de solo la carga útil del DNS. Los servidores DoT escuchan en el puerto TCP 853. La RFC 7858 especifica que se puede admitir el cifrado oportunista y el cifrado autenticado, pero no hizo obligatoria la autenticación del servidor o del cliente.
En 2018, se desarrolló DNS over HTTPS como un estándar competitivo para el transporte de consultas DNS, que tuneliza los datos de las consultas DNS sobre HTTPS, que transporta HTTP sobre TLS. DoH se promocionó como una alternativa más amigable con la web que DNS ya que, al igual que DNSCrypt, utiliza el puerto TCP 443 y, por lo tanto, se parece al tráfico web, aunque en la práctica son fácilmente diferenciables sin el relleno adecuado. [44]
El RFC 9250, publicado en 2022 por el Grupo de trabajo de ingeniería de Internet , describe el DNS sobre QUIC . Tiene "propiedades de privacidad similares a las del DNS sobre TLS (DoT) [...] y características de latencia similares al DNS clásico sobre UDP". Este método no es lo mismo que el DNS sobre HTTP/3 . [45]
El DNS ajeno (ODNS) fue inventado e implementado por investigadores de la Universidad de Princeton y la Universidad de Chicago como una extensión del DNS no cifrado, [46] antes de que DoH se estandarizara y se implementara ampliamente. Posteriormente, Apple y Cloudflare implementaron la tecnología en el contexto de DoH, como Oblivious DoH (ODoH). [47] ODoH combina la separación de entrada/salida (inventada en ODNS) con la tunelización HTTPS de DoH y el cifrado de capa de transporte TLS en un solo protocolo. [48]
El DNS puede ejecutarse sobre redes privadas virtuales (VPN) y protocolos de tunelización . Un uso que se ha vuelto común desde 2019 para justificar su propio acrónimo de uso frecuente es DNS over Tor . Las ganancias de privacidad de Oblivious DNS se pueden obtener mediante el uso de la red Tor preexistente de nodos de entrada y salida, junto con el cifrado de la capa de transporte proporcionado por TLS. [49]
El protocolo DNSCrypt , que se desarrolló en 2011 fuera del marco de estándares de la IETF , introdujo el cifrado DNS en el lado descendente de los resolutores recursivos, en el que los clientes cifran las cargas útiles de las consultas utilizando las claves públicas de los servidores, que se publican en el DNS (en lugar de depender de autoridades de certificación de terceros) y que, a su vez, pueden estar protegidas por firmas DNSSEC. [50] DNSCrypt utiliza el puerto TCP o UDP 443, el mismo puerto que el tráfico web cifrado HTTPS. Esto introdujo no solo privacidad con respecto al contenido de la consulta, sino también una medida significativa de capacidad de atravesar el firewall. En 2019, DNSCrypt se amplió aún más para admitir un modo "anónimo", similar al "DNS ajeno" propuesto, en el que un nodo de entrada recibe una consulta que se ha cifrado con la clave pública de un servidor diferente y la retransmite a ese servidor, que actúa como un nodo de salida, realizando la resolución recursiva. [51] Se crea privacidad de pares de usuario/consulta, ya que el nodo de entrada no conoce el contenido de la consulta, mientras que los nodos de salida no conocen la identidad del cliente. DNSCrypt fue implementado por primera vez en producción por OpenDNS en diciembre de 2011. Hay varias implementaciones de software libre y de código abierto que además integran ODoH. [52] Está disponible para una variedad de sistemas operativos, incluidos Unix, Apple iOS, Linux, Android y Windows.
En un principio, las preocupaciones de seguridad no eran consideraciones de diseño importantes para el software DNS ni para ningún software destinado a su implementación en los inicios de Internet, ya que la red no estaba abierta a la participación del público en general. Sin embargo, la expansión de Internet al sector comercial en la década de 1990 cambió los requisitos de las medidas de seguridad para proteger la integridad de los datos y la autenticación de los usuarios .
Se han descubierto y explotado varios problemas de vulnerabilidad por parte de usuarios malintencionados. Uno de ellos es el envenenamiento de la caché de DNS , en el que los datos se distribuyen a los servidores de resolución de caché bajo la apariencia de ser un servidor de origen autorizado, contaminando así el almacén de datos con información potencialmente falsa y largos tiempos de caducidad (tiempo de vida). Posteriormente, las solicitudes de aplicaciones legítimas pueden ser redirigidas a hosts de red operados con intenciones maliciosas.
Las respuestas DNS tradicionalmente no tienen una firma criptográfica , lo que genera muchas posibilidades de ataque; las Extensiones de Seguridad del Sistema de Nombres de Dominio (DNSSEC) modifican el DNS para agregar soporte para respuestas firmadas criptográficamente. [53] DNSCurve se ha propuesto como una alternativa a DNSSEC. Otras extensiones, como TSIG , agregan soporte para autenticación criptográfica entre pares confiables y se usan comúnmente para autorizar operaciones de transferencia de zona o de actualización dinámica.
Algunos nombres de dominio pueden utilizarse para lograr efectos de suplantación de identidad. Por ejemplo, paypal.com y paypa1.com son nombres diferentes, pero los usuarios pueden no poder distinguirlos en una interfaz gráfica de usuario según el tipo de letra elegido por el usuario . En muchas fuentes, la letra l y el número 1 parecen muy similares o incluso idénticos. Este problema, conocido como ataque homógrafo de IDN , es grave en sistemas que admiten nombres de dominio internacionalizados , ya que muchos códigos de caracteres en ISO 10646 pueden parecer idénticos en las pantallas de ordenador típicas. Esta vulnerabilidad se explota ocasionalmente en el phishing . [54]
También se pueden utilizar técnicas como el DNS inverso confirmado hacia adelante para ayudar a validar los resultados del DNS.
El DNS también puede "filtrarse" desde conexiones que de otro modo serían seguras o privadas, si no se presta atención a su configuración, y en ocasiones el DNS ha sido utilizado para eludir firewalls por personas malintencionadas y exfiltrar datos, ya que a menudo se lo considera inocuo.
El protocolo DNS, diseñado originalmente como una base de datos pública, jerárquica, distribuida y con un alto nivel de almacenamiento en caché, no tiene controles de confidencialidad. Las consultas de los usuarios y las respuestas de los servidores de nombres se envían sin cifrar, lo que permite el rastreo de paquetes de red , el secuestro de DNS , el envenenamiento de la caché de DNS y los ataques de intermediarios . Los cibercriminales y los operadores de red suelen utilizar esta deficiencia con fines de marketing, autenticación de usuarios en portales cautivos y censura . [55]
La privacidad del usuario se ve aún más expuesta por las propuestas para aumentar el nivel de información IP del cliente en las consultas DNS (RFC 7871) para el beneficio de las redes de distribución de contenido .
Los principales enfoques que se utilizan para contrarrestar los problemas de privacidad con DNS:
Las soluciones que impiden la inspección de DNS por parte de los operadores de redes locales son criticadas por frustrar las políticas de seguridad de las redes corporativas y la censura de Internet. También son criticadas desde el punto de vista de la privacidad, ya que ponen la resolución de DNS en manos de un pequeño número de empresas conocidas por monetizar el tráfico de usuarios y por centralizar la resolución de nombres DNS, lo que generalmente se percibe como perjudicial para Internet. [55]
Google es el proveedor dominante de la plataforma en Android , el navegador en Chrome y el solucionador de DNS en el servicio 8.8.8.8. ¿Sería este escenario un caso en el que una sola entidad corporativa estaría en una posición de control general de todo el espacio de nombres de Internet? Netflix ya presentó una aplicación que usaba su propio mecanismo de resolución de DNS independiente de la plataforma en la que se ejecutaba la aplicación. ¿Qué sucedería si la aplicación de Facebook incluyera DoH? ¿Qué sucedería si el iOS de Apple usara un mecanismo de resolución de DoH para eludir la resolución de DNS local y dirigir todas las consultas de DNS de las plataformas de Apple a un conjunto de solucionadores de nombres operados por Apple?
— La privacidad del DNS y el IETF
El derecho a utilizar un nombre de dominio es delegado por los registradores de nombres de dominio que están acreditados por la Corporación de Internet para la Asignación de Nombres y Números (ICANN) u otras organizaciones como OpenNIC , que se encargan de supervisar los sistemas de nombres y números de Internet. Además de la ICANN, cada dominio de nivel superior (TLD) es mantenido y atendido técnicamente por una organización administrativa, que opera un registro. Un registro es responsable de operar la base de datos de nombres dentro de su zona autorizada, aunque el término se utiliza con más frecuencia para los TLD. Un registrante es una persona u organización que solicitó el registro de un dominio. [23] El registro recibe información de registro de cada registrador de nombres de dominio , que está autorizado (acreditado) para asignar nombres en la zona correspondiente y publica la información utilizando el protocolo WHOIS . A partir de 2015, se está considerando el uso de RDAP . [56]
La ICANN publica la lista completa de los TLD, los registros de TLD y los registradores de nombres de dominio. La información del registrante asociada a los nombres de dominio se mantiene en una base de datos en línea accesible con el servicio WHOIS. Para la mayoría de los más de 290 dominios de nivel superior de código de país (ccTLD), los registros de dominio mantienen la información WHOIS (Registrante, servidores de nombres, fechas de vencimiento, etc.). Por ejemplo, DENIC , NIC de Alemania, mantiene los datos de dominio DE. Desde aproximadamente 2001, la mayoría de los registros de dominios genéricos de nivel superior (gTLD) han adoptado este llamado enfoque de registro grueso , es decir, mantienen los datos WHOIS en registros centrales en lugar de bases de datos de registradores.
Para los dominios de nivel superior en COM y NET, se utiliza un modelo de registro delgado . El registro de dominios (por ejemplo, GoDaddy , BigRock y PDR , VeriSign , etc., etc.) contiene datos WHOIS básicos (es decir, registrador y servidores de nombres, etc.). Las organizaciones, o los registrantes que utilizan ORG, por otro lado, están exclusivamente en el Registro de Interés Público .
Algunos registros de nombres de dominio, a menudo denominados centros de información de red (NIC), también funcionan como registradores para los usuarios finales, además de proporcionar acceso a los conjuntos de datos WHOIS. Los registros de dominio de nivel superior, como los dominios COM, NET y ORG, utilizan un modelo de registro-registrador que consta de muchos registradores de nombres de dominio. [57] En este método de gestión, el registro solo administra la base de datos de nombres de dominio y la relación con los registradores. Los registrantes (usuarios de un nombre de dominio) son clientes del registrador, en algunos casos a través de subcontratación adicional de revendedores.
Investigamos si el tráfico DoH se puede distinguir del tráfico web cifrado. Para ello, entrenamos un modelo de aprendizaje automático para clasificar el tráfico HTTPS como web o DoH. Con nuestro modelo de identificación DoH en funcionamiento, demostramos que un ISP autoritario puede identificar correctamente aproximadamente el 97,4 % de los paquetes DoH y solo clasificar incorrectamente 1 de cada 10 000 paquetes web.
DNS sobre HTTPS (DoH) evita muchos, pero no todos, los riesgos, y su protocolo de transporte (es decir, HTTPS) plantea preocupaciones sobre la privacidad debido a (por ejemplo) las "cookies". La red Tor existe para proporcionar a los circuitos TCP cierta libertad frente al seguimiento, la vigilancia y el bloqueo. Por lo tanto: En combinación con Tor, DoH y el principio de "No hagas eso, entonces" (DDTT) para mitigar la identificación de solicitudes, describo DNS sobre HTTPS sobre Tor (DoHoT).
Estas RFC tienen carácter consultivo, pero pueden proporcionar información útil a pesar de no definir un estándar o un BCP. (RFC 1796)
Estas RFC tienen un estado oficial de Desconocido , pero debido a su antigüedad no están claramente etiquetadas como tales.