En informática , una lista de saltos (o skiplist ) es una estructura de datos probabilística que permite una complejidad media para la búsqueda, así como una complejidad media para la inserción dentro de una secuencia ordenada de elementos. Por lo tanto, puede obtener las mejores características de una matriz ordenada (para la búsqueda) mientras mantiene una estructura similar a una lista enlazada que permite la inserción, lo que no es posible con una matriz estática. La búsqueda rápida es posible manteniendo una jerarquía enlazada de subsecuencias, con cada subsecuencia sucesiva saltando menos elementos que la anterior (ver la imagen de abajo a la derecha). La búsqueda comienza en la subsecuencia más dispersa hasta que se hayan encontrado dos elementos consecutivos, uno más pequeño y uno más grande o igual que el elemento buscado. A través de la jerarquía enlazada, estos dos elementos se vinculan a elementos de la siguiente subsecuencia más dispersa, donde la búsqueda continúa hasta que finalmente se busca en la secuencia completa. Los elementos que se saltan pueden elegirse de forma probabilística [2] o determinista [3] , siendo la primera más común.
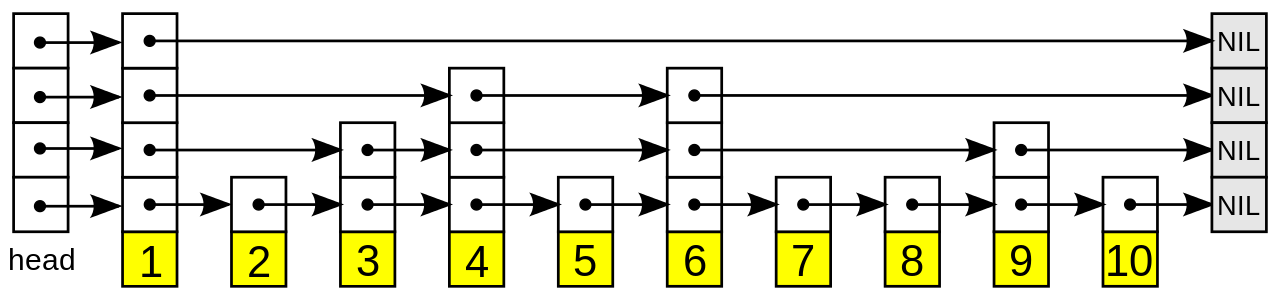
Una lista de saltos se construye en capas. La capa inferior es una lista enlazada ordenada ordinaria . Cada capa superior actúa como un "carril exprés" para las listas inferiores, donde un elemento de una capa aparece en una capa con cierta probabilidad fija (dos valores comúnmente utilizados para son o ). En promedio, cada elemento aparece en las listas, y el elemento más alto (generalmente un elemento de cabecera especial al frente de la lista de saltos) aparece en todas las listas. La lista de saltos contiene (es decir, la base logarítmica de ) listas.
La búsqueda de un elemento de destino comienza en el elemento principal de la lista superior y continúa horizontalmente hasta que el elemento actual sea mayor o igual que el objetivo. Si el elemento actual es igual al objetivo, se ha encontrado. Si el elemento actual es mayor que el objetivo o la búsqueda llega al final de la lista enlazada, el procedimiento se repite después de volver al elemento anterior y descender verticalmente hasta la lista inmediatamente inferior. El número esperado de pasos en cada lista enlazada es como máximo , lo que se puede ver rastreando la ruta de búsqueda hacia atrás desde el objetivo hasta llegar a un elemento que aparece en la lista inmediatamente superior o hasta llegar al principio de la lista actual. Por lo tanto, el coste total esperado de una búsqueda es que es , cuando es una constante. Al elegir diferentes valores de , es posible intercambiar los costes de búsqueda por los costes de almacenamiento.

Los elementos utilizados para una lista de omisión pueden contener más de un puntero, ya que pueden participar en más de una lista.
Las inserciones y eliminaciones se implementan de forma muy similar a las operaciones de lista enlazada correspondientes, excepto que los elementos "altos" deben insertarse o eliminarse de más de una lista enlazada.
Las operaciones que nos obligan a visitar cada nodo en orden ascendente (como imprimir la lista completa) brindan la oportunidad de realizar una desaleatorización detrás de escena de la estructura de niveles de la lista de omisión de una manera óptima, llevando la lista de omisión al momento de la búsqueda. (Elija el nivel del i-ésimo nodo finito para que sea 1 más el número de veces que es posible dividir repetidamente i por 2 antes de que se vuelva impar. Además, i = 0 para el encabezado de infinito negativo, ya que existe el caso especial habitual de elegir el nivel más alto posible para nodos infinitos negativos y/o positivos). Sin embargo, esto también permite que alguien sepa dónde están todos los nodos de nivel superior a 1 y los elimine.
Alternativamente, la estructura de niveles podría hacerse cuasialeatoria de la siguiente manera:
hacer que todos los nodos sean de nivel 1y ← 1mientras que el número de nodos en el nivel j > 1 , hacer para cada i-ésimo nodo en el nivel j, hacer si i es impar y i no es el último nodo en el nivel j Elige aleatoriamente si promoverlo al nivel j+1 De lo contrario, si i es par y el nodo i-1 no fue promovido promoverlo al nivel j+1 terminar si se repite j ← j + 1repetir
Al igual que la versión desaleatorizada, la cuasialeatorización solo se realiza cuando existe algún otro motivo para ejecutar una operación (que visita cada nodo).
La ventaja de esta aleatoriedad cuasialeatoria es que no revela tanta información relacionada con la estructura de niveles a un usuario adversario como la desaleatorizada. Esto es deseable porque un usuario adversario que es capaz de determinar qué nodos no están en el nivel más bajo puede pesimizar el rendimiento simplemente eliminando nodos de nivel superior. (Bethea y Reiter, sin embargo, sostienen que, de todos modos, un adversario puede usar métodos probabilísticos y de tiempo para forzar la degradación del rendimiento. [4] ) Se sigue garantizando que el rendimiento de la búsqueda sea logarítmico.
Sería tentador hacer la siguiente "optimización": en la parte que dice "A continuación, para cada i th...", olvídese de hacer un lanzamiento de moneda para cada par par-impar. Simplemente lance una moneda una vez para decidir si promover solo los pares o solo los impares. En lugar de lanzamientos de moneda, solo habría de ellos. Desafortunadamente, esto le da al usuario adversario una probabilidad del 50/50 de acertar al adivinar que todos los nodos pares (entre los que están en el nivel 1 o superior) son superiores al nivel uno. Esto es a pesar de la propiedad de que hay una probabilidad muy baja de adivinar que un nodo en particular está en el nivel N para algún entero N.
Una lista de saltos no proporciona las mismas garantías de rendimiento en el peor de los casos absolutos que las estructuras de datos de árboles balanceados más tradicionales , porque siempre es posible (aunque con una probabilidad muy baja [5] ) que los lanzamientos de moneda utilizados para construir la lista de saltos produzcan una estructura mal balanceada. Sin embargo, funcionan bien en la práctica, y se ha argumentado que el esquema de balanceo aleatorio es más fácil de implementar que los esquemas de balanceo deterministas utilizados en árboles de búsqueda binarios balanceados. Las listas de saltos también son útiles en computación paralela , donde las inserciones se pueden realizar en diferentes partes de la lista de saltos en paralelo sin ningún reequilibrio global de la estructura de datos. Tal paralelismo puede ser especialmente ventajoso para el descubrimiento de recursos en una red inalámbrica ad-hoc porque una lista de saltos aleatoria se puede hacer robusta a la pérdida de cualquier nodo individual. [6]
Como se describió anteriormente, una lista de omisión es capaz de insertar y eliminar rápidamente valores de una secuencia ordenada, pero solo tiene búsquedas lentas de valores en una posición dada en la secuencia (es decir, devuelve el valor 500); sin embargo, con una modificación menor, la velocidad de las búsquedas indexadas de acceso aleatorio se puede mejorar a .
Para cada enlace, también se almacena el ancho del enlace. El ancho se define como la cantidad de enlaces de la capa inferior que atraviesa cada uno de los enlaces de "carril rápido" de la capa superior.
Por ejemplo, aquí están los anchos de los enlaces en el ejemplo en la parte superior de la página:
1 10 o---> o---------------------------------------------------------> o Nivel superior 1 3 2 5 o---> o---------------> o---------> o---------------- -----------> o Nivel 3 1 2 1 2 3 2 o---> o---------> o---> o---------> o---------------> o ---------> o Nivel 2 1 1 1 1 1 1 1 1 1 1 1 o---> o---> o---> o---> o---> o---> o---> o---> o---> o---> o---> o Nivel inferiorCabeza 1º 2º 3º 4º 5º 6º 7º 8º 9º 10º NINGUNO Nodo Nodo Nodo Nodo Nodo Nodo Nodo Nodo Nodo Nodo
Tenga en cuenta que el ancho de un enlace de nivel superior es la suma de los enlaces componentes que se encuentran debajo de él (es decir, el enlace de ancho 10 abarca los enlaces de anchos 3, 2 y 5 que se encuentran inmediatamente debajo de él). En consecuencia, la suma de todos los anchos es la misma en todos los niveles (10 + 1 = 1 + 3 + 2 + 5 = 1 + 2 + 1 + 2 + 3 + 2).
Para indexar la lista de saltos y encontrar el valor i, recorra la lista de saltos mientras cuenta hacia abajo los anchos de cada vínculo recorrido. Descienda un nivel cuando el próximo ancho sea demasiado grande.
Por ejemplo, para encontrar el nodo en la quinta posición (Nodo 5), recorra un enlace de ancho 1 en el nivel superior. Ahora se necesitan cuatro pasos más, pero el siguiente ancho en este nivel es diez, lo que es demasiado grande, por lo que debe descender un nivel. Recorra un enlace de ancho 3. Dado que otro paso de ancho 2 sería demasiado, descienda hasta el nivel inferior. Ahora recorra el enlace final de ancho 1 para alcanzar el total acumulado objetivo de 5 (1+3+1).
función lookupByPositionIndex(i) nodo ← cabeza i ← i + 1 # no contar la cabeza como un paso para el nivel de arriba a abajo do while i ≥ node.width[level] do # si el siguiente paso no está demasiado lejos i ← i - node.width[level] # restar el ancho actual node ← node.next[level] # avanzar en el nivel actual repeat repeat return node.value end function
Este método de implementación de la indexación se detalla en "A skip list cookbook" de William Pugh [7].
Las listas de omisión fueron descritas por primera vez en 1989 por William Pugh . [8]
Para citar al autor:
Las listas de salto son una estructura de datos probabilística que parece probable que sustituya a los árboles equilibrados como el método de implementación preferido para muchas aplicaciones. Los algoritmos de listas de salto tienen los mismos límites de tiempo esperados asintóticos que los árboles equilibrados y son más simples, más rápidos y utilizan menos espacio.
— William Pugh, Mantenimiento simultáneo de listas de omisión (1989)
Lista de aplicaciones y marcos que utilizan listas de omisión:
Las listas de salto también se utilizan en aplicaciones distribuidas (donde los nodos representan computadoras físicas y los punteros representan conexiones de red) y para implementar colas de prioridad concurrentes altamente escalables con menos contención de bloqueo, [17] o incluso sin bloqueo , [18] [19] [20] así como diccionarios concurrentes sin bloqueo . [21] También hay varias patentes estadounidenses para usar listas de salto para implementar colas de prioridad (sin bloqueo) y diccionarios concurrentes. [22]














