
En informática , una tabla hash es una estructura de datos que implementa una matriz asociativa , también llamada diccionario o simplemente mapa ; una matriz asociativa es un tipo de datos abstracto que asigna claves a valores . [2] Una tabla hash utiliza una función hash para calcular un índice , también llamado código hash , en una matriz de contenedores o ranuras , desde donde se puede encontrar el valor deseado. Durante la búsqueda, la clave se convierte en hash y el hash resultante indica dónde se almacena el valor correspondiente. Un mapa implementado por una tabla hash se llama mapa hash .
La mayoría de los diseños de tablas hash emplean una función hash imperfecta . Por lo tanto, las colisiones hash , en las que la función hash genera el mismo índice para más de una clave, normalmente deben solucionarse de alguna manera.
En una tabla hash bien dimensionada, la complejidad temporal promedio para cada búsqueda es independiente de la cantidad de elementos almacenados en la tabla. Muchos diseños de tablas hash también permiten inserciones y eliminaciones arbitrarias de pares clave-valor , a un costo promedio constante amortizado por operación. [3] [4] [5]
El hash es un ejemplo de un equilibrio entre el espacio y el tiempo . Si la memoria es infinita, se puede utilizar toda la clave directamente como índice para localizar su valor con un único acceso a la memoria. Por otro lado, si se dispone de tiempo infinito, se pueden almacenar valores sin tener en cuenta sus claves y se puede utilizar una búsqueda binaria o lineal para recuperar el elemento. [6] : 458
En muchas situaciones, las tablas hash resultan ser, en promedio, más eficientes que los árboles de búsqueda o cualquier otra estructura de búsqueda de tablas . Por este motivo, se utilizan ampliamente en muchos tipos de software informático , en particular para matrices asociativas , indexación de bases de datos , cachés y conjuntos .
La idea del hash surgió de forma independiente en diferentes lugares. En enero de 1953, Hans Peter Luhn escribió un memorando interno de IBM que utilizaba el hash con encadenamiento. El primer ejemplo de direccionamiento abierto fue propuesto por AD Linh, basándose en el memorando de Luhn. [4] : 547 Casi al mismo tiempo, Gene Amdahl , Elaine M. McGraw , Nathaniel Rochester y Arthur Samuel de IBM Research implementaron el hash para el ensamblador IBM 701. [7] : 124 El direccionamiento abierto con sondeo lineal se atribuye a Amdahl, aunque Andrey Ershov tuvo la misma idea de forma independiente. [7] : 124–125 El término "direccionamiento abierto" fue acuñado por W. Wesley Peterson en su artículo que analiza el problema de la búsqueda en archivos grandes. [8] : 15
El primer trabajo publicado sobre hash con encadenamiento se atribuye a Arnold Dumey , quien discutió la idea de usar el resto módulo un primo como función hash. [8] : 15 La palabra "hashing" fue publicada por primera vez en un artículo de Robert Morris. [7] : 126 Konheim y Weiss presentaron originalmente un análisis teórico del sondeo lineal. [8] : 15
Una matriz asociativa almacena un conjunto de pares (clave, valor) y permite la inserción, eliminación y búsqueda, con la restricción de claves únicas . En la implementación de la tabla hash de matrices asociativas, una matriz de longitud se llena parcialmente con elementos, donde . Un valor se almacena en una ubicación de índice , donde es una función hash y . [8] : 2 Bajo suposiciones razonables, las tablas hash tienen mejores límites de complejidad temporal en las operaciones de búsqueda, eliminación e inserción en comparación con los árboles de búsqueda binarios autoequilibrados . [8] : 1
Las tablas hash también se utilizan comúnmente para implementar conjuntos, omitiendo el valor almacenado para cada clave y simplemente rastreando si la clave está presente. [8] : 1
Un factor de carga es una estadística crítica de una tabla hash y se define de la siguiente manera: [1] donde
El rendimiento de la tabla hash se deteriora en relación con el factor de carga . [8] : 2
El software normalmente garantiza que el factor de carga se mantenga por debajo de una cierta constante, . Esto ayuda a mantener un buen rendimiento. Por lo tanto, un enfoque común es cambiar el tamaño o "rehacer" la tabla hash cada vez que el factor de carga alcanza . De manera similar, la tabla también puede cambiar de tamaño si el factor de carga cae por debajo de . [9]
Con tablas hash de encadenamiento independientes, cada ranura de la matriz de contenedores almacena un puntero a una lista o matriz de datos. [10]
Las tablas hash de encadenamiento independientes sufren una disminución gradual del rendimiento a medida que aumenta el factor de carga, y no existe un punto fijo más allá del cual sea absolutamente necesario cambiar el tamaño. [9]
Con encadenamiento separado, el valor que ofrece el mejor rendimiento suele estar entre 1 y 3. [9]
Con direccionamiento abierto, cada ranura de la matriz de contenedores contiene exactamente un elemento. Por lo tanto, una tabla hash con direccionamiento abierto no puede tener un factor de carga mayor que 1. [10]
El rendimiento del direccionamiento abierto se vuelve muy malo cuando el factor de carga se acerca a 1. [9]
Por lo tanto, una tabla hash que utiliza direccionamiento abierto debe redimensionarse o rehacerse si el factor de carga se acerca a 1. [9]
Con direccionamiento abierto, las cifras aceptables de factor de carga máxima deberían oscilar entre 0,6 y 0,75. [11] [12] : 110
Una función hash asigna el universo de claves a índices o ranuras dentro de la tabla, es decir, para . Las implementaciones convencionales de funciones hash se basan en el supuesto del universo entero de que todos los elementos de la tabla provienen del universo , donde la longitud de bits de está confinada dentro del tamaño de palabra de una arquitectura de computadora . [8] : 2
Se dice que una función hash es perfecta para un conjunto dado si es inyectiva en , es decir, si cada elemento se asigna a un valor diferente en . [13] [14] Se puede crear una función hash perfecta si se conocen todas las claves de antemano. [13]
Los esquemas de hash utilizados en el supuesto de universo entero incluyen hash por división, hash por multiplicación, hash universal , hash perfecto dinámico y hash perfecto estático . [8] : 2 Sin embargo, el hash por división es el esquema más utilizado. [15] : 264 [12] : 110
El esquema en el hash por división es el siguiente: [8] : 2 donde es el valor hash de y es el tamaño de la tabla.
El esquema en el hash por multiplicación es el siguiente: [8] : 2–3 Donde es una constante de valor real no entero y es el tamaño de la tabla. Una ventaja del hash por multiplicación es que no es crítico. [8] : 2–3 Aunque cualquier valor produce una función hash, Donald Knuth sugiere usar la proporción áurea . [8] : 3
La distribución uniforme de los valores hash es un requisito fundamental de una función hash. Una distribución no uniforme aumenta la cantidad de colisiones y el costo de resolverlas. A veces es difícil garantizar la uniformidad por diseño, pero se puede evaluar empíricamente mediante pruebas estadísticas, por ejemplo, una prueba de chi-cuadrado de Pearson para distribuciones uniformes discretas. [16] [17]
La distribución debe ser uniforme solo para los tamaños de tabla que se dan en la aplicación. En particular, si se utiliza un redimensionamiento dinámico con duplicación exacta y reducción a la mitad del tamaño de la tabla, entonces la función hash debe ser uniforme solo cuando el tamaño sea una potencia de dos . En este caso, el índice se puede calcular como un rango de bits de la función hash. Por otro lado, algunos algoritmos hash prefieren que el tamaño sea un número primo . [18]
En el caso de los esquemas de direccionamiento abierto , la función hash también debería evitar la agrupación , es decir, la asignación de dos o más claves a ranuras consecutivas. Dicha agrupación puede hacer que el costo de búsqueda se dispare, incluso si el factor de carga es bajo y las colisiones son poco frecuentes. Se afirma que el popular hash multiplicativo tiene un comportamiento de agrupación particularmente deficiente. [18] [4]
El hash K-independiente ofrece una manera de probar que una determinada función hash no tiene conjuntos de claves incorrectos para un tipo dado de tabla hash. Se conocen varios resultados de K-independencia para esquemas de resolución de colisiones como el sondeo lineal y el hash cuckoo. Dado que la K-independencia puede probar que una función hash funciona, uno puede entonces enfocarse en encontrar la función hash más rápida posible. [19]
Un algoritmo de búsqueda que utiliza hash consta de dos partes. La primera parte consiste en calcular una función hash que transforma la clave de búsqueda en un índice de matriz . El caso ideal es aquel en el que no hay dos claves de búsqueda que tengan el mismo índice de matriz. Sin embargo, este no siempre es el caso y es imposible garantizarlo para datos no visibles. [20] : 515 Por lo tanto, la segunda parte del algoritmo es la resolución de colisiones. Los dos métodos comunes para la resolución de colisiones son el encadenamiento separado y el direccionamiento abierto. [6] : 458

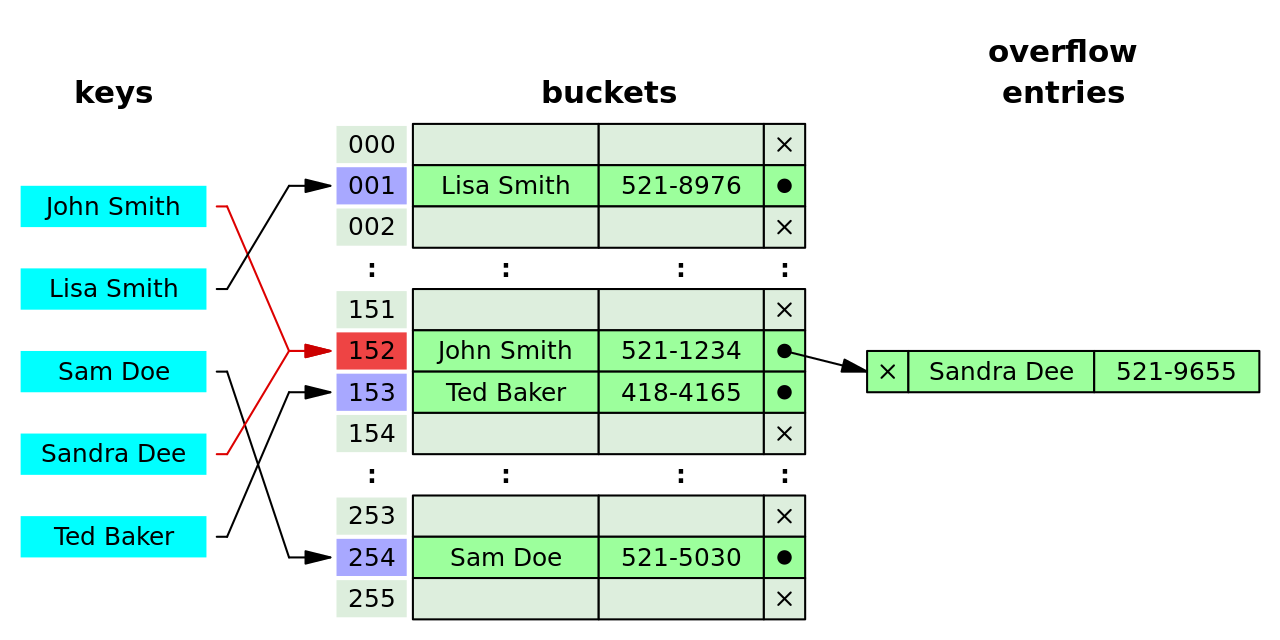
En el encadenamiento por separado, el proceso implica la construcción de una lista enlazada con un par clave-valor para cada índice de matriz de búsqueda. Los elementos colisionados se encadenan entre sí a través de una única lista enlazada, que se puede recorrer para acceder al elemento con una clave de búsqueda única. [6] : 464 La resolución de colisiones a través del encadenamiento con lista enlazada es un método común de implementación de tablas hash. Sea y la tabla hash y el nodo respectivamente, la operación implica lo siguiente: [15] : 258
Chained-Hash-Insert( T , k ) inserta x al principio de la lista enlazada T [ h ( k )]Chained-Hash-Search( T , k ) busca un elemento con clave k en una lista enlazada T [ h ( k )]Chained-Hash-Delete( T , k ) elimina x de la lista enlazada T [ h ( k )]
Si el elemento es comparable numérica o léxicamente y se inserta en la lista manteniendo el orden total , resulta en una terminación más rápida de las búsquedas fallidas. [20] : 520–521
Si las claves están ordenadas , podría ser eficiente utilizar conceptos " autoorganizados " como el uso de un árbol binario de búsqueda autoequilibrado , a través del cual se podría reducir el peor caso teórico a , aunque introduce complejidades adicionales. [20] : 521
En el hash dinámico perfecto , se utilizan tablas hash de dos niveles para reducir la complejidad de búsqueda y garantizar que sea una tarea en el peor de los casos. En esta técnica, los grupos de entradas se organizan como tablas hash perfectas con ranuras que proporcionan un tiempo de búsqueda constante en el peor de los casos y un tiempo amortizado bajo para la inserción. [21] Un estudio muestra que el encadenamiento separado basado en matrices tiene un 97 % más de rendimiento en comparación con el método de lista enlazada estándar bajo carga pesada. [22] : 99
Técnicas como el uso de árboles de fusión para cada grupo también dan como resultado un tiempo constante para todas las operaciones con alta probabilidad. [23]
La lista enlazada de la implementación de encadenamiento independiente puede no ser consciente de la memoria caché debido a la localidad espacial ( localidad de referencia ) cuando los nodos de la lista enlazada están dispersos en la memoria, por lo que el recorrido de la lista durante la inserción y la búsqueda puede implicar ineficiencias de la memoria caché de la CPU . [22] : 91
En las variantes de resolución de colisiones que tienen en cuenta la memoria caché mediante encadenamiento separado, se utiliza una matriz dinámica que es más compatible con la memoria caché en el lugar donde normalmente se implementa una lista enlazada o árboles de búsqueda binarios autoequilibrados, ya que el patrón de asignación contiguo de la matriz podría ser explotado por prefetchers de memoria caché de hardware (como el búfer de búsqueda de traducción) , lo que da como resultado un menor tiempo de acceso y consumo de memoria. [24] [25] [26]


El direccionamiento abierto es otra técnica de resolución de colisiones en la que cada registro de entrada se almacena en la propia matriz de contenedores y la resolución de hash se realiza mediante sondeo . Cuando se debe insertar una nueva entrada, se examinan los contenedores, comenzando con la ranura a la que se le ha aplicado el hash y siguiendo una secuencia de sondeo , hasta que se encuentra una ranura desocupada. Cuando se busca una entrada, se escanean los contenedores en la misma secuencia, hasta que se encuentra el registro de destino o una ranura de matriz sin usar, lo que indica una búsqueda fallida. [27]
Las secuencias de sonda más conocidas incluyen:
El rendimiento del direccionamiento abierto puede ser más lento en comparación con el encadenamiento separado, ya que la secuencia de sondeo aumenta cuando el factor de carga se acerca a 1. [9] [22] : 93 El sondeo da como resultado un bucle infinito si el factor de carga llega a 1, en el caso de una tabla completamente llena. [6] : 471 El costo promedio del sondeo lineal depende de la capacidad de la función hash para distribuir los elementos de manera uniforme en toda la tabla para evitar la agrupación , ya que la formación de agrupaciones daría como resultado un mayor tiempo de búsqueda. [6] : 472
Dado que las ranuras están ubicadas en posiciones sucesivas, el sondeo lineal podría conducir a una mejor utilización de la memoria caché de la CPU debido a la localidad de las referencias, lo que resulta en una latencia de memoria reducida . [28]
El hash fusionado es un híbrido entre el encadenamiento independiente y el direccionamiento abierto en el que los contenedores o nodos se vinculan dentro de la tabla. [30] : 6–8 El algoritmo es ideal para la asignación de memoria fija . [30] : 4 La colisión en el hash fusionado se resuelve identificando la ranura vacía con el índice más grande en la tabla hash, luego el valor en colisión se inserta en esa ranura. El contenedor también está vinculado a la ranura del nodo insertado que contiene su dirección hash en colisión. [30] : 8
El hash de cuco es una forma de técnica de resolución de colisiones de direccionamiento abierto que garantiza la complejidad de búsqueda en el peor de los casos y un tiempo amortizado constante para las inserciones. La colisión se resuelve mediante el mantenimiento de dos tablas hash, cada una con su propia función hash, y la ranura colisionada se reemplaza con el elemento dado, y el elemento ocupado de la ranura se desplaza a la otra tabla hash. El proceso continúa hasta que cada clave tiene su propio lugar en los contenedores vacíos de las tablas; si el procedimiento entra en un bucle infinito (lo que se identifica mediante el mantenimiento de un contador de bucle de umbral), ambas tablas hash se vuelven a codificar con funciones hash más nuevas y el procedimiento continúa. [31] : 124–125
El hash Hopscotch es un algoritmo basado en direccionamiento abierto que combina los elementos del hash cuckoo , el sondeo lineal y el encadenamiento a través de la noción de un vecindario de contenedores (los contenedores subsiguientes alrededor de cualquier contenedor ocupado dado, también llamado contenedor "virtual"). [32] : 351–352 El algoritmo está diseñado para ofrecer un mejor rendimiento cuando el factor de carga de la tabla hash crece más allá del 90%; también proporciona un alto rendimiento en configuraciones concurrentes , por lo que es muy adecuado para implementar una tabla hash concurrente redimensionable . [32] : 350 La característica de vecindario del hash Hopscotch garantiza una propiedad de que el costo de encontrar el elemento deseado de cualquier contenedor dado dentro del vecindario es muy cercano al costo de encontrarlo en el contenedor mismo; el algoritmo intenta ser un elemento en su vecindario, con un posible costo involucrado en desplazar otros elementos. [32] : 352
Cada contenedor dentro de la tabla hash incluye una "información de salto" adicional: una matriz de bits de H -bits para indicar la distancia relativa del elemento que se ha convertido originalmente en el contenedor virtual actual dentro de H -1 entradas. [32] : 352 Sea y la clave que se va a insertar y el contenedor en el que se convierte la clave respectivamente; hay varios casos involucrados en el procedimiento de inserción de modo que se compromete la propiedad de vecindad del algoritmo: [32] : 352–353 si está vacío, se inserta el elemento y el bit más a la izquierda del mapa de bits se establece en 1; si no está vacío, se utiliza un sondeo lineal para encontrar una ranura vacía en la tabla, el mapa de bits del contenedor se actualiza seguido de la inserción; si la ranura vacía no está dentro del rango de la vecindad, es decir , H -1, se realiza un intercambio posterior y una manipulación de la matriz de bits de información de salto de cada contenedor de acuerdo con sus propiedades invariantes de vecindad . [32] : 353
El hashing Robin Hood es un algoritmo de resolución de colisiones basado en direccionamiento abierto; las colisiones se resuelven favoreciendo el desplazamiento del elemento que está más alejado (o la longitud de secuencia de sonda (PSL) más larga) de su "ubicación de origen", es decir, el depósito en el que se ha introducido el elemento. [33] : 12 Aunque el hashing Robin Hood no cambia el coste teórico de búsqueda , afecta significativamente la varianza de la distribución de los elementos en los depósitos, [34] : 2 es decir, se ocupa de la formación de clústeres en la tabla hash. [35] Cada nodo dentro de la tabla hash que utiliza el hashing Robin Hood debe aumentarse para almacenar un valor PSL adicional. [36] Sea la clave que se va a insertar, la longitud PSL (incremental) de , la tabla hash y el índice, el procedimiento de inserción es el siguiente: [33] : 12–13 [37] : 5
Las inserciones repetidas hacen que el número de entradas en una tabla hash crezca, lo que en consecuencia aumenta el factor de carga; para mantener el rendimiento amortizado de las operaciones de búsqueda e inserción, una tabla hash se redimensiona dinámicamente y los elementos de las tablas se vuelven a codificar en los contenedores de la nueva tabla hash, [9] ya que los elementos no se pueden copiar ya que variar los tamaños de tabla da como resultado diferentes valores hash debido a la operación de módulo . [38] Si una tabla hash se vuelve "demasiado vacía" después de eliminar algunos elementos, se puede realizar un cambio de tamaño para evitar el uso excesivo de memoria . [39]
Generalmente, se asigna de forma privada una nueva tabla hash con un tamaño que duplica al de la tabla hash original y cada elemento de la tabla hash original se mueve a la tabla recién asignada calculando los valores hash de los elementos seguidos de la operación de inserción. La repetición del hash es simple, pero computacionalmente costosa. [40] : 478–479
Algunas implementaciones de tablas hash, en particular en sistemas en tiempo real , no pueden pagar el precio de agrandar la tabla hash de una sola vez, porque puede interrumpir operaciones críticas en el tiempo. Si no se puede evitar el cambio de tamaño dinámico, una solución es realizar el cambio de tamaño gradualmente para evitar un bache de almacenamiento (normalmente al 50 % del tamaño de la nueva tabla) durante el rehashing y para evitar la fragmentación de la memoria que desencadena la compactación del montón debido a la desasignación de grandes bloques de memoria causada por la antigua tabla hash. [41] : 2–3 En tal caso, la operación de rehashing se realiza de forma incremental mediante la extensión del bloque de memoria anterior asignado para la antigua tabla hash de modo que los contenedores de la tabla hash permanezcan inalterados. Un enfoque común para el rehashing amortizado implica mantener dos funciones hash y . El proceso de rehacer el hash de los elementos de un depósito de acuerdo con la nueva función hash se denomina limpieza , que se implementa a través del patrón de comando encapsulando las operaciones como , y a través de un contenedor de modo que cada elemento en el depósito se rehace y su procedimiento implica lo siguiente: [41] : 3
El hash lineal es una implementación de la tabla hash que permite crecimientos o reducciones dinámicas de la tabla, un segmento a la vez. [42]
El rendimiento de una tabla hash depende de la capacidad de la función hash para generar números cuasialeatorios ( ) para las entradas en la tabla hash donde , y denota la clave, el número de contenedores y la función hash tal que . Si la función hash genera lo mismo para claves distintas ( ), esto da como resultado una colisión , que se maneja de varias maneras. La complejidad de tiempo constante ( ) de la operación en una tabla hash se presupone con la condición de que la función hash no genere índices en colisión; por lo tanto, el rendimiento de la tabla hash es directamente proporcional a la capacidad de la función hash elegida para dispersar los índices. [43] : 1 Sin embargo, la construcción de una función hash de este tipo es prácticamente inviable , por lo que las implementaciones dependen de técnicas de resolución de colisiones específicas del caso para lograr un mayor rendimiento. [43] : 2
Las tablas hash se utilizan comúnmente para implementar muchos tipos de tablas en memoria. Se utilizan para implementar matrices asociativas . [29]
Las tablas hash también se pueden utilizar como estructuras de datos basadas en disco e índices de bases de datos (como en dbm ), aunque los árboles B son más populares en estas aplicaciones. [44]
Las tablas hash se pueden utilizar para implementar cachés , tablas de datos auxiliares que se utilizan para acelerar el acceso a los datos que se almacenan principalmente en medios más lentos. En esta aplicación, las colisiones de hash se pueden manejar descartando una de las dos entradas en colisión, generalmente borrando el elemento antiguo que está almacenado actualmente en la tabla y sobrescribiéndolo con el nuevo elemento, de modo que cada elemento de la tabla tenga un valor hash único. [45] [46]
Las tablas hash se pueden utilizar en la implementación de estructuras de datos de conjunto , que pueden almacenar valores únicos sin ningún orden particular; el conjunto se utiliza normalmente para probar la pertenencia de un valor en la colección, en lugar de la recuperación de elementos. [47]
Una tabla de transposición a una tabla hash compleja que almacena información sobre cada sección que se ha buscado. [48]
Muchos lenguajes de programación proporcionan la funcionalidad de tabla hash, ya sea como matrices asociativas integradas o como módulos de biblioteca estándar .
En JavaScript , un "objeto" es una colección mutable de pares clave-valor (llamados "propiedades"), donde cada clave es una cadena o un "símbolo" único garantizado; cualquier otro valor, cuando se utiliza como clave, primero se convierte en una cadena. Aparte de los siete tipos de datos "primitivos", cada valor en JavaScript es un objeto. [49] ECMAScript 2015 también agregó la Mapestructura de datos, que acepta valores arbitrarios como claves. [50]
C++11 incluye unordered_mapen su biblioteca estándar para almacenar claves y valores de tipos arbitrarios . [51]
Los implementos integrados de Gomap crean una tabla hash en forma de tipo . [52]
El lenguaje de programación Java incluye las colecciones HashSet, HashMap, LinkedHashSety LinkedHashMap genéricas . [53]
Los implementos integrados de Pythondict crean una tabla hash en forma de tipo . [54]
El modelo integrado de RubyHash utiliza el modelo de direccionamiento abierto desde Ruby 2.4 en adelante. [55]
El lenguaje de programación Rust incluye HashMap, HashSetcomo parte de la biblioteca estándar de Rust. [56]
La biblioteca estándar .NETHashSet incluye y Dictionary, [57] [58] por lo que se puede utilizar desde lenguajes como C# y VB.NET . [59]
{{cite web}}: CS1 maint: bot: estado de URL original desconocido ( enlace )




![{\displaystyle A[h(x)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ac75d530b12267b829df7cff8b2ff01a24e61ab0)


























![{\displaystyle x.psl\ \leq \ T[j].psl}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0813eb6a21c2c8a817aa86085d3cf9417f01e8fb)
![{\displaystyle x.psl\ >\T[j].psl}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d06f4753fda641edd5afb066239100a667124f39)
![{\displaystyle T[j]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb1f9ca1ed801caf88d5004aa3685644667099b6)








![{\displaystyle \mathrm {Tabla} [h_{\text{antiguo}}(\mathrm {clave} )]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/afcb195bb40a51be98c16b6d9b930061f3c11682)
![{\displaystyle \mathrm {Tabla} [h_{\text{nuevo}}(\mathrm {clave} )]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d8097baf3c9220a1be057b3c86395debce381845)



