Estimación de la importancia de una palabra en un documento
En recuperación de información , tf–idf (también TF*IDF , TFIDF , TF–IDF o Tf–idf ), abreviatura de frecuencia de término–frecuencia inversa de documento , es una medida de importancia de una palabra para un documento en una colección o corpus , ajustada por el hecho de que algunas palabras aparecen con mayor frecuencia en general. [1] Al igual que el modelo de bolsa de palabras, modela un documento como un conjunto múltiple de palabras, sin orden de palabras . Es un refinamiento del modelo simple de bolsa de palabras , al permitir que el peso de las palabras dependa del resto del corpus.
Se utilizó a menudo como factor de ponderación en búsquedas de recuperación de información, minería de texto y modelado de usuarios . Una encuesta realizada en 2015 mostró que el 83% de los sistemas de recomendación basados en texto en bibliotecas digitales usaban tf-idf. [2] Los motores de búsqueda solían utilizar variaciones del esquema de ponderación tf-idf como herramienta central para puntuar y clasificar la relevancia de un documento dada una consulta de usuario .
Una de las funciones de clasificación más simples se calcula sumando tf–idf para cada término de consulta; muchas funciones de clasificación más sofisticadas son variantes de este modelo simple.
Motivaciones
Karen Spärck Jones (1972) concibió una interpretación estadística de la especificidad de los términos llamada Frecuencia Inversa de Documentos (idf), que se convirtió en una piedra angular de la ponderación de los términos: [3]
La especificidad de un término se puede cuantificar como una función inversa del número de documentos en los que aparece.
Por ejemplo, la frecuencia del documento (df) y la frecuencia del documento (idf) de algunas palabras en las 37 obras de Shakespeare son las siguientes: [4]
Vemos que " Romeo ", " Falstaff " y "ensalada" aparecen en muy pocas obras, por lo que al ver estas palabras, uno podría tener una buena idea de qué obra podría estar en juego. En cambio, "bueno" y "dulce" aparecen en todas las obras y no brindan ninguna información sobre qué obra es.
Definición
La tf–idf es el producto de dos estadísticas, la frecuencia de términos y la frecuencia inversa de documentos . Existen varias formas de determinar los valores exactos de ambas estadísticas.
Una fórmula que tiene como objetivo definir la importancia de una palabra clave o frase dentro de un documento o una página web.
Frecuencia de término
La frecuencia del término, tf( t , d ) , es la frecuencia relativa del término t dentro del documento d ,
,
donde f t , d es el recuento bruto de un término en un documento, es decir, la cantidad de veces que ese término t aparece en el documento d . Nótese que el denominador es simplemente la cantidad total de términos en el documento d (contando cada ocurrencia del mismo término por separado). Hay varias otras formas de definir la frecuencia de términos: [5] : 128
el recuento bruto en sí: tf( t , d ) = f t , d
"Frecuencias" booleanas : tf( t , d ) = 1 si t ocurre en d y 0 en caso contrario;
frecuencia aumentada, para evitar un sesgo hacia documentos más largos, por ejemplo, frecuencia bruta dividida por la frecuencia bruta del término que aparece con mayor frecuencia en el documento:
Frecuencia inversa del documento
La frecuencia inversa de los documentos es una medida de cuánta información proporciona la palabra, es decir, cuán común o rara es en todos los documentos. Es la fracción inversa escalada logarítmicamente de los documentos que contienen la palabra (obtenida dividiendo el número total de documentos por el número de documentos que contienen el término y luego tomando el logaritmo de ese cociente):
con
: número total de documentos en el corpus
: número de documentos en los que aparece el término (es decir, ). Si el término no está en el corpus, esto dará lugar a una división por cero. Por lo tanto, es común ajustar el numerador y el denominador a .
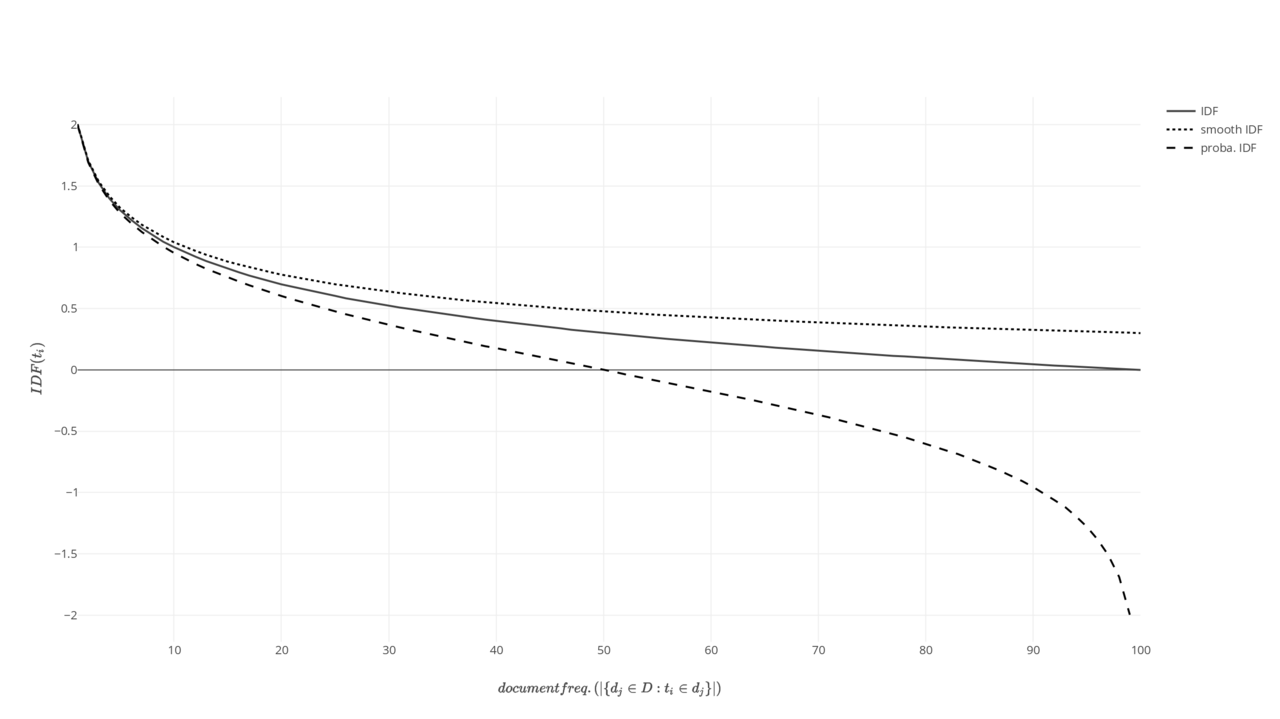
Gráfico de diferentes funciones de frecuencia de documentos inversas: estándar, suave, probabilística.
Frecuencia de término – frecuencia inversa de documento
Luego tf–idf se calcula como
Un peso alto en tf–idf se alcanza con una frecuencia alta de término (en el documento dado) y una frecuencia baja de documento del término en toda la colección de documentos; por lo tanto, los pesos tienden a filtrar los términos comunes. Dado que la razón dentro de la función logarítmica de idf es siempre mayor o igual a 1, el valor de idf (y tf–idf) es mayor o igual a 0. A medida que un término aparece en más documentos, la razón dentro del logaritmo se acerca a 1, lo que acerca idf y tf–idf a 0.
Justificación de las FDI
Karen Spärck Jones introdujo el término IDF como "especificidad de término" en un artículo de 1972. Aunque ha funcionado bien como heurística , sus fundamentos teóricos han sido problemáticos durante al menos tres décadas después, y muchos investigadores han intentado encontrar justificaciones teóricas de la información para ello. [7]
La propia explicación de Spärck Jones no propuso mucha teoría, aparte de una conexión con la ley de Zipf . [7] Se han hecho intentos de poner a idf sobre una base probabilística , [8] estimando la probabilidad de que un documento dado d contenga un término t como la frecuencia relativa del documento,
De modo que podemos definir idf como
Es decir, la frecuencia inversa del documento es el logaritmo de la frecuencia relativa del documento "inversa".
Esta interpretación probabilística a su vez adopta la misma forma que la de la autoinformación . Sin embargo, la aplicación de tales nociones de teoría de la información a los problemas de recuperación de información conduce a problemas cuando se intenta definir los espacios de eventos apropiados para las distribuciones de probabilidad requeridas : no solo se deben tener en cuenta los documentos, sino también las consultas y los términos. [7]
Enlace con la teoría de la información
Tanto la frecuencia de términos como la frecuencia inversa de documentos se pueden formular en términos de la teoría de la información ; esto ayuda a entender por qué su producto tiene un significado en términos del contenido informativo conjunto de un documento. Un supuesto característico sobre la distribución es que:
Esta suposición y sus implicaciones, según Aizawa: “representan la heurística que emplea tf–idf”. [9]
La entropía condicional de un documento "escogido al azar" en el corpus , condicional al hecho de que contiene un término específico (y asumiendo que todos los documentos tienen la misma probabilidad de ser elegidos) es:
En términos de notación, y son "variables aleatorias" que corresponden respectivamente a la extracción de un documento o de un término. La información mutua puede expresarse como
El último paso es expandir , la probabilidad incondicional de extraer un término, con respecto a la elección (aleatoria) de un documento, para obtener:
Esta expresión muestra que al sumar los Tf–idf de todos los términos y documentos posibles se recupera la información mutua entre documentos y términos teniendo en cuenta todas las especificidades de su distribución conjunta. [9] Por lo tanto, cada Tf–idf lleva el "bit de información" asociado a un par término x documento.
Ejemplo de tf–idf
Supongamos que tenemos tablas de recuento de términos de un corpus que consta de solo dos documentos, como los que se enumeran a la derecha.
El cálculo de tf–idf para el término "this" se realiza de la siguiente manera:
En su forma de frecuencia bruta, tf es simplemente la frecuencia de la palabra "this" para cada documento. En cada documento, la palabra "this" aparece una vez; pero como el documento 2 tiene más palabras, su frecuencia relativa es menor.
Un idf es constante por corpus y representa la proporción de documentos que incluyen la palabra "this". En este caso, tenemos un corpus de dos documentos y todos ellos incluyen la palabra "this".
Entonces, tf–idf es cero para la palabra "this", lo que implica que la palabra no es muy informativa ya que aparece en todos los documentos.
La palabra "ejemplo" es más interesante: aparece tres veces, pero solo en el segundo documento:
La idea detrás de tf–idf también se aplica a entidades distintas de términos. En 1998, el concepto de idf se aplicó a las citas. [10] Los autores argumentaron que "si una cita muy poco común es compartida por dos documentos, esta debería tener un peso mayor que una cita hecha por un gran número de documentos". Además, tf–idf se aplicó a "palabras visuales" con el propósito de realizar la correspondencia de objetos en videos, [11] y oraciones completas. [12] Sin embargo, el concepto de tf–idf no demostró ser más efectivo en todos los casos que un esquema tf simple (sin idf). Cuando tf–idf se aplicó a las citas, los investigadores no pudieron encontrar ninguna mejora con respecto a una ponderación simple de recuento de citas que no tenía un componente idf. [13]
Derivados
Varios esquemas de ponderación de términos se han derivado de tf–idf. Uno de ellos es TF–PDF (frecuencia de término * frecuencia proporcional de documento). [14] TF–PDF se introdujo en 2001 en el contexto de la identificación de temas emergentes en los medios. El componente PDF mide la diferencia de la frecuencia con la que aparece un término en diferentes dominios. Otro derivado es TF–IDuF. En TF–IDuF, [15] idf no se calcula en función del corpus de documentos que se va a buscar o recomendar. En cambio, idf se calcula en las colecciones de documentos personales de los usuarios. Los autores informan que TF–IDuF fue igualmente eficaz que tf–idf, pero también podría aplicarse en situaciones en las que, por ejemplo, un sistema de modelado de usuarios no tiene acceso a un corpus de documentos global.
^ Rajaraman, A.; Ullman, JD (2011). "Minería de datos" (PDF) . Minería de conjuntos de datos masivos . págs. 1–17. doi :10.1017/CBO9781139058452.002. ISBN 978-1-139-05845-2.
^ Breitinger, Corinna; Gipp, Bela; Langer, Stefan (26 de julio de 2015). "Sistemas de recomendación de artículos de investigación: una revisión bibliográfica". Revista internacional de bibliotecas digitales . 17 (4): 305–338. doi :10.1007/s00799-015-0156-0. ISSN 1432-5012. S2CID 207035184.
^ Spärck Jones, K. (1972). "Una interpretación estadística de la especificidad de los términos y su aplicación en la recuperación". Revista de documentación . 28 (1): 11–21. CiteSeerX 10.1.1.115.8343 . doi :10.1108/eb026526. S2CID 2996187.
^ Procesamiento del habla y del lenguaje (borrador de la 3.ª edición), Dan Jurafsky y James H. Martin, capítulo 14. https://web.stanford.edu/~jurafsky/slp3/14.pdf
^ Manning, CD; Raghavan, P.; Schutze, H. (2008). "Puntuación, ponderación de términos y el modelo de espacio vectorial" (PDF) . Introducción a la recuperación de información . p. 100. doi :10.1017/CBO9780511809071.007. ISBN978-0-511-80907-1.
^ "Estadísticas TFIDF | SAX-VSM".
^ abc Robertson, S. (2004). "Entender la frecuencia inversa de documentos: argumentos teóricos a favor de la IDF". Journal of Documentation . 60 (5): 503–520. doi :10.1108/00220410410560582.
^ Véase también Estimaciones de probabilidad en la práctica en Introducción a la recuperación de información .
^ ab Aizawa, Akiko (2003). "Una perspectiva de teoría de la información de las medidas tf-idf". Procesamiento y gestión de la información . 39 (1): 45–65. doi :10.1016/S0306-4573(02)00021-3. S2CID 45793141.
^ Bollacker, Kurt D.; Lawrence, Steve; Giles, C. Lee (1 de enero de 1998). "CiteSeer". Actas de la segunda conferencia internacional sobre agentes autónomos - AGENTS '98 . págs. 116–123. doi :10.1145/280765.280786. ISBN978-0-89791-983-8. Número de identificación del sujeto 3526393.
^ Sivic, Josef; Zisserman, Andrew (1 de enero de 2003). "Video Google: un enfoque de recuperación de texto para la comparación de objetos en videos". Actas de la Novena Conferencia Internacional IEEE sobre Visión por Computador. ICCV '03. págs. 1470–. doi :10.1109/ICCV.2003.1238663. ISBN978-0-7695-1950-0.S2CID14457153 .
^ Seki, Yohei. "Extracción de oraciones mediante tf/idf y ponderación de posición a partir de artículos de periódicos" (PDF) . Instituto Nacional de Informática.
^ Beel, Joeran; Breitinger, Corinna (2017). "Evaluación del esquema de ponderación de citas CC-IDF: ¿con qué eficacia se puede aplicar la 'Frecuencia de documento inversa' (IDF) a las referencias?" (PDF) . Actas de la 12.ª IConference . Archivado desde el original (PDF) el 22 de septiembre de 2020. Consultado el 29 de enero de 2017 .
^ Khoo Khyou Bun; Bun, Khoo Khyou; Ishizuka, M. (2001). "Sistema de seguimiento de temas emergentes". Actas del Tercer taller internacional sobre cuestiones avanzadas de comercio electrónico y sistemas de información basados en la Web. WECWIS 2001. págs. 2–11. CiteSeerX 10.1.1.16.7986 . doi :10.1109/wecwis.2001.933900. ISBN .978-0-7695-1224-2.S2CID 1049263 .
^ Langer, Stefan; Gipp, Bela (2017). "TF-IDuF: un nuevo esquema de ponderación de términos para el modelado de usuarios basado en colecciones de documentos personales de los usuarios" (PDF) . IConference .
Salton, G. ; Fox, EA; Wu, H. (1983). "Recuperación de información booleana extendida". Comunicaciones de la ACM . 26 (11): 1022–1036. doi :10.1145/182.358466. hdl : 1813/6351 . S2CID 207180535.
Salton, G. ; Buckley, C. (1988). "Enfoques de ponderación de términos en la recuperación automática de texto" (PDF) . Procesamiento y gestión de la información . 24 (5): 513–523. doi :10.1016/0306-4573(88)90021-0. hdl : 1813/6721 . S2CID 7725217.
Wu, HC; Luk, RWP; Wong, KF; Kwok, KL (2008). "Interpretación de los pesos de los términos TF-IDF como toma de decisiones de relevancia". ACM Transactions on Information Systems . 26 (3): 1. doi :10.1145/1361684.1361686. hdl : 10397/10130 . S2CID 18303048.
Enlaces externos y lecturas recomendadas
Gensim es una biblioteca de Python para modelado de espacios vectoriales e incluye ponderación tf–idf.
Anatomía de un motor de búsqueda
tf–idf y definiciones relacionadas tal como se utilizan en Lucene
Generador de texto a matriz (TMG) Caja de herramientas de MATLAB que se puede utilizar para diversas tareas en minería de texto (TM), específicamente i) indexación, ii) recuperación, iii) reducción de dimensionalidad, iv) agrupamiento, v) clasificación. El paso de indexación ofrece al usuario la capacidad de aplicar métodos de ponderación locales y globales, incluidos tf–idf.
Explicación de la frecuencia de términos Explicación de la frecuencia de términos