Un filtro Bloom es una estructura de datos probabilística que ahorra espacio , concebida por Burton Howard Bloom en 1970, que se utiliza para comprobar si un elemento es miembro de un conjunto . Es posible que se produzcan coincidencias de falsos positivos , pero no de falsos negativos ; en otras palabras, una consulta devuelve "posiblemente en el conjunto" o "definitivamente no en el conjunto". Se pueden añadir elementos al conjunto, pero no eliminarlos (aunque esto se puede solucionar con la variante de filtro Bloom de conteo); cuantos más elementos se añadan, mayor será la probabilidad de que se produzcan falsos positivos.
Bloom propuso la técnica para aplicaciones en las que la cantidad de datos de origen requeriría una cantidad de memoria imprácticamente grande si se aplicaran técnicas de hash sin errores "convencionales". Dio el ejemplo de un algoritmo de separación de palabras para un diccionario de 500.000 palabras, de las cuales el 90% sigue reglas de separación de palabras simples, pero el 10% restante requiere costosos accesos al disco para recuperar patrones de separación de palabras específicos. Con suficiente memoria central , se podría utilizar un hash sin errores para eliminar todos los accesos innecesarios al disco; por otro lado, con una memoria central limitada, la técnica de Bloom utiliza un área de hash más pequeña pero aún así elimina la mayoría de los accesos innecesarios. Por ejemplo, un área de hash de solo el 18% del tamaño necesario para un hash sin errores ideal aún elimina el 87% de los accesos al disco. [1]
De manera más general, se requieren menos de 10 bits por elemento para una probabilidad de falso positivo del 1%, independientemente del tamaño o la cantidad de elementos del conjunto. [2]
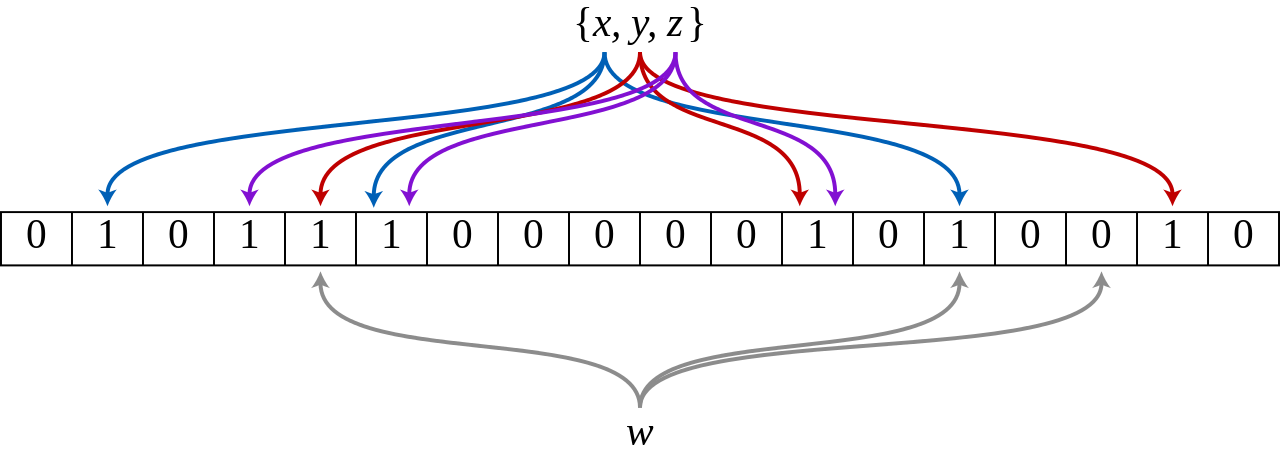
Un filtro Bloom vacío es una matriz de bits de m bits, todos configurados a 0. Está equipado con k funciones hash diferentes , que asignan elementos del conjunto a una de las m posiciones posibles de la matriz. Para que sean óptimas, las funciones hash deben estar distribuidas uniformemente y ser independientes . Normalmente, k es una constante pequeña que depende de la tasa de errores falsos deseada ε , mientras que m es proporcional a k y al número de elementos que se van a agregar.
Para agregar un elemento, introdúzcalo en cada una de las k funciones hash para obtener k posiciones de la matriz. Establezca los bits en todas estas posiciones en 1.
Para comprobar si un elemento está en el conjunto, introdúzcalo en cada una de las k funciones hash para obtener k posiciones de la matriz. Si alguno de los bits en estas posiciones es 0, el elemento definitivamente no está en el conjunto; si lo estuviera, entonces todos los bits se habrían establecido en 1 cuando se insertó. Si todos son 1, entonces el elemento está en el conjunto o los bits se han establecido por casualidad en 1 durante la inserción de otros elementos, lo que da como resultado un falso positivo . En un filtro Bloom simple, no hay forma de distinguir entre los dos casos, pero técnicas más avanzadas pueden abordar este problema.
El requisito de diseñar k funciones hash independientes diferentes puede ser prohibitivo para valores k grandes . Para una buena función hash con una salida amplia, debería haber poca o ninguna correlación entre los diferentes campos de bits de dicho hash, por lo que este tipo de hash se puede utilizar para generar múltiples funciones hash "diferentes" al dividir su salida en múltiples campos de bits. Alternativamente, se pueden pasar k valores iniciales diferentes (como 0, 1, ..., k − 1) a una función hash que toma un valor inicial; o agregar (o anexar) estos valores a la clave. Para valores m y/o k mayores , la independencia entre las funciones hash se puede relajar con un aumento insignificante en la tasa de falsos positivos. [3] (Específicamente, Dillinger y Manolios (2004b) muestran la efectividad de derivar los índices k utilizando hash doble mejorado y hash triple , variantes de hash doble que son efectivamente generadores de números aleatorios simples sembrados con los dos o tres valores hash).
Eliminar un elemento de este filtro Bloom simple es imposible porque no hay forma de saber cuál de los k bits a los que se asigna debe borrarse. Aunque establecer cualquiera de esos k bits en cero es suficiente para eliminar el elemento, también eliminaría cualquier otro elemento que se asigne a ese bit. Dado que el algoritmo simple no proporciona ninguna forma de determinar si se han agregado otros elementos que afecten a los bits del elemento que se eliminará, borrar cualquiera de los bits introduciría la posibilidad de falsos negativos.
La eliminación única de un elemento de un filtro Bloom se puede simular con un segundo filtro Bloom que contenga elementos que se han eliminado. Sin embargo, los falsos positivos en el segundo filtro se convierten en falsos negativos en el filtro compuesto, lo que puede resultar indeseable. Con este enfoque, no es posible volver a agregar un elemento eliminado previamente, ya que habría que quitarlo del filtro "eliminado".
Suele suceder que todas las claves están disponibles, pero enumerarlas resulta costoso (por ejemplo, porque requieren muchas lecturas del disco). Cuando la tasa de falsos positivos es demasiado alta, se puede regenerar el filtro; este debería ser un evento relativamente poco frecuente.

Si bien corren el riesgo de falsos positivos, los filtros Bloom tienen una ventaja sustancial de espacio sobre otras estructuras de datos para representar conjuntos, como árboles de búsqueda binarios autoequilibrados , tries , tablas hash o matrices simples o listas enlazadas de las entradas. La mayoría de estos requieren almacenar al menos los elementos de datos en sí, lo que puede requerir desde una pequeña cantidad de bits, para números enteros pequeños, hasta una cantidad arbitraria de bits, como para cadenas ( los tries son una excepción ya que pueden compartir almacenamiento entre elementos con prefijos iguales). Sin embargo, los filtros Bloom no almacenan los elementos de datos en absoluto, y se debe proporcionar una solución separada para el almacenamiento real. Las estructuras enlazadas incurren en una sobrecarga de espacio lineal adicional para los punteros. Un filtro Bloom con un error del 1% y un valor óptimo de k , en contraste, requiere solo alrededor de 9,6 bits por elemento, independientemente del tamaño de los elementos. Esta ventaja proviene en parte de su compacidad, heredada de las matrices, y en parte de su naturaleza probabilística. La tasa de falsos positivos del 1% se puede reducir en un factor de diez añadiendo sólo unos 4,8 bits por elemento.
Sin embargo, si el número de valores potenciales es pequeño y muchos de ellos pueden estar en el conjunto, el filtro Bloom es superado fácilmente por la matriz de bits determinista , que requiere solo un bit para cada elemento potencial. Las tablas hash obtienen una ventaja de espacio y tiempo si comienzan a ignorar las colisiones y almacenan solo si cada contenedor contiene una entrada; en este caso, se han convertido efectivamente en filtros Bloom con k = 1. [ 4]
Los filtros Bloom también tienen la propiedad inusual de que el tiempo necesario para agregar elementos o para verificar si un elemento está en el conjunto es una constante fija, O( k ) , completamente independiente de la cantidad de elementos que ya están en el conjunto. Ninguna otra estructura de datos de conjuntos de espacio constante tiene esta propiedad, pero el tiempo de acceso promedio de las tablas hash dispersas puede hacer que, en la práctica, sean más rápidas que algunos filtros Bloom. Sin embargo, en una implementación de hardware, el filtro Bloom se destaca porque sus k búsquedas son independientes y se pueden paralelizar.
Para entender su eficiencia espacial, es instructivo comparar el filtro Bloom general con su caso especial cuando k = 1. Si k = 1 , entonces para mantener la tasa de falsos positivos suficientemente baja, se debe establecer una pequeña fracción de bits, lo que significa que la matriz debe ser muy grande y contener largas series de ceros. El contenido de información de la matriz en relación con su tamaño es bajo. El filtro Bloom generalizado ( k mayor que 1) permite establecer muchos más bits mientras se mantiene una baja tasa de falsos positivos; si los parámetros ( k y m ) se eligen bien, aproximadamente la mitad de los bits se establecerán, [5] y estos serán aparentemente aleatorios, minimizando la redundancia y maximizando el contenido de información.

Supongamos que una función hash selecciona cada posición de la matriz con la misma probabilidad. Si m es el número de bits de la matriz, la probabilidad de que una determinada función hash no establezca en 1 un determinado bit durante la inserción de un elemento es
Si k es el número de funciones hash y cada una no tiene correlación significativa entre sí, entonces la probabilidad de que el bit no esté establecido en 1 por ninguna de las funciones hash es
Podemos utilizar la identidad conocida para e −1
para concluir que, para m grande ,
Si hemos insertado n elementos, la probabilidad de que un determinado bit siga siendo 0 es
La probabilidad de que sea 1 es por lo tanto
Ahora, se prueba la pertenencia de un elemento que no está en el conjunto. Cada una de las k posiciones de la matriz calculadas por las funciones hash es 1 con una probabilidad como la indicada anteriormente. La probabilidad de que todas sean 1, lo que haría que el algoritmo afirmara erróneamente que el elemento está en el conjunto, se suele expresar como
Esto no es estrictamente correcto, ya que supone independencia de las probabilidades de que se establezca cada bit. Sin embargo, suponiendo que es una aproximación cercana, tenemos que la probabilidad de falsos positivos disminuye a medida que aumenta m (la cantidad de bits en la matriz) y aumenta a medida que aumenta n (la cantidad de elementos insertados).
La probabilidad real de un falso positivo, sin asumir independencia, es
donde las llaves denotan números de Stirling del segundo tipo . [6]
Mitzenmacher y Upfal ofrecen un análisis alternativo que llega a la misma aproximación sin el supuesto de independencia. [7] Después de que se hayan añadido todos los n elementos al filtro Bloom, sea q la fracción de los m bits que están fijados a 0. (Es decir, el número de bits que todavía están fijados a 0 es qm ). Entonces, al probar la pertenencia de un elemento que no está en el conjunto, para la posición de la matriz dada por cualquiera de las k funciones hash, la probabilidad de que el bit se encuentre fijado a 1 es . Por lo tanto, la probabilidad de que todas las k funciones hash encuentren su bit fijado a 1 es . Además, el valor esperado de q es la probabilidad de que una posición de matriz dada no sea tocada por cada una de las k funciones hash para cada uno de los n elementos, que es (como arriba)
Es posible demostrar, sin el supuesto de independencia, que q está muy fuertemente concentrado alrededor de su valor esperado. En particular, a partir de la desigualdad de Azuma-Hoeffding , demuestran que [8]
Por esto, podemos decir que la probabilidad exacta de falsos positivos es
Como antes.
El número de funciones hash, k , debe ser un entero positivo. Dejando de lado esta restricción, para un m y n dados , el valor de k que minimiza la probabilidad de falsos positivos es
La cantidad requerida de bits, m , dada n (la cantidad de elementos insertados) y una probabilidad de falso positivo deseada ε (y asumiendo que se utiliza el valor óptimo de k ), se puede calcular sustituyendo el valor óptimo de k en la expresión de probabilidad anterior:
Lo cual se puede simplificar así:
Esto da como resultado:
Por lo tanto, el número óptimo de bits por elemento es
con el número correspondiente de funciones hash k (ignorando la integralidad):
Esto significa que para una probabilidad de falso positivo dada ε , la longitud de un filtro Bloom m es proporcional al número de elementos que se filtran n y el número requerido de funciones hash solo depende de la probabilidad de falso positivo objetivo ε . [9]
La fórmula es aproximada por tres razones. En primer lugar, y la menos preocupante, se aproxima como , que es una buena aproximación asintótica (es decir, que se cumple cuando m →∞). En segundo lugar, y la más preocupante, supone que durante la prueba de pertenencia el evento de que un bit probado se establezca en 1 es independiente del evento de que cualquier otro bit probado se establezca en 1. En tercer lugar, y la más preocupante, supone que es fortuitamente integral.
Sin embargo, Goel y Gupta [10] dan un límite superior riguroso que no hace aproximaciones ni requiere suposiciones. Muestran que la probabilidad de falsos positivos para un filtro Bloom finito con m bits ( ), n elementos y k funciones hash es como máximo
Este límite se puede interpretar como que la fórmula aproximada se puede aplicar con una penalización de, como máximo, medio elemento adicional y, como máximo, un bit menos.
La cantidad de elementos en un filtro Bloom se puede aproximar con la siguiente fórmula:
donde es una estimación del número de elementos en el filtro, m es la longitud (tamaño) del filtro, k es el número de funciones hash y X es el número de bits establecidos en uno. [11]
Los filtros Bloom son una forma de representar de forma compacta un conjunto de elementos. Es habitual intentar calcular el tamaño de la intersección o unión entre dos conjuntos. Los filtros Bloom se pueden utilizar para aproximar el tamaño de la intersección y la unión de dos conjuntos. Para dos filtros Bloom de longitud m , sus recuentos, respectivamente, se pueden estimar como
y
El tamaño de su unión se puede estimar como
donde es el número de bits establecido en uno en cualquiera de los dos filtros Bloom. Finalmente, la intersección se puede estimar como
utilizando las tres fórmulas juntas. [11]
Los filtros Bloom clásicos utilizan bits de espacio por cada clave insertada, donde es la tasa de falsos positivos del filtro Bloom. Sin embargo, el espacio que es estrictamente necesario para cualquier estructura de datos que desempeñe el mismo papel que un filtro Bloom es solo por clave. [26] Por lo tanto, los filtros Bloom utilizan un 44% más de espacio que una estructura de datos óptima equivalente.
Pagh et al. proporcionan una estructura de datos que utiliza bits mientras admite operaciones de tiempo esperado amortizado constante. [27] Su estructura de datos es principalmente teórica, pero está estrechamente relacionada con el filtro de cociente ampliamente utilizado , que se puede parametrizar para usar bits de espacio, para un parámetro arbitrario , mientras admite operaciones de tiempo constante. [28] Las ventajas del filtro de cociente, en comparación con el filtro Bloom, incluyen su localidad de referencia y la capacidad de admitir eliminaciones.
Otra alternativa al filtro Bloom clásico es el filtro cuco , basado en variantes de hash cuco que ahorran espacio . En este caso, se construye una tabla hash que no contiene claves ni valores, sino huellas digitales cortas (hashes pequeños) de las claves. Si al buscar la clave se encuentra una huella digital coincidente, entonces es probable que la clave esté en el conjunto. Los filtros cuco admiten eliminaciones y tienen una mejor localidad de referencia que los filtros Bloom. [29] Además, en algunos regímenes de parámetros, los filtros cuco se pueden parametrizar para ofrecer garantías de espacio casi óptimas. [29]
Muchas alternativas a los filtros Bloom, incluidos los filtros de cociente y los filtros de cuco , se basan en la idea de convertir las claves en huellas dactilares aleatorias de 128 bits y luego almacenar esas huellas dactilares en una tabla hash compacta. Esta técnica, que fue introducida por primera vez por Carter et al. en 1978, [26] se basa en el hecho de que las tablas hash compactas se pueden implementar para utilizar aproximadamente bits menos de espacio que sus contrapartes no compactas. Usando tablas hash sucintas , el uso del espacio se puede reducir a tan solo bits [30] mientras se admiten operaciones de tiempo constante en una amplia variedad de regímenes de parámetros.
Putze, Sanders y Singler (2007) han estudiado algunas variantes de los filtros Bloom que son más rápidas o utilizan menos espacio que los filtros Bloom clásicos. La idea básica de la variante rápida es ubicar los k valores hash asociados con cada clave en uno o dos bloques que tengan el mismo tamaño que los bloques de caché de memoria del procesador (generalmente 64 bytes). Esto presumiblemente mejorará el rendimiento al reducir la cantidad de posibles errores de caché de memoria . Sin embargo, las variantes propuestas tienen el inconveniente de utilizar aproximadamente un 32% más de espacio que los filtros Bloom clásicos.
La variante que ahorra espacio se basa en el uso de una única función hash que genera para cada clave un valor en el rango donde es la tasa de falsos positivos solicitada. A continuación, la secuencia de valores se ordena y se comprime utilizando la codificación Golomb (o alguna otra técnica de compresión) para ocupar un espacio cercano a los bits. Para consultar el filtro Bloom para una clave determinada, bastará con comprobar si su valor correspondiente está almacenado en el filtro Bloom. Descomprimir todo el filtro Bloom para cada consulta haría que esta variante fuera totalmente inutilizable. Para superar este problema, la secuencia de valores se divide en pequeños bloques de igual tamaño que se comprimen por separado. En el momento de la consulta, solo será necesario descomprimir medio bloque en promedio. Debido a la sobrecarga de descompresión, esta variante puede ser más lenta que los filtros Bloom clásicos, pero esto puede compensarse con el hecho de que es necesario calcular una única función hash.
Graf y Lemire (2020) describen un enfoque llamado filtro xor, en el que almacenan huellas dactilares en un tipo particular de tabla hash perfecta , lo que produce un filtro que es más eficiente en el uso de la memoria ( bits por clave) y más rápido que los filtros Bloom o Cuckoo. (El ahorro de tiempo proviene del hecho de que una búsqueda requiere exactamente tres accesos a la memoria, que pueden ejecutarse todos en paralelo). Sin embargo, la creación de filtros es más compleja que los filtros Bloom y Cuckoo, y no es posible modificar el conjunto después de la creación.
Existen más de 60 variantes de filtros Bloom, muchas encuestas sobre el campo y una continua rotación de aplicaciones (ver, por ejemplo, Luo, et al [31] ). Algunas de las variantes difieren lo suficiente de la propuesta original como para ser brechas o bifurcaciones de la estructura de datos original y su filosofía. [31] Aún queda por hacer un tratamiento que unifique los filtros Bloom con otros trabajos sobre proyecciones aleatorias , detección compresiva y hash sensible a la localidad (aunque ver Dasgupta, et al [32] para un intento inspirado en la neurociencia).

Las redes de distribución de contenido implementan cachés web en todo el mundo para almacenar en caché y ofrecer contenido web a los usuarios con mayor rendimiento y confiabilidad. Una aplicación clave de los filtros Bloom es su uso para determinar de manera eficiente qué objetos web almacenar en estos cachés web. Casi tres cuartas partes de las URL a las que se accede desde un caché web típico son "one-hit-wonders" a las que los usuarios acceden solo una vez y nunca más. Es claramente un desperdicio de recursos de disco almacenar one-hit-wonders en un caché web, ya que nunca se volverá a acceder a ellos. Para evitar el almacenamiento en caché de one-hit-wonders, se utiliza un filtro Bloom para realizar un seguimiento de todas las URL a las que acceden los usuarios. Un objeto web se almacena en caché solo cuando se ha accedido a él al menos una vez antes, es decir, el objeto se almacena en caché en su segunda solicitud. El uso de un filtro Bloom de esta manera reduce significativamente la carga de trabajo de escritura en disco, ya que la mayoría de los one-hit-wonders no se escriben en el caché de disco. Además, filtrar los one-hit-wonders también ahorra espacio de caché en el disco, lo que aumenta las tasas de aciertos de caché. [13]
Kiss et al [33] describieron una nueva construcción para el filtro Bloom que evita los falsos positivos además de la típica inexistencia de falsos negativos. La construcción se aplica a un universo finito del que se toman los elementos del conjunto. Se basa en el esquema de prueba de grupos combinatorios no adaptativos existente de Eppstein, Goodrich y Hirschberg. A diferencia del filtro Bloom típico, los elementos se convierten en una matriz de bits mediante funciones deterministas, rápidas y fáciles de calcular. El tamaño máximo del conjunto para el que se evitan por completo los falsos positivos es una función del tamaño del universo y está controlado por la cantidad de memoria asignada.
Como alternativa, se puede construir un filtro Bloom inicial de la forma estándar y luego, con un dominio finito y enumerable de forma manejable, se pueden encontrar exhaustivamente todos los falsos positivos y luego construir un segundo filtro Bloom a partir de esa lista; los falsos positivos en el segundo filtro se manejan de manera similar construyendo un tercero, y así sucesivamente. Como el universo es finito y el conjunto de falsos positivos se reduce estrictamente con cada paso, este procedimiento da como resultado una cascada finita de filtros Bloom que (en este dominio finito y cerrado) producirán solo verdaderos positivos y verdaderos negativos. Para verificar la membresía en la cascada de filtros, se consulta el filtro inicial y, si el resultado es positivo, se consulta el segundo filtro, y así sucesivamente. Esta construcción se utiliza en CRLite , un mecanismo de distribución de estado de revocación de certificados propuesto para la PKI web, y se explota la Transparencia de certificados para cerrar el conjunto de certificados existentes. [34]
Los filtros de conteo proporcionan una forma de implementar una operación de eliminación en un filtro Bloom sin tener que volver a crear el filtro. En un filtro de conteo, las posiciones de la matriz (cubetas) se extienden de ser un solo bit a ser un contador de varios bits. De hecho, los filtros Bloom regulares pueden considerarse filtros de conteo con un tamaño de cubeta de un bit. Los filtros de conteo fueron introducidos por Fan et al. (2000).
La operación de inserción se extiende para incrementar el valor de los contenedores, y la operación de búsqueda verifica que cada uno de los contenedores requeridos sea distinto de cero. La operación de eliminación consiste entonces en disminuir el valor de cada uno de los contenedores respectivos.
El desbordamiento aritmético de los contenedores es un problema y los contenedores deben ser lo suficientemente grandes para que este caso sea poco frecuente. Si ocurre, las operaciones de incremento y decremento deben dejar el contenedor configurado en el valor máximo posible para conservar las propiedades de un filtro Bloom.
El tamaño de los contadores suele ser de 3 o 4 bits. Por lo tanto, los filtros Bloom de conteo utilizan de 3 a 4 veces más espacio que los filtros Bloom estáticos. Por el contrario, las estructuras de datos de Pagh, Pagh y Rao (2005) y Fan et al. (2014) también permiten eliminaciones, pero utilizan menos espacio que un filtro Bloom estático.
Otro problema con los filtros de conteo es la escalabilidad limitada. Debido a que la tabla de filtros Bloom de conteo no se puede expandir, se debe conocer de antemano la cantidad máxima de claves que se almacenarán simultáneamente en el filtro. Una vez que se excede la capacidad diseñada de la tabla, la tasa de falsos positivos aumentará rápidamente a medida que se inserten más claves.
Bonomi et al. (2006) introdujeron una estructura de datos basada en el hash d-left que es funcionalmente equivalente pero que utiliza aproximadamente la mitad de espacio que los filtros Bloom de conteo. El problema de escalabilidad no se produce en esta estructura de datos. Una vez que se excede la capacidad diseñada, las claves se pueden volver a insertar en una nueva tabla hash de tamaño doble.
La variante de uso eficiente del espacio de Putze, Sanders y Singler (2007) también podría usarse para implementar filtros de conteo al admitir inserciones y eliminaciones.
Rottenstreich, Kanizo y Keslassy (2012) introdujeron un nuevo método general basado en incrementos de variables que mejora significativamente la probabilidad de falsos positivos de contar filtros Bloom y sus variantes, al mismo tiempo que admite eliminaciones. A diferencia de contar filtros Bloom, en cada inserción de elementos, los contadores hash se incrementan mediante un incremento de variable hash en lugar de un incremento unitario. Para consultar un elemento, se consideran los valores exactos de los contadores y no solo su positividad. Si una suma representada por un valor de contador no puede estar compuesta por el incremento de variable correspondiente para el elemento consultado, se puede devolver una respuesta negativa a la consulta.
Kim et al. (2019) muestra que el falso positivo del filtro Bloom de conteo disminuye desde k = 1 hasta un punto definido , y aumenta desde hasta el infinito positivo, y encuentra una función del umbral de conteo. [35]
Los filtros Bloom se pueden organizar en estructuras de datos distribuidas para realizar cálculos totalmente descentralizados de funciones agregadas . La agregación descentralizada hace que las mediciones colectivas estén disponibles localmente en cada nodo de una red distribuida sin involucrar a una entidad computacional centralizada para este propósito. [36]
Los filtros Bloom paralelos se pueden implementar para aprovechar los múltiples elementos de procesamiento (PE) presentes en las máquinas paralelas sin uso compartido . Uno de los principales obstáculos para un filtro Bloom paralelo es la organización y comunicación de los datos no ordenados que, en general, se distribuyen de manera uniforme entre todos los PE en el inicio o en las inserciones por lotes. Para ordenar los datos se pueden utilizar dos enfoques, ya sea dando como resultado un filtro Bloom sobre todos los datos almacenados en cada PE, llamado filtro Bloom replicante, o el filtro Bloom sobre todos los datos divididos en partes iguales, cada PE almacena una parte de ellos. [37] Para ambos enfoques se utiliza un filtro Bloom de "disparo único" que solo calcula un hash, lo que da como resultado un bit invertido por elemento, para reducir el volumen de comunicación.
Los filtros Bloom distribuidos se inician primero aplicando un hash a todos los elementos en su PE local y luego ordenándolos por sus hashes localmente. Esto se puede hacer en tiempo lineal usando, por ejemplo, la ordenación por cubos y también permite la detección de duplicados locales. La ordenación se usa para agrupar los hashes con su PE asignado como separador para crear un filtro Bloom para cada grupo. Después de codificar estos filtros Bloom usando, por ejemplo, la codificación Golomb, cada filtro Bloom se envía como paquete al PE responsable de los valores hash que se insertaron en él. Un PE p es responsable de todos los hashes entre los valores y , donde s es el tamaño total del filtro Bloom sobre todos los datos. Debido a que cada elemento solo se aplica un hash una vez y, por lo tanto, solo se establece un solo bit, para verificar si un elemento se insertó en el filtro Bloom, solo se necesita operar en el PE responsable del valor hash del elemento. Las operaciones de inserción única también se pueden realizar de manera eficiente porque solo se debe cambiar el filtro Bloom de un PE, en comparación con la replicación de filtros Bloom donde cada PE tendría que actualizar su filtro Bloom. Al distribuir el filtro Bloom global entre todos los PE en lugar de almacenarlo por separado en cada PE, el tamaño de los filtros Bloom puede ser mucho mayor, lo que da como resultado una mayor capacidad y una menor tasa de falsos positivos.
Los filtros Bloom distribuidos se pueden utilizar para mejorar los algoritmos de detección de duplicados [38] filtrando los elementos más "únicos". Estos se pueden calcular comunicando solo los hashes de los elementos, no los elementos en sí mismos, que son mucho más grandes en volumen, y eliminándolos del conjunto, lo que reduce la carga de trabajo para el algoritmo de detección de duplicados utilizado posteriormente.
Durante la comunicación de los hashes, los PE buscan bits que estén configurados en más de uno de los paquetes de recepción, ya que esto significaría que dos elementos tenían el mismo hash y, por lo tanto, podrían ser duplicados. Si esto ocurre, se envía un mensaje que contiene el índice del bit, que también es el hash del elemento que podría ser un duplicado, a los PE que enviaron un paquete con el bit configurado. Si un remitente envía múltiples índices al mismo PE, puede ser ventajoso codificar también los índices. Ahora se garantiza que todos los elementos cuyo hash no se envió de vuelta no serán duplicados y no se evaluarán más; para los elementos restantes se puede utilizar un algoritmo de repartición [39] . Primero, todos los elementos cuyo valor hash se envió de vuelta se envían al PE del que es responsable su hash. Ahora se garantiza que cualquier elemento y su duplicado están en el mismo PE. En el segundo paso, cada PE utiliza un algoritmo secuencial para la detección de duplicados en los elementos receptores, que son solo una fracción de la cantidad de elementos iniciales. Al permitir una tasa de falsos positivos para los duplicados, el volumen de comunicación se puede reducir aún más, ya que los PE no tienen que enviar elementos con hashes duplicados y, en cambio, cualquier elemento con un hash duplicado puede marcarse simplemente como duplicado. Como resultado, la tasa de falsos positivos para la detección de duplicados es la misma que la tasa de falsos positivos del filtro Bloom utilizado.
El proceso de filtrado de los elementos más "únicos" también se puede repetir varias veces modificando la función hash en cada paso de filtrado. Si se utiliza un solo paso de filtrado, se debe generar una pequeña tasa de falsos positivos; sin embargo, si el paso de filtrado se repite una vez, el primer paso puede permitir una tasa de falsos positivos más alta, mientras que el segundo tiene una tasa más alta, pero también funciona con menos elementos, ya que muchos ya se han eliminado en el paso de filtrado anterior. Si bien el uso de más de dos repeticiones puede reducir aún más el volumen de comunicación si la cantidad de duplicados en un conjunto es pequeña, la recompensa por las complicaciones adicionales es baja.
Los filtros Bloom replicantes organizan sus datos utilizando un algoritmo de hipercubo bien conocido para chismear, p. ej. [40] Primero, cada PE calcula el filtro Bloom sobre todos los elementos locales y lo almacena. Al repetir un bucle donde en cada paso i los PE envían su filtro Bloom local sobre la dimensión i y fusionan el filtro Bloom que reciben sobre la dimensión con su filtro Bloom local, es posible duplicar los elementos que contiene cada filtro Bloom en cada iteración. Después de enviar y recibir filtros Bloom sobre todas las dimensiones, cada PE contiene el filtro Bloom global sobre todos los elementos.
Los filtros Bloom replicados son más eficientes cuando el número de consultas es mucho mayor que el número de elementos que contiene el filtro Bloom, el punto de equilibrio en comparación con los filtros Bloom distribuidos es aproximadamente después de los accesos, siendo la tasa de falsos positivos del filtro Bloom.
Los filtros Bloom se pueden utilizar para la sincronización aproximada de datos, como en Byers et al. (2004). Los filtros Bloom de conteo se pueden utilizar para aproximar la cantidad de diferencias entre dos conjuntos; este enfoque se describe en Agarwal y Trachtenberg (2006).
Los filtros Bloom pueden adaptarse al contexto de transmisión de datos. Por ejemplo, Deng y Rafiei (2006) propusieron filtros Bloom estables, que consisten en un filtro Bloom de conteo donde la inserción de un nuevo elemento establece los contadores asociados en un valor c , y luego solo una cantidad fija s de contadores se reduce en 1, por lo tanto, la memoria contiene principalmente información sobre elementos recientes (intuitivamente, se podría suponer que la vida útil de un elemento dentro de un SBF de N contadores es de alrededor de ). Otra solución es el filtro Bloom de envejecimiento, que consta de dos filtros Bloom, cada uno de los cuales ocupa la mitad de la memoria total disponible: cuando un filtro está lleno, el segundo filtro se borra y luego se agregan elementos más nuevos a este filtro recién vacío. [41]
Sin embargo, se ha demostrado [42] que sin importar el filtro, después de n inserciones, la suma de las probabilidades de falsos positivos y falsos negativos está limitada por debajo de donde L es la cantidad de todos los elementos posibles (el tamaño del alfabeto), m el tamaño de la memoria (en bits), asumiendo . Este resultado muestra que para L suficientemente grande y n yendo al infinito, entonces el límite inferior converge a , que es la relación característica de un filtro aleatorio. Por lo tanto, después de suficientes inserciones, y si el alfabeto es demasiado grande para ser almacenado en la memoria (lo que se asume en el contexto de filtros probabilísticos), es imposible que un filtro funcione mejor que la aleatoriedad. Este resultado se puede aprovechar esperando solo que un filtro funcione en una ventana deslizante en lugar de en todo el flujo. En este caso, el exponente n en la fórmula anterior se reemplaza por w , lo que da una fórmula que podría desviarse de 1, si w no es demasiado pequeño.
Chazelle et al. (2004) diseñaron una generalización de los filtros Bloom que podían asociar un valor a cada elemento que se hubiera insertado, implementando un array asociativo . Al igual que los filtros Bloom, estas estructuras logran una pequeña sobrecarga de espacio al aceptar una pequeña probabilidad de falsos positivos. En el caso de los "filtros Bloomer", un falso positivo se define como devolver un resultado cuando la clave no está en el mapa. El mapa nunca devolverá el valor incorrecto para una clave que esté en el mapa.
Boldi y Vigna (2005) propusieron una generalización de los filtros Bloom basada en retículas . Un aproximador compacto asocia a cada clave un elemento de una retícula (los filtros Bloom estándar son el caso de la retícula booleana de dos elementos). En lugar de una matriz de bits, tienen una matriz de elementos de la retícula. Al agregar una nueva asociación entre una clave y un elemento de la retícula, calculan el máximo de los contenidos actuales de las k ubicaciones de la matriz asociadas a la clave con el elemento de la retícula. Al leer el valor asociado a una clave, calculan el mínimo de los valores encontrados en las k ubicaciones asociadas a la clave. El valor resultante se aproxima desde arriba al valor original.
Esta implementación utilizó una matriz separada para cada función hash. Este método permite realizar cálculos hash paralelos tanto para inserciones como para consultas. [43]
Almeida et al. (2007) propusieron una variante de los filtros Bloom que pueden adaptarse dinámicamente al número de elementos almacenados, asegurando al mismo tiempo una probabilidad mínima de falsos positivos. La técnica se basa en secuencias de filtros Bloom estándar con capacidad creciente y probabilidades de falsos positivos más ajustadas, de modo que se pueda establecer de antemano una probabilidad máxima de falsos positivos, independientemente del número de elementos a insertar.
Los filtros Spatial Bloom (SBF) fueron propuestos originalmente por Palmieri, Calderoni y Maio (2014) como una estructura de datos diseñada para almacenar información de ubicación , especialmente en el contexto de protocolos criptográficos para privacidad de ubicación . Sin embargo, la característica principal de los SBF es su capacidad para almacenar múltiples conjuntos en una sola estructura de datos, lo que los hace adecuados para varios escenarios de aplicación diferentes. [44] Se puede consultar la pertenencia de un elemento a un conjunto específico, y la probabilidad de falso positivo depende del conjunto: los primeros conjuntos que se ingresan en el filtro durante la construcción tienen mayores probabilidades de falso positivo que los conjuntos ingresados al final. [45] Esta propiedad permite una priorización de los conjuntos, donde se pueden preservar los conjuntos que contienen elementos más "importantes".
Un filtro Bloom en capas consta de varias capas de filtro Bloom. Los filtros Bloom en capas permiten realizar un seguimiento de cuántas veces se agregó un elemento al filtro Bloom al verificar cuántas capas contienen el elemento. Con un filtro Bloom en capas, una operación de verificación normalmente devolverá el número de capa más profunda en la que se encontró el elemento. [46]

Un filtro Bloom atenuado de profundidad D puede verse como una matriz de D filtros Bloom normales. En el contexto del descubrimiento de servicios en una red, cada nodo almacena filtros Bloom regulares y atenuados localmente. El filtro Bloom regular o local indica qué servicios ofrece el propio nodo. El filtro atenuado de nivel i indica qué servicios se pueden encontrar en nodos que están a i-hops de distancia del nodo actual. El valor i-ésimo se construye tomando una unión de filtros Bloom locales para nodos que están a i-hops de distancia del nodo. [47]
Por ejemplo, considere una red pequeña, como se muestra en el gráfico a continuación. Digamos que estamos buscando un servicio A cuyo identificador se convierte en los bits 0, 1 y 3 (patrón 11010). Sea el nodo n1 el punto de partida. Primero, verificamos si el servicio A es ofrecido por n1 verificando su filtro local. Como los patrones no coinciden, verificamos el filtro Bloom atenuado para determinar qué nodo debería ser el siguiente salto. Vemos que n2 no ofrece el servicio A, pero se encuentra en la ruta hacia los nodos que sí lo ofrecen. Por lo tanto, nos movemos a n2 y repetimos el mismo procedimiento. Rápidamente encontramos que n3 ofrece el servicio y, por lo tanto, se encuentra el destino. [48]
Al utilizar filtros Bloom atenuados que constan de múltiples capas, se pueden descubrir servicios a más de un salto de distancia, evitando al mismo tiempo la saturación del filtro Bloom al atenuar (desplazar) los bits establecidos por fuentes más alejadas. [47]
Los filtros Bloom se utilizan a menudo para buscar en bases de datos de estructuras químicas de gran tamaño (consulte similitud química ). En el caso más simple, los elementos añadidos al filtro (llamados huella digital en este campo) son simplemente los números atómicos presentes en la molécula, o un hash basado en el número atómico de cada átomo y el número y tipo de sus enlaces. Este caso es demasiado simple para ser útil. Los filtros más avanzados también codifican recuentos de átomos, características de subestructuras más grandes como grupos carboxilo y propiedades de gráficos como el número de anillos. En huellas digitales basadas en hash, se utiliza una función hash basada en propiedades de átomos y enlaces para convertir un subgrafo en una semilla PRNG , y los primeros valores de salida se utilizan para establecer bits en el filtro Bloom.
Las huellas moleculares comenzaron a usarse a fines de la década de 1940 como una forma de buscar estructuras químicas buscadas en tarjetas perforadas. Sin embargo, no fue hasta alrededor de 1990 que Daylight Chemical Information Systems, Inc. introdujo un método basado en hash para generar los bits, en lugar de utilizar una tabla precalculada. A diferencia del enfoque del diccionario, el método hash puede asignar bits para subestructuras que no se habían visto anteriormente. A principios de la década de 1990, el término "huella" se consideraba diferente de "claves estructurales", pero desde entonces el término ha crecido para abarcar la mayoría de las características moleculares que se pueden usar para una comparación de similitud, incluidas las claves estructurales, las huellas dactilares de recuento disperso y las huellas dactilares 3D. A diferencia de los filtros Bloom, el método hash de Daylight permite que la cantidad de bits asignados por característica sea una función del tamaño de la característica, pero la mayoría de las implementaciones de huellas dactilares similares a Daylight usan una cantidad fija de bits por característica, lo que las convierte en un filtro Bloom. Las huellas dactilares Daylight originales se podían usar tanto para fines de similitud como de cribado. Muchos otros tipos de huellas dactilares, como la popular ECFP2, se pueden utilizar para la similitud, pero no para el cribado, ya que incluyen características ambientales locales que introducen falsos negativos cuando se utilizan como cribado. Incluso si se construyen con el mismo mecanismo, no son filtros Bloom porque no se pueden utilizar para filtrar.
{{cite book}}: CS1 maint: location missing publisher (link)resúmenes de caché se basan en una técnica publicada por primera vez por Pei Cao, llamada caché de resumen. La idea fundamental es utilizar un filtro Bloom para representar el contenido de la caché.










![{\displaystyle \varepsilon =\left(1-\left[1-{\frac {1}{m}}\right]^{kn}\right)^{k}\approx \left(1-e^{-kn/m}\right)^{k}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de73929baec5fd76dde95874189051648c635b1d)



![{\displaystyle E[q]=\left(1-{\frac {1}{m}}\right)^{kn}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c213b5ac119f9c4f695469b512545fc5b49ef8c1)
![{\displaystyle \Pr(\left|qE[q]\right|\geq {\frac {\lambda }{m}})\leq 2\exp(-2\lambda ^{2}/kn)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b63e23e0badb4182e147f75aa18b011421c014dc)
![{\displaystyle \sum_{t}\Pr(q=t)(1-t)^{k}\approx (1-E[q])^{k}=\left(1-\left[1-{\frac {1}{m}}\right]^{kn}\right)^{k}\approx \left(1-e^{-kn/m}\right)^{k}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c6ec47c32d7acc2aef7c673b9f891f26ec425c5f)













![{\displaystyle n^{*}=-{\frac {m}{k}}\ln \left[1-{\frac {X}{m}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/61a0f3398b96f0e26aa0935aba89096dcc22fc5f)

![{\displaystyle n(A^{*})=-{\frac {m}{k}}\ln \left[1-{\frac {|A|}{m}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fd27c870de822d6032469dda4b6eccf4ba4ac9eb)
![{\displaystyle n(B^{*})=-{\frac {m}{k}}\ln \left[1-{\frac {|B|}{m}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dbcc1699bb04b9dcb909cd136210db798526bbf1)
![{\displaystyle n(A^{*}\cup B^{*})=-{\frac {m}{k}}\ln \left[1-{\frac {|A\cup B|}{m}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/af258dc11fd3f7cc5eda98e4a4d8552c3f418e48)












![{\displaystyle \left[0,n/\varepsilon \right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/08fc8018675c0d5ae415f476b94085ff896d18d4)













