En informática , un árbol binario enhebrado es una variante de árbol binario que facilita el recorrido en un orden particular.
Se puede recorrer fácilmente un árbol binario de búsqueda completo siguiendo el orden de la clave principal, pero si se proporciona solo un puntero a un nodo , encontrar el nodo que viene a continuación puede resultar lento o imposible. Por ejemplo, los nodos hoja por definición no tienen descendientes, por lo que si se proporciona solo un puntero a un nodo hoja, no se puede llegar a ningún otro nodo. Un árbol con subprocesos agrega información adicional en algunos o todos los nodos, de modo que para cualquier nodo individual dado, se puede encontrar rápidamente el nodo "próximo", lo que permite recorrer el árbol sin recursión y sin el almacenamiento adicional (proporcional a la profundidad del árbol) que requiere la recursión.
"Un árbol binario se crea haciendo que todos los punteros secundarios derechos que normalmente serían nulos apunten al sucesor en orden del nodo ( si existe), y todos los punteros secundarios izquierdos que normalmente serían nulos apunten al predecesor en orden del nodo". [1]
Esto supone que el orden de recorrido es el mismo que el recorrido en orden del árbol. Sin embargo, se pueden añadir punteros a los nodos del árbol (o además de ellos), en lugar de reemplazarlos. Las listas enlazadas así definidas también se denominan comúnmente "hilos" y se pueden utilizar para permitir el recorrido en cualquier orden que se desee. Por ejemplo, un árbol cuyos nodos representan información sobre personas podría estar ordenado por nombre, pero tener hilos adicionales que permitan un recorrido rápido en orden de fecha de nacimiento, peso o cualquier otra característica conocida.
Los árboles, incluidos (pero no limitados a) los árboles binarios de búsqueda , se pueden utilizar para almacenar elementos en un orden particular, como el valor de alguna propiedad almacenada en cada nodo, a menudo llamada clave . Una operación útil en un árbol de este tipo es el recorrido : visitar todos los elementos en el orden de la clave.
El siguiente es un algoritmo de recorrido recursivo simple que visita cada nodo de un árbol binario de búsqueda . Supongamos que t es un puntero a un nodo o nil . "Visitar" t puede significar realizar cualquier acción en el nodo t o en su contenido.
Algoritmo traverse( t ):
Un problema con este algoritmo es que, debido a su recursión, utiliza un espacio de pila proporcional a la altura de un árbol. Si el árbol está bastante equilibrado, esto equivale a O (log n ) espacio para un árbol que contiene n elementos. En el peor de los casos, cuando el árbol toma la forma de una cadena , la altura del árbol es n , por lo que el algoritmo ocupa O ( n ) espacio. Un segundo problema es que todos los recorridos deben comenzar en la raíz cuando los nodos tienen punteros solo a sus hijos. Es común tener un puntero a un nodo en particular, pero eso no es suficiente para volver al resto del árbol a menos que se agregue información adicional, como punteros de hilo.
Con este enfoque, puede que no sea posible determinar si los punteros izquierdo y/o derecho de un nodo determinado apuntan en realidad a hijos o son consecuencia de la ejecución de subprocesos. Si la distinción es necesaria, basta con agregar un solo bit a cada nodo para registrarla.
En un libro de texto de 1968, Donald Knuth preguntó si existía un algoritmo no recursivo para el recorrido en orden, que no utiliza ninguna pila y deja el árbol sin modificar. [2] Una de las soluciones a este problema es el enhebrado de árboles, presentado por Joseph M. Morris en 1979. [3] [4] En la edición de seguimiento de 1969, [5] Knuth atribuyó la representación del árbol enhebrado a Perlis y Thornton (1960). [6]
Otra forma de lograr objetivos similares es incluir un puntero en cada nodo, al nodo padre de ese nodo. Dado que, siempre se puede llegar al nodo "próximo", los punteros "derechos" siguen siendo nulos siempre que no haya hijos derechos. Para encontrar el nodo "próximo" a partir de un nodo cuyo puntero derecho es nulo, recorra los punteros "padre" hasta llegar a un nodo cuyo puntero derecho no sea nulo y no sea el hijo del que acaba de llegar. Ese nodo es el nodo "próximo", y después de él vienen sus descendientes a la derecha.
También es posible descubrir el padre de un nodo a partir de un árbol binario enhebrado, sin el uso explícito de punteros padre o una pila, aunque es más lento. Para ver esto, considere un nodo k con hijo derecho r . Entonces, el puntero izquierdo de r debe ser un hijo o un hilo de regreso a k . En el caso de que r tenga un hijo izquierdo, ese hijo izquierdo debe tener a su vez un hijo izquierdo propio o un hilo de regreso a k , y así sucesivamente para todos los hijos izquierdos sucesivos. Entonces, al seguir la cadena de punteros izquierdos desde r , eventualmente encontraremos un hilo que apunta de regreso a k . La situación es simétricamente similar cuando q es el hijo izquierdo de p —podemos seguir los hijos derechos de q a un hilo que apunta hacia adelante a p .
En Python :
def padre ( nodo ): si nodo es nodo . árbol . raíz : devuelve Ninguno x = nodo y = nodo mientras Verdadero : si es_hilo ( y ): p = y . derecha si p es Ninguno o p . izquierda no es nodo : p = x mientras no es_hilo ( p . izquierda ): p = p . izquierda p = p . izquierda devuelve p elif es_hilo ( x ): p = x . izquierda si p es Ninguno o p . derecha no es nodo : p = y mientras no es_hilo ( p . derecha ): p = p . derecha p = p . derecha devuelve p x = x . izquierda y = y . derecha Los subprocesos son referencias a los predecesores y sucesores del nodo de acuerdo con un recorrido en orden.
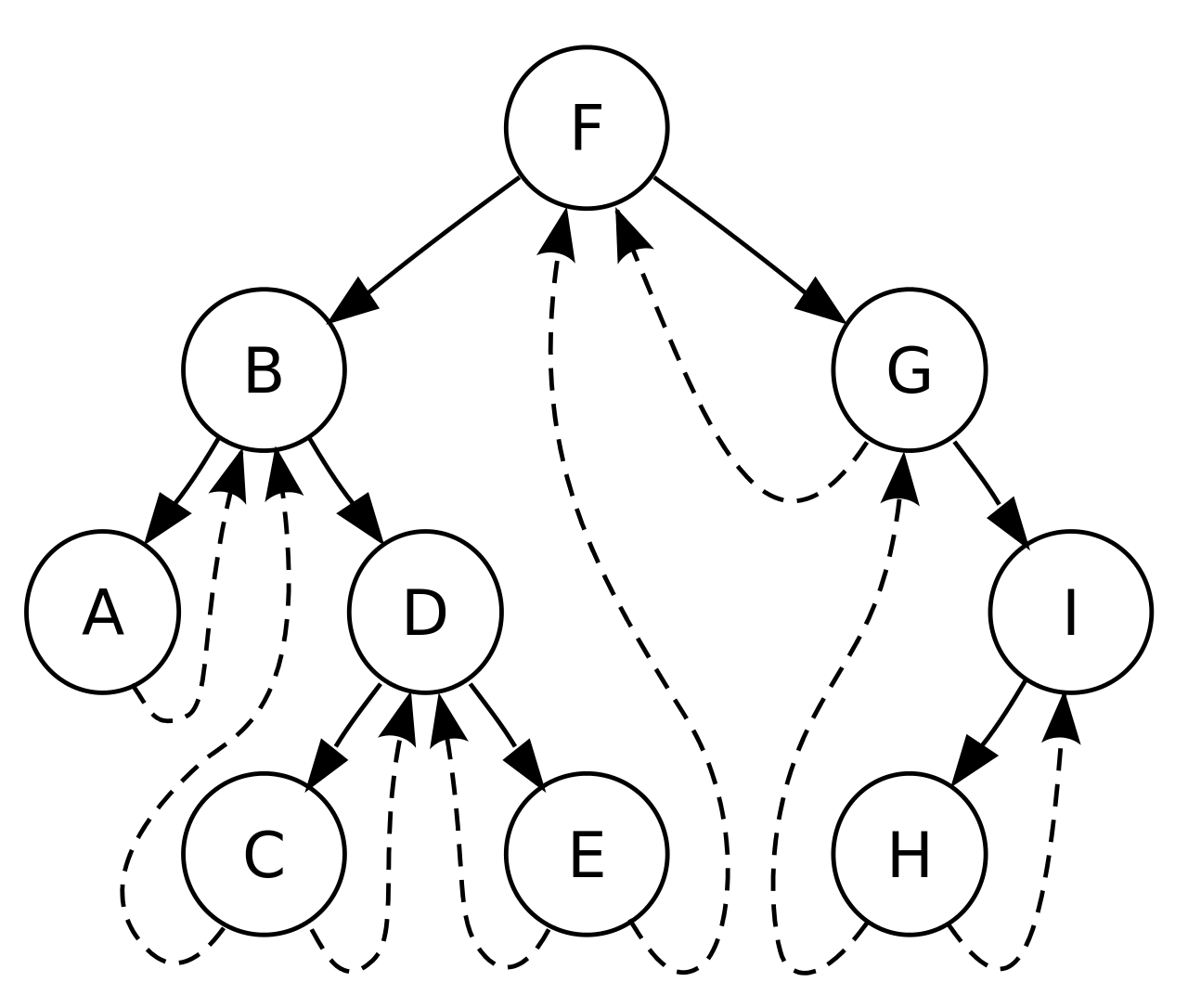
El recorrido en orden del árbol de subprocesos es A,B,C,D,E,F,G,H,I, el predecesor de Ees D, el sucesor de Ees F.
Construyamos el árbol binario enhebrado a partir de un árbol binario normal:
El recorrido en orden para el árbol anterior es — DBAE C. Por lo tanto, el árbol binario enhebrado respectivo será:
En un árbol binario con subprocesos m y n nodos, hay n × m − ( n −1) enlaces vacíos.