Técnica estadística
Un suavizador de kernel es una técnica estadística para estimar una función de valor real como el promedio ponderado de datos observados vecinos. El peso está definido por el kernel , de modo que los puntos más cercanos reciben pesos más altos. La función estimada es suave y el nivel de suavidad se establece mediante un único parámetro. El suavizado de kernel es un tipo de promedio móvil ponderado .
Definiciones
Sea un núcleo definido por
dónde:
- es la norma euclidiana
- es un parámetro (radio del núcleo)
- D ( t ) es típicamente una función de valor real positivo, cuyo valor es decreciente (o no aumenta) a medida que aumenta la distancia entre X y X 0 .
Los núcleos populares utilizados para suavizar incluyen los núcleos parabólicos (Epanechnikov), Tricube y Gaussianos .
Sea una función continua de X . Para cada , el promedio ponderado por kernel de Nadaraya-Watson (estimación suave de Y ( X )) se define por
dónde:
- N es el número de puntos observados
- Y ( X i ) son las observaciones en los puntos X i .
En las siguientes secciones describimos algunos casos particulares de suavizadores de kernel.
Suavizado de núcleo gaussiano
El kernel gaussiano es uno de los kernels más utilizados y se expresa con la siguiente ecuación.
Aquí, b es la escala de longitud para el espacio de entrada.
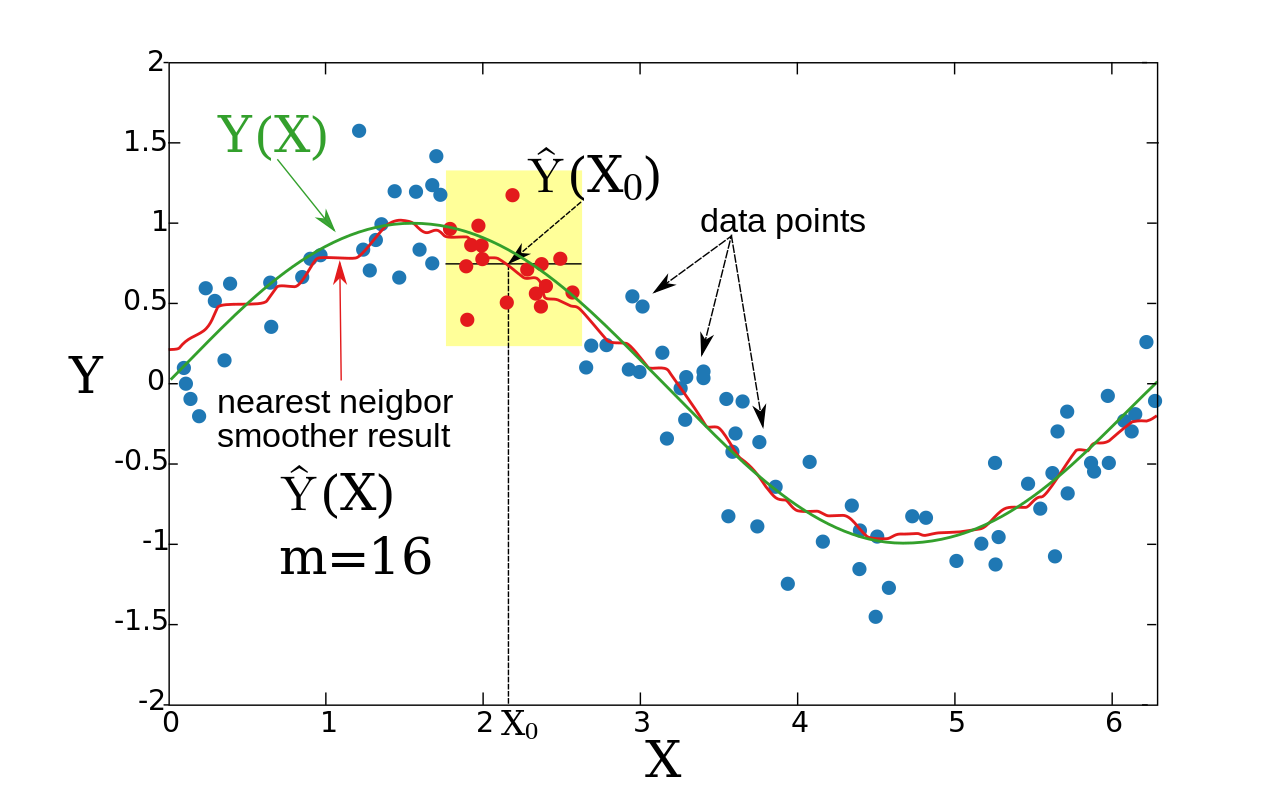
El vecino más cercano es más suave
La idea del suavizador de vecinos más próximos es la siguiente: para cada punto X 0 , tome m vecinos más próximos y estime el valor de Y ( X 0 ) promediando los valores de estos vecinos.
Formalmente, , donde es el m ésimo vecino más cercano a X 0 , y
Ejemplo:
En este ejemplo, X es unidimensional. Para cada X 0 , hay un valor promedio de 16 puntos más cercanos a X 0 (indicados en rojo).
Promedio de kernel más suave
La idea del suavizador de promedios de kernel es la siguiente: para cada punto de datos X 0 , elija un tamaño de distancia constante λ (radio de kernel o ancho de ventana para p = 1 dimensión) y calcule un promedio ponderado para todos los puntos de datos que estén más cerca que X 0 ( los puntos más cercanos a X 0 obtienen pesos más altos).
Formalmente, D ( t ) es uno de los núcleos más populares.
Ejemplo:
Para cada X 0 el ancho de la ventana es constante, y el peso de cada punto en la ventana se denota esquemáticamente por la figura amarilla en el gráfico. Se puede ver que la estimación es suave, pero los puntos límite están sesgados. La razón de esto es la cantidad desigual de puntos (desde la derecha y desde la izquierda hasta X 0 ) en la ventana, cuando X 0 está lo suficientemente cerca del límite.
Regresión lineal local
En las dos secciones anteriores asumimos que la función subyacente Y(X) es localmente constante, por lo tanto pudimos usar el promedio ponderado para la estimación. La idea de la regresión lineal local es ajustar localmente una línea recta (o un hiperplano para dimensiones superiores), y no la constante (línea horizontal). Después de ajustar la línea, la estimación la proporciona el valor de esta línea en el punto X 0 . Al repetir este procedimiento para cada X 0 , se puede obtener la función de estimación . Como en la sección anterior, el ancho de la ventana es constante
Formalmente, la regresión lineal local se calcula resolviendo un problema de mínimos cuadrados ponderados.
Para una dimensión ( p = 1):
La solución en forma cerrada viene dada por:
dónde:
Ejemplo:
La función resultante es suave y se reduce el problema con los puntos límite sesgados.
La regresión lineal local se puede aplicar a cualquier espacio dimensional, aunque la cuestión de qué es una vecindad local se vuelve más complicada. Es común utilizar k puntos de entrenamiento más cercanos a un punto de prueba para ajustar la regresión lineal local. Esto puede generar una alta varianza de la función ajustada. Para limitar la varianza, el conjunto de puntos de entrenamiento debe contener el punto de prueba en su envoltura convexa (consulte la referencia de Gupta et al.).
Regresión polinómica local
En lugar de ajustar funciones localmente lineales, se pueden ajustar funciones polinómicas.
Para p=1, se debe minimizar:
con
En el caso general (p>1), se debe minimizar:
Véase también
Referencias
- Li, Q. y JS Racine. Econometría no paramétrica: teoría y práctica . Princeton University Press, 2007, ISBN 0-691-12161-3 .
- T. Hastie, R. Tibshirani y J. Friedman, The Elements of Statistical Learning , Capítulo 6, Springer, 2001. ISBN 0-387-95284-5 (sitio del libro complementario).
- M. Gupta, E. Garcia y E. Chin, "Regresión lineal local adaptativa con aplicación a la gestión del color de la impresora", IEEE Trans. Image Processing 2008.












![{\displaystyle h_{m}(X_{0})=\left\|X_{0}-X_{[m]}\right\|}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e649a2d186d0ff66a1aa6c00792a3f263293049d)
![Estilo de visualización X_{[m]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c375afa1c3ce963071818546bfa67b2b846585ee)













