Un interframe es un fotograma en un flujo de compresión de vídeo que se expresa en términos de uno o más fotogramas vecinos. La parte "inter" del término se refiere al uso de la predicción entre fotogramas . Este tipo de predicción intenta aprovechar la redundancia temporal entre fotogramas vecinos, lo que permite tasas de compresión más altas.
Un fotograma intercodificado se divide en bloques conocidos como macrobloques . Después de eso, en lugar de codificar directamente los valores de píxeles sin procesar para cada bloque, el codificador intentará encontrar un bloque similar al que está codificando en un fotograma codificado previamente, denominado fotograma de referencia . Este proceso se realiza mediante un algoritmo de coincidencia de bloques . Si el codificador tiene éxito en su búsqueda, el bloque podría codificarse mediante un vector, conocido como vector de movimiento , que apunta a la posición del bloque coincidente en el fotograma de referencia. El proceso de determinación del vector de movimiento se denomina estimación de movimiento .
En la mayoría de los casos, el codificador tendrá éxito, pero es probable que el bloque encontrado no coincida exactamente con el bloque que está codificando. Por este motivo, el codificador calculará las diferencias entre ellos. Esos valores residuales se conocen como error de predicción y deben transformarse y enviarse al decodificador.
En resumen, si el codificador consigue encontrar un bloque coincidente en un fotograma de referencia, obtendrá un vector de movimiento que apunta al bloque coincidente y un error de predicción. Utilizando ambos elementos, el decodificador podrá recuperar los píxeles en bruto del bloque. La siguiente imagen muestra todo el proceso de forma gráfica:

Este tipo de predicción tiene algunas ventajas y desventajas:
Debido a estos inconvenientes, para que esta técnica sea eficaz y útil, se debe utilizar un marco de referencia fiable y periódico en el tiempo. Ese marco de referencia se conoce como intra-marco , que está estrictamente codificado intra, por lo que siempre se puede decodificar sin información adicional.
En la mayoría de los diseños, existen dos tipos de intermarcos: los P-marcos y los B-marcos. Estos dos tipos de marcos y los I-marcos (imágenes intracodificadas) suelen unirse en un GOP (grupo de imágenes). El I-marco no necesita información adicional para ser decodificado y puede utilizarse como una referencia fiable. Esta estructura también permite lograr una periodicidad de I-marcos, necesaria para la sincronización del decodificador.
La diferencia entre los fotogramas P y los fotogramas B es el fotograma de referencia que pueden utilizar.
P-frame es el término utilizado para definir las imágenes predichas hacia adelante. La predicción se realiza a partir de una imagen anterior, principalmente un I-frame o P-frame, por lo que requiere menos datos de codificación (≈50% en comparación con el tamaño del I-frame).
La cantidad de datos necesarios para realizar esta predicción consiste en vectores de movimiento y coeficientes de transformación que describen la corrección de la predicción. Implica el uso de compensación de movimiento .
B-frame es el término que se utiliza para las imágenes predichas bidireccionalmente. Este tipo de método de predicción ocupa menos datos de codificación que los P-frames en general (≈25 % en comparación con el tamaño de los I-frames) porque la predicción se realiza a partir de un fotograma anterior o posterior, o de ambos. (Los B-frames también pueden ser menos eficientes que los P-frames en ciertos casos, [1] por ejemplo: codificación sin pérdida).
De manera similar a los fotogramas P, los fotogramas B se expresan como vectores de movimiento y coeficientes de transformación. Para evitar un error de propagación creciente, los fotogramas B no se utilizan como referencia para realizar predicciones adicionales en la mayoría de los estándares de codificación. Sin embargo, en los métodos de codificación más nuevos (como H.264/MPEG-4 AVC y HEVC ), los fotogramas B se pueden utilizar como referencia para aprovechar mejor la redundancia temporal. [2] [3]
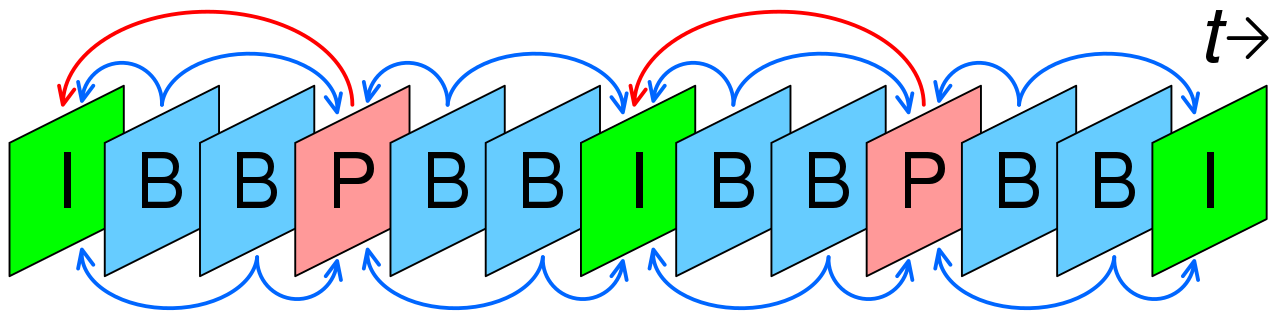
La estructura típica de un grupo de imágenes (GOP) es IBBPBBP... El fotograma I se utiliza para predecir el primer fotograma P y estos dos fotogramas también se utilizan para predecir el primer y el segundo fotograma B. El segundo fotograma P también se predice utilizando el primer fotograma I. Ambos fotogramas P se unen para predecir el tercer y el cuarto fotograma B. El esquema se muestra en la siguiente imagen:
Esta estructura plantea un problema porque se necesita el cuarto cuadro (un cuadro P) para predecir el segundo y el tercero (cuadros B). Por lo tanto, necesitamos transmitir el cuadro P antes que los cuadros B y esto retrasará la transmisión (será necesario mantener el cuadro P). Esta estructura tiene puntos fuertes:
Pero tiene puntos débiles:
Las mejoras más importantes de la técnica H.264 con respecto a los estándares anteriores (especialmente MPEG-2 ) son:
Partición de bloques de luminancia de 16×16 ( MPEG-2 ), 16×8, 8×16 y 8×8. El último caso permite la división del bloque en nuevos bloques de 4×8, 8×4 o 4×4.
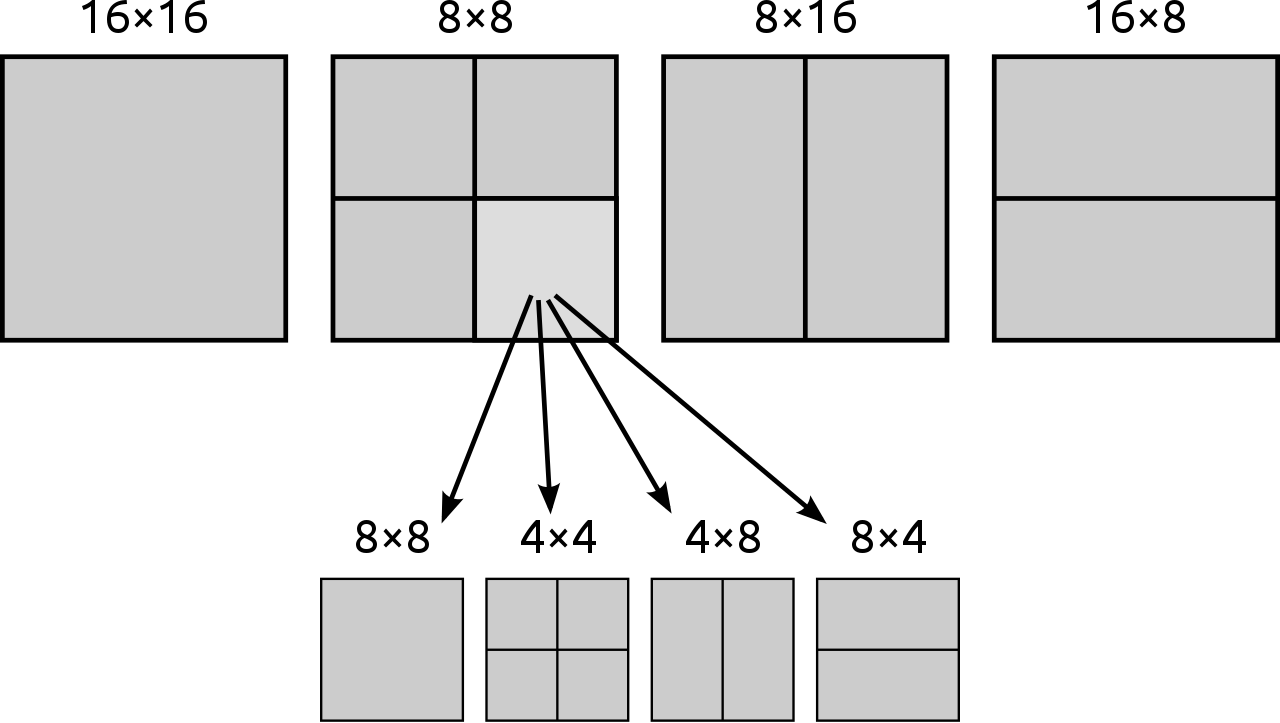
El fotograma que se va a codificar se divide en bloques de igual tamaño, como se muestra en la imagen anterior. Cada predicción de bloque estará formada por bloques del mismo tamaño que las imágenes de referencia, separados por un pequeño desplazamiento.
Los píxeles en la posición de medio píxel se obtienen aplicando un filtro de longitud 6.
H=[1 -5 20 20 -5 1], es decirmedio píxel "b"=A - 5B + 20C + 20D - 5E + F
Los píxeles en la posición de un cuarto de píxel se obtienen mediante interpolación bilineal .
Mientras que el MPEG-2 permite una resolución de ½ píxel, el Inter frame permite una resolución de hasta ¼ de píxel. Esto significa que es posible buscar un bloque en el fotograma para codificarlo en otros fotogramas de referencia, o podemos interpolar píxeles inexistentes para encontrar bloques que se adapten aún mejor al bloque actual. Si el vector de movimiento es un número entero de unidades de muestra, significa que es posible encontrar en las imágenes de referencia el bloque compensado en movimiento. Si el vector de movimiento no es un número entero, la predicción se obtendrá a partir de los píxeles interpolados por un filtro interpolador en direcciones horizontal y vertical.
Las referencias múltiples a la estimación de movimiento permiten encontrar la mejor referencia en 2 posibles buffers (Lista 0 para imágenes pasadas, Lista 1 para imágenes futuras) que contienen hasta 16 cuadros en total. [4] [5] La predicción de bloques se realiza mediante una suma ponderada de bloques de la imagen de referencia. Permite una mejor calidad de imagen en escenas donde hay cambios de plano, zoom o cuando se revelan nuevos objetos.
Los modos directo y de salto se utilizan con mucha frecuencia, especialmente con fotogramas B. Reducen significativamente la cantidad de bits a codificar. Se hace referencia a estos modos cuando se codifica un bloque sin enviar errores residuales ni vectores de movimiento. El codificador solo registrará que se trata de un macrobloque de salto. El decodificador deducirá el vector de movimiento del bloque codificado en modo directo/de salto a partir de otros bloques ya decodificados.
Hay dos formas de deducir el movimiento:
En la figura anterior, los bloques rosados son bloques codificados en modo directo/saltar. Como podemos ver, se utilizan con mucha frecuencia, principalmente en fotogramas B.
Aunque el uso del término "cuadro" es común en el uso informal, en muchos casos (como en los estándares internacionales para codificación de video de MPEG y VCEG ) se aplica un concepto más general al utilizar la palabra "imagen" en lugar de "cuadro", donde una imagen puede ser un cuadro completo o un solo campo entrelazado .
Los códecs de vídeo como MPEG-2 , H.264 u Ogg Theora reducen la cantidad de datos de una transmisión al incluir uno o más fotogramas intermedios después de los fotogramas clave. Estos fotogramas se pueden codificar normalmente con una tasa de bits inferior a la necesaria para los fotogramas clave, ya que gran parte de la imagen suele ser similar, por lo que solo es necesario codificar las partes cambiantes.