En programación y seguridad de la información , un desbordamiento de búfer o desbordamiento de búfer es una anomalía por la cual un programa escribe datos en un búfer más allá de la memoria asignada al búfer , sobrescribiendo las ubicaciones de memoria adyacentes .
Los buffers son áreas de memoria reservadas para almacenar datos, a menudo mientras se mueven de una sección de un programa a otra, o entre programas. Los desbordamientos de buffer a menudo pueden ser provocados por entradas mal formadas; si uno supone que todas las entradas serán más pequeñas que un tamaño determinado y el buffer se crea para que tenga ese tamaño, entonces una transacción anómala que produzca más datos podría hacer que se escriba más allá del final del buffer. Si esto sobrescribe datos adyacentes o código ejecutable, puede resultar en un comportamiento errático del programa, incluidos errores de acceso a la memoria , resultados incorrectos y fallas .
La explotación del comportamiento de un desbordamiento de búfer es un exploit de seguridad bien conocido . En muchos sistemas, la distribución de la memoria de un programa, o del sistema en su conjunto, está bien definida. Al enviar datos diseñados para provocar un desbordamiento de búfer, es posible escribir en áreas que se sabe que contienen código ejecutable y reemplazarlo con código malicioso , o sobrescribir selectivamente datos pertenecientes al estado del programa, lo que provoca un comportamiento que no fue previsto por el programador original. Los búferes están muy extendidos en el código del sistema operativo (SO), por lo que es posible realizar ataques que realicen una escalada de privilegios y obtengan acceso ilimitado a los recursos del equipo. El famoso gusano Morris en 1988 utilizó esto como una de sus técnicas de ataque.
Los lenguajes de programación que se asocian comúnmente con desbordamientos de búfer incluyen C y C++ , que no brindan protección incorporada contra el acceso o la sobrescritura de datos en cualquier parte de la memoria y no verifican automáticamente que los datos escritos en una matriz (el tipo de búfer incorporado) estén dentro de los límites de esa matriz. La verificación de límites puede evitar desbordamientos de búfer, pero requiere código adicional y tiempo de procesamiento. Los sistemas operativos modernos utilizan una variedad de técnicas para combatir desbordamientos de búfer maliciosos, en particular aleatorizando el diseño de la memoria o dejando deliberadamente espacio entre búferes y buscando acciones que escriban en esas áreas ("canarios").
Un desbordamiento de búfer ocurre cuando los datos escritos en un búfer también corrompen los valores de datos en direcciones de memoria adyacentes al búfer de destino debido a una verificación de límites insuficiente . [1] : 41 Esto puede ocurrir al copiar datos de un búfer a otro sin verificar primero que los datos quepan dentro del búfer de destino.
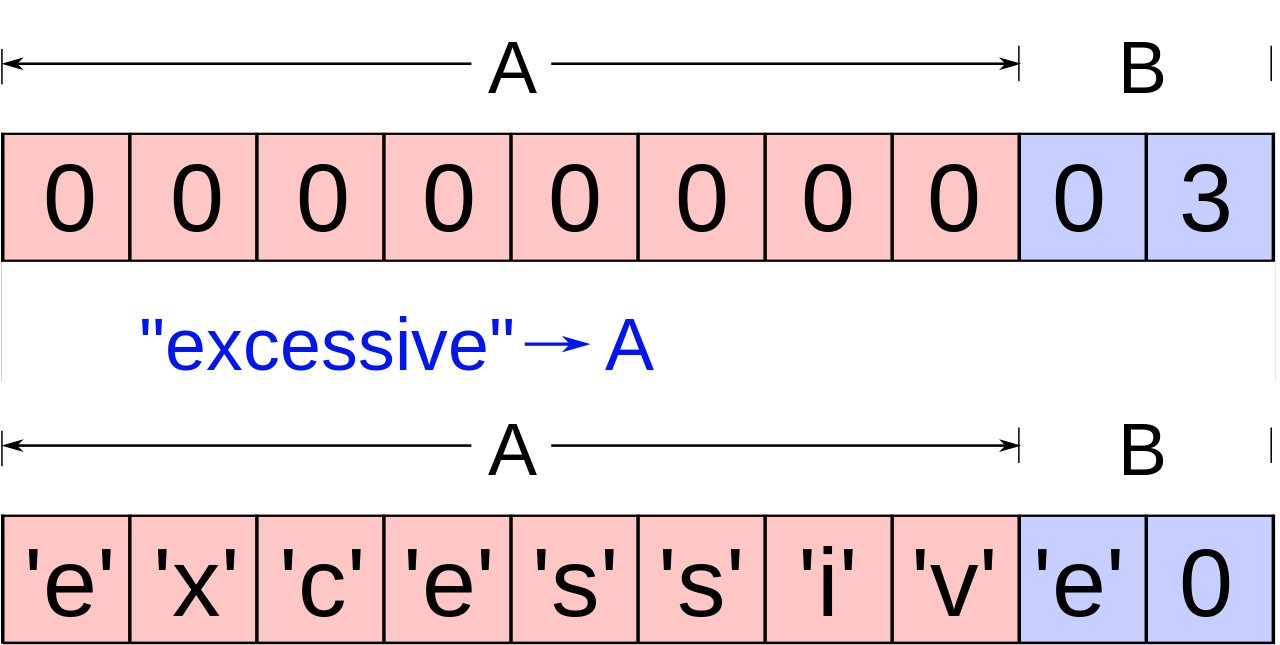
En el siguiente ejemplo expresado en C , un programa tiene dos variables adyacentes en la memoria: un búfer de cadena de 8 bytes de longitud, A, y un entero big-endian de dos bytes, B.
char A [ 8 ] = "" ; unsigned short B = 1979 ; Inicialmente, A no contiene nada más que cero bytes y B contiene el número 1979.
Ahora, el programa intenta almacenar la cadena terminada en nulo "excessive" con codificación ASCII en el búfer A.
strcpy ( A , "excesivo" ); "excessive"tiene 9 caracteres de longitud y se codifica en 10 bytes, incluido el terminador nulo, pero A solo puede ocupar 8 bytes. Al no comprobar la longitud de la cadena, también sobrescribe el valor de B:
El valor de B ha sido reemplazado inadvertidamente por un número formado a partir de una parte de la cadena de caracteres. En este ejemplo, "e" seguido de un byte cero se convertiría en 25856.
A veces, el sistema operativo puede detectar que escribir datos más allá del final de la memoria asignada genera un error de segmentación que finaliza el proceso.
Para evitar que se produzca un desbordamiento del búfer en este ejemplo, la llamada a strcpypodría reemplazarse por strlcpy, que toma la capacidad máxima de A (incluido un carácter de terminación nula) como parámetro adicional y garantiza que no se escriba más que esta cantidad de datos en A:
strlcpy ( A , "excesivo" , sizeof ( A )); Cuando está disponible, strlcpyse prefiere la función de biblioteca a strncpyla que no termina en nulo el búfer de destino si la longitud de la cadena de origen es mayor o igual que el tamaño del búfer (el tercer argumento que se pasa a la función). Por lo tanto, Ano puede terminar en nulo y no puede tratarse como una cadena válida de estilo C.
Las técnicas para explotar una vulnerabilidad de desbordamiento de búfer varían según la arquitectura , el sistema operativo y la región de memoria. Por ejemplo, la explotación en el montón (utilizado para la memoria asignada dinámicamente) difiere notablemente de la explotación en la pila de llamadas . En general, la explotación en el montón depende del administrador de montón utilizado en el sistema de destino, mientras que la explotación en la pila depende de la convención de llamadas utilizada por la arquitectura y el compilador.
Hay varias formas en las que se puede manipular un programa aprovechando los desbordamientos de búfer basados en la pila:
El atacante diseña datos para provocar uno de estos exploits, luego coloca estos datos en un búfer suministrado a los usuarios por el código vulnerable. Si la dirección de los datos suministrados por el usuario utilizados para afectar el desbordamiento del búfer de pila es impredecible, explotar un desbordamiento del búfer de pila para provocar la ejecución remota de código se vuelve mucho más difícil. Una técnica que se puede utilizar para explotar un desbordamiento de búfer de este tipo se llama " trampolining ". Aquí, un atacante encontrará un puntero al búfer de pila vulnerable y calculará la ubicación de su shellcode en relación con ese puntero. El atacante luego usará la sobrescritura para saltar a una instrucción que ya está en la memoria que realizará un segundo salto, esta vez en relación con el puntero. Ese segundo salto ramificará la ejecución en el shellcode. Las instrucciones adecuadas suelen estar presentes en código grande. El Proyecto Metasploit , por ejemplo, mantiene una base de datos de códigos de operación adecuados, aunque solo enumera aquellos que se encuentran en el sistema operativo Windows . [4]
Un desbordamiento de búfer que ocurre en el área de datos del montón se conoce como desbordamiento de montón y se puede explotar de una manera diferente a la de los desbordamientos basados en pila. La aplicación asigna dinámicamente la memoria del montón en tiempo de ejecución y normalmente contiene datos del programa. La explotación se realiza corrompiendo estos datos de formas específicas para hacer que la aplicación sobrescriba las estructuras internas, como los punteros de lista enlazada. La técnica de desbordamiento de montón canónico sobrescribe el enlace de asignación de memoria dinámica (como los metadatos de malloc ) y utiliza el intercambio de puntero resultante para sobrescribir un puntero de función del programa.
La vulnerabilidad GDI+ de Microsoft en el manejo de archivos JPEG es un ejemplo del peligro que puede presentar un desbordamiento de montón. [5]
La manipulación del búfer, que ocurre antes de que se lea o ejecute, puede provocar el fracaso de un intento de explotación. Estas manipulaciones pueden mitigar la amenaza de explotación, pero pueden no hacerla imposible. Las manipulaciones podrían incluir la conversión a mayúsculas o minúsculas, la eliminación de metacaracteres y el filtrado de cadenas no alfanuméricas . Sin embargo, existen técnicas para eludir estos filtros y manipulaciones, como el shellcode alfanumérico , el código polimórfico , el código automodificable y los ataques de retorno a libc . Se pueden utilizar los mismos métodos para evitar la detección por parte de los sistemas de detección de intrusiones . En algunos casos, incluso cuando el código se convierte a Unicode , [6] los divulgadores han tergiversado la amenaza de la vulnerabilidad como solo denegación de servicio cuando, de hecho, es posible la ejecución remota de código arbitrario.
En los exploits del mundo real, hay una variedad de desafíos que deben superarse para que los exploits funcionen de manera confiable. Estos factores incluyen bytes nulos en las direcciones, variabilidad en la ubicación del shellcode, diferencias entre entornos y varias contramedidas en la operación.

Un NOP-sled es la técnica más antigua y más conocida para explotar desbordamientos de búfer de pila. [7] Resuelve el problema de encontrar la dirección exacta del búfer aumentando efectivamente el tamaño del área objetivo. Para hacer esto, secciones mucho más grandes de la pila se corrompen con la instrucción de máquina no-op . Al final de los datos proporcionados por el atacante, después de las instrucciones no-op, el atacante coloca una instrucción para realizar un salto relativo a la parte superior del búfer donde se encuentra el shellcode . Esta colección de no-ops se conoce como el "NOP-sled" porque si la dirección de retorno se sobrescribe con cualquier dirección dentro de la región no-op del búfer, la ejecución se "deslizará" hacia abajo por las no-ops hasta que se redirija al código malicioso real por el salto al final. Esta técnica requiere que el atacante adivine en qué parte de la pila se encuentra el NOP-sled en lugar del shellcode comparativamente pequeño. [8]
Debido a la popularidad de esta técnica, muchos proveedores de sistemas de prevención de intrusiones buscarán este patrón de instrucciones de máquina no operativa en un intento de detectar el código shell en uso. Un sled NOP no necesariamente contiene solo instrucciones de máquina no operativas tradicionales. Cualquier instrucción que no corrompa el estado de la máquina hasta un punto en que el código shell no se ejecute se puede utilizar en lugar del no-op asistido por hardware. Como resultado, se ha convertido en una práctica común para los escritores de exploits componer el sled no-op con instrucciones elegidas al azar que no tendrán un efecto real en la ejecución del código shell. [9]
Aunque este método mejora enormemente las posibilidades de que un ataque tenga éxito, no está exento de problemas. Los exploits que utilizan esta técnica aún deben confiar en cierta cantidad de suerte para adivinar los desplazamientos en la pila que están dentro de la región NOP-sled. [10] Una suposición incorrecta generalmente provocará el bloqueo del programa de destino y podría alertar al administrador del sistema sobre las actividades del atacante. Otro problema es que el NOP-sled requiere una cantidad de memoria mucho mayor para albergar un NOP-sled lo suficientemente grande como para que sea de alguna utilidad. Esto puede ser un problema cuando el tamaño asignado del búfer afectado es demasiado pequeño y la profundidad actual de la pila es baja (es decir, no hay mucho espacio desde el final del marco de la pila actual hasta el comienzo de la pila). A pesar de sus problemas, el NOP-sled es a menudo el único método que funcionará para una plataforma, entorno o situación determinada y, como tal, sigue siendo una técnica importante.
La técnica de "saltar al registro" permite una explotación fiable de los desbordamientos del búfer de pila sin necesidad de espacio adicional para un sled NOP y sin tener que adivinar los desplazamientos de la pila. La estrategia consiste en sobrescribir el puntero de retorno con algo que haga que el programa salte a un puntero conocido almacenado dentro de un registro que apunta al búfer controlado y, por tanto, al shellcode. Por ejemplo, si el registro A contiene un puntero al inicio de un búfer, entonces cualquier salto o llamada que tome ese registro como operando se puede utilizar para obtener el control del flujo de ejecución. [11]

DbgPrint()rutina contiene el código de operación de la máquina i386 para jmp esp.En la práctica, un programa puede no contener intencionalmente instrucciones para saltar a un registro en particular. La solución tradicional es encontrar una instancia no intencional de un código de operación adecuado en una ubicación fija en algún lugar dentro de la memoria del programa. La Figura E a la izquierda contiene un ejemplo de una instancia no intencional de la jmp espinstrucción i386. El código de operación para esta instrucción es FF E4. [12] Esta secuencia de dos bytes se puede encontrar en un desplazamiento de un byte desde el inicio de la instrucción call DbgPrinten la dirección 0x7C941EED. Si un atacante sobrescribe la dirección de retorno del programa con esta dirección, el programa primero saltará a 0x7C941EED, interpretará el código de operación FF E4como la jmp espinstrucción y luego saltará a la parte superior de la pila y ejecutará el código del atacante. [13]
Cuando esta técnica es posible, la gravedad de la vulnerabilidad aumenta considerablemente, ya que la explotación funcionará de forma suficientemente fiable como para automatizar un ataque con una garantía virtual de éxito cuando se ejecute. Por este motivo, esta es la técnica más utilizada en gusanos de Internet que explotan vulnerabilidades de desbordamiento de búfer de pila. [14]
Este método también permite colocar el shellcode después de la dirección de retorno sobrescrita en la plataforma Windows. Dado que los ejecutables se basan principalmente en la dirección 0x00400000y x86 es una arquitectura little endian , el último byte de la dirección de retorno debe ser nulo, lo que finaliza la copia del búfer y no se escribe nada más allá de eso. Esto limita el tamaño del shellcode al tamaño del búfer, lo que puede ser demasiado restrictivo. Las DLL se encuentran en la memoria alta (por encima de 0x01000000) y, por lo tanto, tienen direcciones que no contienen bytes nulos, por lo que este método puede eliminar bytes nulos (u otros caracteres no permitidos) de la dirección de retorno sobrescrita. Si se utiliza de esta manera, el método a menudo se conoce como "trampolín de DLL".
Se han utilizado diversas técnicas para detectar o prevenir desbordamientos de búfer, con distintas ventajas y desventajas. Las siguientes secciones describen las opciones e implementaciones disponibles.
Assembly, C y C++ son lenguajes de programación populares que son vulnerables al desbordamiento de búfer en parte porque permiten el acceso directo a la memoria y no están fuertemente tipados . [15] C no proporciona protección incorporada contra el acceso o la sobrescritura de datos en cualquier parte de la memoria. Más específicamente, no verifica que los datos escritos en un búfer estén dentro de los límites de ese búfer. Las bibliotecas estándar de C++ proporcionan muchas formas de almacenar datos en búfer de forma segura, y la biblioteca de plantillas estándar (STL) de C++ proporciona contenedores que pueden realizar opcionalmente una verificación de límites si el programador solicita explícitamente verificaciones mientras accede a los datos. Por ejemplo, una vectorfunción miembro at()de realiza una verificación de límites y lanza una out_of_range excepción si la verificación de límites falla. [16] Sin embargo, C++ se comporta igual que C si la verificación de límites no se llama explícitamente. También existen técnicas para evitar desbordamientos de búfer para C.
Los lenguajes que están fuertemente tipados y no permiten el acceso directo a la memoria, como COBOL, Java, Eiffel, Python y otros, evitan el desbordamiento del búfer en la mayoría de los casos. [15] Muchos lenguajes de programación distintos de C o C++ proporcionan comprobación en tiempo de ejecución y, en algunos casos, incluso comprobación en tiempo de compilación que podría enviar una advertencia o generar una excepción, mientras que C o C++ sobrescribirían los datos y continuarían ejecutando instrucciones hasta que se obtengan resultados erróneos, lo que podría provocar que el programa se bloquee. Ejemplos de dichos lenguajes incluyen Ada , Eiffel , Lisp , Modula-2 , Smalltalk , OCaml y derivados de C como Cyclone , Rust y D. Los entornos de código de bytes de Java y .NET Framework también requieren comprobación de límites en todas las matrices. Casi todos los lenguajes interpretados protegerán contra el desbordamiento del búfer, señalando una condición de error bien definida. Los lenguajes que proporcionan suficiente información de tipo para realizar la comprobación de límites a menudo proporcionan una opción para habilitarla o deshabilitarla. El análisis de código estático puede eliminar muchas comprobaciones de tipo y límites dinámicos, pero las implementaciones deficientes y los casos incómodos pueden reducir significativamente el rendimiento. Los ingenieros de software deben considerar cuidadosamente las compensaciones entre los costos de seguridad y de rendimiento al momento de decidir qué lenguaje y configuración de compilador utilizar.
El problema de los desbordamientos de búfer es común en los lenguajes C y C++ porque exponen detalles de representación de bajo nivel de los búferes como contenedores para tipos de datos. Los desbordamientos de búfer se pueden evitar manteniendo un alto grado de corrección en el código que realiza la gestión del búfer. También se ha recomendado durante mucho tiempo evitar las funciones de la biblioteca estándar que no tienen límites comprobados, como gets, scanfy strcpy. El gusano Morris explotó una getsllamada en fingerd . [17]
Las bibliotecas de tipos de datos abstractos bien escritas y probadas que centralizan y realizan automáticamente la gestión de búfer, incluida la comprobación de límites, pueden reducir la aparición y el impacto de los desbordamientos de búfer. Los tipos de datos principales en los lenguajes en los que los desbordamientos de búfer son comunes son las cadenas y las matrices. Por lo tanto, las bibliotecas que evitan los desbordamientos de búfer en estos tipos de datos pueden proporcionar la gran mayoría de la cobertura necesaria. Sin embargo, no utilizar correctamente estas bibliotecas seguras puede dar lugar a desbordamientos de búfer y otras vulnerabilidades, y naturalmente cualquier error en la biblioteca también es una vulnerabilidad potencial. Las implementaciones de bibliotecas "seguras" incluyen "The Better String Library", [18] Vstr [19] y Erwin. [20] La biblioteca C del sistema operativo OpenBSD proporciona las funciones strlcpy y strlcat , pero estas son más limitadas que las implementaciones de bibliotecas seguras completas.
En septiembre de 2007 se publicó el Informe Técnico 24731, preparado por el comité de estándares de C. [21] Especifica un conjunto de funciones que se basan en las funciones de cadena y de E/S de la biblioteca estándar de C, con parámetros adicionales de tamaño de búfer. Sin embargo, la eficacia de estas funciones para reducir los desbordamientos de búfer es discutible. Requieren la intervención del programador en cada llamada de función, lo que es equivalente a la intervención que podría hacer que las funciones análogas de la biblioteca estándar más antiguas fueran seguras contra los desbordamientos de búfer. [22]
La protección contra desbordamientos de búfer se utiliza para detectar los desbordamientos de búfer más comunes comprobando que la pila no haya sido alterada cuando una función retorna. Si ha sido alterada, el programa sale con un error de segmentación . Tres de estos sistemas son Libsafe, [23] y los parches gcc StackGuard [24] y ProPolice [25] .
La implementación del modo de prevención de ejecución de datos (DEP) de Microsoft protege explícitamente el puntero al controlador de excepciones estructurado (SEH) para que no se sobrescriba. [26]
Es posible lograr una protección de pila más fuerte al dividir la pila en dos: una para los datos y otra para los retornos de funciones. Esta división está presente en el lenguaje Forth , aunque no fue una decisión de diseño basada en la seguridad. De todas formas, esta no es una solución completa para los desbordamientos de búfer, ya que los datos confidenciales que no sean la dirección de retorno aún pueden sobrescribirse.
Este tipo de protección tampoco es del todo precisa, ya que no detecta todos los ataques. Los sistemas como StackGuard se centran más en el comportamiento de los ataques, lo que los hace eficientes y más rápidos en comparación con los sistemas de comprobación de rango. [27]
Los desbordamientos de búfer funcionan manipulando punteros , incluidas las direcciones almacenadas. PointGuard se propuso como una extensión del compilador para evitar que los atacantes manipulen de forma fiable los punteros y las direcciones. [28] El enfoque funciona haciendo que el compilador agregue código para codificar automáticamente los punteros con XOR antes y después de que se utilicen. En teoría, debido a que el atacante no sabe qué valor se utilizará para codificar y decodificar el puntero, no se puede predecir a qué apuntará el puntero si se sobrescribe con un nuevo valor. PointGuard nunca se lanzó, pero Microsoft implementó un enfoque similar a partir de Windows XP SP2 y Windows Server 2003 SP1. [29] En lugar de implementar la protección de punteros como una característica automática, Microsoft agregó una rutina API que se puede llamar. Esto permite un mejor rendimiento (porque no se usa todo el tiempo), pero coloca la carga sobre el programador para saber cuándo es necesario su uso.
Debido a que XOR es lineal, un atacante puede manipular un puntero codificado sobrescribiendo solo los bytes inferiores de una dirección. Esto puede permitir que un ataque tenga éxito si el atacante puede intentar explotar la vulnerabilidad varias veces o completar un ataque haciendo que un puntero apunte a una de varias ubicaciones (como cualquier ubicación dentro de un sled NOP). [30] Microsoft agregó una rotación aleatoria a su esquema de codificación para abordar esta debilidad en las sobrescrituras parciales. [31]
La protección del espacio ejecutable es un método de protección contra desbordamientos de búfer que impide la ejecución de código en la pila o el montón. Un atacante puede utilizar desbordamientos de búfer para insertar código arbitrario en la memoria de un programa, pero con la protección del espacio ejecutable, cualquier intento de ejecutar ese código provocará una excepción.
Algunas CPU admiten una función llamada bit NX ("No eXecute") o XD ("eXecute Disabled"), que, junto con el software, se puede utilizar para marcar páginas de datos (como las que contienen la pila y el montón) como legibles y escribibles, pero no ejecutables.
Algunos sistemas operativos Unix (p. ej., OpenBSD , macOS ) se entregan con protección del espacio ejecutable (p. ej., W^X ). Algunos paquetes opcionales incluyen:
Las variantes más nuevas de Microsoft Windows también admiten la protección del espacio ejecutable, denominada Prevención de ejecución de datos . [35] Los complementos propietarios incluyen:
La protección del espacio ejecutable no suele proteger contra ataques de tipo return-to-libc o cualquier otro ataque que no dependa de la ejecución del código del atacante. Sin embargo, en sistemas de 64 bits que utilizan ASLR , como se describe a continuación, la protección del espacio ejecutable dificulta mucho la ejecución de dichos ataques.
La aleatorización del diseño del espacio de direcciones (ASLR) es una característica de seguridad informática que implica organizar las posiciones de áreas de datos clave, que generalmente incluyen la base del ejecutable y la posición de bibliotecas, montón y pila, de forma aleatoria en el espacio de direcciones de un proceso.
La aleatorización de las direcciones de memoria virtual en las que se pueden encontrar funciones y variables puede dificultar la explotación de un desbordamiento de búfer, pero no imposibilitarlo. También obliga al atacante a adaptar el intento de explotación al sistema individual, lo que frustra los intentos de los gusanos de Internet . [38] Un método similar, pero menos efectivo, es rebasar los procesos y las bibliotecas en el espacio de direcciones virtuales.
El uso de la inspección profunda de paquetes (DPI) puede detectar, en el perímetro de la red, intentos remotos muy básicos de explotar desbordamientos de búfer mediante el uso de firmas de ataque y heurísticas . Esta técnica puede bloquear paquetes que tienen la firma de un ataque conocido. Anteriormente se utilizaba en situaciones en las que se detectaba una larga serie de instrucciones de no operación (conocidas como NOP-sled) y la ubicación de la carga útil del exploit era ligeramente variable.
El escaneo de paquetes no es un método efectivo ya que solo puede prevenir ataques conocidos y hay muchas formas de codificar un NOP-sled. El shellcode utilizado por los atacantes puede ser alfanumérico , metamórfico o automodificable para evadir la detección por parte de escáneres de paquetes heurísticos y sistemas de detección de intrusiones .
La comprobación de desbordamientos de búfer y la aplicación de parches a los errores que los provocan ayuda a prevenirlos. Una técnica automatizada habitual para descubrirlos es el fuzzing . [39] Las pruebas de casos extremos también pueden descubrir desbordamientos de búfer, al igual que el análisis estático. [40] Una vez que se detecta un posible desbordamiento de búfer, se debe aplicar un parche. Esto hace que el enfoque de pruebas sea útil para el software que está en desarrollo, pero menos útil para el software heredado que ya no se mantiene ni se admite.
Los desbordamientos de búfer se comprendieron y se documentaron parcialmente de forma pública ya en 1972, cuando el Computer Security Technology Planning Study expuso la técnica: "El código que realiza esta función no comprueba las direcciones de origen y destino correctamente, lo que permite que el usuario superponga partes del monitor. Esto se puede utilizar para inyectar código en el monitor que permitirá al usuario tomar el control de la máquina". [41] Hoy en día, el monitor se denominaría núcleo.
La primera explotación hostil documentada de un desbordamiento de búfer fue en 1988. Fue uno de los varios exploits utilizados por el gusano Morris para propagarse a través de Internet. El programa explotado fue un servicio en Unix llamado finger . [42] Más tarde, en 1995, Thomas Lopatic redescubrió de forma independiente el desbordamiento de búfer y publicó sus hallazgos en la lista de correo de seguridad Bugtraq . [43] Un año después, en 1996, Elias Levy (también conocido como Aleph One) publicó en la revista Phrack el artículo "Smashing the Stack for Fun and Profit", [44] una introducción paso a paso a la explotación de vulnerabilidades de desbordamiento de búfer basadas en la pila.
Desde entonces, al menos dos gusanos importantes de Internet han explotado desbordamientos de búfer para comprometer una gran cantidad de sistemas. En 2001, el gusano Code Red aprovechó un desbordamiento de búfer en Internet Information Services (IIS) 5.0 de Microsoft [45] y en 2003 el gusano SQL Slammer comprometió máquinas que ejecutaban Microsoft SQL Server 2000. [ 46]
En 2003, los desbordamientos de búfer presentes en los juegos con licencia de Xbox se han explotado para permitir que software sin licencia, incluidos los juegos homebrew , se ejecuten en la consola sin la necesidad de modificaciones de hardware, conocidas como modchips . [47] El PS2 Independence Exploit también utilizó un desbordamiento de búfer para lograr lo mismo para la PlayStation 2. El hack de Twilight logró lo mismo con la Wii , utilizando un desbordamiento de búfer en The Legend of Zelda: Twilight Princess .
{{cite journal}}: Requiere citar revista |journal=( ayuda ){{cite journal}}: Requiere citar revista |journal=( ayuda ){{cite journal}}: Requiere citar revista |journal=( ayuda ){{cite journal}}: Requiere citar revista |journal=( ayuda ){{cite web}}: CS1 maint: copia archivada como título ( enlace )