En informática y telecomunicaciones , un carácter de control o carácter no imprimible ( NPC ) es un punto de código en un conjunto de caracteres que no representa un carácter escrito o símbolo. Se utilizan como señalización en banda para provocar efectos distintos a la adición de un símbolo al texto. Todos los demás caracteres son principalmente caracteres gráficos , también conocidos como caracteres de impresión (o caracteres imprimibles ), excepto quizás los caracteres de " espacio ". En el estándar ASCII hay 33 caracteres de control, como el código 7, BEL , que hace sonar una campana de terminal.
Los signos de procedimiento en código Morse son una forma de carácter de control.
En el código Baudot de 1870 se introdujeron una serie de caracteres de control : NUL y DEL. El código Murray de 1901 añadió el retorno de carro (CR) y el avance de línea (LF), y otras versiones del código Baudot incluyeron otros caracteres de control.
El carácter de campana (BEL), que hacía sonar una campana para alertar a los operadores, también fue uno de los primeros caracteres de control de teletipo .
Algunos caracteres de control también han sido denominados "efectores de formato".
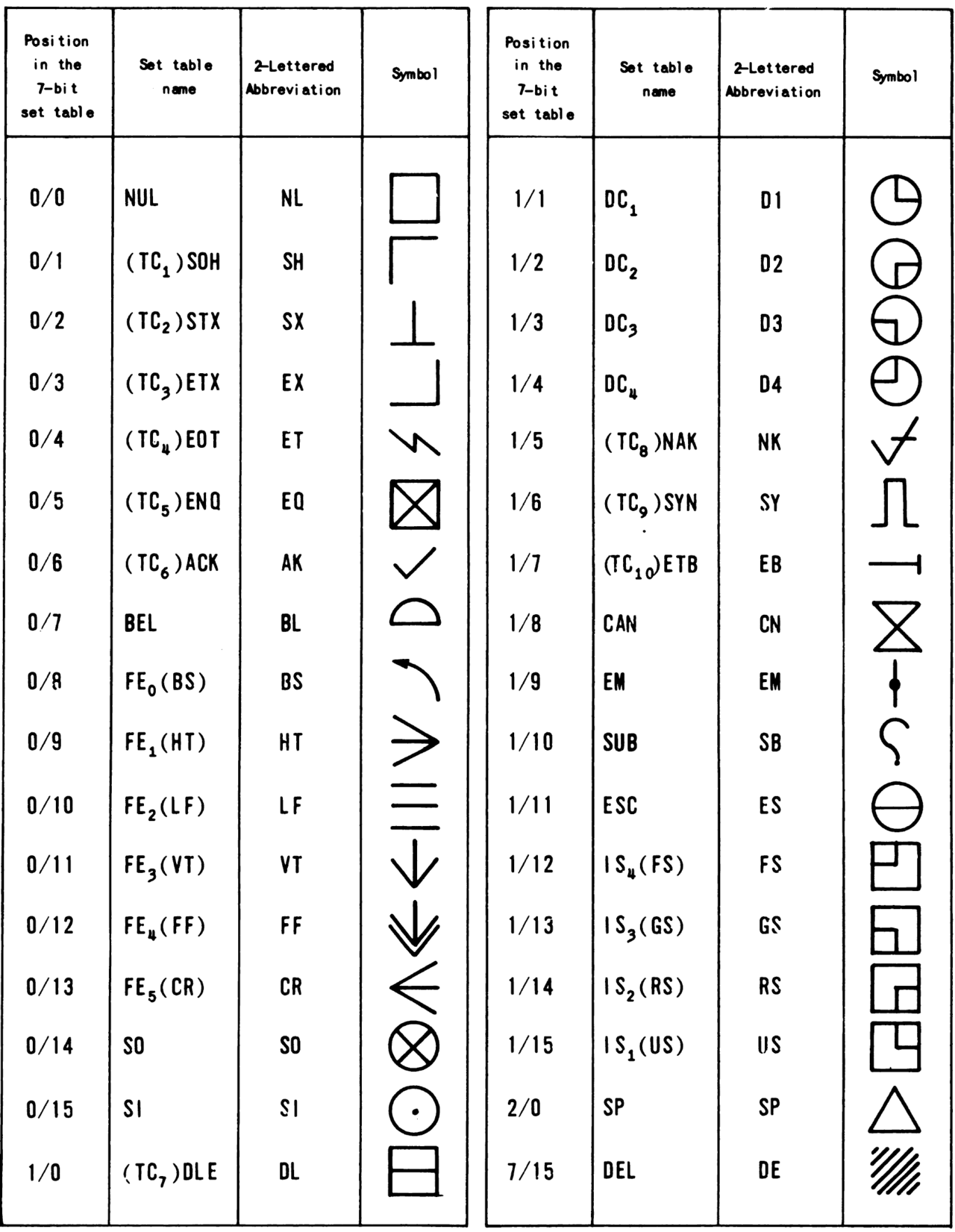
Se definieron bastantes caracteres de control (33 en ASCII, y el estándar ECMA-48 añade 32 más). Esto se debía a que los primeros terminales tenían controles mecánicos o eléctricos muy primitivos que hacían que cualquier tipo de API de recuerdo de estado fuera bastante costoso de implementar, por lo que un código diferente para cada función parecía un requisito. Rápidamente se hizo posible y económico interpretar secuencias de códigos para realizar una función, y los fabricantes de dispositivos encontraron una forma de enviar cientos de instrucciones de dispositivo. En concreto, utilizaron el código ASCII 27 10 (escape), seguido de una serie de caracteres denominados "secuencia de control" o "secuencia de escape". El mecanismo fue inventado por Bob Bemer , el padre de ASCII. Por ejemplo, la secuencia de código 27 10 , seguida de los caracteres imprimibles "[2;10H", haría que un terminal VT100 de Digital Equipment Corporation moviera su cursor a la décima celda de la segunda línea de la pantalla. Existen varios estándares para estas secuencias, especialmente ANSI X3.64 , pero el número de variaciones no estándar es grande.
Todas las entradas de la tabla ASCII por debajo del código 32 10 (técnicamente el conjunto de códigos de control C0 ) son de este tipo, incluyendo CR y LF, que se utilizan para separar líneas de texto. El código 127 10 ( DEL ) también es un carácter de control. [1] [2] Los conjuntos ASCII extendidos definidos por ISO 8859 añadieron los códigos 128 10 a 159 10 como caracteres de control. Esto se hizo principalmente para que, si se eliminaba el bit alto, no cambiara un carácter de impresión a un código de control C0. Este segundo conjunto se denomina conjunto C1 .
Estos 65 códigos de control se trasladaron a Unicode . Unicode agregó más caracteres que podrían considerarse de control, pero hace una distinción entre estos "caracteres de formato" (como el non-joiner de ancho cero ) y los 65 caracteres de control.
El conjunto de caracteres EBCDIC ( código de intercambio decimal codificado en binario extendido ) contiene 65 códigos de control, incluidos todos los códigos de control ASCII más códigos adicionales que se utilizan principalmente para controlar periféricos de IBM.
Los caracteres de control en ASCII que todavía se utilizan comúnmente incluyen:
Los caracteres de control pueden describirse como algo que hace algo cuando el usuario los ingresa, como el código 3 ( carácter de fin de texto , ETX, ^C ) para interrumpir el proceso en ejecución, o el código 4 ( carácter de fin de transmisión , EOT, ^D ), utilizado para finalizar la entrada de texto en Unix o para salir de un shell de Unix . Estos usos generalmente tienen poco que ver con su uso cuando están en el texto que se está generando.
En Unicode, los "caracteres de control" son U+0000—U+001F (controles C0), U+007F (eliminar) y U+0080—U+009F (controles C1). Su categoría general es "Cc". Los códigos de formato son distintos, en la categoría general "Cf". Los caracteres de control Cc no tienen nombre en Unicode, pero se les asignan etiquetas como "<control-001A>" en su lugar. [4]
Existen varias técnicas para mostrar caracteres no imprimibles, que pueden ilustrarse con el carácter de campana en codificación ASCII :
Los teclados basados en ASCII tienen una tecla denominada " Control ", "Ctrl" o (raramente) "Cntl", que se utiliza de forma muy similar a una tecla de mayúsculas, ya que se presiona en combinación con otra tecla de letra o símbolo. En una implementación, la tecla de control genera el código 64 lugares por debajo del código de la letra (generalmente) mayúscula con la que se presiona en combinación (es decir, resta 0x40 del valor del código ASCII de la letra (generalmente) mayúscula). La otra implementación es tomar el código ASCII producido por la tecla y realizar una operación AND bit a bit con 0x1F, lo que obliga a que los bits 5 a 7 sean cero. Por ejemplo, al presionar "control" y la letra "g" (que es 0110 0111 en binario ), se produce el código 7 (BELL, 7 en base diez o 0000 0111 en binario). El carácter NULL (código 0) se representa con Ctrl-@, siendo "@" el código inmediatamente anterior a "A" en el conjunto de caracteres ASCII. Por comodidad, algunas terminales aceptan Ctrl-Espacio como alias para Ctrl-@. En cualquier caso, esto produce uno de los 32 códigos de control ASCII entre 0 y 31. Ninguno de los dos métodos funciona para producir el carácter DEL debido a su ubicación especial en la tabla y su valor (código 127 10 ), Ctrl-? a veces se utiliza para este carácter. [5]
Cuando se mantiene presionada la tecla de control, las teclas de letras producen los mismos caracteres de control independientemente del estado de las teclas de mayúsculas o de bloqueo de mayúsculas . En otras palabras, no importa si la tecla hubiera producido una letra mayúscula o minúscula. La interpretación de la tecla de control con las teclas de espacio, caracteres gráficos y dígitos (códigos ASCII 32 a 63) varía entre sistemas. Algunos producirán el mismo código de carácter que si no se mantuviera presionada la tecla de control. Otros sistemas traducen estas teclas en caracteres de control cuando se mantiene presionada la tecla de control. La interpretación de la tecla de control con teclas que no son ASCII ("extranjeras") también varía entre sistemas.
Los caracteres de control se suelen representar en un formato imprimible conocido como notación de intercalación, mediante la impresión de un intercalador (^) y, a continuación, el carácter ASCII que tiene un valor del carácter de control más 64. Los caracteres de control generados mediante teclas de letras se muestran, por tanto, con la forma mayúscula de la letra. Por ejemplo, ^G representa el código 7, que se genera al pulsar la tecla G mientras se mantiene pulsada la tecla de control.
Los teclados también suelen tener algunas teclas individuales que producen códigos de caracteres de control. Por ejemplo, la tecla denominada "Retroceso" normalmente produce el código 8, la tecla "Tab" el código 9, la tecla "Enter" o "Return" el código 13 (aunque algunos teclados pueden producir el código 10 para "Enter").
Muchos teclados incluyen teclas que no corresponden a ningún carácter de control o imprimible ASCII, por ejemplo, flechas de control del cursor y funciones de procesamiento de textos . Las pulsaciones de teclas asociadas se comunican a los programas informáticos mediante uno de cuatro métodos: apropiándose de caracteres de control que de otro modo no se utilizarían; utilizando alguna codificación distinta a ASCII; utilizando secuencias de control de múltiples caracteres; o utilizando un mecanismo adicional fuera de la generación de caracteres. Los terminales informáticos "tontos" suelen utilizar secuencias de control. Los teclados conectados a los ordenadores personales independientes fabricados en la década de 1980 suelen utilizar uno (o ambos) de los dos primeros métodos. Los teclados de ordenador modernos generan códigos de escaneo que identifican las teclas físicas específicas que se pulsan; el software informático determina entonces cómo manejar las teclas que se pulsan, incluido cualquiera de los cuatro métodos descritos anteriormente.
Los caracteres de control fueron diseñados para dividirse en unos pocos grupos: control de impresión y visualización, estructuración de datos, control de transmisión y varios.
Los caracteres de control de impresión se utilizaron por primera vez para controlar el mecanismo físico de las impresoras, el dispositivo de salida más antiguo. Un ejemplo temprano de esta idea fue el uso de cifras (FIGS) y letras (LTRS) en el código Baudot para cambiar entre dos páginas de códigos. Un ejemplo posterior, pero aún temprano, fueron los caracteres de control de carro ASA fuera de banda . Más tarde, los caracteres de control se integraron en el flujo de datos que se iban a imprimir. El carácter de retorno de carro (CR), cuando se envía a un dispositivo de este tipo, hace que coloque el carácter en el borde del papel en el que comienza la escritura (también puede, o no, mover la posición de impresión a la siguiente línea). El carácter de avance de línea (LF/NL) hace que el dispositivo coloque la posición de impresión en la siguiente línea. Puede (o no), dependiendo del dispositivo y su configuración, también mover la posición de impresión al comienzo de la siguiente línea (que sería la posición más a la izquierda para las escrituras de izquierda a derecha , como los alfabetos utilizados para los idiomas occidentales, y la posición más a la derecha para las escrituras de derecha a izquierda, como los alfabetos hebreo y árabe). Los caracteres de tabulación verticales y horizontales (VT y HT/TAB) hacen que el dispositivo de salida mueva la posición de impresión a la siguiente parada de tabulación en la dirección de lectura. El carácter de avance de página (FF/NP) inicia una nueva hoja de papel y puede o no moverse al comienzo de la primera línea. El carácter de retroceso (BS) mueve la posición de impresión un espacio de carácter hacia atrás. En las impresoras, incluidas las terminales de copia impresa , esto se usa con más frecuencia para que la impresora pueda sobreimprimir caracteres para crear otros caracteres que normalmente no están disponibles. En las terminales de video y otros dispositivos de salida electrónicos, a menudo hay opciones de configuración de software (o hardware) que permiten un retroceso destructivo (por ejemplo, una secuencia BS, SP, BS), que borra, o uno no destructivo, que no lo hace. Los caracteres de desplazamiento hacia adentro y hacia afuera (SI y SO) seleccionaban conjuntos de caracteres alternativos, fuentes, subrayado u otros modos de impresión. Las secuencias de escape se usaban a menudo para hacer lo mismo.
Con la llegada de terminales de ordenador que no imprimían físicamente en papel y que, por tanto, ofrecían más flexibilidad en cuanto a la colocación de la pantalla, el borrado, etc., se adaptaron los códigos de control de impresión. Los avances de página, por ejemplo, normalmente dejaban la pantalla en blanco, ya que no había una nueva página de papel a la que pasar. Se desarrollaron secuencias de escape más complejas para aprovechar la flexibilidad de los nuevos terminales y, de hecho, de las impresoras más modernas. El concepto de carácter de control siempre había sido algo limitante, y lo era en extremo cuando se utilizaba con hardware nuevo, mucho más flexible. Las secuencias de control (a veces implementadas como secuencias de escape) podían adaptarse a la nueva flexibilidad y potencia y se convirtieron en el método estándar. Sin embargo, había, y sigue habiendo, una gran variedad de secuencias estándar entre las que elegir.
Los separadores (Archivo, Grupo, Registro y Unidad: FS, GS, RS y US) se crearon para estructurar datos, generalmente en una cinta, con el fin de simular tarjetas perforadas . El fin del medio (EM) advierte que la cinta (u otro medio de grabación) está terminando. Si bien muchos sistemas utilizan CR/LF y TAB para estructurar datos, es posible encontrar los caracteres de control de separador en datos que necesitan estructurarse. Los caracteres de control de separador no están sobrecargados; no hay un uso general de ellos excepto para separar datos en agrupaciones estructuradas. Sus valores numéricos son contiguos al carácter de espacio, que puede considerarse un miembro del grupo, como separador de palabras.
Por ejemplo, el separador RS se utiliza en la RFC 7464 (JSON Text Sequences) para codificar una secuencia de elementos JSON. Cada elemento de la secuencia comienza con un carácter RS y termina con un salto de línea. Esto permite serializar secuencias JSON abiertas. Es uno de los protocolos de transmisión JSON .
Los caracteres de control de transmisión fueron pensados para estructurar un flujo de datos y gestionar la retransmisión o falla elegante, según fuera necesario, ante errores de transmisión.
El carácter de inicio de encabezado (SOH) se utilizaba para marcar una sección sin datos de un flujo de datos (la parte de un flujo que contiene direcciones y otros datos de mantenimiento). El carácter de inicio de texto (STX) marcaba el final del encabezado y el inicio de la parte textual de un flujo. El carácter de fin de texto (ETX) marcaba el final de los datos de un mensaje. Una convención muy utilizada es convertir los dos caracteres que preceden a ETX en una suma de comprobación o CRC para fines de detección de errores. El carácter de fin de bloque de transmisión (ETB) se utilizaba para indicar el final de un bloque de datos, donde los datos se dividían en dichos bloques para fines de transmisión.
El carácter de escape ( ESC ) fue creado para "entrecomillar" el siguiente carácter; si se trataba de otro carácter de control, lo imprimía en lugar de realizar la función de control. Hoy en día casi nunca se utiliza para este propósito. Se utilizan varios caracteres imprimibles como " caracteres de escape " visibles, según el contexto.
El carácter sustituto ( SUB ) se creó para solicitar una traducción del siguiente carácter de un carácter imprimible a otro valor, generalmente estableciendo el bit 5 a cero. Esto es útil porque algunos medios (como las hojas de papel producidas por máquinas de escribir) solo pueden transmitir caracteres imprimibles. Sin embargo, en los sistemas MS-DOS con archivos abiertos en modo texto, el "fin del texto" o "fin del archivo" se marca con este carácter Ctrl-Z , en lugar de Ctrl-C o Ctrl-D , que son comunes en otros sistemas operativos.
El carácter de cancelación ( CAN ) indica que el elemento anterior debe descartarse. El carácter de reconocimiento negativo ( NAK ) es una bandera definitiva para, por lo general, indicar que la recepción fue un problema y, a menudo, que el elemento actual debe enviarse nuevamente. El carácter de reconocimiento ( ACK ) se utiliza normalmente como bandera para indicar que no se detectó ningún problema con el elemento actual.
Cuando un medio de transmisión es semidúplex (es decir, puede transmitir en una sola dirección a la vez), normalmente hay una estación maestra que puede transmitir en cualquier momento y una o más estaciones esclavas que transmiten cuando tienen permiso. El carácter de consulta ( ENQ ) generalmente lo utiliza una estación maestra para pedirle a una estación esclava que envíe su próximo mensaje. Una estación esclava indica que ha completado su transmisión enviando el carácter de fin de transmisión ( EOT ).
Los códigos de control de dispositivo (DC1 a DC4) eran originalmente genéricos, para ser implementados según fuera necesario por cada dispositivo. Sin embargo, una necesidad universal en la transmisión de datos es solicitar al remitente que detenga la transmisión cuando un receptor no puede aceptar más datos temporalmente. Digital Equipment Corporation inventó una convención que usaba 19 (el carácter de control de dispositivo 3 ( DC3 ), también conocido como control-S o XOFF ) para detener la transmisión, y 17 (el carácter de control de dispositivo 1 ( DC1 ), también conocido como control-Q o XON ) para iniciar la transmisión. Se ha vuelto tan ampliamente utilizado que la mayoría no se da cuenta de que no es parte del ASCII oficial. Esta técnica, independientemente de cómo se implemente, evita cables adicionales en el cable de datos dedicados solo a la gestión de la transmisión, lo que ahorra dinero. Sin embargo, se debe utilizar un protocolo sensato para el uso de tales señales de control de flujo de transmisión, para evitar posibles condiciones de bloqueo.
El carácter de escape de enlace de datos ( DLE ) fue concebido para ser una señal al otro extremo de un enlace de datos de que el siguiente carácter es un carácter de control como STX o ETX. Por ejemplo, un paquete puede estructurarse de la siguiente manera ( DLE ) <STX> <PAYLOAD> ( DLE ) <ETX>.
El código 7 ( BEL ) tiene como objetivo generar una señal audible en el terminal receptor. [6]
Muchos de los caracteres de control ASCII fueron diseñados para dispositivos de la época que no se ven a menudo en la actualidad. Por ejemplo, el código 22, "sincronización inactiva" ( SYN ), fue enviado originalmente por módems sincrónicos (que tienen que enviar datos constantemente) cuando no había datos reales para enviar. (Los sistemas modernos suelen utilizar un bit de inicio para anunciar el comienzo de una palabra transmitida; esta es una característica de la comunicación asincrónica . Los enlaces de comunicación sincrónica se veían más a menudo en mainframes, donde normalmente se ejecutaban a través de líneas alquiladas corporativas para conectar un mainframe a otro mainframe o quizás a una minicomputadora).
El código 0 (nombre de código ASCII NUL ) es un caso especial. En una cinta de papel, es el caso en el que no hay agujeros. Es conveniente tratarlo como un carácter de relleno sin ningún significado en caso contrario. Dado que la posición de un carácter NUL no tiene agujeros perforados, puede reemplazarse con cualquier otro carácter en un momento posterior, por lo que se usaba típicamente para reservar espacio, ya sea para corregir errores o para insertar información que estaría disponible en un momento posterior o en otro lugar. En informática, se usa a menudo para rellenar registros de longitud fija ; para marcar el final de una cadena ; y antiguamente para dar a los dispositivos de impresión tiempo suficiente para ejecutar una función de control .
El código 127 ( DEL , también conocido como "rubout") es también un caso especial. Su código de 7 bits es de todos los bits activados en binario, lo que esencialmente borraba una celda de carácter en una cinta de papel cuando se perforaba en exceso. La cinta de papel era un medio de almacenamiento común cuando se desarrolló ASCII, con una historia informática que se remonta a los equipos de descifrado de códigos de la Segunda Guerra Mundial en Biuro Szyfrów . La cinta de papel se volvió obsoleta en la década de 1970, por lo que este aspecto inteligente de ASCII rara vez se usó después de eso. Algunos sistemas (como los Apple originales) lo convirtieron en un retroceso. Pero debido a que su código está en el rango ocupado por otros caracteres imprimibles, y debido a que no tenía un glifo asignado oficialmente, muchos proveedores de equipos informáticos lo usaron como un carácter imprimible adicional (a menudo un carácter de "caja" completamente negro útil para borrar texto sobreimprimiendo con tinta).
Las ROM programables no borrables se implementan típicamente como matrices de elementos fusibles, cada uno representando un bit , que solo se puede conmutar en una dirección, generalmente de uno a cero. En dichas PROM, los caracteres DEL y NUL se pueden usar de la misma manera que se usaban en la cinta perforada: uno para reservar bytes de relleno sin sentido que se pueden escribir más tarde, y el otro para convertir bytes escritos en bytes de relleno sin sentido. Para las PROM que conmutan de uno a cero, los roles de NUL y DEL se invierten; además, DEL solo funcionará con caracteres de 7 bits, que rara vez se usan hoy en día; para contenido de 8 bits, se puede usar el código de carácter 255, comúnmente definido como un carácter de espacio indivisible, en lugar de DEL.
Muchos sistemas de archivos no permiten caracteres de control en los nombres de archivos , ya que pueden tener funciones reservadas.