

El método de entrada Wubizixing ( chino simplificado :五笔字型输入法; chino tradicional :五筆字型輸入法; pinyin : wǔbǐ zìxíng shūrùfǎ ; lit. 'método de entrada de modelo de caracteres de cinco trazos'), a menudo abreviado simplemente como Wubi o Wubi Xing , [1] es un método de entrada de caracteres chinos principalmente para ingresar texto en chino simplificado y chino tradicional en una computadora. Wubi no debe confundirse con el método Wubihua (五笔画) , que es un método de entrada diferente que comparte la categorización en cinco tipos de trazos.
El método también se conoce como Wang Ma ( chino simplificado :王码; chino tradicional :王碼; pinyin : Wáng mǎ ; lit. 'código Wang'), llamado así por el inventor Wang Yongmin (王永民). Hay cuatro versiones de Wubi que se consideran estándar: Wubi 86, Wubi 98, Wubi 18030 y Wubi New-century (la versión de tercera generación). Las últimas tres también se pueden utilizar para ingresar texto en chino tradicional , aunque de una manera más limitada. Wubi 86 es el método de entrada basado en formas más conocido y utilizado para teclados de letras completas en China continental . Si también se necesita ingresar con frecuencia caracteres chinos tradicionales, otros métodos de entrada como Cangjie o Zhengma pueden ser más adecuados para la tarea, y también es mucho más probable encontrarlos en la computadora que uno necesita usar.
El método Wubi se basa en la estructura de los caracteres más que en su pronunciación, lo que permite introducir caracteres incluso cuando el usuario no conoce la pronunciación, además de no estar demasiado vinculado a ninguna variedad hablada del chino . También es extremadamente eficiente: casi todos los caracteres se pueden escribir con un máximo de 4 pulsaciones de teclas. En la práctica, la mayoría de los caracteres se pueden escribir con menos. Hay informes de mecanógrafos experimentados que alcanzan los 160 caracteres por minuto con Wubi. [2] Lo que esto significa en el contexto del chino no es exactamente lo mismo que en el inglés, pero es cierto que Wubi es extremadamente rápido cuando lo utiliza un mecanógrafo experimentado. La razón principal de esto es que, a diferencia de los métodos de entrada fonética tradicionales, uno no tiene que perder tiempo seleccionando el carácter deseado de una lista de posibilidades homofónicas: prácticamente todos los caracteres tienen una representación única.
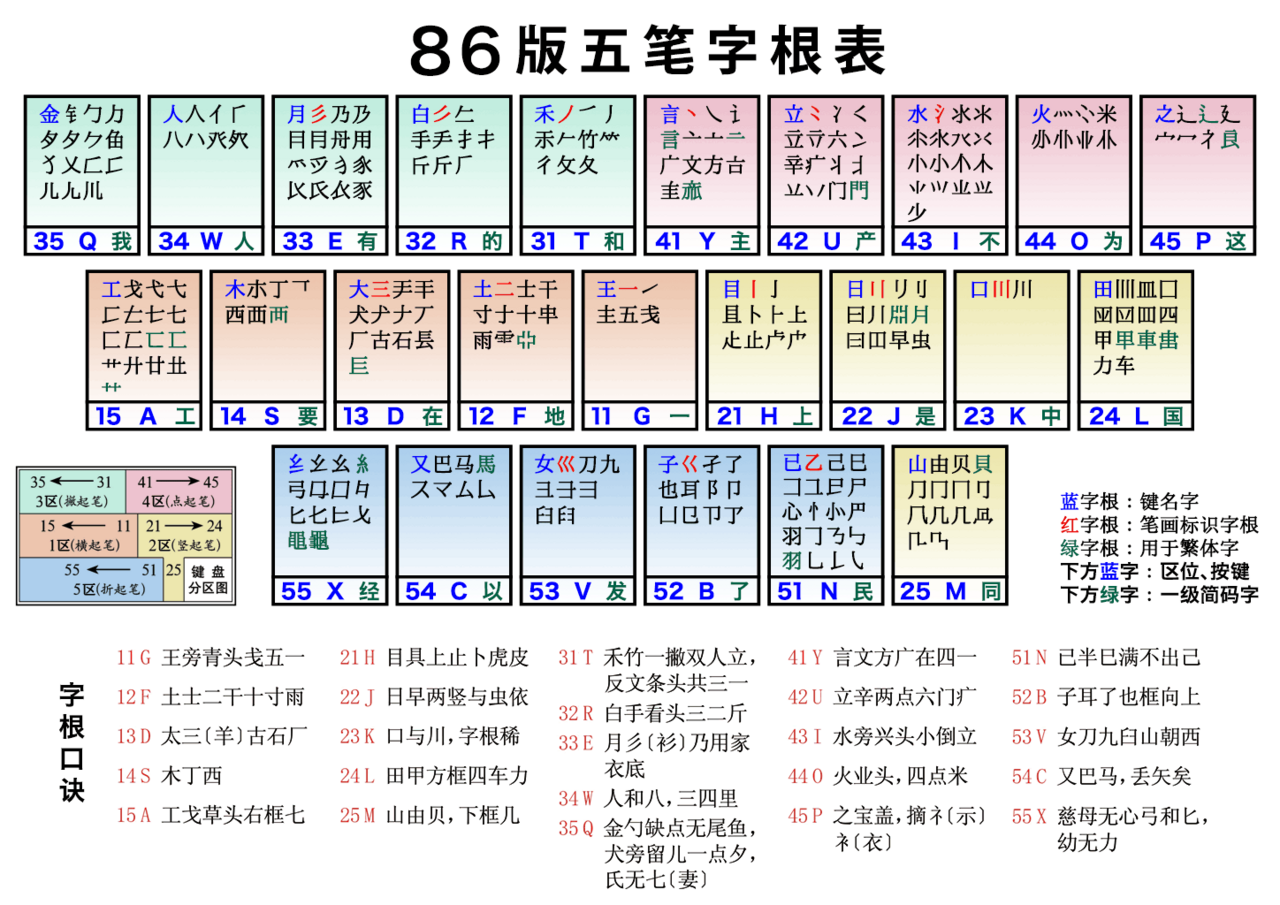
Como sugiere su nombre, el teclado está dividido en cinco regiones. El carácter chino 笔 (bǐ), cuando se utiliza en el contexto de la escritura de caracteres chinos, hace referencia a las pinceladas utilizadas en la caligrafía china. A cada región se le asigna un tipo de trazo determinado.
Una de las principales desventajas de aprender Wubi es que su curva de aprendizaje es más pronunciada, ya que, al ser un sistema más complejo, lleva más tiempo adquirir la habilidad necesaria. La memorización y la práctica son factores clave para un uso competente.
Para utilizar Wubi, hay varios métodos de entrada disponibles, incluidas las herramientas de entrada de Google (utilizadas por Google Translate) y las opciones de teclado en dispositivos Mac. Se pueden buscar secuencias de Wubi para caracteres específicos utilizando diccionarios en línea.
En este artículo, se utilizará la siguiente convención: carácter siempre significará carácter chino, mientras que letra , tecla y pulsación de tecla siempre se referirán a las teclas del teclado.
Básicamente, un carácter se descompone en componentes, que suelen ser (aunque no siempre) los mismos que los radicales . Estos se escriben en el orden en el que se escribirían a mano . Para garantizar que los caracteres extremadamente complejos no requieran una cantidad desmesurada de pulsaciones de teclas, cualquier carácter que contenga más de 4 componentes se introduce escribiendo los 3 primeros componentes escritos, seguidos del último. De esta forma, los datos de cada carácter se pueden introducir con no más de 4 pulsaciones de teclas.
Wubi distribuye sus caracteres de manera muy uniforme y, como tal, la gran mayoría de los caracteres están definidos de manera única por las 4 pulsaciones de teclas que se analizaron anteriormente. Luego, se escribe un espacio para mover el carácter desde el búfer de entrada a la pantalla. En el caso de que la representación de 4 letras del carácter no sea única, se escribiría un dígito para seleccionar el carácter relevante (por ejemplo, si dos caracteres tienen la misma representación, al escribir 1 se seleccionaría el primero y 2 el segundo). En la mayoría de las implementaciones, siempre se puede escribir un espacio y simplemente significa 1 en una configuración ambigua. El software inteligente intentará asegurarse de que el carácter en la posición predeterminada sea el deseado.
Muchos caracteres tienen más de una representación. A veces, esto se hace para facilitar su uso, en caso de que haya más de una forma obvia de descomponer un carácter. Sin embargo, con más frecuencia, se debe a que ciertos caracteres tienen una representación corta de menos de 4 letras, así como una representación "completa".
Para los caracteres con menos de 4 componentes que no tienen una representación en forma abreviada, se escribe cada componente y luego se "completa" la representación (es decir, se escriben suficientes pulsaciones de teclas adicionales para que la representación tenga 4 pulsaciones de teclas) escribiendo manualmente las pulsaciones del último componente, en el orden en que se escribirían. Si hay demasiados trazos, se deben escribir tantos como sea posible, pero se debe colocar el último trazo al final (esto refleja la regla de componentes para caracteres con más de 4 componentes descrita anteriormente).
Una vez que se comprende el algoritmo, se puede escribir prácticamente cualquier carácter con un poco de práctica, incluso si no se lo ha escrito antes. La memoria muscular garantiza que quienes escriben con frecuencia con este método no tengan que pensar en cómo se construyen realmente los caracteres, de la misma manera que la gran mayoría de los mecanógrafos ingleses no piensan demasiado en la ortografía de las palabras cuando escriben.
Muchas implementaciones emplean optimizaciones adicionales de varias palabras. Por lo general, un dígrafo de uso común (palabra de dos caracteres) en el que ambos caracteres tienen representaciones cortas de dos pulsaciones de teclas se puede combinar en una única representación de cuatro pulsaciones de teclas que genera dos caracteres en lugar de uno. También hay algunos atajos de 3 caracteres e incluso uno bastante más largo, con motivaciones políticas. [ Aclaración necesaria ] Algunos ejemplos de estos se proporcionan en la sección de ejemplos a continuación.
Otra característica común es el uso de la tecla "z" como comodín. El método Wubi fue diseñado con esta característica en mente; por eso no se asignan componentes a la tecla z. Básicamente, uno puede escribir az cuando no está seguro de cuál debería ser el componente, y el método de entrada le ayudará a completarlo. Si uno supiera, por ejemplo, que el carácter debería comenzar con "kt", pero no estuviera seguro de cuál debería ser el siguiente componente, escribir "ktz" produciría una lista de todos los caracteres que comienzan con "kt". Sin embargo, en la práctica, muchos motores de métodos de entrada utilizan un método de búsqueda tabular para todos los sistemas de entrada basados en tablas, incluido Wubi. Esto significa que simplemente tienen una tabla grande en la memoria, asociando diferentes caracteres a sus respectivas representaciones. El método de entrada entonces se convierte simplemente en una búsqueda en la tabla. En una implementación de este tipo, la tecla z rompe el paradigma y, como tal, no se encuentra en mucho software generalizado (aunque el método de entrada Wubi que se encuentra comúnmente en Windows chino implementa la característica). Por esta misma razón, la optimización de múltiples caracteres descrita en el párrafo anterior también es relativamente rara.
Algunos métodos de entrada, como xcin (que se encuentra en muchos sistemas similares a UNIX), proporcionan una funcionalidad genérica de comodín que se puede utilizar en todos los sistemas de entrada basados en tablas, incluidos pinyin y prácticamente cualquier otro. Xcin utiliza '*' para completar automáticamente y '?' para una sola letra, siguiendo las convenciones iniciadas en la codificación de archivos en UNIX. Otras implementaciones tienen sus propias convenciones.
El teclado Wubi asume una distribución similar a la del teclado QWERTY , por lo que los usuarios de teclados que implementan una distribución nacionalizada o alternativa (como Dvorak o el AZERTY francés ) probablemente tendrán que hacer algún tipo de remapeo para que el sistema funcione correctamente. Wubi no coloca sus componentes de manera arbitraria: hay demasiados y solo con la introducción de una metodología lógica el sistema se vuelve fácil de aprender.
Básicamente, el teclado está dividido en 5 zonas, cada una de las cuales representa un trazo. Esos cinco trazos son: descendente a la izquierda, descendente a la derecha, horizontal, vertical y en gancho, y las zonas que los representan son QWERT, YUIOP, ASDFG, HJKLM y XCVBN, respectivamente. Todas estas zonas están dispuestas horizontalmente, con la excepción de la M, que no está alineada con el resto de las letras de su zona.
De manera general, se puede pensar que el teclado está dividido por la mitad, entre T e Y, G y H, y N y M. Las teclas de cada zona se numeran alejándose de esta línea divisoria: por lo que en realidad deberíamos decir que en la zona QWERT, T es la primera letra, R es la segunda y E la tercera; en la zona YUIOP, Y es la primera, U es la segunda, I la tercera, etc. Para XCVBN, N es la primera, y así sucesivamente. En HJKLM, considere que M es la última de la serie, aunque no se encuentre en la línea.
Esto es importante porque los componentes que estén en la primera posición tendrán una repetición del trazo en cuestión (el trazo asignado a la zona a la que pertenecen), los de la segunda, dos, los de la tercera, tres. Aquellos componentes que no sean fácilmente clasificables utilizando este paradigma se colocarán en la última letra.
Por lo tanto, se esperaría que 一 estuviera en G, 二 en F y 三 en D, y de hecho, este es el caso. De manera similar, se esperaría que 丨 estuviera en H, 刂 en J y 川 en K. Este patrón se mantiene para todas las zonas. Además, se extiende a la mayoría de los radicales que parecen estar formados por tres trazos de este tipo, incluso si de hecho no lo están en absoluto. Un ejemplo de esto es 中 en K: si bien no tiene tres trazos descendentes (solo dos), parece tener tres. Además, se escribe a mano escribiendo primero un radical de boca, 口, y luego dividándolo con un trazo vertical descendente. El radical de boca se encuentra en 'K', por lo que esto hace que la asignación sea doblemente lógica. Y la romanización pinyin de 口, kou3, comienza con k, otra ayuda para la memoria codificada en el teclado Wubi.
Además, cada letra de cada zona tiene un componente asociado, su "componente principal". Estos suelen ser un carácter completo (con excepción de la X) por derecho propio. Siempre se puede escribir este componente principal escribiendo la letra en la que se encuentra cuatro veces. Así, por ejemplo, el componente principal de H es 目, por lo que se escribiría escribiendo "hhhh".
Cada letra tiene también un carácter de acceso directo asociado. En algunos casos, este carácter es el mismo que el componente asociado a la tecla en cuestión, y en otras ocasiones no. Este carácter de acceso directo es el que se produce cuando se escribe solo la letra y nada más; todos estos son caracteres extremadamente comunes que se utilizan al escribir en chino.
Es muy posible que haya varios componentes que no estén enumerados a continuación, ya sea por descuido, porque rara vez se usan o porque no existe una representación Unicode simple para el componente.
El componente principal de la tecla Q es 金 y su carácter de atajo es 我. Está asociada con los siguientes componentes: 金, 钅, 勹, 儿, 夕, así como el gancho en la parte superior de 饣 y 角, el radical 犭sin el trazo descendente inferior izquierdo (por lo que los caracteres con ese radical comienzan con "qt", no solo "q"), el entrecruzamiento (como en el centro de 区), la parte superior de 鱼 (es decir, sin el trazo horizontal en la parte inferior) y los tres "pies" (casi verticales) en la esquina inferior derecha de 流.
El componente principal y el carácter de acceso directo de la tecla W son ambos 人. Está asociada con los siguientes componentes: 人, 亻, 八 y la parte superior de 癸. Si bien 人 significa persona, Wubi la usa a menudo para construir un radical de techo, como en 会, "wfc". 入 no está gobernada por W, a pesar de parecer similares, y si bien 餐 tiene una parte superior que se parece vagamente a la parte superior de 癸, no son lo mismo (de hecho, para escribir 餐, uno debe escribir físicamente cada componente en la parte superior).
El componente principal de la tecla E es 月, y su carácter de atajo es 有. Está asociado con los siguientes componentes: 月, 用, 彡, 乃, la parte inferior de 衣 (es decir, sin 亠), la parte superior de 孚 (es decir, sin 子), 豕 (cerdo), la parte inferior de 良 (es decir, sin 白) y la parte inferior de 舟 (es decir, sin el pequeño punto en la parte superior). En este caso, el carácter de atajo de E ni siquiera comienza con un trazo descendente hacia la izquierda, sino que simplemente figura prominentemente como un componente perteneciente a E. 彡 aparece en este carácter, ya que es el tercer carácter en la zona (contando desde T, ver arriba). Una distorsión particular que surge a menudo es el uso de E en 且 y en caracteres que lo contienen: Wubi piensa en este componente como 月 + 一.
El componente principal de la tecla R es 白, y su carácter de atajo es 的. Está asociado con los siguientes componentes: 白, 手, 扌, 斤 (con y sin la T), 牛 ( sin el trazo vertical descendente) y, por supuesto, los dos trazos descendentes hacia la izquierda 𰀪 que uno esperaría de la segunda tecla en la zona (ver más arriba para una explicación). Esté atento a las variedades de 手 donde el gancho descendente central se reemplaza por un trazo descendente hacia la izquierda, como en 看.
El componente principal de la tecla T es 禾, y su carácter de acceso directo es 和. Está asociada con los siguientes componentes: 禾, 竹, 夂, 攵, 彳 y la parte superior de 乞 (es decir, sin 乙). 竹 también se puede encontrar en su forma más pequeña (⺮). 丿 también se encuentra en esta tecla, porque T es la primera tecla en la zona (ver arriba). Esto significa que si uno está escribiendo un componente o carácter trazo por trazo, (generalmente) usaría T para representar un trazo descendente hacia la izquierda. Vea la sección sobre trazos de desambiguación para obtener más información sobre las excepciones a esta regla.
Esta zona también podría llamarse zona de puntos, porque su patrón de Y: 讠 U: 冫 I: 氵 y O: 灬 no está necesariamente formado por trazos descendentes hacia la derecha. De hecho, se podría argumentar que el primer trazo de 灬 en realidad cae hacia la izquierda . Se llama zona descendente hacia la derecha porque las teclas de esta zona, cuando se utilizan para construir un carácter por trazo (en lugar de componente), representan todas trazos descendentes hacia la derecha para alguna configuración de carácter (consulte la sección sobre trazos de desambiguación para obtener más información).
El componente principal de la tecla Y es 言, y su carácter de acceso directo es 主. Está asociada con los siguientes componentes: 言, 讠, 亠, 亠 con una 口 debajo, 广, 文, 方 y 丶. Todos estos componentes comienzan con un trazo descendente hacia la derecha. Por lo general, los puntos en los caracteres chinos son en realidad trazos descendentes hacia la izquierda , por lo que la mayoría de las veces, el uso de T es más apropiado que Y. Por supuesto, si uno puede escribir caracteres chinos a mano, debería poder saber cuál elegir recordando cómo se escribe.
El componente principal de la tecla U es 立, y su carácter de acceso directo es 产. Está asociada con los siguientes componentes: 立, 六, 辛, 门, 疒, 丬, 冫, las "antenas" en la parte superior de 单 (solo dos trazos: 丷) y las antenas más un trazo horizontal, como se encuentra en la parte superior de 兹. La mayoría de estos tienen dos trazos diagonales cortos (门 es la excepción obvia). Esto es coherente con el lugar de U como la segunda letra en la zona (ver más arriba para una explicación).
El componente principal de la tecla I es 水, y su carácter de acceso directo es 不. Está asociada con los siguientes componentes: 水, 氵, 小, los tres trazos sobre 学 y los tres trazos sobre 当. Además, un componente que podría describirse como dos 冫, uno tras otro, está asociado con este carácter.
El componente principal de la tecla O es 火, y su carácter de acceso directo es 为. Está asociada con los siguientes componentes: 火, 米, 灬 y 业sin el trazo horizontal inferior, lo que permite la construcción de caracteres como 严. Esta es la cuarta tecla en la zona descendente derecha: de ahí la inclusión de 灬.
El componente principal de la tecla P es 之 y su carácter de acceso directo es 这. Está asociada con los siguientes componentes: 之, 辶, 廴, 冖, 宀 y 礻. Como los componentes de Wubi se escriben en el orden en que se tendrían que escribir si uno escribiera a mano, los componentes 辶 y 廴 normalmente se escriben al final .
Las pulsaciones del teclado se dividen en 5 zonas
Ejemplo 1: 请 Consta de tres componentes: y (讠, radical #10), g (王*, radical 89), e (月, radical 118) → 请
Ejemplo 2: 遗
Consta de cinco componentes: k (口), h (丨), g (一), m (贝), p (辶) → khgp → 遗 (no es necesario escribir m)
Ejemplo 3a: 文: Primero escribes la tecla que tiene el símbolo, que es "Y". Luego escribes el primer componente, que también es "Y" para el trazo 点, luego una "G" para el trazo 横, y como ahora ya tienes tres trazos, escribes el último trazo, que también es 捺, llegando al código de tecla "YYGY" para el carácter completo.
Ejemplo 3b: 一: El código para este carácter es 'GGLL'. Como antes, primero se escribe la tecla para el carácter, que es 'G', luego el primer trazo de ese carácter, que también es una 'G'. Debido a que toda esta es información necesaria, la L se utiliza como relleno hasta que se alcanzan las 4 letras. [2] Tenga en cuenta que '一' también es el carácter de atajo para 'G' (lo que en la práctica lo convierte en un solo trazo).
Ejemplo 3c: 广: El código para este carácter es 'YYGT'. Primero, escribe la tecla donde se encuentra este carácter, que es una 'Y'. Luego, escribe un trazo 点, que también está en 'Y'. El siguiente será el trazo 横 en 'G', y el último será el 捺, en 'T'.
Ejemplo 4: 等
Consta de tres componentes: t (竹), f (土), f (寸),
Trazos de desambiguación: El último trazo es 丶 y el carácter tiene una estructura de arriba a abajo (42,u) → 等
Se realizó un poema como mnemotecnia para el teclado Wubi, asociando unos pocos caracteres a cada tecla. El primer carácter es el componente principal de la tecla correspondiente, mientras que los siguientes son componentes o caracteres asociados.
G11王旁青头戋五一
F12土士二干十寸雨
D13大犬三羊古石厂
S14木丁西
A15工戈草头右框七
H21目具上止卜虎皮
J22日早两竖与虫依
K23口与川,字根稀
L24田甲方框四车力
M25山由贝,下框几
T31禾竹一撇双人立,反文条头共三一
R32白手看头三二斤
E 33月彡(衫)乃用家衣底
W34人和八,登祭头
Q35金勺缺点无尾鱼,犬旁留义儿一点夕,氏无七
Y41言文方广在四一,高头一捺谁人去
U42立辛两点六门疒(病)
I43 水旁兴头小倒立
O44火业头,四点米
P45之宝盖,摘示衣
N51已半巳满不出己,左框折尸心和羽
B52子耳了也框向上
V53女刀九臼山朝西
C54又巴马,丢矢矣
X55慈母无心弓和匕,幼无力
G11 王旁青头五夫一
F12 土干十寸未甘雨,不要忘了革字底
D13 大犬戊其古石厂
S14 木丁西甫一四里
A 15 工戈草头右框七
H21 目上卜止虎具头
J22 日早两竖与虫依
K23 口流川,码元稀
L24 田甲方框四车里
M25 山由贝骨下框集
T31 禾竹反文双人立
R32 白斤气丘叉手提
E33
34 人八登头单人几
Q35 金夕鸟儿犭边鱼
Y41言文方点谁人去
U42 立辛六羊病门里
I43 水族三点鳖头小
O44 火业广鹿四点米
P45 之字宝盖补示衣
N51 已类左框心尸羽
B52 子耳了也乃框皮
V 53 女刀九良山西倒
C54 又巴牛入马失蹄
X55 幺母贯头弓和匕
G11 王旁青头五一提
F12 土士二干十寸雨
D13 大三肆头古石厂
S14 木丁西边要无女
A15 工戈草头右框七
H21 目止具头卜虎皮
J22 日曰两竖与虫依
K23 口中两川三个竖
L24 田框四车甲单底
M25 山由贝骨下框里
T31 禾竹牛旁卧人立
R32 白斤气头叉手提
E33 月舟衣力豕豸臼
W34
35 金夕犭儿包头鱼
Y41 言文方点在四一
U42 立带两点病门里
I43 水边一族三点小
O44 火变三态广二米
P45 之字宝盖补示衣
N51 已类左框心尸羽
B52 子耳了也乃齿底
V53 女刀九巡录无水
C 54 又巴甬矣马失蹄
X55 幺母绞丝弓三匕
En 2020, la historia de Wubi apareció en un episodio de Radiolab titulado "El efecto Wubi". [3]